NLP入门——文本表示概述
文本表示的含义
文本表示是将自然语言转为计算机能理解的数值形式,是绝大多数自然语言处理任务(NLP)的基础步骤。
文本表示的过程
文本表示的过程主要是分词和词表构建。
分词的概念
分词是把原始文本按照一定的规则切分为若干个具有独立语义的最小单元,这样的最小单号就叫token。
每一个模型,都会由自己的分词规则,分词规则越准确(不是指更细,而是分的准确率),模型的能力也相应地更高。
词表的概念
在分词之后会得到大量的token的集合,给每个token都分配有唯一的id这就是词表。在词表中,id和token之间是相互映射的,即可以用id找到token,也就是对应的词,也可以用token去找到对应的id。
在后续的处理中,词表会转为低维稠密的向量表示(词向量),如“我”-》[1.2,3.3,2,4,1.5]
不同词的向量是不一样的。词之间可能在一个或多个维度上相似或相反,这就构成了词与词之间的关联,也就有了可预测性、
对于自然语言处理来说,分词和词表是地基,是原始素材,一起的处理过程都要基于词表。在常见的文本生成任务重,模型输出的本质是通过预测下一个词出现的概率,从而选择概率最大的词。
案例
分词和词表的案例:
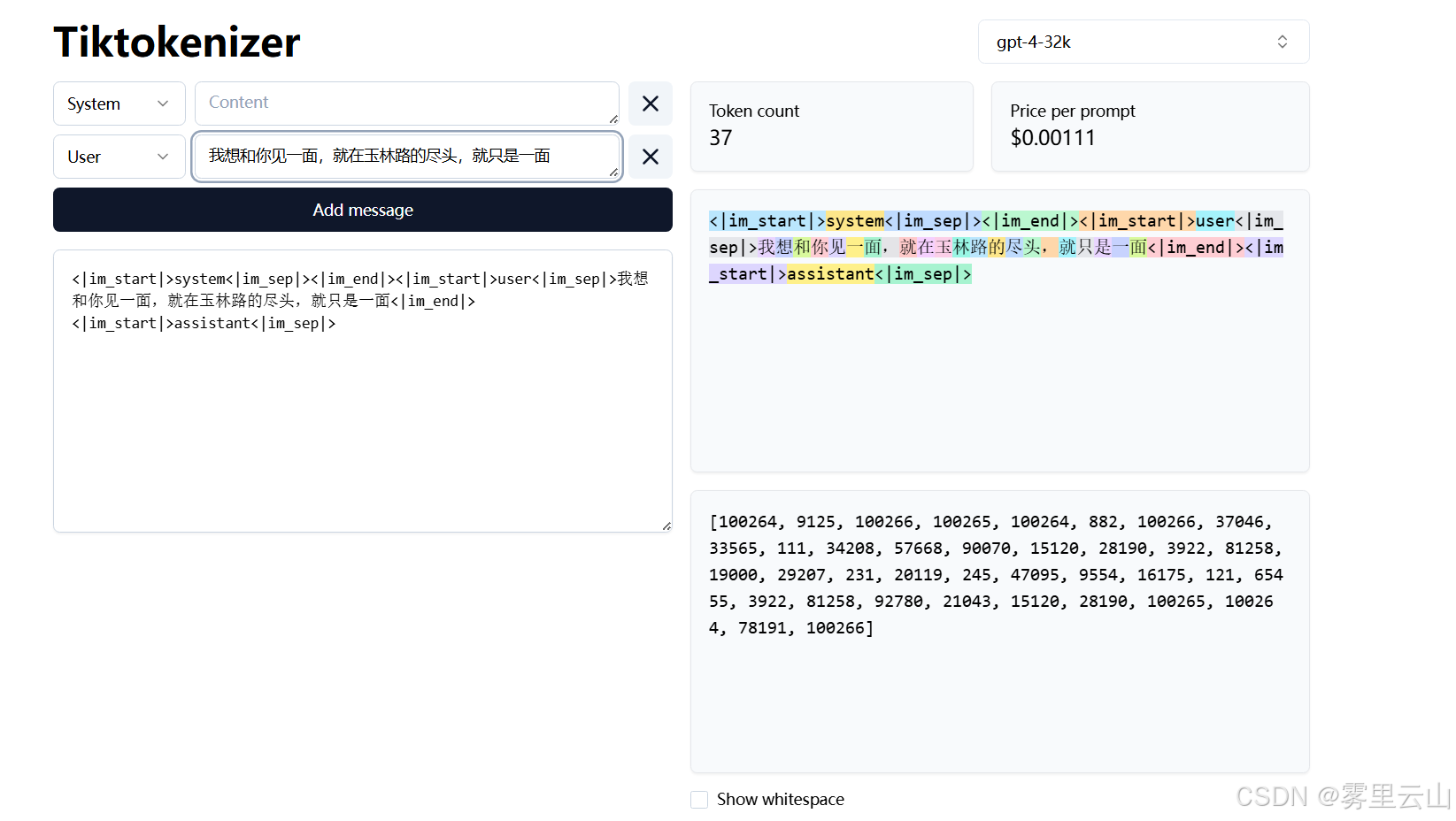
打开Tiktokenizer这个网站,上面有很多模型,分别对应了不同的分词规则和词表,通过输入对应语句可以观察各个模型之间的区别和理解分词和词表。
如下,在gpt3.5中【我想和你见一面,就在玉林路的尽头,就只是一面】对应的向量是
[100264, 9125, 198, 100265, 198, 100264, 882, 198, 37046, 33565, 111, 34208, 57668, 90070, 15120, 28190, 3922, 81258, 19000, 29207, 231, 20119, 245, 47095, 9554, 16175, 121, 65455, 3922, 81258, 92780, 21043, 15120, 28190, 100265, 198, 100264, 78191, 198],
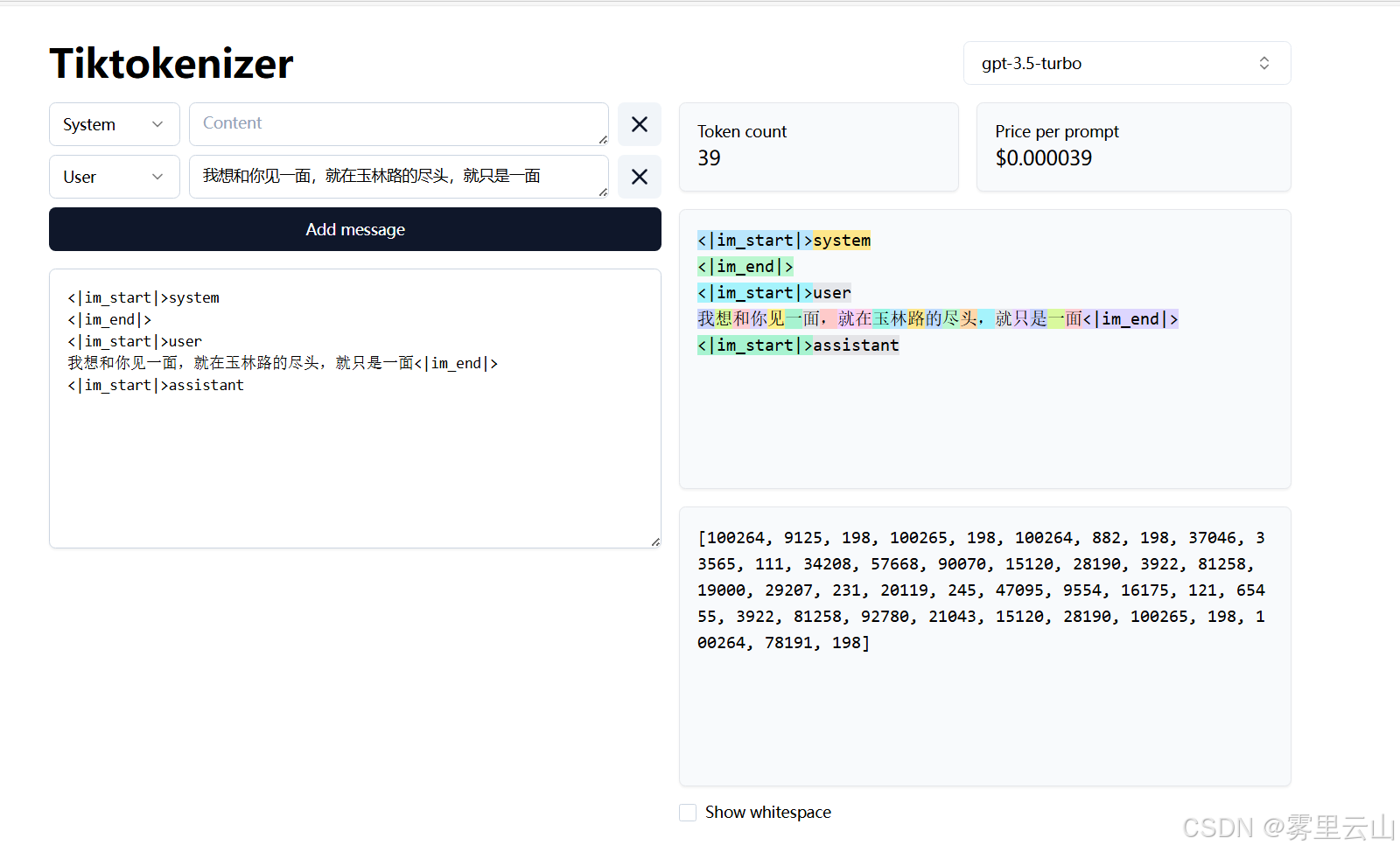
而在gpt-4-32k中,对应的向量却是这样的