PHIAF:基于GAN的数据增强和基于序列的特征融合的噬菌体-宿主相互作用预测
摘要
噬菌体治疗已成为细菌疾病治疗中最有前途的抗生素替代品之一,鉴定噬菌体-宿主相互作用( PHIs )有助于了解噬菌体感染细菌的可能机制,从而指导噬菌体治疗的发展。与湿试验相比,辨识PHIs的计算方法可以降低成本、节省时间,更加有效和经济。在本文中,我们提出了一种基于生成对抗网络( GAN )的数据增强和基于序列的特征融合( PHIAF )的PHI预测方法。首先,PHIAF应用了基于GAN的数据增强模块,生成伪PHI以缓解数据稀缺问题。其次,PHIAF融合了来自DNA和蛋白质序列的特征以获得更好的性能。第三,PHIAF利用注意力机制来考虑DNA /蛋白质序列衍生特征的不同贡献,这也提供了预测模型的可解释性。在计算实验中,当通过5折交叉验证( AUC和AUPR分别为0.88和0.86)进行评估时,PHIAF优于其他先进的PHI预测方法。消融研究表明,数据增强、特征融合和注意力机制都有利于提高PHIAF的预测性能。此外,案例研究中PHIAF得分最高的4个新PHI也得到了近期文献的验证。总之,PHIAF是一个很有前途的加速探索噬菌体治疗的工具。
引言
现有方法的局限性:
首先,在数据库中有成千上万个经过实验验证的PHI,但只有几百个非冗余的PHI可用于建立预测模型。这种局限性阻碍了高性能预测模型的发展。其次,大多数现有的方法使用噬菌体和宿主的DNA序列或蛋白质序列来构建预测模型,但很少将两类序列结合起来。第三,尽管多种特征和机器学习技术已被用于构建预测模型,但这些模型往往缺乏足够的可解释性,这阻碍了对PHIs机制的阐述。
在当前的研究中,我们提出了一种新颖的基于GAN数据增强和基于序列的特征融合的PHI预测方法,简称PHIAF,以解决PHI预测的各种挑战。首先,PHIAF使用GAN构建数据增强模块,生成高质量的伪样本以克服PHI数据稀缺的瓶颈。其次,PHIAF融合了噬菌体和宿主的DNA和蛋白质序列编码的不同特征,以增强预测性能。第三,PHIAF利用CNN构建PHI预测模块,并将注意力机制融入CNN中,以提供预测模型的可解释性。
方法
PHIAF
PHIAF包含三个主要模块:特征提取、数据增强和PHI预测。PHIAF的原理图如图1所示。首先,将噬菌体和宿主的DNA和蛋白质序列编码成特征(图1A )。其次,使用基于GAN的数据增强模块来生成伪PHIs (图1B )。最后,在CNN框架下构建PHI预测模块,并注意利用DNA和蛋白质序列在重塑为适当形式后衍生的特征来预测PHIs (图1C )。
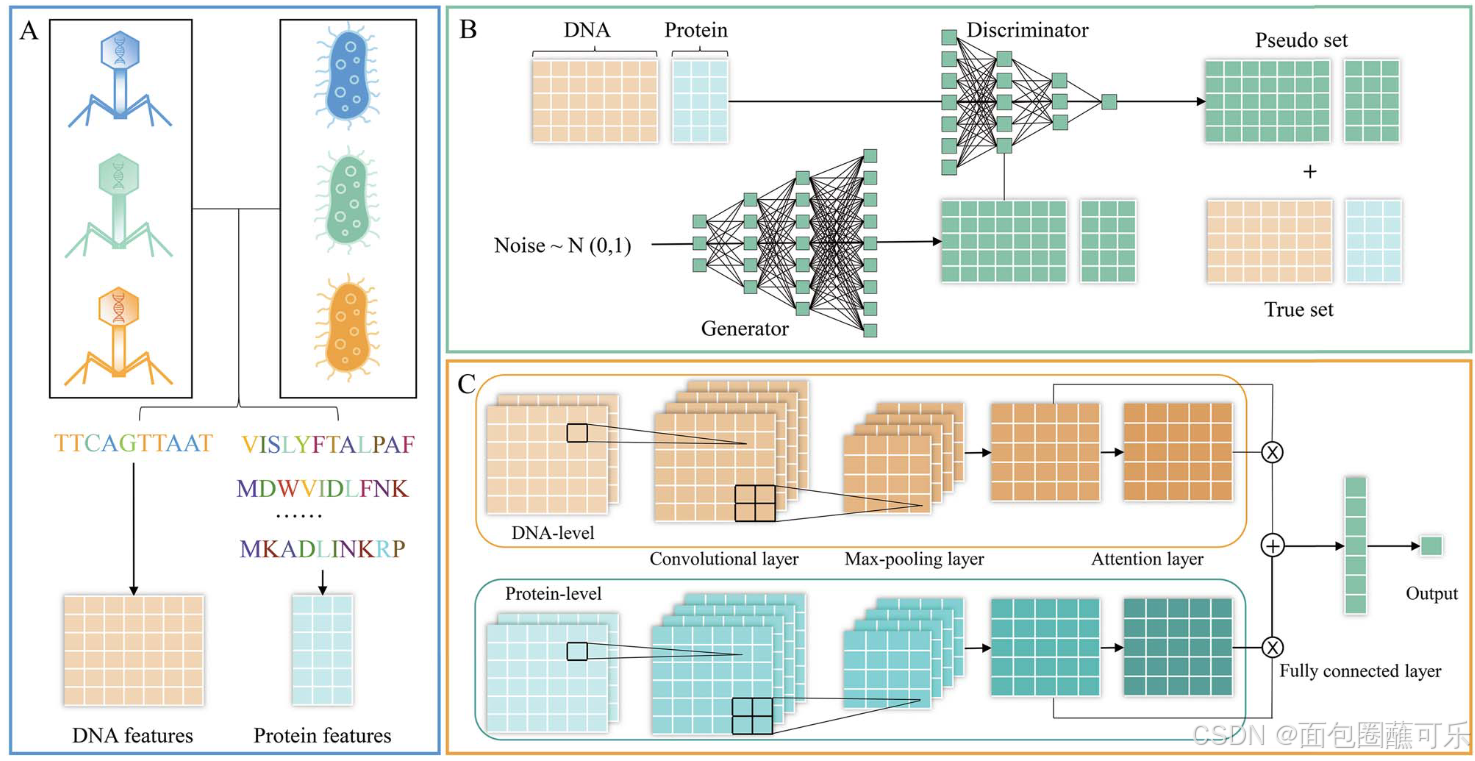
特征提取模块
一些研究表明,DNA和蛋白质序列在噬菌体和宿主的生物进化中起着基础性的作用。为了获得更全面有效的信息,我们从噬菌体和宿主的DNA和蛋白质序列中提取特征,总结如表1所示;这些特征的详细信息见《补充材料》第3节。

数据增强模块
GAN是一种新型的生成式模型,旨在通过精确学习真实样本的潜在分布来生成高质量的伪样本。该模型受到了相当大的关注,并在多个领域[ 43、44 ]中取得了优异的表现。在这项研究中,我们使用了一个GAN [ 39 ]来解决我们数据集中PHIs的数据稀缺问题,用于模型训练。
一个网络(生成器)试图通过5个全连接层生成伪样本(公式1 )。另一个网络(判别器),由四个全连接层组成(公式2 ),试图区分给定样本是否为真实样本。每个网络的任务越来越好,直到达到平衡,此时生成器无法产生更好的样本,判别器无法分离真实样本和伪样本。
上述处理用于扩增我们数据集中的阳性样本。由于所有未知的PHI都是候选的负样本,并且远远多于正样本,因此我们从这个候选集中随机选择负样本,以确保正负样本的数量相等。最后,我们将真实的正样本、选择的负样本和伪正样本结合起来构建增广数据集,用于训练预测模型。
PHI预测模块
基于扩增后的数据集,我们利用噬菌体和宿主的DNA和蛋白质序列衍生特征来构建预测模型。
我们首先采用Min - Max归一化将特征向量中的值归一化到0到1的范围内。然后,我们构建了一个双层架构( DNA和蛋白质水平),从DNA和蛋白质特征矩阵中提取更深层次的特征。对于DNA级别,我们将噬菌体和宿主的DNA衍生特征矩阵跨通道堆叠形成组合矩阵,然后将该组合矩阵输入到一个两层的CNN中,产生一个包含更多有意义信息的特征图Od。CNN包括一个卷积层和一个最大池化层。
注意力机制旨在模仿人脑的动作,在机器学习任务中选择性地集中于少数几个重要部分而忽略其他部分。我们所拥有的DNA和蛋白质层面特征可能对PHI预测做出不同的贡献。因此,我们在我们的模型中引入注意力机制,加入注意力层来捕获重要的特征,然后将这些特征进行整合。
在注意力层,将DNA -和蛋白质层面特征图( Od和Op)输入到全连接层,分别计算权重向量;然后,将特征图与对应的权重向量相乘。最后,输出结果。