LLM - 大模型融合 LangChain 与 OpenRouter 的框架
欢迎关注我的CSDN:https://spike.blog.csdn.net/
本文地址:https://spike.blog.csdn.net/article/details/153823110
免责声明:本文来源于个人知识与公开资料,仅用于学术交流,欢迎讨论,不支持转载。
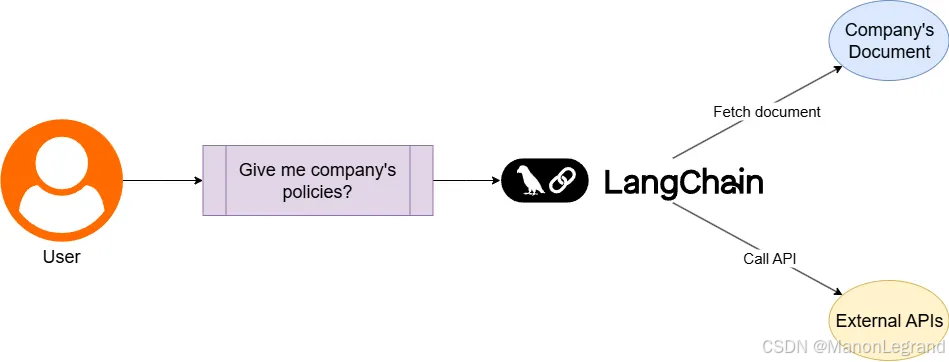
LangChain 与 OpenRouter 的结合使用,为构建灵活且可扩展的大语言模型应用提供优雅的解决方案。LangChain 作为应用开发框架,通过其模块化的链式调用、智能代理和记忆管理机制,为开发者搭建复杂的 LLM 工作流提供了坚实基础;而 OpenRouter 则扮演着统一的模型路由网关角色,将 OpenAI、Anthropic、Google 等数十家模型提供商的接口标准化,无需修改代码即可在 GPT、Claude、Gemini 等不同模型间无缝切换。
环境配置
安装 python 环境:
brew install python@3.12
安装 conda 配置:
curl -O https://repo.anaconda.com/miniconda/Miniconda3-latest-MacOSX-arm64.sh
bash ~/Miniconda3-latest-MacOSX-arm64.sh
source ~/.zshrc
安装 LangGraph 环境:
pip install -U langgraph==1.0.2 langchain==1.0.5 langchain-openai==1.0.2 langchain-core==1.0.4
OpenRouter
申请 OpenRouter 的 Key,即 https://openrouter.ai/
- 设置 Credits,配置信用卡,国内卡可用,即:
- 在 Keys 中配置 Key,可选择 Tokens 上限,即:
- 模型列表,参考 https://openrouter.ai/models,即
openai/gpt-4.1
google/gemini-2.5-flash
代码
在 .env 中,配置 key,即:
OPENROUTER_API_KEY="sk-or-v1-xxx"
环境变量:
from dotenv import load_dotenv
load_dotenv(dotenv_path=".env")
配置 LLM:
from langchain_openai import ChatOpenAI
from langchain_core.prompts import PromptTemplate
from langchain_core.output_parsers import StrOutputParser
from os import getenv
from dotenv import load_dotenv
import base64load_dotenv(dotenv_path=".env")llm = ChatOpenAI(api_key=getenv("OPENROUTER_API_KEY"),base_url="https://openrouter.ai/api/v1",# model="openai/gpt-4.1",model="google/gemini-2.5-flash",# default_headers={# "HTTP-Referer": getenv("YOUR_SITE_URL"), # Optional. Site URL for rankings on openrouter.ai.# "X-Title": getenv("YOUR_SITE_NAME"), # Optional. Site title for rankings on openrouter.ai.# }
)
LLM 处理 3 类文件,即文本、图像、PDF文件。
文本(Text)
测试:
def test_text():"""测试文本问答"""template = """你是一位善于推理的顶尖AI助理。
请认真阅读用户给出的提问,并结合事实,分步骤详细推理你的答案,最后给出简明的结论。
问题:{question}
推理过程:
"""prompt = PromptTemplate(template=template, input_variables=["question"])# 直接输出字符串 StrOutputParserllm_chain = prompt | llm | StrOutputParser()question = "贾斯汀·比伯出生那一年,哪支NFL球队赢得了超级碗?"res = llm_chain.invoke({"question": question})print(res)
输出:
好的,我将按要求进行推理并给出结论。**推理过程:**1. **确定关键信息:** 问题询问“贾斯汀·比伯出生那一年”,哪支NFL球队赢得了超级碗。2. **查找贾斯汀·比伯的出生年份:*** 通过可靠的信息来源(例如维基百科、官方传记等)查询贾斯汀·比伯的出生日期。* 查询结果显示,贾斯汀·比伯(Justin Bieber)出生于1994年3月1日。3. **确定与出生年份相关的超级碗赛事:*** NFL超级碗通常在每年的1月或2月初举行,对应的是前一年的常规赛和季后赛。* 因此,贾斯汀·比伯于1994年出生,那么在他出生那一年(1994年)举行的超级碗赛事,应该是1993赛季的超级碗。这个赛事通常被称为“超级碗 XXVIII”(Super Bowl XXVIII)。4. **查找“超级碗 XXVIII”的获胜球队:*** 查询超级碗 XXVIII(Super Bowl XXVIII)的比赛结果。* 查询结果显示,超级碗 XXVIII 于1994年1月30日举行,由达拉斯牛仔队(Dallas Cowboys)对阵布法罗比尔队(Buffalo Bills)。* 比赛最终结果是达拉斯牛仔队以30-13的比分击败了布法罗比尔队,赢得了该届超级碗冠军。**结论:**贾斯汀·比伯出生那一年(1994年),赢得超级碗的球队是**达拉斯牛仔队**。
Image(图像)
测试:
def test_image():"""测试图像问答(VQA, Visual Question Answering)"""img_path = "./test.jpg" # 测试图像vqa_template = """你是一位专业的视觉问答AI助理。请根据用户输入的图片内容,详细推理并回答下面的问题。
图片内容请认真观察,必要时一步步分析;最后给出简要结论。
问题:{question}
推理过程:
"""def encode_image_to_base64(img_path):with open(img_path, "rb") as image_file:return base64.b64encode(image_file.read()).decode("utf-8")image_base64 = encode_image_to_base64(img_path) # 将图片转为base64编码print(f"图像内容长度: {len(image_base64)}")question = "图中有几个人?他们在做什么?"message = {"role": "user","content": [{"type": "text", "text": vqa_template.format(question=question)},{"type": "image","base64": image_base64,"mime_type": "image/jpeg",},],}llm_chain = llm | StrOutputParser()res = llm_chain.invoke([message])print(res)
输出:
图像内容长度: 220268
这幅图像描绘了一个动漫风格的角色。**关于人数:**
1. 图像中呈现的是一个完整的人物形象,从头到脚都清晰可见。
2. 她有完整的五官(虽然一只眼睛被头发遮挡)、躯干、四肢(包括手和脚)。
3. 没有其他人物的特征或部分出现在画面中。**关于她在做什么:**
1. **姿势:** 她处于一个动态的姿势。她的左腿高高抬起并弯曲,脚掌露出,脚趾上似乎有一根棒棒糖形状的装饰物。她的右腿(大部分被遮挡)似乎是站立或支撑身体的。她的右臂向前方伸出,手掌张开,手指弯曲,呈现出一种蓄势待发或邀请的姿态。她的身体向左侧倾斜,头部略微抬起并转向右侧。
2. **表情:** 她的脸上带着明显的笑容,嘴角上扬,露出一颗尖牙,眼神中透着自信和一丝玩味。
3. **服装和配饰:** 她穿着一套黑白相间的服装,带有粉色和荧光绿的边缘装饰。服装设计独特,露出部分腹部,并且带有绑带和铆钉等朋克风格的元素。她的头发是深色的,在头部两侧扎成类似牛角的形状,并有粉色挑染。她的指甲是荧光绿色的。
4. **文字元素:** 在她的右腿下方,有黑色的文字“Let's PLAY!”,周围环绕着粉色和蓝色的泼墨效果。
5. **整体氛围:** 结合她的姿势、表情和文字,她似乎在邀请或发起某种活动,比如游戏或战斗,传递出一种自信、挑衅和活泼的氛围。背景的泼墨效果也增加了这种动感和艺术感。**简要结论:**
图中有**1个人**。她似乎是一名动漫角色,正摆出自信而挑衅的姿势,邀请对方“Let's PLAY!”,可能是在表达准备开始游戏或战斗。
测试图像:

文档(PDF)
测试:
def test_pdf():"""测试PDF问答"""pdf_path = "./test.pdf" # 测试PDFpdf_qa_template = """你是一位专业的PDF内容问答AI助理。请根据用户输入的PDF文档内容,详细推理并回答下面的问题。
请认真分析PDF内容,必要时一步步分析;最后给出简要结论。
问题:{question}
推理过程:
"""def encode_pdf_to_base64(pdf_path):with open(pdf_path, "rb") as pdf_file:return base64.b64encode(pdf_file.read()).decode("utf-8")pdf_base64 = encode_pdf_to_base64(pdf_path)print(f"PDF内容长度: {len(pdf_base64)}")question = "这份PDF文档的主题是什么?"message = {"role": "user","content": [{"type": "text", "text": pdf_qa_template.format(question=question)},{"type": "file", # always required"base64": pdf_base64, # 本地base64内容"mime_type": "application/pdf", # 文件类型"filename": "test.pdf", # 推荐添加,用于OpenAI文件上传},],}llm_chain = llm | StrOutputParser()res = llm_chain.invoke([message])print(res)
输出:
PDF内容长度: 173800
**推理过程:**1. **审视文档整体结构:** 这份PDF文档包含了“个人优势”、“工作经历”、“教育经历”和“资格证书”等几个主要的区块。
2. **分析“个人优势”部分:*** 开头明确指出文档的主人公是“XXX”,并给出了“男 | 32岁”、“10年工作经验”、“求职意向:算法工程师”、“期望薪资:40-70K”、“期望城市:北京”等关键信息。* 列举了多条技能和经验,包括编程语言(Python, Golang, C)、SQL、深度学习框架(TensorFlow, PyTorch)、数学系背景、AI领域研究、跨学科知识结合、AI领域最新动态跟踪等。* 这些都指向了求职者在AI和数据技术领域的专业能力。...**结论:**这份PDF文档的主题是**一份专注于算法工程和数据技术的个人简历**。详细展示了XXX在编程语言、数据库管理、大数据处理、人工智能和算法开发领域的专业技能、丰富的工作经验和扎实的教育背景,旨在求职“算法工程师”职位。