DrawEduMath:评估视觉语言模型的教育领域新基准
在AI赋能教育的浪潮中,视觉语言模型(VLMs)在数学教育场景的应用潜力日益凸显,从即时作业反馈到错误概念诊断,都离不开模型对学生手写数学内容的精准理解。
项目主页:https://drawedumath.org/
原文链接:https://arxiv.org/pdf/2501.14877
代码链接:https://github.com/allenai/drawedumath
数据集:https://huggingface.co/datasets/Heffernan-WPI-Lab/DrawEduMath
一、引言:为什么需要DrawEduMath?
1.1 研究背景与动机
近年来,Khan Academy、微软等机构纷纷推出AI数学教育工具,但这些工具的核心——视觉语言模型,却面临着“实验室表现”与“课堂实际”的脱节问题:
-
数据场景错位:现有主流数学基准如GSM8k、MATH均采用规整的印刷体问题,而真实课堂中80%以上的数学作业是手写形式,包含潦草字迹、手绘图表、计算痕迹等噪声。
-
评估维度单一:传统基准仅关注“解题正确性”,而教育场景更需要模型识别学生的解题策略、错误类型、概念误解等 pedagogical(教学法)维度的信息。
-
标注缺乏教育专业性:现有数据集标注多由普通标注员完成,缺少教师对学生作业的专业解读视角。
为解决上述问题,论文团队联合教育工作者构建了DrawEduMath基准,核心目标是:评估VLMs在真实教育场景下,理解学生手写数学内容的综合能力。
1.2 核心贡献
论文的核心贡献可概括为“一个数据集+三大技术创新”:
-
首个教师标注的手写数学数据集:包含2030张K-12学生手写作业图像,搭配教师撰写的详细描述和11661个QA对。
-
规模化合成QA方案:基于教师描述,利用LLM生成44362个合成QA,解决人工标注成本高的问题。
-
教育导向的问题分类体系:提出7类问题类型,精准覆盖教育场景的评估需求。
-
全面的VLM评估框架:结合自动评估(BERTSCORE、ROUGE-L)、LLM评估和人工评估,量化VLMs在教育场景的短板。
二、数据集构建:教师主导的全流程设计
DrawEduMath的数据集构建以“教育真实性”为核心,分为图像采样、教师标注、标注优化三个阶段,全程由资深数学教师参与,确保数据的教学价值。
2.1 图像采样:聚焦真实课堂场景
数据集的图像来源并非人工构造,而是源自美国在线学习平台ASSISTments的真实学生作业,具体采样策略如下:
-
问题覆盖:选取188个K-12数学问题,涵盖2年级到高中,其中6-8年级(初中)问题占比55.3%,符合手写作业的高频场景。
-
图像筛选:从6万张原始图像中,每个问题随机采样15张,最终经过去模糊、去隐私处理后保留2030张。
-
隐私保护:由本科生助理裁剪图像,仅保留数学内容,用黑块遮挡学生手部、姓名等个人信息,通过IRB(伦理审查委员会)认证。
-
标准对齐:所有问题关联美国共同核心州立标准(CCSS),确保数据与教学大纲一致。
数据集的核心特征如表2所示,其覆盖的数学领域前5名如表1所示,其中“比例与比例关系”(29.9%)和“几何”(24.4%)占比最高,这两类问题恰好是手写绘图的高频场景。


2.2 教师标注:注入教学专业视角
论文的核心创新之一是让教师主导标注,而非传统的普通标注员。标注团队由3名纽约市资深数学教师组成,平均教龄6年,其中2名专攻初中,1名覆盖5-12年级。标注分为两轮,流程如图1所示。

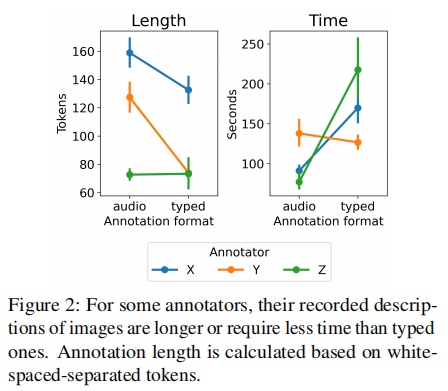
第一轮标注聚焦“详细描述”,教师需通过语音或文字,完整描述学生作业的所有细节,要求“另一位教师仅凭描述就能复现作业内容”。为提升效率,团队提供了两种标注方式:
-
语音标注:教师口头描述,通过OpenAI Whisper转录为文本,速度快且描述更详细。
-
文字标注:适合嘈杂环境,减少转录误差。
两种方式的对比如图2所示,部分教师的语音标注长度更长、耗时更短。第一轮标注最终产生22.8万字描述,平均每张图像111.1个词。
2.3 标注优化:新增QA对与修正
第二轮标注由5名更资深的教师(平均教龄9年,覆盖英美多地教学场景)完成,重点是修正描述+撰写QA对:
-
描述修正:94.2%的描述无需修改,修改部分多为拼写错误(如“rose”改为“rows”),平均编辑距离48.5。
-
QA对撰写:教师针对每个图像撰写QA对,聚焦教育核心需求,例如“学生使用了什么解题策略?”“存在哪些错误?”。最终产生11661个教师QA对,平均每张图像5.74个。
教师QA对的独特价值在于其教学导向性,例如针对“4个三分之一的分数条绘制”问题,教师会追问“学生标记的每部分是1/4还是1/3?”,这种问题直接指向学生的概念误解,是普通标注员难以设计的。

三、规模化创新:合成QA的生成与质量控制
教师撰写QA对的成本极高(平均每张图像4.3分钟),难以规模化。论文借鉴Changpinyo等人的思路,提出基于教师描述的合成QA生成方案,用LLM将自然语言描述转化为结构化QA对,实现数据扩容。
3.1 合成流程:从描述到QA的两步法
合成过程分为“信息拆分→QA生成”两步,全程由教师参与prompt设计,确保生成质量:
-
原子化拆分(Facet Extraction):将教师的长描述拆分为“原子信息块”,每个块仅包含一个核心事实。例如“左侧写着‘糖浆’,旁边有两个上下排列的数轴”拆分为两个facet:①左侧有手写词“糖浆”;②两个数轴上下排列。
-
QA生成:针对每个facet,生成闭合式QA对(避免开放式问题),例如将facet②转化为“两个数轴是上下排列还是左右排列?”,答案为“上下排列”。
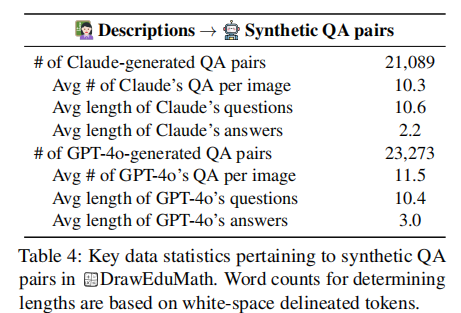
团队使用Claude 3.5 Sonnet和GPT-4o两种模型生成,最终得到44362个合成QA对,是教师QA的3.8倍。合成QA的统计信息如表4所示。
3.2 质量评估:合成QA的可靠性
为验证合成QA的有效性,团队邀请两名专业评估者(一名K-12教师、一名教育技术专家)对100个随机样本(GPT-4o和Claude各50个)进行评估,核心指标为“问题可回答性”和“答案正确性”,结果如表5所示。

评估结果表明:
-
高可靠性:教师评估者认为100%的问题可回答,94%的答案正确;技术专家的评估略严格,但整体正确率仍达86%。
-
错误原因:不可回答的问题多因“指代模糊”(如“第二个箭头指向哪里?”未明确箭头位置);错误答案多为转录或提取时的细节遗漏。
这证明合成QA虽不完美,但可作为教师QA的有效补充,且能大幅降低标注成本。
四、问题分类体系:精准定位教育场景需求
为深入分析VLMs在不同教育任务中的表现,论文提出了7类问题分类体系,通过“定性编码+量化聚类”的方式构建,确保分类的科学性和实用性。
4.1 分类方法:从聚类到验证的迭代过程
分类体系的构建分为三步:
-
模式检测:对教师和合成QA进行定性编码,并用Sentence-BERT生成句子嵌入,通过K-means(K=30)聚类,提取共性问题模式。
-
类别提炼:将聚类结果归纳为7类核心类型,区分“数学推理类”和“基础识别类”问题。
-
验证优化:让GPT-4o对500-2000个样本进行分类,迭代调整类别定义,确保分类边界清晰。
4.2 七类问题:覆盖教育全场景
7类问题的具体定义、占比及示例如表6所示,核心差异在于“是否需要数学教学知识”和“是否关注学生行为”:
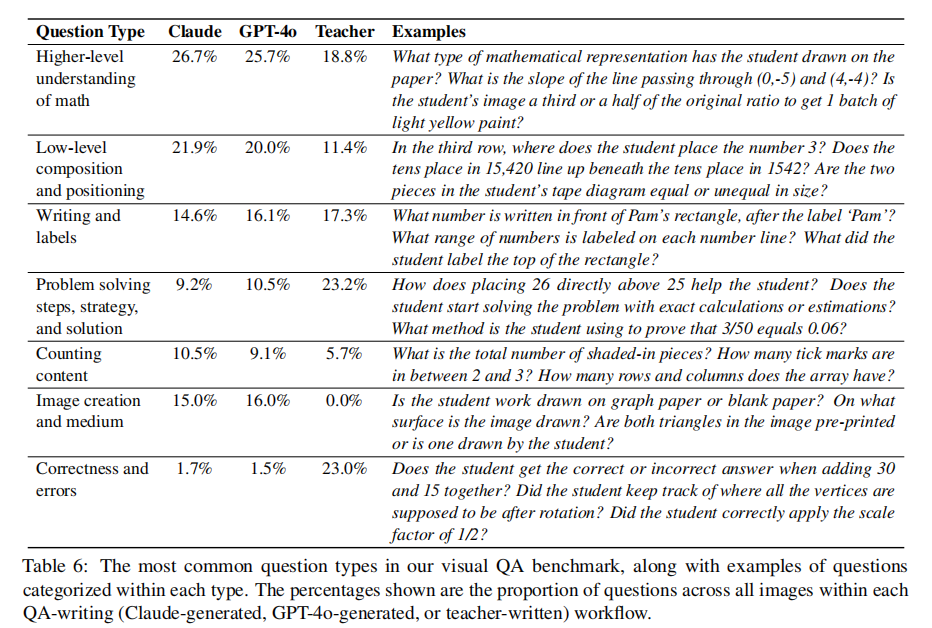
从占比可以看出关键差异:教师更关注“解题策略”(23.2%)和“正确性与错误”(23.0%),这两类问题直接服务于教学反馈;而合成QA更关注“媒介类型”(15%-16%)和“低阶位置”(20%-22%),这类问题更容易从描述中提取。这种差异恰好体现了合成QA的互补性——覆盖教师未关注的基础识别任务。
五、模型评估:VLMs在教育场景的表现如何?
论文选取4个主流VLMs进行评估,包括3个闭源模型(GPT-4o、Claude 3.5 Sonnet、Gemini 1.5 Pro)和1个开源模型(Llama 3.2-11B Vision),从“整体性能”和“问题类型细分”两个维度展开分析。
5.1 评估框架:三重验证确保可靠性
为避免单一评估指标的偏差,论文采用“自动评估+LLM评估+人工评估”的三重框架:
-
自动评估:用BERTSCORE(语义相似度)和ROUGE-L(n-gram匹配)衡量模型答案与标准答案的相似度。
-
LLM评估:让Mixtral 8x22B对模型答案与标准答案的相似度打分(1-4分),将3-4分视为正确。
-
人工评估:5名作者对500个样本(涵盖所有模型和QA类型)进行评估,判断“答案正确性”和“与标准答案匹配度”。
评估指标的相关性分析表明:LLM评估与人工评估的Spearman相关系数最高(0.801),准确率达89.6%,因此后续分析以LLM评估结果为主。
5.2 整体性能:闭源模型碾压开源,合成QA可替代教师QA
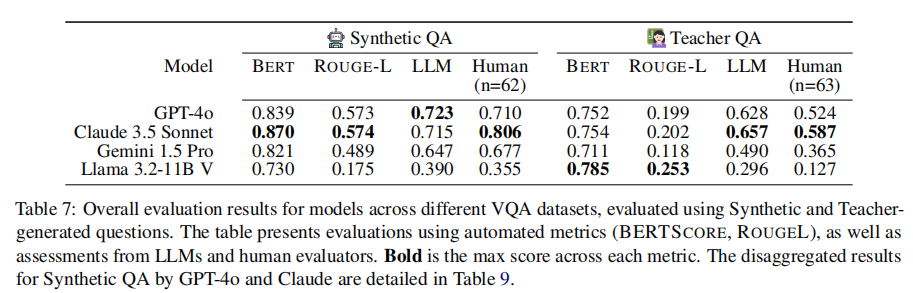
整体评估结果如表7所示,核心发现有三点:
-
闭源模型远优于开源:Claude 3.5和GPT-4o在合成QA上的LLM得分达0.7以上,而Llama 3.2仅0.39,差距显著。这说明开源VLMs在手写内容理解上仍有巨大提升空间。
-
合成QA与教师QA的一致性:两种QA对的模型排名一致(Claude≈GPT-4o>Gemini>Llama),证明合成QA可作为低成本的评估替代方案。
-
教师QA更具挑战性:所有模型在教师QA上的得分均低于合成QA,尤其是Gemini和Llama,说明教师设计的教育导向问题对VLMs更难。
5.3 问题类型细分:正确性判断是最大短板
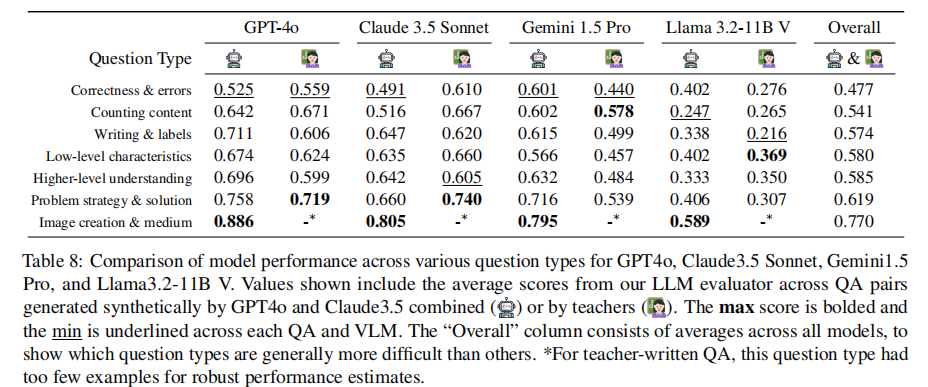
为定位VLMs的具体短板,论文分析了模型在7类问题上的表现,结果如表8所示。
六、研究价值与未来方向
6.1 理论与实践价值
-
基准价值:DrawEduMath是首个融合教师专业知识的手写数学评估基准,填补了真实教育场景评估的缺口,已开源供学界使用(drawedumath.org);
-
技术价值:提出“教师标注+LM合成”的QA生成策略,为高成本专业领域的基准构建提供范式;
-
应用价值:明确VLMs在教育场景的性能瓶颈,为AI助教工具的研发指明方向——需强化“学生应答匹配”和“错误诊断”能力。
6.2 局限性与未来方向
论文也坦诚指出了研究局限性,并提出未来改进方向:
-
局限性:数据集基于美国CCSS标准,地域和文化代表性不足;合成QA存在指代模糊问题;部分问题依赖通用数学知识而非手写内容理解;
-
未来方向: 拓展数据集:覆盖更多国家的课程标准和语言;
-
优化评估:设计更精细的问题分类(如“计算错误”“概念错误”);
-
模型优化:研发融合教育知识的VLMs,提升对解题策略和错误类型的理解。
七、总结
DrawEduMath通过“真实场景数据+教师专业标注+双轨QA评估”的创新设计,系统评估了VLMs在手写数学理解中的性能。研究发现,尽管闭源VLMs在表面特征识别上表现出色,但在“学生应答匹配”和“错误诊断”等教育核心需求上仍有巨大提升空间。该研究不仅为VLMs的教育应用提供了评估基准,更揭示了AI赋能教育的关键方向——从“数学正确”走向“精准匹配学生实际学习状态”。对于教育AI研究者和开发者而言,DrawEduMath既是评估工具,更是理解教育场景需求的重要参考。