LSTM模型做分类任务2(PyTorch实现)
LSTM实战案例(成员推断攻击日志数据集)
0. 导入相关包
这里面新认识两个包torch.utils.data.TensorDataset、torch.nn.utils.rnn.PackedSequence。
另外请注意对比Dataset与TensorDataset的区别。(后面会讲)
1. 加载原始数据

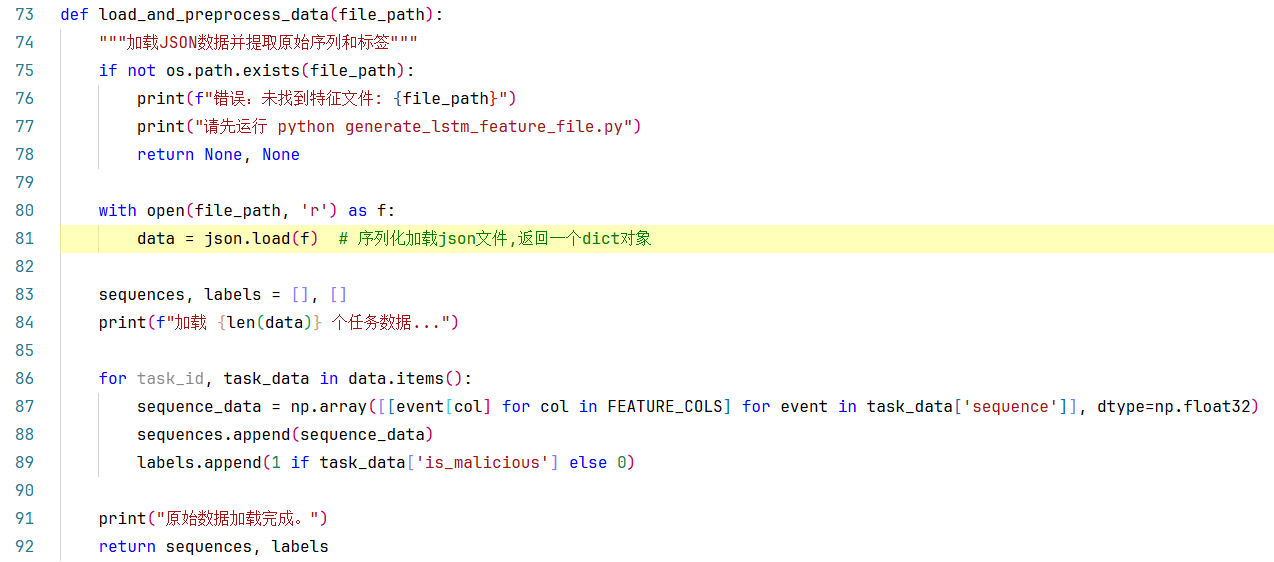
上面讲的是load_and_preprocess_data()方法的实现,输入一个路径参数file_path,返回序列特征sequences+标签labels。
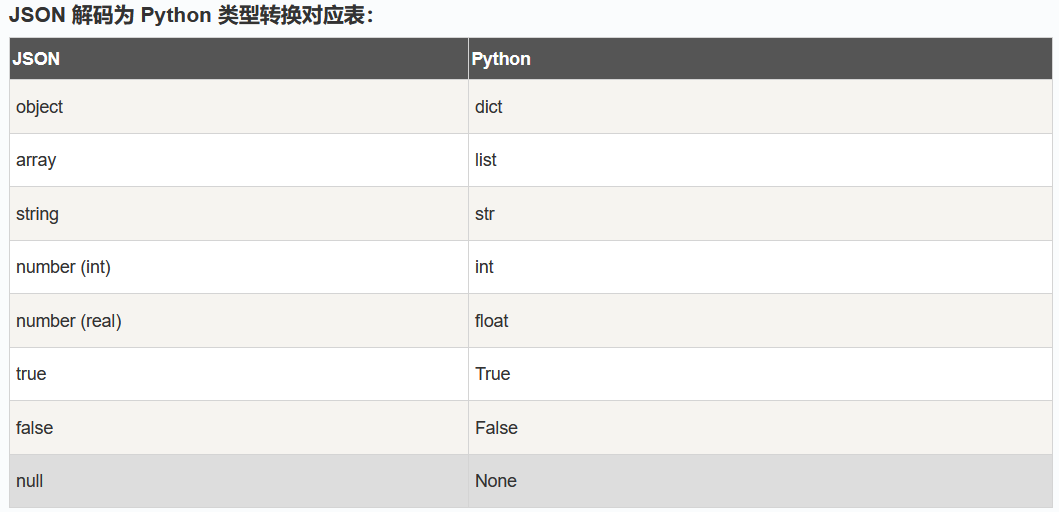
1.在第81行,json.load()方法:序列化加载json文件,返回一个dict对象。
Python3 JSON 数据解析
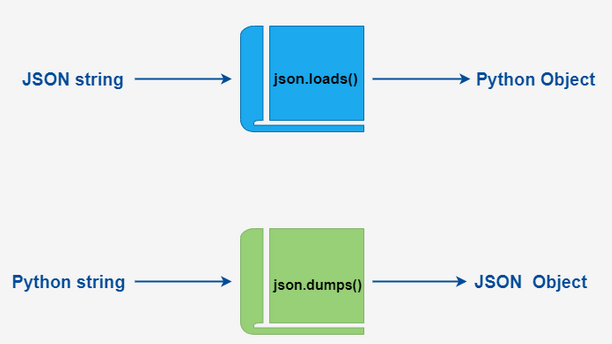
- json.dumps(): 对数据进行编码。
- json.loads(): 对数据进行解
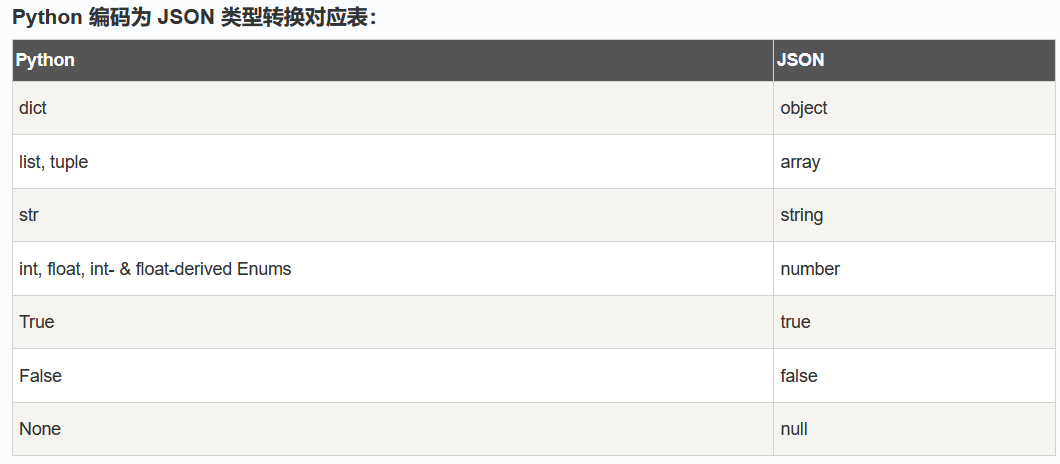
在 json 的编解码过程中,Python 的原始类型与 json 类型会相互转换,具体的转化对照如下:
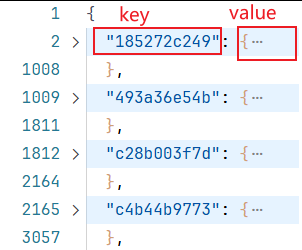
2.在第86行,data.items()方法:聚合的一个可遍历的key/value 对。
在这里task_id即拿到的每一个key,task_data即对应的每一个Value值;
task_data又是一个json字符串(在python里叫dict字典)
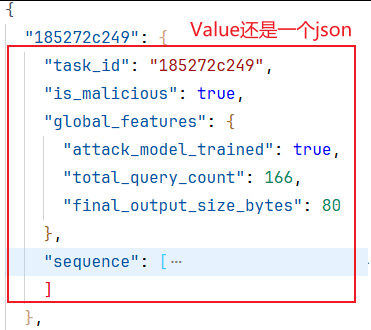

第86行:
Python 字典 items() 方法以列表返回视图对象,是一个可遍历的key/value 对。
dict.keys()、dict.values() 和 dict.items() 返回的都是视图对象( view objects),提供了字典实体的动态视图,这就意味着字典改变,视图也会跟着变化。
视图对象不是列表,不支持索引,可以使用 list() 来转换为列表。
我们不能对视图对象进行任何的修改,因为字典的视图对象都是只读的。
第87行:提取特征列并转换为float32类型。
np.array([ [event[col] for col in FEATURE_COLS] for event in task_data['sequence'] ], dtype=np.float32)这是一个生成式列表的写法,

外层:对于每个事件(event)在task_data['sequence']中,我们创建一个列表(内层列表推导式)
内层:对于每个特征列(col)在FEATURE_COLS中,我们从当前事件(event)中取出该列的值。
因此,对于每个事件,我们生成一个列表,包含FEATURE_COLS中指定的所有特征值。然后,对于每个任务(task_id),我们将所有事件(即任务序列中的每个时间步)的这些列表组合成一个二维数组(序列长度, 特征数),其中每一行代表一个时间步,每一列代表一个特征。
所以,整个第二行代码的作用是:从当前任务的数据中提取出特征序列,每个时间步提取指定的三个特征,形成一个二维数组(序列长度 x 特征数),并将其数据类型设置为float32。
这种语法是Python中非常常见的数据转换技巧,可以简洁地将嵌套的循环和条件判断转换为一行代码。但是,如果嵌套层数过多,可能会降低可读性。在这个例子中,两层嵌套还是比较清晰的。
注意:如果某个事件中缺少某个特征列,那么会抛出KeyError异常。因此,确保每个事件都有FEATURE_COLS中指定的列。
list 生成式的创建
语法:
[expr for iter_var in iterable] [expr for iter_var in iterable if cond_expr]第一种语法:首先迭代 iterable 里所有内容,每一次迭代,都把 iterable 里相应内容放到iter_var 中,再在表达式中应用该 iter_var 的内容,最后用表达式的计算值生成一个列表。
第二种语法:加入了判断语句,只有满足条件的内容才把 iterable 里相应内容放到 iter_var 中,再在表达式中应用该 iter_var 的内容,最后用表达式的计算值生成一个列表。
其实不难理解的,因为是 list 生成式,因此肯定是用 [] 括起来的,然后里面的语句是把要生成的元素放在前面,后面加 for 循环语句或者 for 循环语句和判断语句。
优势:
列表推导式通常比标准循环更快
代码更简洁易读(一旦熟悉语法)
第88、89行:分别将特征序列和标签追加到列表中。此处使用的append()方法,请注意extend()与append()的区别(上篇文档有说明:https://blog.csdn.net/m0_59777389/article/details/154060500?spm=1011.2415.3001.5331)
2.划分数据集(80%训练+20%验证, 30%测试)
一次划分:先划分出来训练集和测试集(7:3)

二次划分:再从训练集中划分出验证集(8:2)

stratify参数是train_test_split中一个非常重要的参数,用于确保划分后的数据集中各类别的比例与原始数据集中保持一致。这在处理不平衡数据集时尤其重要。让我们详细解释一下:
作用:
当设置stratify=labels时,train_test_split会按照labels中各类别的比例来划分数据。也就是说,划分后的训练集和测试集中,每个类别的样本比例与原始数据集中每个类别的样本比例相同。为什么使用:
假设原始数据集中有100个样本,其中20个正样本(1),80个负样本(0),即正样本占20%。如果使用分层划分,那么训练集和测试集中都会保持正样本占20%的比例。这可以防止因为随机划分导致训练集和测试集中类别比例不一致,从而影响模型的训练和评估。用法:
stratify参数可以接收一个数组,通常就是标签数组y(即labels)。train_test_split会根据这个数组中的类别比例进行划分。示例:
假设我们有一个数据集,标签为y,其中0和1的比例是7:3(即70%的0,30%的1)。如果我们使用stratify=y,那么划分后的训练集和测试集中,0和1的比例都会是7:3。注意事项:
如果标签是离散的,那么分层划分是很有用的。对于连续型标签,通常不使用分层。当数据集中某个类别的样本数非常少时,分层划分可以确保在训练集和测试集中都有该类别的代表。
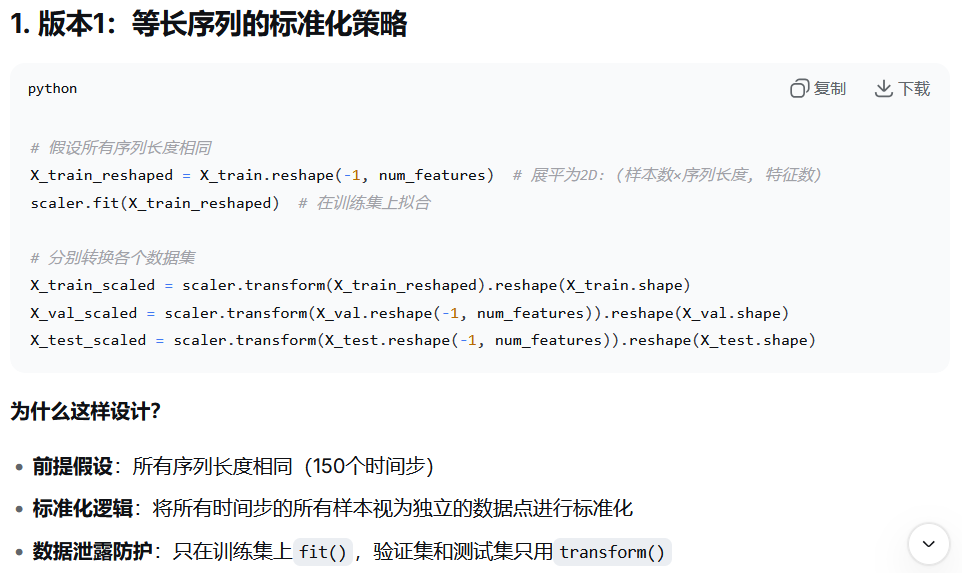
3. 特征缩放(仅在训练集上拟合,分别转换训练、验证和测试集)

210行:将所有训练集特征序列垂直拼接成到一起,返回一个(样本数*时间步,特征数)的二维数组。
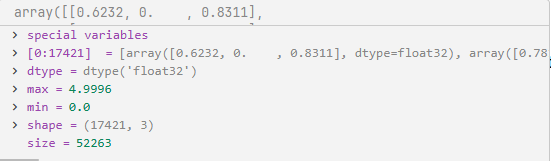
211行:在训练集上拟合scaler(计算均值和标准差)
214-216行:用这个拟合好的 scaler 来转换训练集、验证集和测试集。
其实我第一次做的时候犯了一个错误:在划分数据集之前就使用了全部数据来拟合 StandardScaler,好在debug的过程中我又调整过来了。
如果是相同的定长序列,可以将整个训练集(包括所有序列的所有时间步)重塑成一个二维数组(样本数*时间步,特征数),然后在这个二维数组上拟合一个标准化器(scaler)。然后,对训练集、验证集和测试集都使用这个标准化器进行转换。注意,这里验证集和测试集使用了训练集拟合的标准化器,这是正确的做法,避免了数据泄露。(在我们上一篇文章中的特征缩放部分就是这样做的https://blog.csdn.net/m0_59777389/article/details/154060500?spm=1011.2415.3001.5331)
训练集: fit + transform ✓ 验证集: transform ✓ 测试集: transform ✓ → 无数据泄露但是在这里我们的数据是变长序列,不能直接重塑成二维数组。因此,它首先将所有序列的所有时间步垂直拼接成一个二维数组(总时间步数,特征数),然后在这个二维数组上拟合标准化器。然后,对每个序列分别进行转换(因为每个序列长度不同,但特征数相同)。这里也是用同一个标准化器(基于所有序列的统计量)来转换每个序列,包括训练、验证和测试序列。
实际上,正确的做法是先划分数据集,然后仅在训练集上拟合 StandardScaler ,最后用这个拟合好的 scaler 来转换训练集、验证集和测试集。
如果在划分数据集之前就使用了全部数据来拟合 StandardScaler ,这会导致模型在评估时表现得过于乐观,因为验证集和测试集的信息已经泄露给了训练过程。
所有数据: fit + transform ✗ → 存在数据泄露!重要原则:永远不要在测试集(包括验证集)上拟合任何预处理器,标准化器、归一化器、PCA等都只能在训练集上拟合。

4. 序列填充和创建Tensor
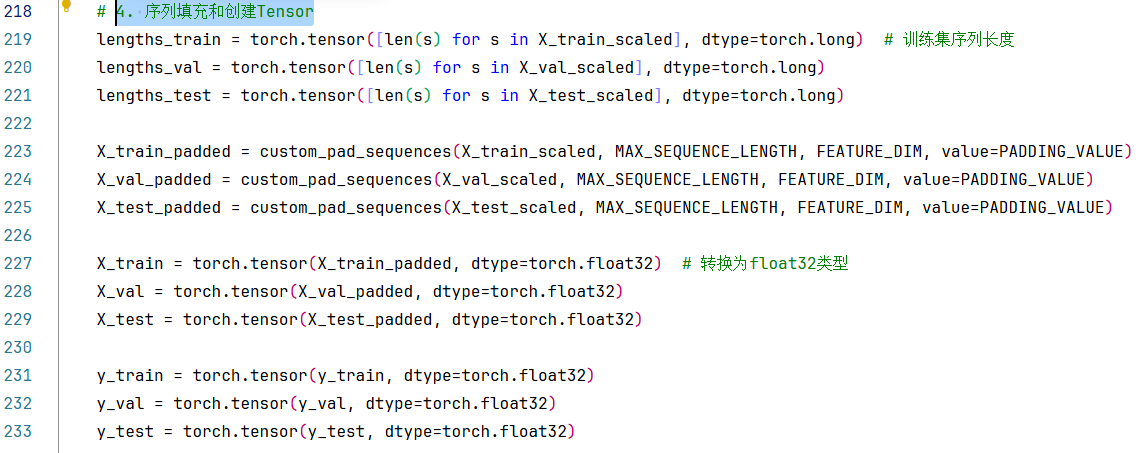
219-221行:分别获取到训练集、验证集、测试集的序列长度,这里指定了数值类型为更大长度的torch.long类型(长整型)
记住:在深度学习中最常用的是 torch.float32 和 torch.long(int64)!
对比一下python、numpy、pytorch中常用的数值类型(整数+浮点数)
1. Python内置数值类型
# Python 2 中有 long 类型 # Python 3 中只有 int 类型,自动处理大整数2. NumPy数值类型详解 NumPy提供了更精细的数值类型控制:
整数:
浮点数:
3. PyTorch数值类型
4. 类型转换
(Python内置转换)
(NumPy类型转换)
(PyTorch类型转换)
5.在实际项目中的选择建议
深度学习(PyTorch):
# 默认推荐 features = torch.tensor(X, dtype=torch.float32) # 特征数据 labels = torch.tensor(y, dtype=torch.long) # 分类标签 (int64) probabilities = torch.tensor(p, dtype=torch.float32) # 概率值# 原因: # - float32: 精度足够,内存节省,GPU计算效率高 # - long(int64): PyTorch索引要求int64科学计算(NumPy):
# 根据需求选择 image_data = np.array(pixels, dtype=np.uint8) # 图像数据 scientific_data = np.array(values, dtype=np.float64) # 高精度计算 large_arrays = np.array(data, dtype=np.float32) # 大数据集节省内存通用Python:
# 让Python自动处理 count = 100 # int price = 19.99 # float total = count * price # float6. 重要注意事项
精度问题:
溢出问题:
总结:
深度学习:默认使用
float32和int64科学计算:精度要求高用
float64,大数据用float32内存敏感:使用
float16、int8等小类型通用编程:让Python自动处理类型
始终检查:转换类型时注意精度损失和溢出风险
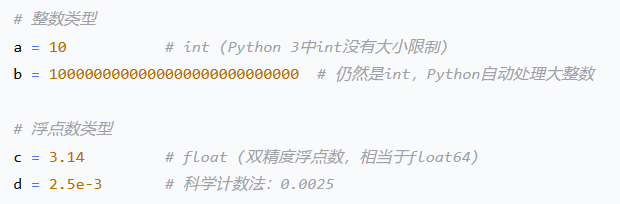








我们分别讨论Python、NumPy和PyTorch的默认数据类型。
Python:
int(无限精度),float(64位)NumPy:整数→
int64,浮点数→float64PyTorch:整数→
int64,浮点数→float32特别记住:PyTorch默认使用
float32而不是float64,这是为了深度学习的性能和内存效率考虑!Python:
整数:
int(无限精度)浮点数:
float(双精度,64位)NumPy:
整数:平台相关(32位系统:
int32,64位系统:int64)浮点数:
float64(双精度)PyTorch:
整数:
torch.int64浮点数:
torch.float32注意:PyTorch中,当你使用
torch.tensor函数从Python列表或NumPy数组创建张量时,它会推断数据类型。如果输入都是整数,则得到torch.int64;如果输入有浮点数,则得到torch.float32。PyTorch的一些张量创建函数(如
torch.zeros、torch.ones)默认整数类型默认也是torch.int64,浮点类型默认也是torch.float32。为什么PyTorch默认用float32?
# 1. 内存效率 # 2. 计算效率 - GPU对float32优化更好 # 3. 深度学习通常不需要float64的精度 # 4. 业界标准 - 大多数深度学习框架默认使用float32
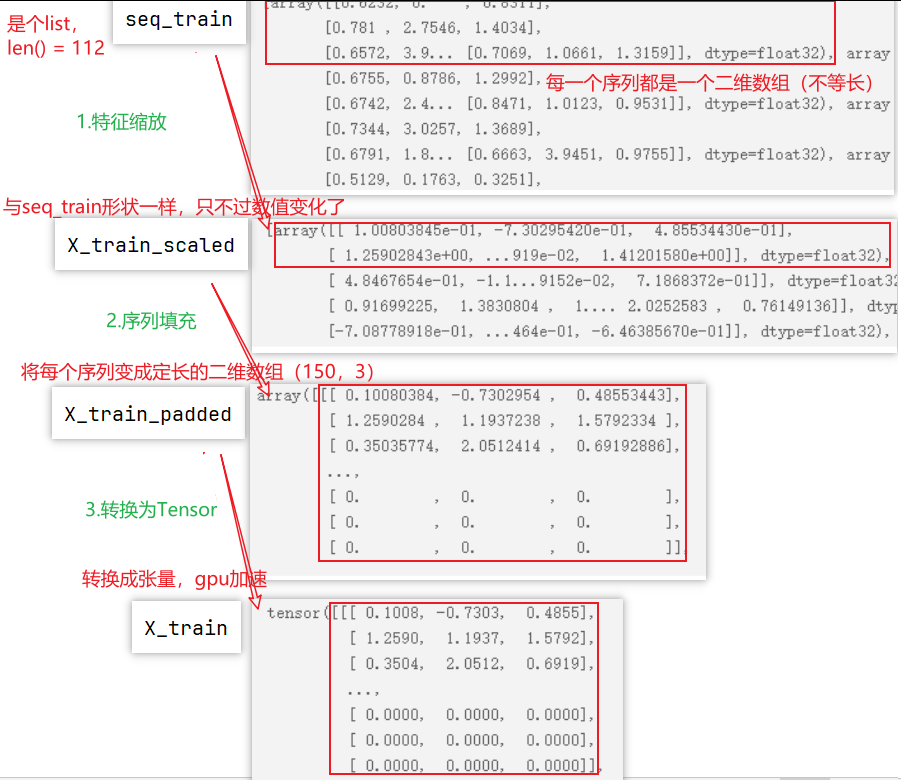
223行:custom_pad_sequences()方法:实现序列填充(padding)和截断(truncating),用于处理神经网络中变长序列输入,使其具有相同的长度。方法实现如下图所示:
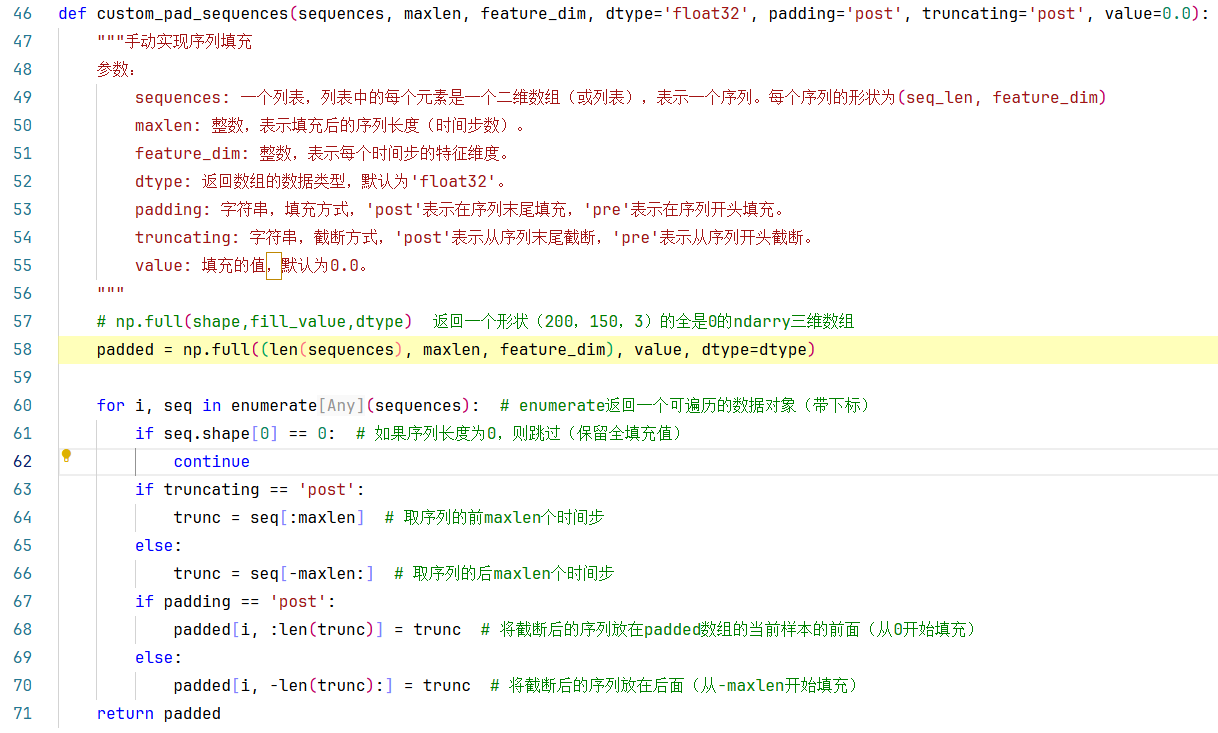
以X_train_padded为例,
第58行:返回一个形状(112,150,3)的,数值全是0的三维数组。
numpy.full(shape, fill_value, dtype=None):返回一个给定形状和类型的新数组,并用 fill_value 填充。
参数:
- shape:新数组的形状。
- fill_value:填充值。
- dtype:数组所需的数据类型。默认值 None 表示。
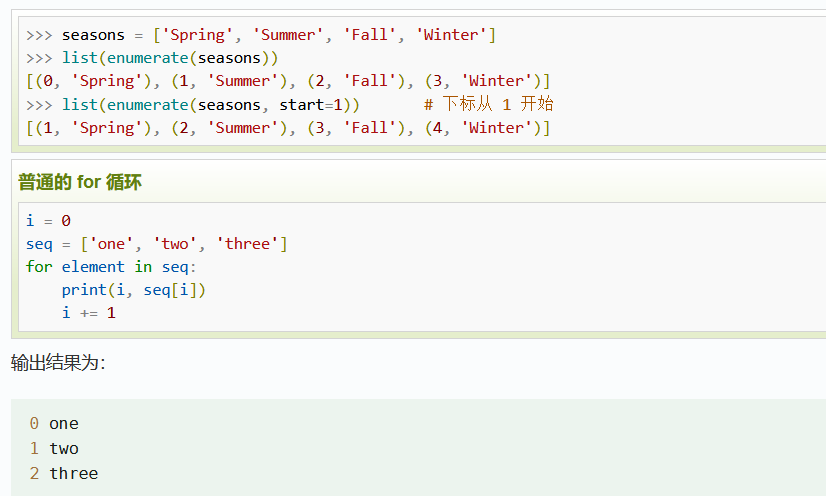
第60行:enumerate返回一个可遍历的数据对象(带下标)
enumerate() 函数用于将一个可遍历的数据对象(如列表、元组或字符串)组合为一个索引序列,同时列出数据和数据下标,一般用在 for 循环当中。
语法
enumerate(sequence, [start=0])
参数
- sequence -- 一个序列、迭代器或其他支持迭代对象。
- start -- 下标起始位置。
返回值
返回 enumerate(枚举) 对象。
60-71行:即循环遍历每一个序列(不等长),先使用seq[:maxlen]截取序列的前150个时间步(行),然后将上一步截断后的序列使用赋值语句padded[i, :len(trunc)] = trunc填充到padded数组中。
最后返回填充好的padded数组。
以训练集为例,下面画出变量的变化过程如下:
5. 创建DataLoader

这里使用的是torch.utils.data.TensorDataset(*tensors),TensorDataset是PyTorch提供的一个便捷的数据集类,用于将多个张量(tensors)包装成一个数据集。它要求所有张量的第一个维度(样本数量维度)大小相同。
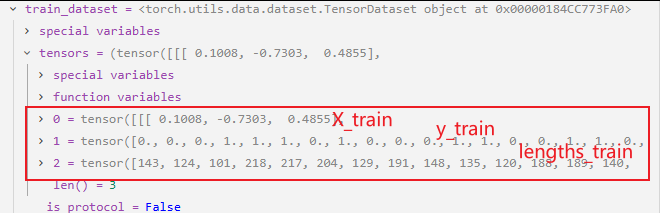
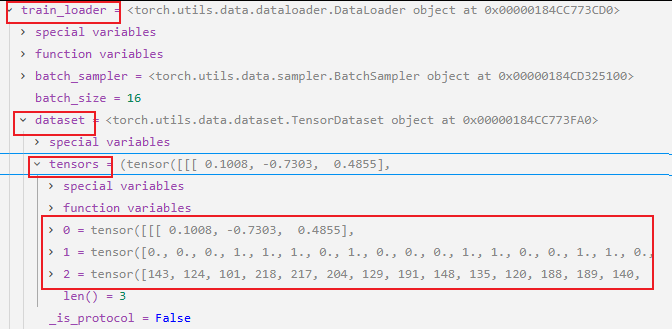
之前我们使用的都是Dataset,通过自定义一个MyDataset类(必须继承 DataSet ),并重写__init__、__getitem__、__len__三个方法,从而实现数据集的封装。
TensorDataset VS Dataset的区别?
torch.utils.data.TensorDataset 是PyTorch提供的一个便捷的数据集类,用于将多个张量(tensors)包装成一个数据集。它要求所有张量的第一个维度(样本数量维度)大小相同。
参数:
*tensors (Tensor): 可以传入多个张量,这些张量第一个维度必须大小相同。(通常用于包装特征张量(X)和标签张量(y))
返回值:
返回一个TensorDataset对象,可以通过索引访问,返回对应位置的各个张量的元素组成的元组。
与torch.utils.data.Dataset的区别:
torch.utils.data.Dataset是一个抽象类,用户需要继承这个类并实现__getitem__和__len__方法来创建自定义数据集。
TensorDataset是Dataset的一个子类,它已经实现了这些方法,适用于多个张量的简单情况。它提供了一种快速创建数据集的方式,而不需要自己编写Dataset类。
使用方式:
首先导入所需的库:torch 和 torch.utils.data.TensorDataset。
准备数据张量,确保每个张量的第一个维度相同。
使用这些张量创建TensorDataset实例。
可以将这个TensorDataset实例传递给DataLoader,以便进行批处理、打乱数据等操作。
# 1.简单情况 - 直接使用TensorDataset
X = torch.tensor([[1, 2], [3, 4], [5, 6]], dtype=torch.float32) y = torch.tensor([0, 1, 0]) dataset = TensorDataset(X, y)# 2.自定义Dataset:
from torch.utils.data import Datasetclass MyDataset(Dataset):def __init__(self, X, y):self.X = Xself.y = ydef __len__(self):return len(self.X)def __getitem__(self, idx):return self.X[idx], self.y[idx]# 使用自定义Dataset dataset = MyDataset(X, y)
TensorDataset:适合数据已经是张量形式的简单场景,使用方便
自定义Dataset:适合需要复杂数据处理、数据增强或非张量数据的场景

6. 构建和训练模型(重点)
训练模型之前需要先做的事情:
(1)定义LSTM模型。
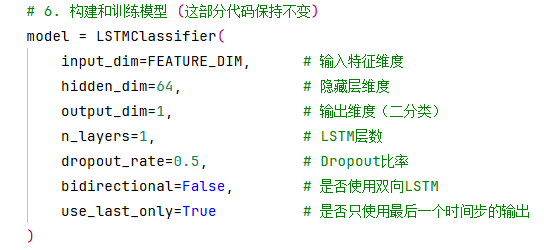
上面LSTMClassifier类的参数对应__init__构造函数的参数,如下:
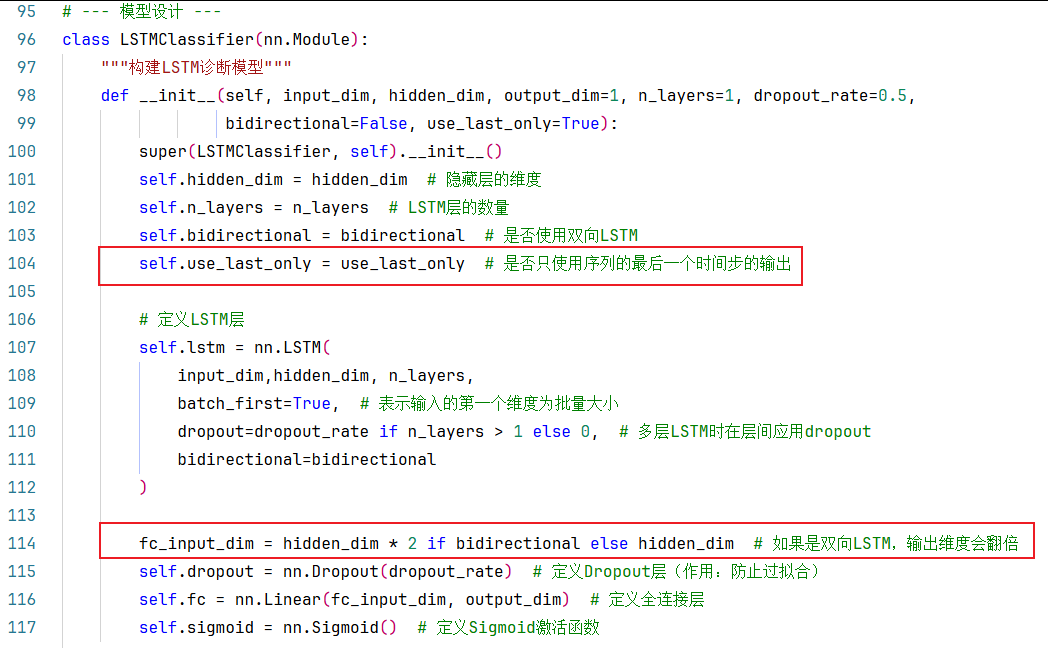
模型构建这部分与《LSTM模型做分类任务1》的文章没什么区别,唯一的区别就是这里对是否使用双向LSTM添加了if-else的判断处理,是更规范的写法,但是这里任然走的是单层单向的的LSTM这条路,所以都一样。
《LSTM模型做分类任务1》中的模型构建中的构造方法如下图:

(2)设置损失函数、优化器。

(3)将模型加载到GPU上,并打印模型。

(4)早停设置。

(5)用于记录每个epoch的损失值。

上面的属于是准备工作,接下来正式进入循环训练模型的阶段:
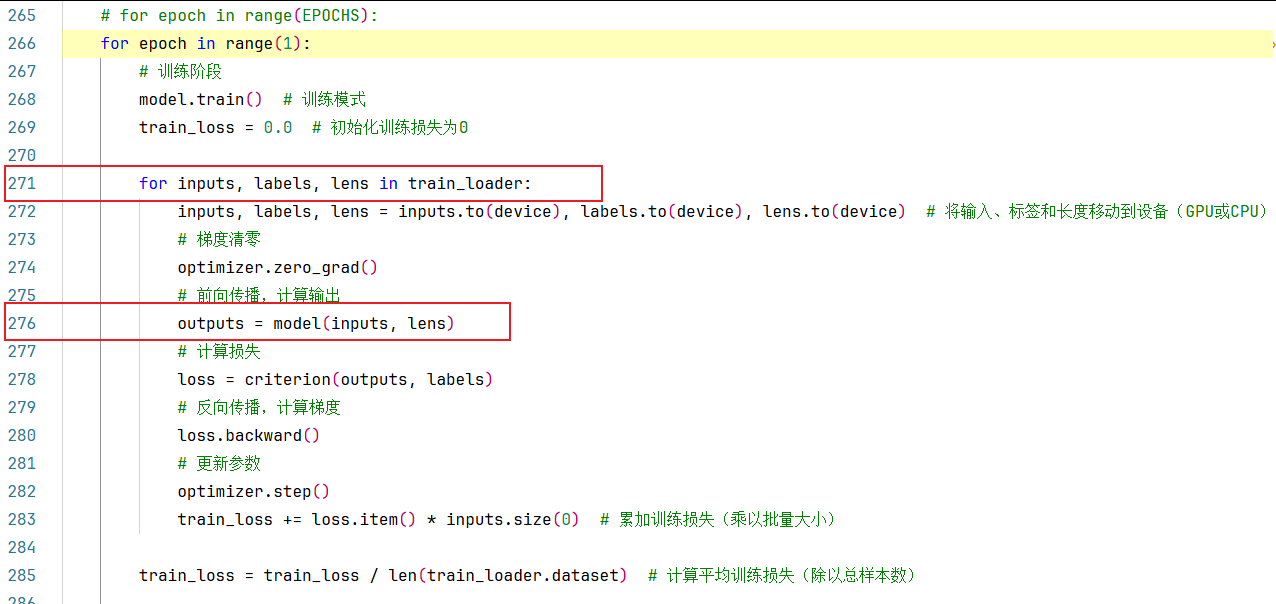
整体操作流程还是老一套,这里不再赘述,详细请见前面我写的文章。值得注意的是,有两点不同:
271行:这里train_loader返回的数据集包括3部分(特征+标签+序列长度),以前我们返回的都只有输入特征和标签两部分;
276行:这里前向传播模型输入的参数包括输入特征和序列长度,以前我们前向传播只将特征输入模型。
调式到276行时,我们步入一下,将会自动跳转到LSTMClassifier类的forward(self, x, lengths)方法中,代码如下:
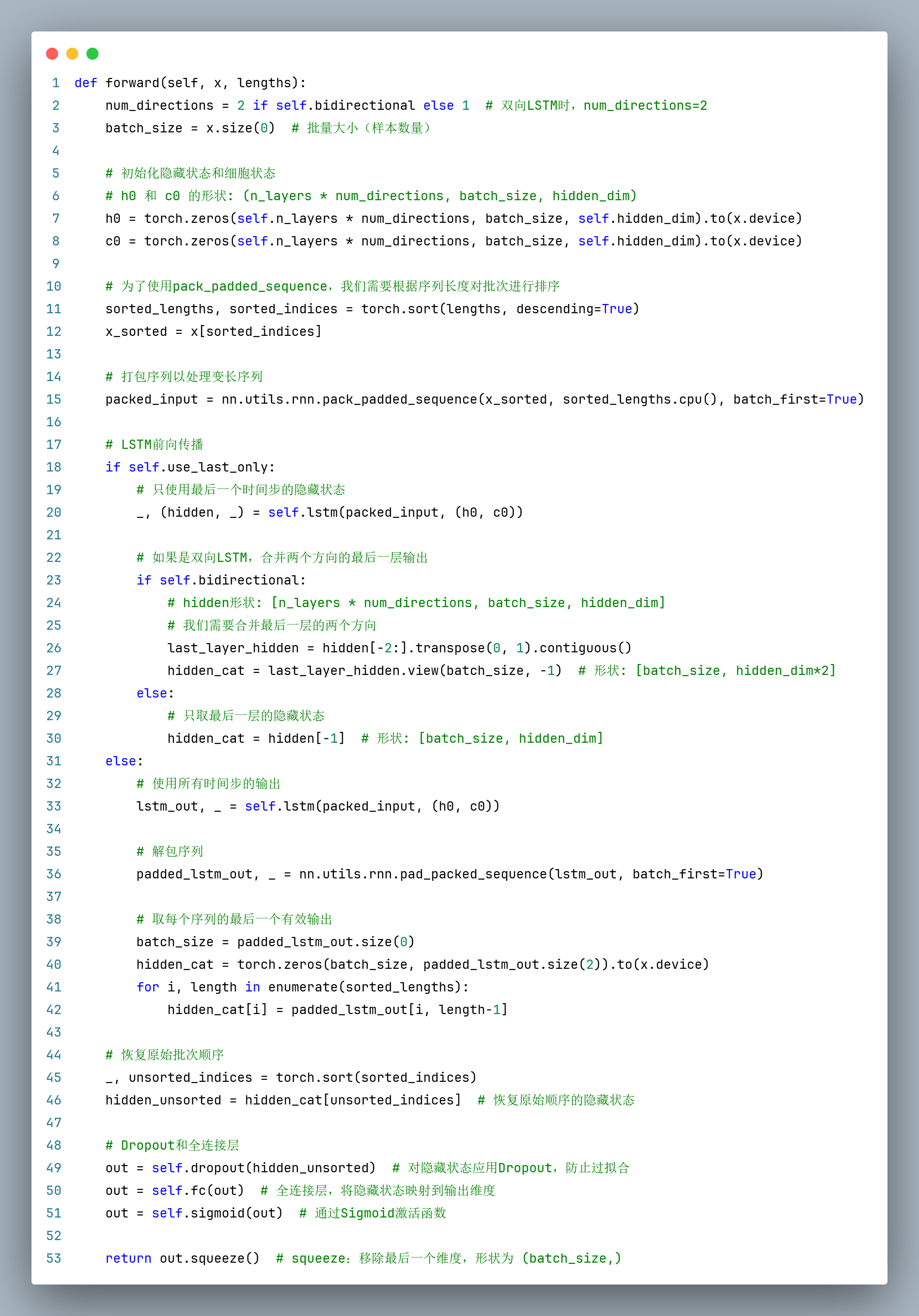
在第1-8行都是一些规范化的操作(因为在__init__构造函数中补充了self.bidirectional参数),虽然我的代码走的是单向的LSTM(bidirectional = False),但是这是更规范的写法。
第11-15行,在LSTM前向传播之前,使用pack_padded_sequence来处理变长序列,因此在forward函数中需要根据序列实际长度进行排序、打包等操作。
第11行:使用了 torch.sort()方法根据序列长度降序排序,返回了从大到小的长度序列
sorted_lengths,和对应的下标sorted_indices;
sorted_lengths:序列实际长度(降序)
![]()
sorted_indices:对应下标
![]()
第12行:将序列长度降序排序对应的下标sorted_indices应用到输入特征x(16,150,3)上即可返回排好序的x_sorted。
x_sorted:按照序列长度从大到小排序好的特征,x_sorted.shape(16,150,3)
第15行:打包序列以处理变长序列。

具体来说,pack_padded_sequence会做以下事情:
-
它接受一个填充后的序列张量(按长度降序排列)和每个序列的实际长度。
-
它将这些序列“打包”成一个PackedSequence对象,该对象将有效时间步连续存储,并记录每个序列的长度信息。
PackedSequence对象是啥?
PackedSequence对象:存储已打包序列的数据和 batch_sizes 列表。所有 RNN 模块都接受已打包序列作为输入。
注意:此类的实例不应手动创建。它们应由 pack_padded_sequence() 等函数实例化。
Batch_sizes 表示批次中每个序列步的元素数量,而不是传递给 pack_padded_sequence() 的可变序列长度。例如,给定数据 abc 和 x,PackedSequence 将包含数据 axbc,其中 batch_sizes=[2,1,1]。
变量:
data (Tensor) – 包含所有有效(非填充)元素的张量
batch_sizes (Tensor) – 每个时间步的有效序列数量
sorted_indices (Tensor, optional) – 包含此 PackedSequence 如何从序列构建的整数张量。
unsorted_indices (Tensor, optional) – 包含如何恢复具有正确顺序的原始序列的整数张量。
返回类型:
自我PackedSequence
想要搞明白打包->前向传播->解包的整个过程,请跳转:https://blog.csdn.net/m0_59777389/article/details/154486864?spm=1001.2014.3001.5501
在LSTM前向传播时,使用打包后的序列作为输入,LSTM会根据每个序列的实际长度处理,而忽略填充的部分。
在PyTorch中,我们通常按照以下步骤使用:
-
将输入序列按照长度降序排序(因为
pack_padded_sequence要求序列按长度降序排列)。 -
使用
nn.utils.rnn.pack_padded_sequence对排序后的序列进行打包。 -
将打包后的序列输入到LSTM中。
-
如果需要,可以使用
nn.utils.rnn.pad_packed_sequence将LSTM的输出重新转换为填充后的形式。
在代码中,我们首先对序列按照长度进行排序(从长到短),然后使用pack_padded_sequence打包。LSTM处理打包后的序列,并返回输出和隐藏状态。
注意:在使用pack_padded_sequence时,必须将序列长度放在CPU上,因此我们使用了.cpu()。但是,如果模型在GPU上,输入数据应该在GPU上,而长度仍然在CPU上。这是因为pack_padded_sequence函数要求长度张量在CPU上。
为什么要使用 pack_padded_sequence?
在自然语言处理或时间序列分析中,序列长度通常不一致。如果直接对填充后的序列进行 LSTM 计算:
会浪费大量计算资源在填充值上
可能影响模型性能(因为填充值没有实际意义)
nn.utils.rnn.pack_padded_sequence是为了让LSTM模型能够高效地处理变长序列。在自然语言处理或其他序列数据处理中,我们经常遇到不同长度的序列。为了批量处理这些序列,我们通常会对序列进行填充(padding)以使它们具有相同的长度。但是,在训练时(多次前向传播中),我们希望LSTM只处理实际的有效长度,而不处理填充的部分。
pack_padded_sequence函数的作用就是将填充后的序列打包,使得LSTM只在每个序列的实际长度上进行计算,从而节省计算资源并提高效率。packed_input = nn.utils.rnn.pack_padded_sequence(x_sorted, # 按长度排序后的输入序列sorted_lengths.cpu(), # 排序后的实际序列长度(必须在 CPU 上)batch_first=True # 输入数据的第一个维度是 batch_size )【具体例子说明】
假设我们有 3 个序列,最大长度为 5:
# 原始序列(batch_first=True 格式) # shape: [batch_size=3, max_length=5, feature_dim=2] sequences = torch.tensor([[[1, 2], [3, 4], [5, 6], [0, 0], [0, 0]], # 有效长度=3[[7, 8], [9, 10], [11, 12], [13, 14], [0, 0]], # 有效长度=4 [[15, 16], [0, 0], [0, 0], [0, 0], [0, 0]] # 有效长度=1 ], dtype=torch.float32)lengths = torch.tensor([3, 4, 1]) # 每个序列的实际长度步骤 1:按长度排序
# 按长度降序排序 sorted_lengths, sorted_indices = torch.sort(lengths, descending=True) # sorted_lengths = [4, 3, 1] # sorted_indices = [1, 0, 2]x_sorted = sequences[sorted_indices] # 重新排列序列 x_sorted = torch.tensor([ [[7, 8], [9, 10], [11, 12], [13, 14], [0, 0]], # 有效长度=4 [[1, 2], [3, 4], [5, 6], [0, 0], [0, 0]], # 有效长度=3 [[15, 16], [0, 0], [0, 0], [0, 0], [0, 0]] # 有效长度=1 ], dtype=torch.float32)步骤 2:打包序列
packed_input = nn.utils.rnn.pack_padded_sequence(x_sorted, sorted_lengths, batch_first=True )打包后的数据不再包含填充值,只保留有效数据:
实际数据(packed_input.data属性): [[7,8], [9,10], [11,12], [13,14], [1,2], [1,2], [5,6], [15,16]]批次信息(packed_input.batch_size属性): 时间步: 0 1 2 3 序列1: [batch1_step1, batch1_step2, batch1_step3, batch1_step4, 序列2: batch2_step1, batch2_step2, batch2_step3, 序列3: batch3_step1]时间步: 0 1 2 3
序列1: [[7,8]] --> [[9,10]] --> [[11,12]] --> [[13,14]]
序列2: [[1,2]] --> [[1,2]] --> [[5,6]] --> (结束)
序列3: [[15,16]] --> (结束) (结束)
打包后的data:
时间步0: [[7,8], [1,2], [15,16]] (3个序列)
时间步1: [[9,10], [1,2]] (2个序列)
时间步2: [[11,12], [5,6]] (2个序列)
时间步3: [[15,16]] (1个序列)batch_sizes: [3, 2, 2, 1]
在我的代码中,我设置了 use_last_only=True,这意味着:
# 我的代码逻辑: if self.use_last_only:# 只使用最后一个时间步的隐藏状态_, (hidden, _) = self.lstm(packed_input, (h0, c0))# 直接使用 hidden state,不需要解包
我的任务是恶意行为检测,这是一个序列分类问题:
-
输入:用户的行为序列
-
输出:整个序列是否是恶意的(0或1)
这种情况下,只需要序列的总体表征,所以使用最后隐藏状态是合适的。
什么时候只需要打包序列而不需要解包?什么时候需要解包?
什么时候不需要解包?
当你只需要LSTM的隐藏状态(最后时刻的隐藏状态,或者所有层的隐藏状态)而不需要每个时间步的输出时,你可以不使用解包。例如,在分类任务中,我们通常只关心最后一个时间步的隐藏状态。
分类任务:只需要序列的最终表示来做分类
序列级预测:整个序列只输出一个预测结果
只使用隐藏状态:LSTM 的隐藏状态已经包含了序列信息
什么时候需要解包?
当你需要每个时间步的输出时,比如在序列标注(命名实体识别、词性标注)或者编码器-解码器结构(如机器翻译)中,你需要解包来获取每个时间步的输出。
- 序列标注任务(每个时间步都需要输出)
- 编码器-解码器结构
- 注意力机制

其实上面的代码中我们设置了默认的的use_last_only=True,bidirectional=Flase,只会运行下面两行代码:
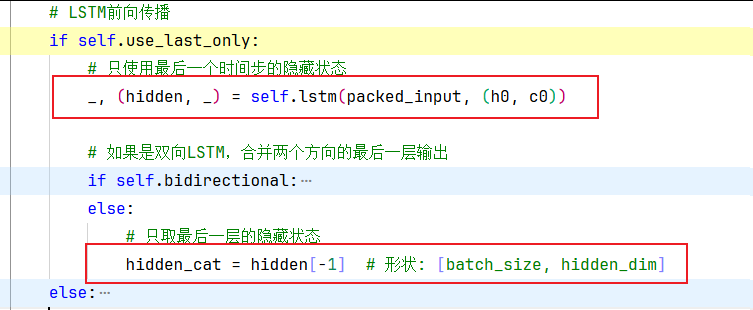
在前向传播的过程中,这里我们返回了每个序列中最后一个有效时间步的隐藏状态hidden,
【取最后一层的隐藏状态(推荐使用) VS 取每个序列的最后一个有效输出】
在PyTorch中,LSTM的输出包括两个部分:output和(hidden, cell)。其中:
output: 最后一层,每个时间步的隐藏状态(LSTM的最后一层),形状为(batch_size, seq_len, hidden_dim * num_directions)。如果是双向LSTM,则每个时间步的隐藏状态是前后向隐藏状态的拼接。
hidden: 每一层中,最后一个有效时间步的隐藏状态(可能包含多层),形状为(num_layers * num_directions, batch_size, hidden_dim)。注意,如果LSTM是双向的,那么最后一个时间步的隐藏状态实际上有两个(前向和反向),所以hidden的第一维是num_layers * num_directions。
在序列分类任务中,我们通常只关心整个序列的表示,然后用于分类。常见的方法有:
使用最后一个时间步的隐藏状态(即hidden的最后一层)作为整个序列的表示。
使用最后一个时间步的output(即output的最后一个时间步)作为整个序列的表示。注意,对于双向LSTM,最后一个时间步的output实际上已经包含了前向和反向的拼接,而hidden的最后一层则分别有前向和反向的最后一个时间步的隐藏状态,需要合并。
但是,由于我们使用了
pack_padded_sequence,所以LSTM的输出实际上只计算到每个序列的实际长度,因此:
对于output,我们通过
pad_packed_sequence解包后,会得到每个序列每个时间步的输出,但填充时间步的输出是0。因此,我们可以通过每个序列的实际长度来取最后一个有效时间步的输出。对于hidden,它已经包含了每个序列最后一个有效时间步的隐藏状态(注意,对于双向LSTM,每个方向最后一个有效时间步可能不同,但hidden会分别记录两个方向的最后一个有效时间步的隐藏状态)。
因此,两种方法都可以得到每个序列的表示。但是,它们可能不完全相同,尤其是在双向LSTM中,因为:
(取hidden的最后一层)会得到每个序列最后一个有效时间步的隐藏状态(双向的话是两个方向的拼接,但注意:双向LSTM中,前向的最后一个时间步是序列的最后一个有效时间步,反向的最后一个时间步是序列的第一个时间步)。
(取output的最后一个有效时间步)实际上和hidden的最后一层是等价的,因为LSTM的设计就是如此:hidden的最后一层就是每个序列最后一个有效时间步的隐藏状态。
在序列分类任务中(只关心最后一个时间步的隐藏状态),我们有两种选择:
方法1:先使用所有时间步的输出output,然后取最后一个有效时间步作为整个序列的表示。
# 使用所有时间步的输出,然后取最后一个有效时间步 lstm_out, _ = self.lstm(packed_input, (h0, c0)) padded_lstm_out, _ = nn.utils.rnn.pad_packed_sequence(lstm_out, batch_first=True)# 解包序列# 手动取每个序列的最后一个有效输出 for i, length in enumerate(sorted_lengths):hidden_cat[i] = padded_lstm_out[i, length-1]方法2(推荐):直接使用最后一个时间步的隐藏状态(即hidden的最后一层)作为整个序列的表示。
# 直接使用LSTM返回的隐藏状态 _, (hidden, _) = self.lstm(packed_input, (h0, c0)) hidden_cat = hidden[-1] # 取最后一层的隐藏状态(我这里本来就是单层)在理论上,对于标准的LSTM,这两种方法应该是等价的:
最后一个有效输出 = 最后一个时间步的LSTM输出
最后一层的隐藏状态 = 最后一个时间步的隐藏状态
在标准LSTM中,每个时间步的输出其实就是该时间步的隐藏状态。
那么,如何选择呢?
如果使用单向LSTM,那么两种方法得到的结果是一样的。
如果使用双向LSTM,那么两种方法也是等价的,因为双向LSTM的hidden state的前向部分就是最后一个时间步的隐藏状态,反向部分是第一个时间步的隐藏状态;而output的最后一个时间步也是将前向的最后一个时间步和反向的第一个时间步(即最后一个有效时间步)拼接起来。但是,注意:在双向LSTM中,取output的最后一个有效时间步和取hidden的最后一层(合并两个方向)是等价的。
所以,你可以根据代码的简洁性来选择。通常,直接使用hidden state更简单,因为它不需要解包output,也不需要循环取每个序列的最后一个有效时间步。
推荐使用方法2:使用hidden(直接取隐藏状态)
def forward(self, x, lengths):# ... 排序和打包代码 ...# 方法2:直接使用隐藏状态(更简洁高效)_, (hidden, _) = self.lstm(packed_input, (h0, c0))if self.bidirectional:# 双向LSTM的特殊处理(还需要手动合并两个方向的隐藏状态)last_layer_hidden = hidden[-2:].transpose(0, 1).contiguous()hidden_cat = last_layer_hidden.view(batch_size, -1)else:# 单向LSTM直接取最后一层hidden_cat = hidden[-1]# ... 后续处理 ...注意,对于双向LSTM,最后一个时间步的output实际上包含了前向和反向的拼接,而hidden的最后一层则分别有前向和反向的最后一个时间步的隐藏状态,需要合并。
什么时候会出现差异?
1. 双向LSTM(Bidirectional LSTM)
# 双向LSTM时,两种方法处理不同 if self.bidirectional:# 方法1:解包后取最后一个有效输出,已经包含了两个方向的信息last_output = padded_lstm_out[i, length-1] # [hidden_dim*2]# 方法2:还需要手动合并两个方向的隐藏状态last_layer_hidden = hidden[-2:].transpose(0, 1).contiguous()hidden_cat = last_layer_hidden.view(batch_size, -1) # [batch_size, hidden_dim*2]2. 多层LSTM(Multi-layer LSTM)
# 对于多层LSTM,最后一层的隐藏状态可能比第一层的输出包含更多高层特征 # 方法1:使用的是最后一层的输出 # 方法2:使用的也是最后一层的隐藏状态 # 在这种情况下两者是等价的3. 特殊LSTM变体
某些LSTM变体(如Peephole LSTM)可能在输出和隐藏状态之间有细微差异。

在上一篇文档中我是这样做的:

由于没有使用pack_padded_sequence,而是使用填充后的序列,然后直接取每个序列的最后一个时间步(即lstm_out[:, -1, :])。
# 这个方法有问题,因为它没有处理变长序列! last_lstm_out = lstm_out[:, -1, :] # 总是取第150个时间步
这种做法没有考虑序列的实际长度,这可能会引入噪声(可能会取到填充值,因为填充的时间步可能也有输出)。这是错误的!所以不推荐那样做。
在本文章中使用pack_padded_sequence,然后取hidden的最后一层作为序列表示。这是正确的做法,因为它考虑了序列的实际长度。
# 正确处理了变长序列 if self.use_last_only:# 方法2:直接使用隐藏状态_, (hidden, _) = self.lstm(packed_input, (h0, c0))hidden_cat = hidden[-1] else:# 方法1:解包后取最后一个有效输出# 这是备选方案,但方法2更优
但是,在本文档的代码处理中,我们有两种选择:
-
使用hidden的最后一层(即
hidden[-1],注意:对于双向LSTM则需要合并两个方向)。 -
使用output,通过解包后取每个序列的最后一个有效时间步(即通过循环,根据每个序列的实际长度取最后一个时间步的输出)。
这两种方法在数学上是等价的,因为LSTM的hidden state就是每个序列最后一个有效时间步的隐藏状态。
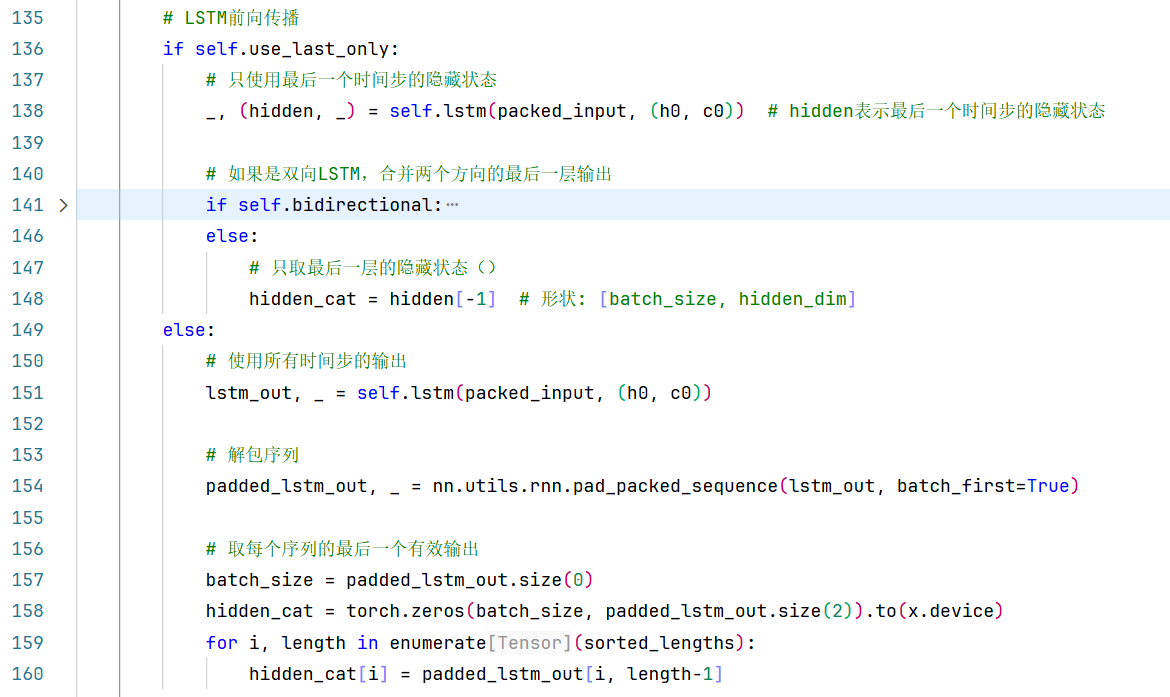
接下来我们总结一下,output,(hn,cn)=input(h0,c0)lstm每个参数的详细描述,并分别针对单层单向、多层单向、单层双向、多层双向举例子,链接请跳转:https://blog.csdn.net/m0_59777389/article/details/154486864?spm=1001.2014.3001.5501
经过前向传播之后,得到最后一层lstm、最后一个有效时间步的输出之后,需要对排序后的索引sorted_indices做一次降序排序,即可返回原始序列的索引,恢复原始顺序的隐藏状态。

接着后面就是跟原先的套路一样了,
先对隐藏状态应用Dropout(防止过拟合)、再加一个全连接层,将隐藏状态映射到输出维度、最后通过Sigmoid激活函数。
从取最后一层、最后一个有效时间步的隐藏状态->Dropout->全连接层->Sigmoid激活函数->最后返回out.squeeze(),如果想一步一步分析这个过程,那么请见:https://blog.csdn.net/m0_59777389/article/details/154060500?sharetype=blogdetail&sharerId=154060500&sharerefer=PC&sharesource=m0_59777389&spm=1011.2480.3001.8118
7.模型训练+验证
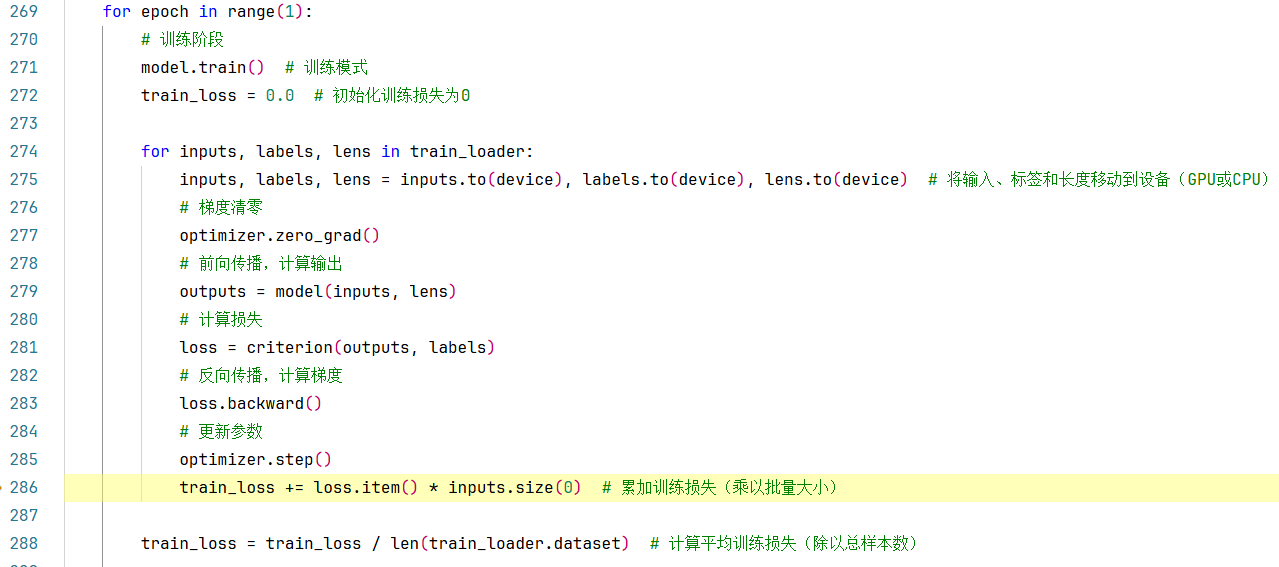
对于整体的模型训练过程,即:循环多轮进行,并在每一个Batch中分别进行:
(1)将输入特征、标签和长度移动到GPU上
(2)梯度清零 + 前向传播计算输出,并通过输出计算损失 + 然后反向传播,计算梯度,并更新参数
(3)累加每个batch批次的损失(乘以样本数)
每一次Epoch,计算一次平均训练损失(除以总样本数)。

对于整体的模型训练过程,即循环多轮进行,并在每一个Batch中分别进行:
(1)将输入特征、标签和长度移动到GPU上
(2)只进行前向传播计算输出,并通过输出计算损失
(3)累加每个batch批次的损失(乘以样本数)
每一次Epoch,计算一次平均验证损失(除以总样本数)
建议:

(1)在每一次Epoch的训练和验证过程中可以记录一下每个epoch的损失值(包括训练损失+验证损失),每迭代一轮都可以在控制台打印一下。当然,如果Epoch轮数上百上千次的话,也可以每10轮或每100轮打印一次,可根据你的任务适当调整。
另外,记录每个epoch的损失值,还可以在所有Epoch结束后,绘制出训练曲线和验证损失曲线,使用matplotlib.pyplot进行可视化。

(2)还可以在每轮后面加一个早停检查,如果连续N轮验证损失都没有改善,就可以提前停止训练了,不用再傻傻的一直等到最后一个Epoch结束了。

8.加载最佳模型并进行评估
一般的,模型测试过程只需要一次前向传播计算输出,然后将概率转换为类别 (0或1),再计算准确率就行了。比如上一个案例中的做法,如下图:
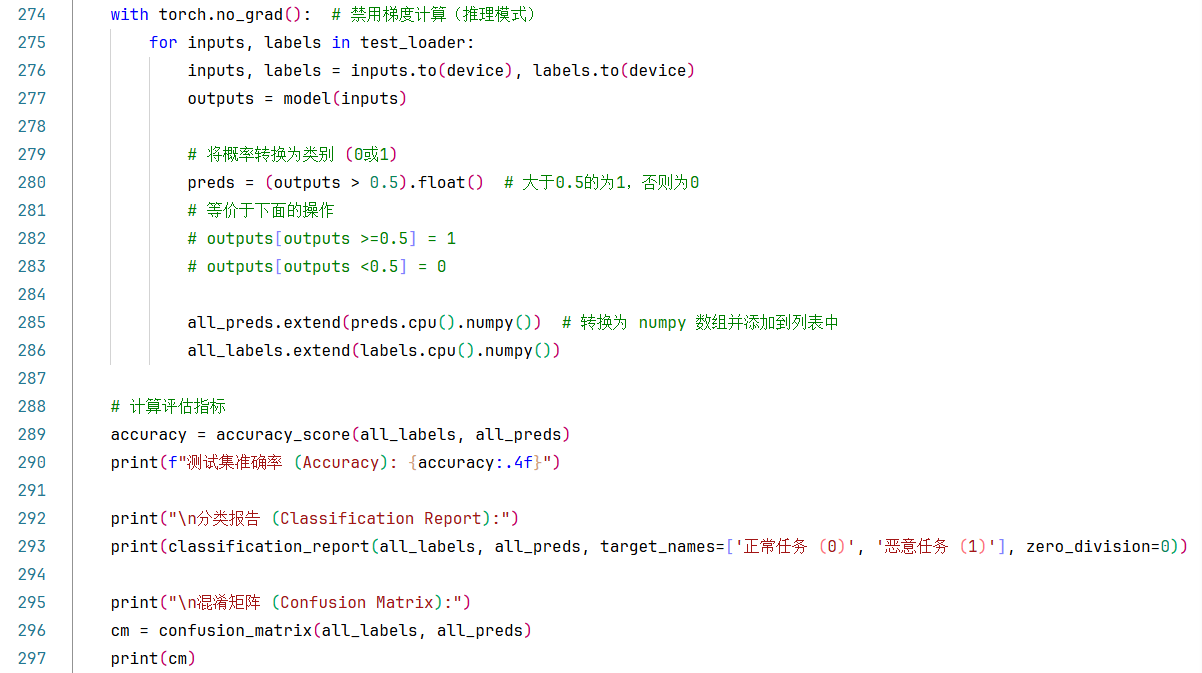
但是在本案例中,我不但让打印了测试损失,还将output输出的预测概率也保留下来了。如下图:
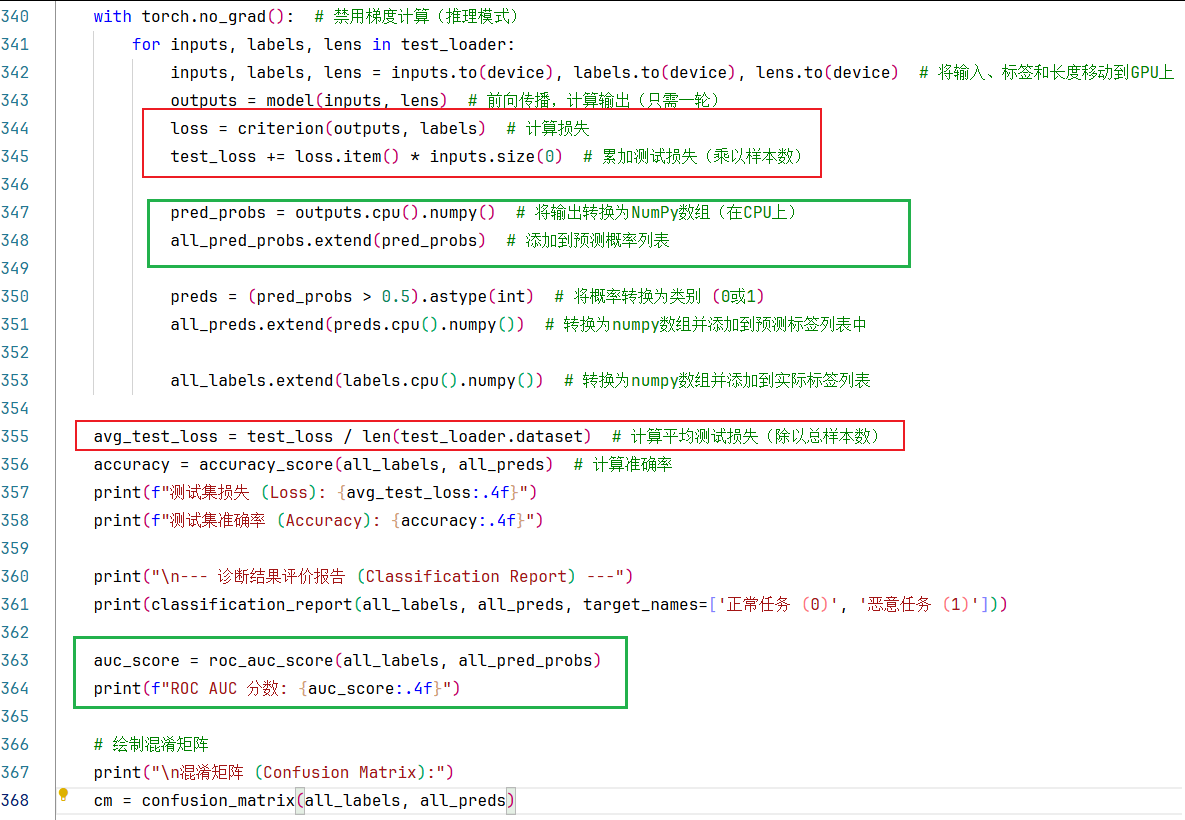
打印测试损失的目的是:为了与训练/验证损失对比,分析过拟合情况。
保留output输出的预测概率的目的是:为了计算ROC AUC 分数。
模型测试过程中计算测试损失是否是冗余操作?
我们通常会在训练和验证阶段计算损失,用于监控模型的学习过程和早停。
在测试阶段,我们通常关注的是模型在未见过的数据上的泛化性能,包括准确率、精确率、召回率、F1分数、AUC等指标。
损失值(例如BCELoss)在测试阶段并不是必须的,但有时也会计算并报告测试损失,以便与训练和验证损失进行比较,观察模型是否过拟合或欠拟合。
在测试阶段计算损失并不是冗余的,它可以帮助我们更全面地了解模型的性能。例如,如果测试损失远高于训练损失,可能表明模型过拟合了训练数据。但是,如果你只关心分类指标,那么不计算测试损失也是可以的。
在我的代码中,测试阶段计算了损失,但并没有使用这个损失值来做任何决策,只是打印出来。所以,从功能上讲,它确实是可选的。但是,从代码的完整性和调试的角度来看,计算测试损失并显示出来是有益的。
为什么测试阶段计算损失是冗余的:
测试阶段的目的:测试阶段主要是评估模型在未见数据上的最终性能,关注的是预测准确率、精确率、召回率等指标,而不是优化模型参数。
损失函数的用途:损失函数主要用于训练过程中的梯度计算和参数更新,在测试阶段没有反向传播,计算损失只是为了监控目的。
性能考虑:计算损失需要额外的计算资源,虽然不多,但在大规模测试集上还是有影响的。
例外情况:
如果出于以下目的,保留测试损失计算也是有意义的:
与训练/验证损失对比,分析过拟合情况
模型选择时比较不同模型的测试损失
学术研究需要报告测试损失
但在大多数生产环境和常规评估中,您的观点是正确的——测试阶段只需前向传播计算预测结果即可。
优化策略
以上实战案例整个代码的逻辑并未有任何错误,但是每次训练的过程中就会出现cuDNN error: CUDNN_STATUS_INTERNAL_ERROR的报错信息,刚开始我以为是因为我的电脑硬件太垃圾导致cuda带不动,或者是因为我的代码的问题(比如:损失函数或优化器选用的不合适)报错,(因为之前就出现过损失函数或优化器选用的不合适导致CUDA报误的)
首先我排除第一个原因,理由是:数据集并不大,不应该是我的显卡带不动的问题;另外cuda版本的问题也不太可能,我的版本挺新的。
报错原因应该就是后者。
具体报错信息如下:
(DL) C:\Users\21031>python Membership-Inference-Attacks\LSTM\train_lstm_model2_1.py
加载 200 个任务数据...
原始数据加载完成。
训练集样本数: 112, 验证集样本数: 28, 测试集样本数: 60
模型已移动到: cuda
LSTMClassifier(
(lstm): LSTM(3, 64, batch_first=True)
(dropout): Dropout(p=0.5, inplace=False)
(fc): Linear(in_features=64, out_features=1, bias=True)
(sigmoid): Sigmoid()
)
--- 开始训练 LSTM 诊断模型 ---
Epoch 1/100, Train Loss: 0.6851, Val Loss: 0.6798
Epoch 2/100, Train Loss: 0.6827, Val Loss: 0.6716
Epoch 3/100, Train Loss: 1.2191, Val Loss: 1.9855
Epoch 4/100, Train Loss: 1.7856, Val Loss: 2.4643
Epoch 5/100, Train Loss: 1.9352, Val Loss: 3.2572
C:\actions-runner\_work\pytorch\pytorch\pytorch\aten\src\ATen\native\cuda\Loss.cu:102: block: [0,0,0], thread: [0,0,0] Assertion `input_val >= zero && input_val <= one` failed.
C:\actions-runner\_work\pytorch\pytorch\pytorch\aten\src\ATen\native\cuda\Loss.cu:102: block: [0,0,0], thread: [1,0,0] Assertion `input_val >= zero && input_val <= one` failed.
C:\actions-runner\_work\pytorch\pytorch\pytorch\aten\src\ATen\native\cuda\Loss.cu:102: block: [0,0,0], thread: [5,0,0] Assertion `input_val >= zero && input_val <= one` failed.
C:\actions-runner\_work\pytorch\pytorch\pytorch\aten\src\ATen\native\cuda\Loss.cu:102: block: [0,0,0], thread: [9,0,0] Assertion `input_val >= zero && input_val <= one` failed.
C:\actions-runner\_work\pytorch\pytorch\pytorch\aten\src\ATen\native\cuda\Loss.cu:102: block: [0,0,0], thread: [15,0,0] Assertion `input_val >= zero && input_val <= one` failed.
Traceback (most recent call last):
File "C:\Users\21031\Desktop\myProject\Membership-Inference-Attacks\LSTM\train_lstm_model2_1.py", line 394, in <module>
main_train_model()
File "C:\Users\21031\Desktop\myProject\Membership-Inference-Attacks\LSTM\train_lstm_model2_1.py", line 307, in main_train_model
val_loss += loss.item() * inputs.size(0)
RuntimeError: CUDA error: device-side assert triggered
CUDA kernel errors might be asynchronously reported at some other API call, so the stacktrace below might be incorrect.
For debugging consider passing CUDA_LAUNCH_BLOCKING=1
Compile with `TORCH_USE_CUDA_DSA` to enable device-side assertions.
我将报错信息和代码发给Gemini之后,他告诉我:
这不是我的电脑硬件问题。
这是一个在 PyTorch 中非常经典的数值稳定性 (Numerical Stability) 问题,它是由你的模型架构和损失函数的组合方式引起的。
并分析了错误原因:
核心错误是
RuntimeError: CUDA error: device-side assert triggered,其根本原因是 CUDA 内核中的一个断言失败了:Assertioninput_val >= zero && input_val <= onefailed.这个错误的意思是:某个值本应在
[0, 1]的范围内,但实际上却超出了这个范围。为什么会发生这种情况?
损失函数的要求: 你使用的是
nn.BCELoss()(二元交叉熵损失)。这个损失函数要求它的输入(即模型的预测概率)必须在[0, 1]区间内。模型的输出: 你的
LSTMClassifier在最后使用了self.sigmoid = nn.Sigmoid()激活函数。理论上,Sigmoid函数的输出总是在(0, 1)范围内,这满足BCELoss的要求。问题的关键 (梯度爆炸):
观察你的训练日志:
Epoch 1/100, Train Loss: 0.6851, Val Loss: 0.6798 Epoch 2/100, Train Loss: 0.6827, Val Loss: 0.6716 Epoch 3/100, Train Loss: 1.2191, Val Loss: 1.9855 <-- 损失开始急剧增大 Epoch 4/100, Train Loss: 1.7856, Val Loss: 2.4643 Epoch 5/100, Train Loss: 1.9352, Val Loss: 3.2572从第 3 个 Epoch 开始,训练和验证损失(Loss)都急剧上升。这是梯度爆炸 (Exploding Gradients) 的典型迹象。
当损失变得非常大时,反向传播计算出的梯度也会变得极大。
这些极大的梯度会导致模型权重被更新到极端值,使得下一次前向传播时,
self.fc(out)(即Sigmoid层的输入)变为了inf(无穷大) 或NaN(非数字)。当
NaN被传入nn.Sigmoid()激活函数时,其输出仍然是NaN。最后,这个
NaN(非数字) 被传递给了nn.BCELoss()。BCELoss在 CUDA 上的实现检测到输入NaN并不满足[0, 1]的条件,于是触发了断言失败,导致程序崩溃。根本原因:
nn.Sigmoid()和nn.BCELoss()的组合在数值上是不稳定的,尤其是在梯度爆炸的情况下。给出了两种修复方案,并推荐同时使用它们,这会使模型训练更加稳健。
方案一:使用数值更稳定的损失函数 (首选)
PyTorch 提供了一个专门的损失函数
nn.BCEWithLogitsLoss,它在内部将Sigmoid和BCELoss结合在一起,并使用了数值稳定技术(如 log-sum-exp 技巧)来避免溢出。你需要做以下三处修改:
1.移除模型中的
Sigmoid层:在
LSTMClassifier类的__init__方法中,删除或注释掉这一行:# self.sigmoid = nn.Sigmoid()
在
LSTMClassifier类的forward方法中,删除或注释掉最后一步:# out = self.sigmoid(out)
2.更改损失函数:
在
main_train_model函数中,将损失函数的定义从BCELoss改为BCEWithLogitsLoss:# 原始代码
# criterion = nn.BCELoss()# 修改为
criterion = nn.BCEWithLogitsLoss()3.修改评估(测试)部分的代码:
因为模型现在输出的是原始 logits(未激活的值)而不是
[0, 1]的概率,所以在评估模型时,你需要手动添加Sigmoid来获取概率。在
main_train_model函数的评估部分(# 4. 加载最佳模型进行评估之后):# 找到这行 (大约在 369 行) # 原始代码: # pred_probs = outputs.cpu().numpy()# 修改为: (手动应用sigmoid) pred_probs = torch.sigmoid(outputs).cpu().numpy()方案二:添加梯度裁剪 (推荐)
梯度裁剪是训练 RNN(如 LSTM)时防止梯度爆炸的标准做法。它会限制梯度的最大范数,防止它们变得过大。
1.在训练循环中添加梯度裁剪:
在
main_train_model函数的训练循环中,找到loss.backward()和optimizer.step(),在它们之间添加torch.nn.utils.clip_grad_norm_:
for inputs, labels, lens in train_loader:# ... (省略)loss = criterion(outputs, labels)loss.backward()# --- 添加梯度裁剪 ---torch.nn.utils.clip_grad_norm_(model.parameters(), max_norm=1.0) # (1.0 是一个常用的值, 你也可以尝试 0.5 或 5.0)# ---------------------optimizer.step()train_loss += loss.item() * inputs.size(0)总结:
- 你的代码逻辑和数据处理(如
StandardScaler的使用)是正确的。问题不在于逻辑,而在于Sigmoid + BCELoss组合的数值不稳定性。- 通过切换到
BCEWithLogitsLoss(方案一)和添加梯度裁剪(方案二),你的模型应该就能稳定训练,损失值也会恢复正常。