Elasticsearch-3--什么是Lucene?
Lucene是Apache软件基金会旗下的一个开源项目,是目前最流行的全文检索引擎工具包(不是完整的搜索引擎应用)。它为开发者提供了一套高效的索引构建、查询和文本分析功能,被广泛应用于搜索引擎、日志分析、企业级搜索等场景。
目前Lucene是许多知名搜索系统的底层引擎,如:
- Elasticsearch
- Solr
- LinkedIn Search
- Amazon CloudSearch
- Netflix Search
1、核心定义
Lucene是一个Java编写的全文检索引擎库,而非完整的搜索引擎。它提供了一个可扩展的架构,开发者可以基于Lucene构建自定义的搜索系统。
核心功能:
- 索引引擎:将文本数据转换为倒排索引(Inverted Index)。
- 查询引擎:支持复杂的全文搜索和过滤。
- 文本分析引擎:提供分词、词干提取、停用词过滤等文本处理功能。
示例:
简单说:
Lucene = 搜索引擎的“发动机”,你需要自己造一辆“车”来搭载它,如ES就相当于是一辆车。
2、历史与发展
- 起源:由Doug Cutting于2000年开发,最初托管在SourceForge。
- Apache项目:2001年加入Apache Jakarta项目组,成为其子项目。
- 版本演进:
- 1.4版(2004年):引入多项增强功能,奠定核心架构。
- 8.x版(近年):支持多语言、分布式索引、更高效的分词和查询优化。
- 多语言支持:通过社区扩展,Lucene已支持中文、日文、韩文等25种语言(如IBM Control Desk中的Lucene 8.5.2版本)。
3、核心概念(Key Concepts)
1、Document(文档)
- 最小数据单元,类似于数据库中的一行记录。
- 由多个Field(字段)组成。
java示例:
Document doc = new Document();
doc.add(new TextField("title", "Elasticsearch 入门", Field.Store.YES));
doc.add(new StringField("category", "search", Field.Store.YES));
doc.add(new LongField("timestamp", System.currentTimeMillis(), Field.Store.YES));
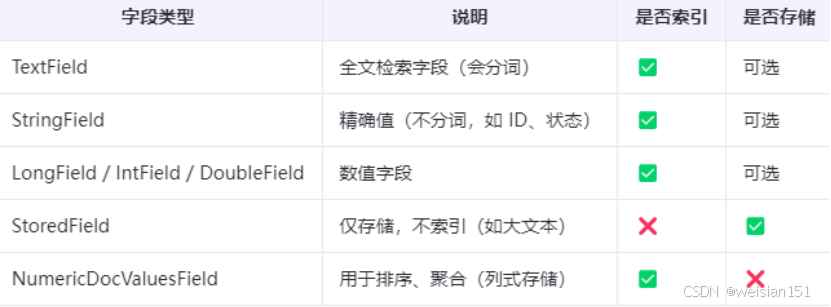
2、Field(字段)
文档的属性,不同类型决定如何索引和存储。
3、Index(索引)
- 包含多个文档的集合,类似于Mysql中的数据表。
- 物理上是一个目录,包含多个Segment(段)文件。
- 索引是只写一次、读多次的结构。
4、Segment(段)
- Lucene索引的基本单元。
- 每个Segment是一个独立的倒排索引。
- 不可变(Immutable):一旦生成,不再修改。
- 新数据写入时,会创建新Segment。
- 定期通过Merge(合并)优化性能。
5、Analyzer(分析器)
将文本转换为可索引的词项(Term)序列,是全文搜索的关键。
Analyzer核心组件:
1、Tokenizer(分词器):切分文本
- StandardTokenizer:按空格、标点切分
- WhitespaceTokenizer:按空格切分
- IKTokenizer(中文):智能分词
2、Token Filters(词项过滤器): - LowerCaseFilter:转小写
- StopFilter:去除停用词(如“的”、“了”)
- SnowballPorterFilter:词干提取(“running” → “run”)
示例:分析"Lucene is great!"
Tokenizer: [Lucene, is, great]
Filter: [lucene, great] → 去除"is"(停用词),转小写
4、核心功能
1、索引构建
-
倒排索引(Inverted Index):
- 将文档拆分为词条(Term),建立“词条 → 文档列表”的映射表。
- 示例:文档“The quick brown fox”拆分为词条[“the”, “quick”, “brown”, “fox”],每个词条指向包含它的文档。
-
索引结构:
- 段(Segment):独立的倒排索引单元,每次刷新(Refresh)生成新段。
- 合并(Merge):定期合并小段为大段,优化搜索性能并删除无效数据。
2、查询引擎
- 支持的查询类型:
- 基本查询:词项查询(TermQuery)、通配符查询(WildcardQuery)、模糊查询(FuzzyQuery)。
- 组合查询:布尔查询(BooleanQuery)、短语查询(PhraseQuery)。
- 高级查询:范围查询(RangeQuery)、正则表达式查询(RegexpQuery)。
- 相关性排序:基于TF-IDF(词频-逆文档频率)或BM25算法计算文档与查询的相关性评分。
3、文本分析
- 分词(Tokenization):将文本拆分为词条。
- 示例:英文分词器(Standard Analyzer)将“Hello World!”拆分为[“hello”, “world”]。
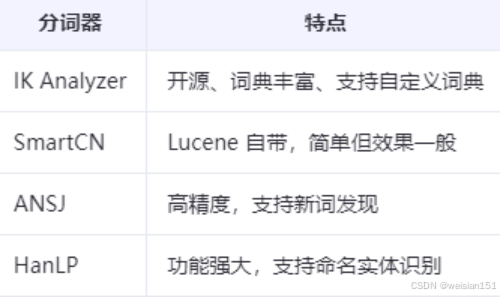
- 中文分词需依赖第三方库(如IK Analyzer、Jieba)。
- 过滤(Filtering):去除停用词(如“the”、“is”)、词干提取(如“running” → “run”)。
Lucene本身不支持中文分词,中文分词需依赖第三方Analyzer。
常用中文分词器:
5、技术架构
1、重点技术概念
(1)、IndexWriter
- 负责创建和更新索引。
- 数据写入内存缓冲区(RAM Buffer)后定期刷新到磁盘段(Segment)。
(2)、IndexReader - 读取索引数据,支持多线程访问。
(3)、IndexSearcher - 执行查询并返回匹配的文档。
(4)、Analyzer - 文本分析器,定义分词和过滤规则。
- 常见分析器:StandardAnalyzer(标准英文分析)、WhitespaceAnalyzer(按空格分词)。
2、数据写入流程
(1)、客户端调用IndexWriter.addDocument()添加文档。
(2)、文档经过Analyzer分词和过滤,生成词条。
(3)、词条写入内存缓冲区(RAM Buffer)和事务日志(Translog)。
(4)、定期刷新(默认1秒)生成新段(Segment),段合并(Merge)优化索引。
3、搜索流程
(1)、客户端提交查询(如QueryParser解析用户输入)。
(2)、IndexSearcher遍历索引段,执行匹配。
(3)、返回匹配文档的ID和相关性评分。
(4)、通过TopDocsCollector排序并返回结果。
6、工作原理:从数据写入到搜索
1、索引流程(Indexing)
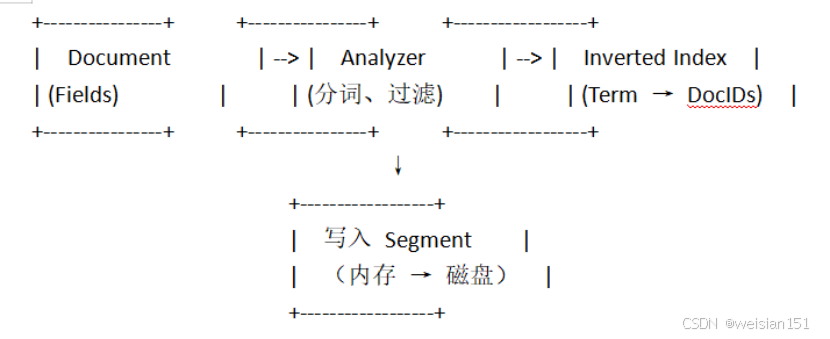
详细步骤:
1、文档解析:提取字段
2、文本分析:对TextField使用Analyzer生成词项
3、构建倒排索引:
- 记录每个词项出现在哪些文档中
- 记录位置(用于短语查询)、偏移(用于高亮)
4、写入Segment: - 先写入内存buffer
- 达到阈值后flush到磁盘,生成新Segment
5、合并Segment(Merge): - 定期将小Segment合并为大Segment
- 提升查询性能,减少文件句柄
2、倒排索引(Inverted Index)结构
假设文档:
- Doc1: “lucene search engine”
- Doc2: “search engine basics”
生成的倒排索引:
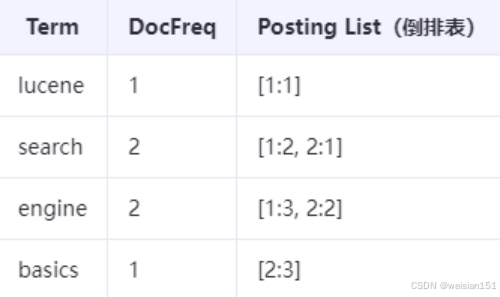
解释:
- DocFreq:包含该词的文档数
- [1:2]:文档1,位置2
- 支持TF-IDF、BM25等相关性评分算法
3、搜索流程(Searching)

支持的查询类型:
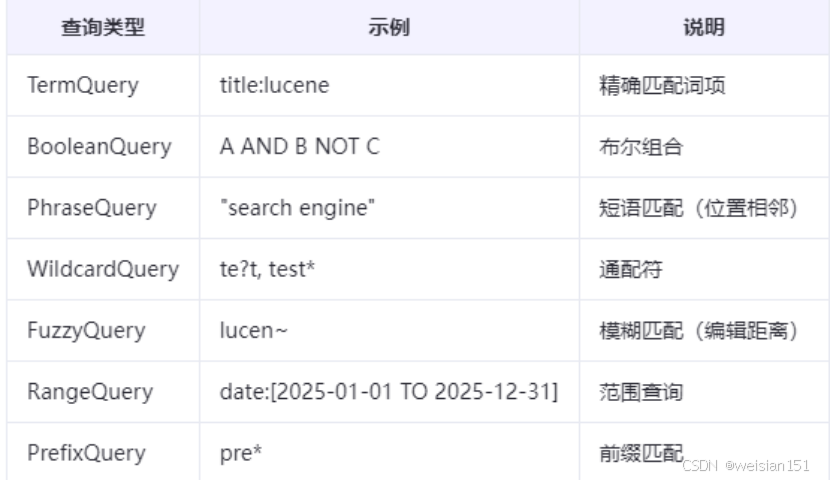
7、存储结构(文件系统)
Lucene索引目录包含多种文件类型。
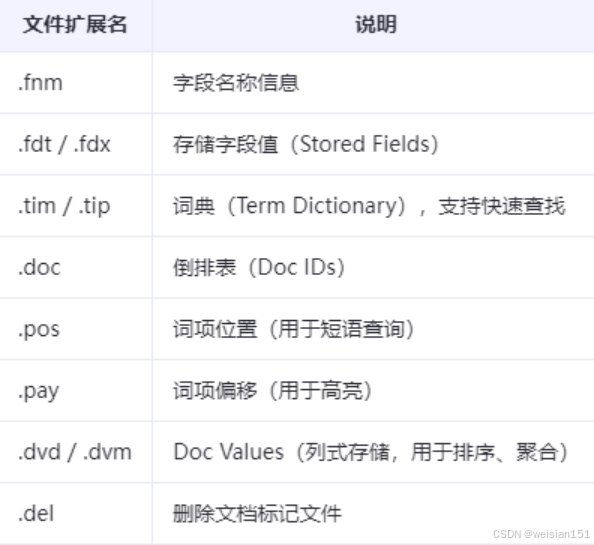
- 所有文件都是只读的(除了.del)
- Segment合并后,旧文件被删除
8、应用场景
1、企业级搜索
- IBM Control Desk:集成Lucene实现全球搜索、服务门户检索。
- 文档管理系统:支持PDF、HTML等格式的全文检索。
2、日志分析 - ELK Stack:Logstash将日志数据写入Elasticsearch(基于Lucene),Kibana可视化分析。
3、电商搜索 - 商品搜索功能,支持模糊匹配、拼写纠正(如“iphnoe” → “iPhone”)。
4、多语言支持 - Lucene 8.x支持25种语言,包括中文、日文、韩文、阿拉伯语等。
9、优势与挑战
优势:
- 高性能:倒排索引和分段机制支持毫秒级响应。
- 灵活扩展:开发者可自定义分词器、查询解析器和评分模型。
- 强大查询能力:布尔、模糊、短语、高亮
- 开源生态:丰富的社区资源和第三方扩展(如中文分词插件)。
- 跨平台:基于Java实现,支持多语言绑定(.NET、Python)。
- 多语言支持:通过插件支持中文、日文等
挑战:
- 复杂性:需手动管理索引、分词和查询逻辑。
- 资源消耗:内存和磁盘占用较高,需合理配置JVM参数。
- 分布式支持:Lucene本身是单机库,分布式功能需依赖上层框架(如Elasticsearch)。
10、Lucene查询语法
Lucene提供灵活的查询语法,支持以下操作符和查询类型:
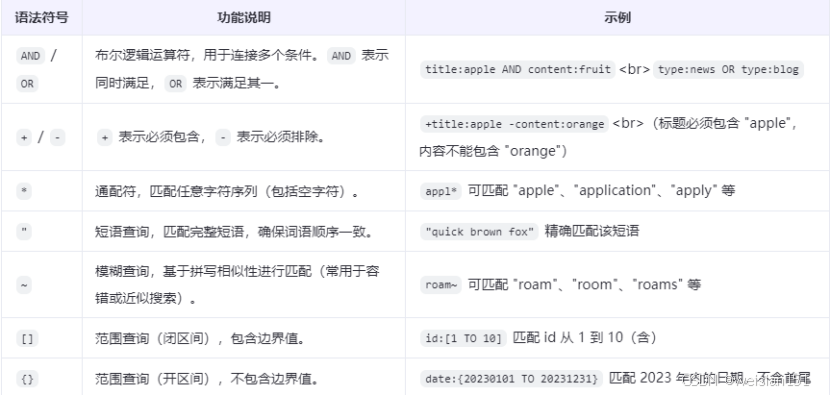
示例:
搜索词:Spacious, air-condition* +“Ocean view”
解析结果:
- 字词查询:spacious
- 前缀查询:air-condition*
- 短语查询:+“Ocean view”(必须包含该短语)
11、与Elasticsearch的关系
- Lucene是底层引擎:Elasticsearch基于Lucene构建,封装了分布式集群管理、REST API、实时分析等功能。
- Elasticsearch的扩展:
- 分布式分片与副本。
- 多租户与安全控制。
- 聚合分析(Aggregation)。
- 实时数据写入与近实时搜索(NRT)。
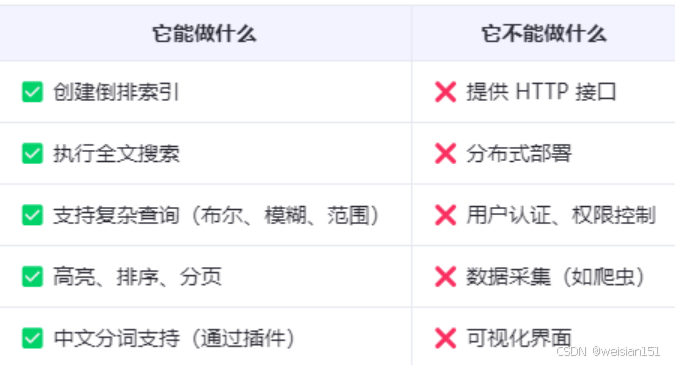
Lucene与Elasticsearch对比:
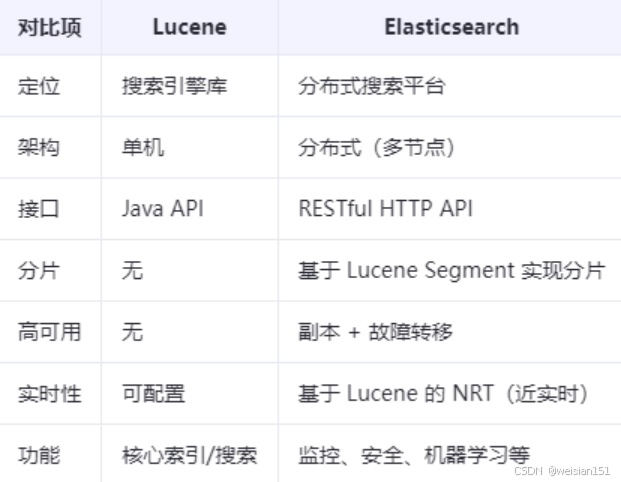
简单理解:
Elasticsearch = Lucene + 分布式协调 + REST API + 运维工具
12、实际案例
- IBM Control Desk:使用Lucene 8.5.2实现多语言搜索,支持25种语言。
- Azure认知搜索:基于Lucene查询语法提供高级搜索功能(如通配符、正则表达式)。
- 电商系统:集成Lucene实现商品搜索、拼写纠错、相关性排序。
13、总结
Lucene作为开源全文检索领域的基石,凭借其高性能、灵活性和丰富的功能,成为构建搜索系统的首选工具。它通过倒排索引 + 分词分析 + 高效存储,实现了毫秒级的全文检索能力。
尽管其本身是单机库,但通过与上层框架(如Elasticsearch)结合,可轻松扩展为分布式搜索引擎。无论是企业级搜索、日志分析还是多语言文本处理,Lucene都能提供强大的技术支持。