计算机网络自顶向下方法42——网络层 自治系统间路由选择:BGP 深度解析
我们开始深入解析将全球数以万计的自治系统粘合在一起的胶水——BGP。这是互联网能够成为一个真正“网”的核心所在。
自治系统间路由选择:BGP 深度解析
BGP是互联网的事实标准外部网关协议,是所有ISP之间进行路由通信的共同语言。理解BGP,就理解了互联网的骨架。
一、BGP 概述:互联网的“外交官”
1. 核心角色:在AS间传递可达性信息
-
内部 vs. 外部:OSPF、RIP等IGP负责AS内部的路由,像一个国家的国内交通系统。而BGP负责AS之间的路由,像国家间的外交官,互相通告“如何到达我这里的网络”。
-
路径向量协议:BGP不属于严格的距离向量或链路状态协议,它被归类为路径向量协议。它通告的不仅是距离,而是完整的AS路径。
2. BGP 的核心作用
-
获取子网可达性信息:BGP允许一个子网向互联网的其他部分通告它的存在:“我在这里,可以通过我所在的AS到达我”。
-
策略决策:这是BGP最强大也最复杂的地方。一个AS可以策略性地决定它向谁发送流量,以及从谁那里接收流量。这不仅仅是技术最优,更是商业最优。
-
基于策略的路由选择:BGP路由决策可以由任意策略决定,而不仅仅基于最短路径。这些策略考虑了政治、安全、商业和经济因素。
二、BGP 基础:会话与通告
1. BGP 会话
-
BGP连接被称为“BGP会话”,运行在TCP端口179上。使用TCP确保了BGP报文的可靠传输。
-
两种类型的会话:
-
eBGP:运行在不同AS的BGP路由器之间。用于在AS间交换路由信息。
-
iBGP:运行在同一AS内部的BGP路由器之间。用于确保AS内部的所有BGP路由器拥有一致的对外路由信息。
-
2. 通告BGP路由信息
-
BGP通告的内容:当一台BGP路由器通过eBGP会话学习到一条去往某IP前缀(如
138.16.0.0/16)的路由后,它会在AS内部通过iBGP共享,并可能通过eBGP通告给其他邻居AS。 -
通告的不是路径,而是“前缀 + BGP属性”:BGP通告的不是简单的下一跳,而是一个网络层可达性信息(包含IP前缀)和一系列BGP属性。最重要的属性之一是
AS-PATH。
3. BGP 属性
BGP路由的决策依赖于一系列属性,这些属性像标签一样附着在每条路由上:
-
AS-PATH:记录了该路由通告所经过的AS序列。例如,AS6431, AS7018, AS15169表示去往某个前缀,需要先经过AS6431,然后是AS7018,最后到达AS15169。-
作用1:防止环路。如果BGP路由器在收到的
AS-PATH中看到了自己所在的AS号,它会拒绝该路由,因为这形成了环路。 -
作用2:是路由选择算法的重要依据(通常偏好路径更短的)。
-
-
NEXT-HOP:这是一个微妙而关键的属性。它指示了到达该路由的下一跳边界路由器的IP地址。对于从eBGP对等体学来的路由,NEXT-HOP就是那个eBGP对等体的接口IP。
三、确定最好的BGP路由:复杂的决策过程
当一台BGP路由器从不同的邻居那里收到通往同一个IP前缀的多条路由时,它会执行一个多阶段的决策过程来选择“最佳”路由。
1. 热土豆路由选择
-
核心思想:“把烫手的土豆(数据包)尽快扔出你自己的AS”。它关注的是如何最小化本AS内部的流量开销。
-
工作机制:对于所有可用的BGP路由,路由器选择那个
NEXT-HOP路由器在本AS内“最近” 的路由。这个“最近”通常由AS内部的IGP(如OSPF)开销来衡量。 -
示例:一个ISP在纽约和旧金山都有入口点可以到达某个前缀。对于洛杉矶的一台路由器,它会选择通过旧金山入口的路由,因为数据包在它自己的AS内部传输到旧金山比到纽约的开销更小。
-
本质:一种自私的路由策略,只优化自己的成本,不管数据包在后续AS中的路径如何。
2. BGP路由选择算法(决策过程)
如果热土豆路由选择后仍有多个选项,BGP路由器会按顺序应用以下规则,直到只剩下一条路由:
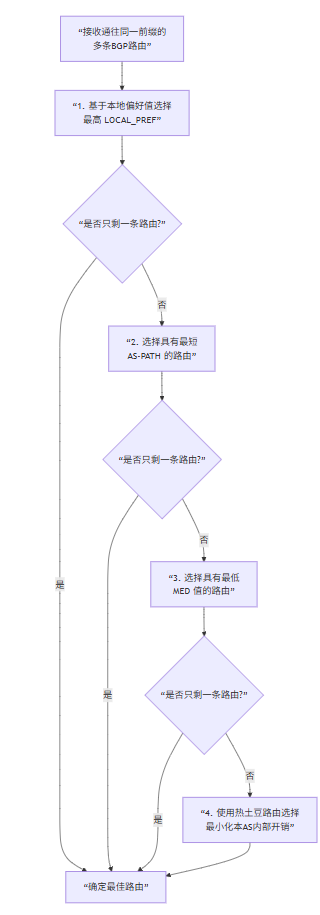
决策步骤详解:
-
本地偏好:这是最高优先级的属性,仅在同一AS内的iBGP对等体之间传递。网络管理员可以手动设置,以明确指示:“当有多个出口时,优先使用这个出口”。例如,优先使用高速、稳定的私有对等链路,而不是廉价的上行链路。
-
最短AS-PATH:在本地偏好相同或未设置的情况下,选择经过AS数量最少的路由。这是最直观的“最短路径”选择。
-
最低MED(多出口鉴别器):MED是一个提示性的属性,由一个AS发送给另一个AS,意思是:“如果你有多个入口点可以到达我,请优先使用这个”。接收AS在
LOCAL_PREF和AS-PATH都相同的情况下,会选择MED值最低的路由。 -
热土豆路由:如果以上所有条件都无法区分,则采用热土豆路由,尽快将数据包送出本AS。
-
如果仍有平局,则可能基于BGP Router ID等打破僵局。
四、BGP与IP任播
1. 什么是IP任播?
IP任播是一种网络寻址和路由技术,其中多个分布在不同地理位置的服务器共享同一个IP地址。数据包根据BGP路由,被路由到拓扑上“最近” 的那台服务器。
2. BGP如何实现任播?
-
通告相同前缀:所有提供相同服务的服务器(或它们前面的路由器)都向互联网通告完全相同的IP前缀(例如,一个DNS服务器的IP)。
-
BGP自然选择:BGP的路由选择算法(特别是热土豆原则和最短AS-PATH)会自动将用户的请求引导到通告该前缀的、拓扑最近的站点。
3. 任播的应用
-
根域名服务器和顶级域名服务器(如
a.root-servers.net)广泛使用任播,以提供极高的可用性和全球负载均衡。 -
大型CDN和云服务提供商:使用任播将用户请求导向最近的数据中心入口。
-
DDoS缓解:攻击流量会被分散到全球多个清洁中心。
五、路由选择策略:BGP的商业本质
BGP的配置本质上就是商业策略的体现。
1. 客户、提供商和对等体
一个ISP与其他AS的关系无外乎三种:
-
提供商:我付钱给它,它为我提供到互联网其他部分的流量传输。
-
客户:它付钱给我,我为它提供到互联网其他部分的流量传输。
-
对等体:我们互不收费,仅交换通往彼此客户的路由信息,以改善双方用户的互访质量。
2. 基于商业关系的策略示例
-
出口策略:
-
对客户:通告“我可以到达所有我知道的网络”(包括我的客户、对等体和提供商网络)。
-
对提供商:通告“我可以到达我自己的网络和我的客户网络”。不会通告从其他提供商或对等体学来的路由,因为我不想成为免费的“中转站”。
-
对对等体:通告“我可以到达我的客户网络”。仅此而已。
-
-
进口策略:
-
从提供商/对等体接收路由时:设置较低的
LOCAL_PREF。 -
从客户接收路由时:设置非常高的
LOCAL_PREF。这意味着:只要客户能到达的目的地,就优先通过客户链路发送,因为这是能带来收入的流量。
-
总结
BGP远不止一个技术协议,它是技术、商业和政治的混合体。
-
技术核心:通过路径向量和可靠的TCP会话,在AS间安全地交换可达性信息。
-
决策复杂性:其路由选择是一个多阶段过滤器,综合考虑了管理员策略、AS跳数和内部开销,其著名的热土豆路由策略旨在最小化自身成本。
-
商业本质:BGP配置直接反映了AS间的商业合同关系(客户、提供商、对等体),策略决定了流量的进出口。
-
强大应用:IP任播巧妙地利用了BGP的“最近”路由特性,实现了全球负载均衡和高可用服务。
正是BGP的这种灵活性和策略驱动特性,使得它虽然复杂,却成为支撑起一个多元化、竞争化、去中心化的全球互联网的唯一可行选择。
详解:为何需要区分AS间与AS内路由选择协议?
我们可以用一个生动的比喻来理解:
-
自治系统内部 像一个国家。
-
自治系统之间 像国际社会。
-
OSPF/RIP 等内部网关协议就像国家的国内法律和交通系统,追求高效、统一、可控。
-
BGP 这个外部网关协议就像国家间的外交规则和条约,讲究策略、协商、互利,并尊重各自的主权。
下面我们从多个维度进行深度解析。
一、核心目标与哲学的根本差异
| 维度 | 自治系统内部 | 自治系统之间 |
|---|---|---|
| 核心目标 | 性能最优化 | 策略控制与策略实现 |
| 设计哲学 | “合作” | “竞争与协作” |
| 信任模型 | 高信任度 | 低信任度 |
| 关注点 | 最小化延迟、最大化吞吐量、快速收敛 | 商业关系、安全、流量成本、政治考量 |
深入解释:
-
AS内部:通常由一个组织管理,所有设备都为共同目标服务。因此,路由协议的目标非常纯粹:找到最快、最短的路径,并在链路故障时尽快恢复(快速收敛)。这是一个工程最优化问题。
-
AS之间:由不同组织(ISP、公司)管理,各有各的利益。对于AS X来说,通过AS Y的路径即使延迟再低,但如果AS Y是它的竞争对手且收费高昂,AS X也宁愿选择另一个更友好、更便宜的AS Z。这是一个商业和政治决策问题。
二、技术尺度的巨大差异
| 维度 | 自治系统内部 | 自治系统之间 |
|---|---|---|
| 规模 | 相对较小(几十到几千台路由器) | 极其巨大(互联网包含数万个AS) |
| 拓扑变化 | 相对频繁(链路抖动、设备维护) | 相对稳定(AS间连接比较固定) |
| 可扩展性 | 分层设计是关键(如OSPF的区域) | 路径矢量和策略控制是关键 |
深入解释:
-
AS内部:使用链路状态协议(如OSPF) 是可行的,因为通过划分区域,可以将洪泛和计算限制在局部。路由器需要知道整个区域的拓扑细节,以便计算精确的最短路径。
-
AS之间:如果让全球所有AS都运行一个统一的链路状态协议,那么每次任何AS内发生任何变化,都需要洪泛到全球所有BGP路由器,这带来的控制平面流量和计算开销将是灾难性的,完全不可扩展。BGP的路径向量方式只传递“路径摘要”(AS序列),而不传递拓扑细节,完美解决了可扩展性问题。
三、策略与控制能力的刚性需求
这是最核心的区别。
-
AS内部:策略需求简单。通常只有基本的流量工程(如调整链路开销来引导流量)和安全过滤。管理员拥有绝对控制权。
-
AS之间:策略需求极其复杂,直接关系到运营商的生存。例如:
-
进口策略:“我从我的客户那里学来的路由,优先级最高;从对等体学来的次之;从上游提供商学来的优先级最低。” 因为来自客户的流量能赚钱。
-
出口策略:“我向我所有的邻居通告我客户的路由,但只向我客户通告我自己的和我的客户的路由,绝不把我的提供商或对等体的路由通告给其他人。” 避免成为免费的“中转站”。
-
BGP被设计成一种“可编程”的协议,它提供了丰富的属性(如 LOCAL_PREF, AS-PATH, MED, Communities),让管理员可以像写程序一样,精细地实现这些商业策略。而OSPF这类IGP根本不具备如此丰富的策略表达能力。
四、安全与信任模型的本质不同
| 维度 | 自治系统内部 | 自治系统之间 |
|---|---|---|
| 信任基础 | 所有路由器由同一机构管理,默认信任。 | 对方AS是另一个商业实体,不可默认信任。 |
| 主要威胁 | 配置错误、设备故障。 | 恶意路由注入、路由劫持。 |
| 协议机制 | 认证机制主要用于防止意外或内部误配置。 | 协议设计必须防范外部攻击。 |
深入解释:
-
AS内部:OSPF邻居之间通常有认证,但这更多是为了防止意外或内部问题。
-
AS之间:BGP设计时必须假设对方可能(无意或恶意地)发送错误路由。其
AS-PATH属性本身就是一个安全特性:它可以防止环路(看到自己的AS号就拒绝),并且让接收方可以看到路由的来源,从而基于来源做出策略决策。此外,现代BGP强烈推荐使用 RPKI 来验证对方通告的IP地址前缀是否真的属于它,以防御路由劫持。
总结:一种协议无法兼顾所有
让我们用表格来做一个最终的总结,清晰地展示为什么“一招鲜”行不通:
| 需求 | AS内部(如OSPF) | AS之间(如BGP) | 如果强行互换会导致 |
|---|---|---|---|
| 核心目标 | 性能最优 | 策略最优 | 要么无法实现商业目标,要么性能低下 |
| 规模适应性 | 通过分层支持成百上千路由器 | 通过路径摘要支持数万AS | 全球路由表洪泛,网络立即崩溃 |
| 收敛速度 | 秒级,追求快速 | 分钟级,追求稳定 | 要么AS内部动荡波及全球,要么AS间变化响应太慢 |
| 策略表达能力 | 弱(主要靠调整度量值) | 极强(多种属性、过滤器) | 复杂的商业关系无法实现,运营商无法盈利 |
| 安全模型 | 基于内部信任 | 基于外部不信任 | 极易遭受路由欺骗和劫持 |
结论:
互联网这种 “IGP处理国内事务,BGP处理外交事务” 的分层路由模型,是一种经过时间检验的、完美的职责分离。它允许每个AS独立地管理自己的内部网络(选择最适合自己的IGP),同时通过一个统一而灵活的外交语言(BGP)与外部世界进行复杂的、策略驱动的交互。这种设计赋予了互联网无与伦比的可扩展性、灵活性和鲁棒性。