【LLM】SmolLM3模型训练手册
note
- 一个可靠的评估任务应具备四个标准:单调性、低噪声、超随机性能和排名一致性。
- 模型的最终行为深受其在训练末期看到的数据的影响。因此,策略是:
- 在训练早期,使用丰富、多样化但质量稍低的数据(如网页文本)。
- 在训练末期(特别是在学习率衰减的「退火阶段」),引入稀缺、高质量的数据(如专业数学和代码数据集),以最大化其影响力。
文章目录
- note
- 一、Smol训练手册
- 1、什么时候需要微调
- 2、每一个大型模型都始于一个小型消融
- 3、设计消融实验
- 4、理解哪些有效:评估
- 5、模型架构
- 二、数据管理
- 三、2025年的后训练阶段
- 1、训练框架
- 2、聊天模版
- 四、基础设施
- 五、RLVR强化学习
- Reference
一、Smol训练手册
Hugging Face发布的214页《Smol训练手册》系统揭示了训练顶尖LLM的真实挑战与解决方案。核心分为四阶段:
1)战略决策需明确Why/What/How,通过"去风险"消融实验确定架构(如GQA注意力、共享嵌入层);
2)预训练采用多阶段课程,前期用海量通用数据打底,后期注入高质量数据;
3)大规模训练需攻克吞吐瓶颈(如本地存储优化)和隐蔽bug(如张量并行种子问题);
4)后训练通过SFT、mid-training和偏好优化打造混合推理能力。https://huggingface.co/spaces/HuggingFaceTB/smol-training-playbook#how-to-read-this-blog-post
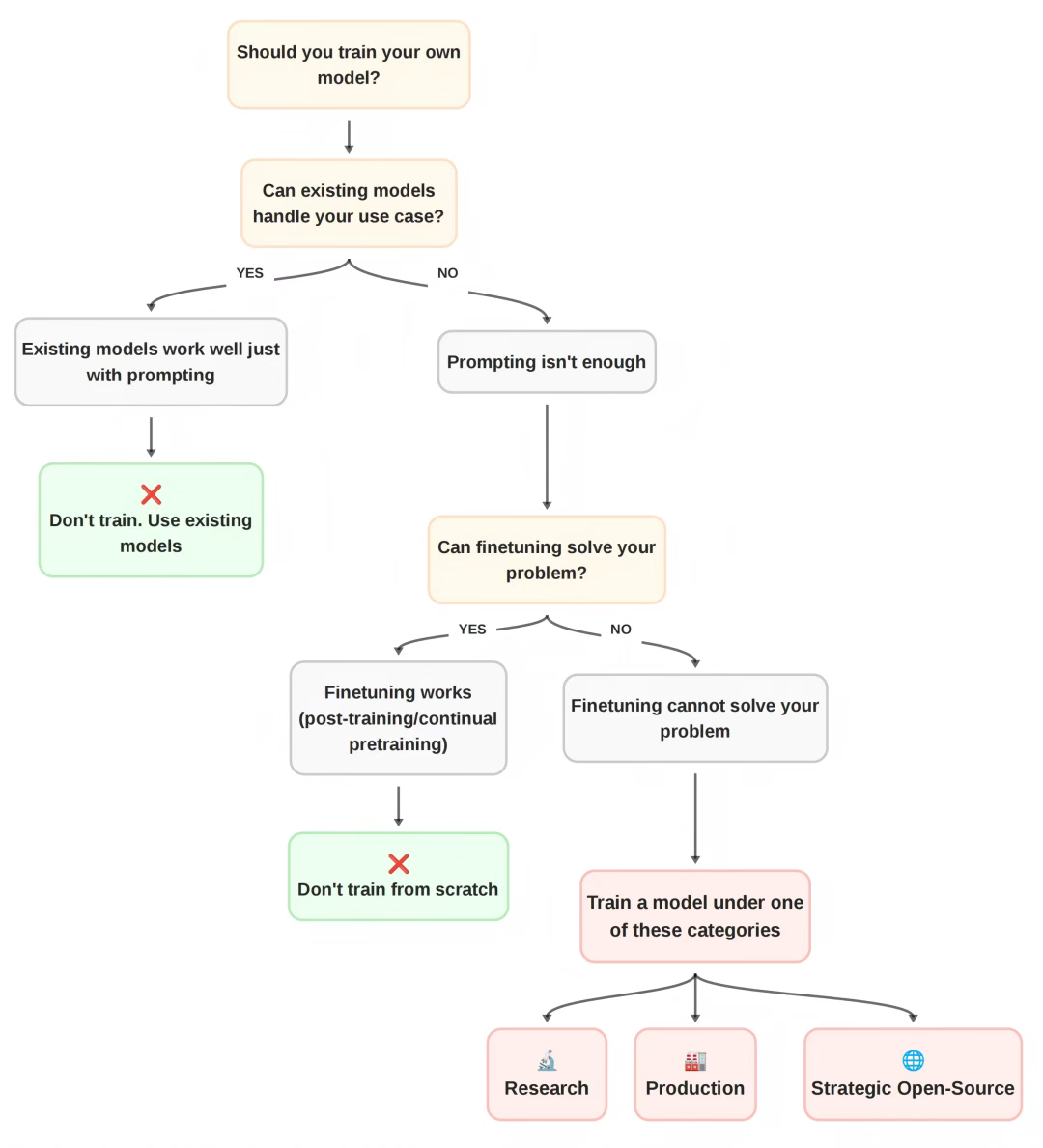
1、什么时候需要微调
一旦你明确了「Why」,就可以推导出「训练什么 (What)」。包括模型类型(密集型、MoE、混合型、某种新型)、模型大小、架构细节和数据混合。
同时前面的领域目标决定了你的训练决策:例如,为设备端运行 —> 训练小型高效模型;需要多语言能力 —> 使用更大的 tokenizer 词汇表;超长上下文 —> 混合架构。
这个决策过程分为两个阶段。规划:将你的约束(来自「Why」)映射到具体的模型规格;验证:通过系统性的实验(消融实验)来测试你的选择。
核心:迭代速度、数据管理
2、每一个大型模型都始于一个小型消融
在开始训练 LLM 之前,需要做出一系列关键决策(架构、优化器、数据组合等)。但很多时候LLM的行为是反直觉的,比如直接拿arxiv文章去SFT效果不一定好,因为过于专业化,可能会缺乏通用文本的多样性。所以LLM训练常需要做实验。
主流训练框架:
- Megatron-LM / DeepSpeed:功能强大,经过实战考验,但代码库庞大且复杂
- TorchTitan:更轻量级,易于上手和实验,但相对较新。
- nanotron (作者自研):提供了完全的灵活性,但需要大量投入来开发和测试。

3、设计消融实验
实验必须足够快(以便快速迭代)和足够可靠(结果能外推到最终模型),有两种主要方法:
- 全尺寸模型,少量数据: 使用最终模型的尺寸(如 SmolLM3 使用 3B 模型),但在更少的 Token 上训练(如 100B 而非 11T)。
- 小型代理模型: 如果目标模型太大(如 1T 参数),则使用一个按比例缩小的代理模型(如 3B 模型)进行实验。
4、理解哪些有效:评估
评估实验结果时,只看训练损失 (Loss) 是不可靠的。例如,训练维基百科的 Loss 更低,但不代表模型能力更强;更换分词器也会导致 Loss 无法直接比较。因此,必须使用更细粒度的下游评估。
一个可靠的评估任务应具备四个标准:单调性、低噪声、超随机性能和排名一致性。
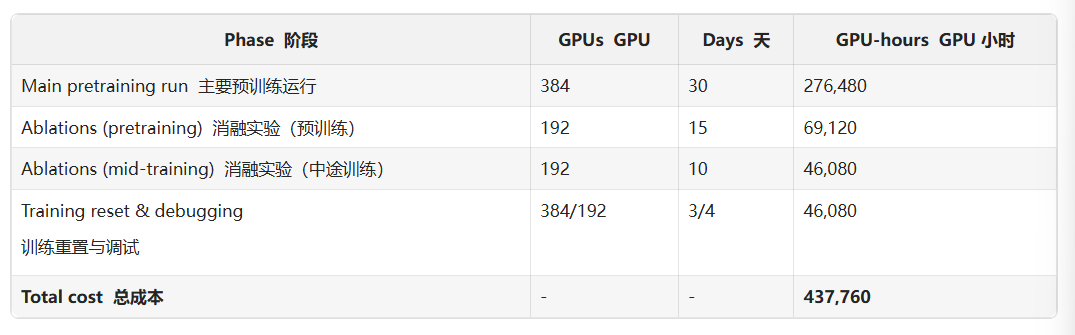
以 SmolLM3 为例,消融和调试所消耗的 GPU 时间超过了主训练运行的一半。
5、模型架构
- 注意力机制:这是推理时的主要瓶颈,关键在于 KV 缓存。文章对比了 MHA(标准,高内存)、MQA(极端压缩,可能损失性能)和 GQA(分组查询)。消融实验证实,GQA 在性能上与 MHA 相当,但极大节省了 KV 缓存,是 SmolLM3 的最终选择。
- 长上下文:文章探讨了两种策略。首先是文档掩码,在训练「打包」的数据时,它能防止模型关注到序列中不相关的其他文档,这被证实对长上下文扩展至关重要。其次是位置编码,标准 RoPE 在长序列上外推能力有限。SmolLM3 采用了 NoPE(实为 RNoPE)的混合策略,即交替使用 RoPE 层(处理短上下文)和 NoPE 层(处理长距离检索),消融实验表明这种方法在不牺牲短上下文性能的同时,为长上下文打下了基础。
- 嵌入共享:对于 SmolLM3 这样的小模型,嵌入层占比较大。文章通过消融实验证明,将参数用于增加模型深度(更多层)比用于「解绑」输入和输出嵌入层更有效。因此,SmolLM3 采用了嵌入共享。
- 稳定性:为防止大规模训练崩溃,文章测试了 Z-loss、QK-norm 等技术。最终,SmolLM3 采用了 OLMo2 的技巧,即移除嵌入层的权重衰减,以提高稳定性。
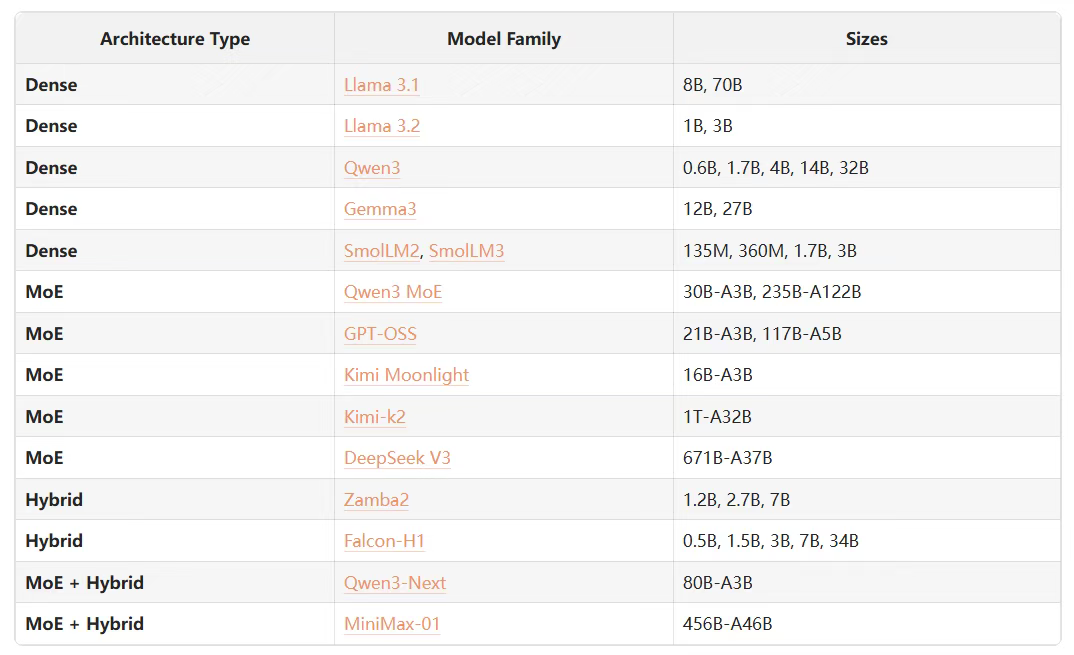
对比了密集型、MoE(混合专家)和 Hybrid(混合模型)三种架构。MoE 通过稀疏激活(只激活部分「专家」)来用更少的计算换取更大的容量,但内存占用极高。Hybrid(如 Mamba)则通过线性注意力或 SSM 来解决 Transformer 在长上下文上的计算瓶颈。SmolLM3 因其「端侧部署」的目标(内存受限)而坚持使用密集型架构。
还有常被低估的 Tokenizer。选择分词器涉及词汇量大小(影响压缩率和嵌入矩阵大小)和算法(BPE 最常用)。引入了「Fertility」(每词平均 Token 数)和「连续词比例」作为评估指标。通过对比 Llama3、Gemma3、Qwen3 等,SmolLM3 最终选择了 Llama3 的 128k 词汇表,因为它在目标语言和模型大小之间取得了最佳平衡。
二、数据管理
很多时候数据比模型修改还重要。
核心:
- 把控数据质量
- 混合数据的比例
- 为了解决这些平衡性问题,现代 LLM 训练已经从「静态混合」(如 GPT-3)演变为多阶段训练(如 Llama3、SmolLM2)。这种方法在训练过程中动态地改变数据混合比例。
- 确定数据配方的过程依赖于系统的消融实验。与架构不同,数据混合的消融实验必须在目标模型规模(例如 3B)上运行,因为模型的容量会显著影响它吸收不同数据的效果。
模型的最终行为深受其在训练末期看到的数据的影响。因此,策略是:
- 在训练早期,使用丰富、多样化但质量稍低的数据(如网页文本)。
- 在训练末期(特别是在学习率衰减的「退火阶段」),引入稀缺、高质量的数据(如专业数学和代码数据集),以最大化其影响力。
两种主要的实验方法:
- 从零开始的消融:使用目标模型(如 3B)进行短期训练(如 100B Token),以测试不同的初始混合比例。
- 退火实验:这是测试多阶段课程的关键。团队会从主训练中(例如在 7T Token 处)获取一个检查点,然后用新的数据混合(例如 40% 基线 + 60% 新数学数据)继续训练一小段时间(如 50B Token),以验证新数据在后期引入的有效性。
启动 SmolLM3 前执行的「起飞前检查」清单为例,包括基础设施准备、评测系统准备、Checkpoint 与自动恢复机制、指标日志记录、训练配置复核等。
三、2025年的后训练阶段
1、训练框架
想清楚:是否需要训练、是否有充足训练数据、评测标准是否明确。
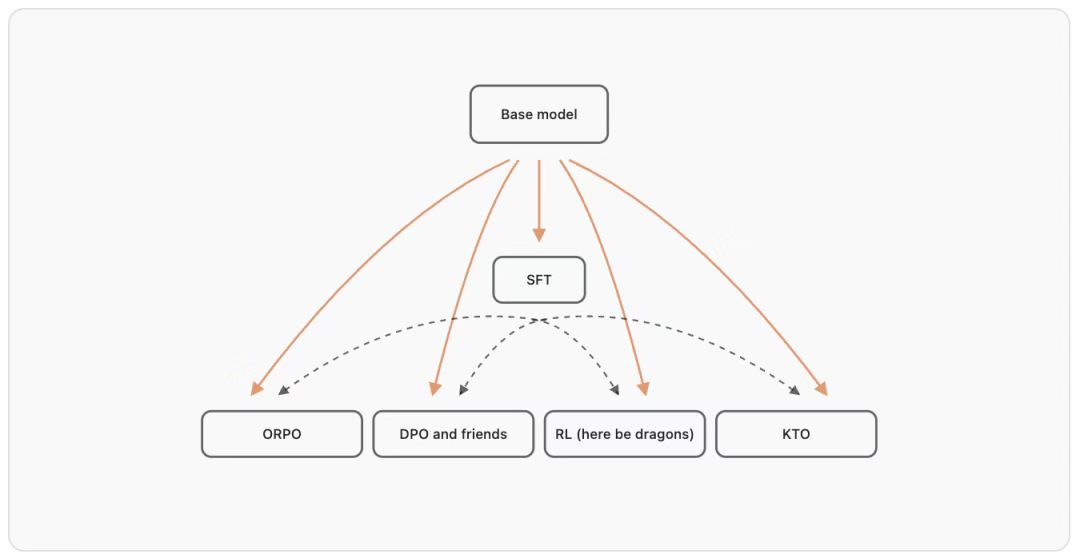
相关训练框架:

2、聊天模版
主流的template:
| Chat Template | System Role Customisation | Tools | Reasoning | Inference Compatibility | Notes |
|---|---|---|---|---|---|
| ChatML | ✅ | ✅ | ❌ | ✅ | Simple and good for most use cases. |
| Qwen3 | ✅ | ✅ | ✅ | ✅ | Hybrid reasoning template |
| DeepSeek-R1 | ❌ | ❌ | ✅ | ✅ | Prefills reasoning content with . |
| Llama 3 | ✅ | ✅ | ❌ | ✅ | Has built-in tools like a Python code interpreter. |
| Gemma 3 | ✅ | ❌ | ❌ | ❌ | System role customisation defined at the first user turn. |
| Command A Reasoning | ✅ | ✅ | ✅ | ❌ | Multiple chat templates per model. |
| GPT-OSS | ✅ | ✅ | ✅ | ✅ | Based on the Harmony response format. Complex, yet versatile. |
在大多数情况下,我们发现 ChatML 或 Qwen 的聊天模板是一个很好的起点。对于 SmolLM3,我们需要一个用于混合推理的模板,发现 Qwen3 是少数几个在我们关心的维度上取得良好平衡的模板之一。然而,它有一个我们并不完全满意的怪癖:除了对话的最后一轮之外,推理内容都被丢弃了。如下图所示,这类似于 OpenAI 的推理模型的工作原理:
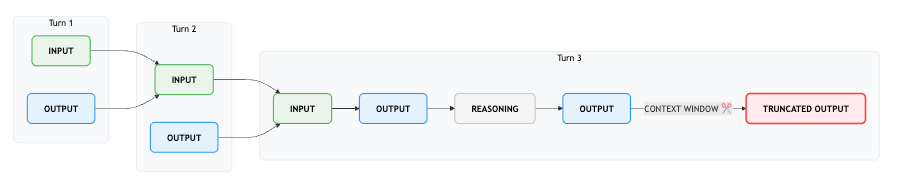
最终使用的template如下,支持代码代理,它执行任意 Python 代码,而不是进行 JSON 工具调用 :
{# ───── defaults ───── #}
{%- if enable_thinking is not defined -%}{%- set enable_thinking = true -%}
{%- endif -%}
{# ───── reasoning mode ───── #}
{%- if enable_thinking -%}{%- set reasoning_mode = "/think" -%}
{%- else -%}{%- set reasoning_mode = "/no_think" -%}
{%- endif -%}
{# ───── header (system message) ───── #}
{{- "<|im_start|>system\n" -}}
{%- if messages[0].role == "system" -%}{%- set system_message = messages[0].content -%}{%- if "/no_think" in system_message -%}{%- set reasoning_mode = "/no_think" -%}{%- elif "/think" in system_message -%}{%- set reasoning_mode = "/think" -%}{%- endif -%}{%- set custom_instructions = system_message.replace("/no_think", "").replace("/think", "").rstrip() -%}
{%- endif -%}
{%- if "/system_override" in system_message -%}{{- custom_instructions.replace("/system_override", "").rstrip() -}}{{- "<|im_end|>\n" -}}
{%- else -%}{{- "## Metadata\n\n" -}}{{- "Knowledge Cutoff Date: June 2025\n" -}}{%- set today = strftime_now("%d %B %Y") -%}{{- "Today Date: " ~ today ~ "\n" -}}{{- "Reasoning Mode: " + reasoning_mode + "\n\n" -}}{{- "## Custom Instructions\n\n" -}}{%- if custom_instructions -%}{{- custom_instructions + "\n\n" -}}{%- elif reasoning_mode == "/think" -%}{{- "You are a helpful AI assistant named SmolLM, trained by Hugging Face. Your role as an assistant involves thoroughly exploring questions through a systematic thinking process before providing the final precise and accurate solutions. This requires engaging in a comprehensive cycle of analysis, summarizing, exploration, reassessment, reflection, backtracking, and iteration to develop well-considered thinking process. Please structure your response into two main sections: Thought and Solution using the specified format: <think> Thought section </think> Solution section. In the Thought section, detail your reasoning process in steps. Each step should include detailed considerations such as analysing questions, summarizing relevant findings, brainstorming new ideas, verifying the accuracy of the current steps, refining any errors, and revisiting previous steps. In the Solution section, based on various attempts, explorations, and reflections from the Thought section, systematically present the final solution that you deem correct. The Solution section should be logical, accurate, and concise and detail necessary steps needed to reach the conclusion.\n\n" -}}{%- else -%}{{- "You are a helpful AI assistant named SmolLM, trained by Hugging Face.\n\n" -}}{%- endif -%}{%- if xml_tools or python_tools or tools -%}{{- "### Tools\n\n" -}}{%- if xml_tools or tools -%}{%- if tools -%}{%- set xml_tools = tools -%}{%- endif -%}{%- set ns = namespace(xml_tool_string="You may call one or more functions to assist with the user query.\nYou are provided with function signatures within <tools></tools> XML tags:\n\n<tools>\n") -%}{%- for tool in xml_tools[:] -%}{# The slicing makes sure that xml_tools is a list #}{%- set ns.xml_tool_string = ns.xml_tool_string ~ tool | string ~ "\n" -%}{%- endfor -%}{%- set xml_tool_string = ns.xml_tool_string + "</tools>\n\nFor each function call, return a json object with function name and arguments within <tool_call></tool_call> XML tags:\n<tool_call>\n{\"name\": <function-name>, \"arguments\": <args-json-object>}\n</tool_call>" -%}{{- xml_tool_string -}}{%- endif -%}{%- if python_tools -%}{%- set ns = namespace(python_tool_string="When you send a message containing Python code between '<code>' and '</code>' tags, it will be executed in a stateful Jupyter notebook environment, and you will then be given the output to continued reasoning in an agentic loop.\n\nYou can use the following tools in your python code like regular functions:\n<tools>\n") -%}{%- for tool in python_tools[:] -%}{# The slicing makes sure that python_tools is a list #}{%- set ns.python_tool_string = ns.python_tool_string ~ tool | string ~ "\n" -%}{%- endfor -%}{%- set python_tool_string = ns.python_tool_string + "</tools>\n\nThe state persists between code executions: so variables that you define in one step are still available thereafter." -%}{{- python_tool_string -}}{%- endif -%}{{- "\n\n" -}}{{- "<|im_end|>\n" -}}{%- endif -%}
{%- endif -%}
{# ───── main loop ───── #}
{%- for message in messages -%}{%- set content = message.content if message.content is string else "" -%}{%- if message.role == "user" -%}{{- "<|im_start|>" + message.role + "\n" + content + "<|im_end|>\n" -}}{%- elif message.role == "assistant" -%}{%- if reasoning_mode == "/think" -%}{{- "<|im_start|>assistant\n" + content.lstrip("\n") + "<|im_end|>\n" -}}{%- else -%}{{- "<|im_start|>assistant\n" + "<think>\n\n</think>\n" + content.lstrip("\n") + "<|im_end|>\n" -}}{%- endif -%}{%- elif message.role == "tool" -%}{{- "<|im_start|>" + "user\n" + content + "<|im_end|>\n" -}}{%- endif -%}
{%- endfor -%}
{# ───── generation prompt ───── #}
{%- if add_generation_prompt -%}{%- if reasoning_mode == "/think" -%}{{- "<|im_start|>assistant\n" -}}{%- else -%}{{- "<|im_start|>assistant\n" + "<think>\n\n</think>\n" -}}{%- endif -%}
{%- endif -%}
四、基础设施
像在训练 SmolLM3 时,使用了 384 块 H100 GPU,持续了将近一个月,总共处理了 11 万亿个 token,工程量之浩大。
GPU 数量 =训练所需总 FLOPs 单卡吞吐量 ×目标训练时间 =\frac{\text { 训练所需总 FLOPs }}{\text { 单卡吞吐量 } \times \text { 目标训练时间 }}= 单卡吞吐量 × 目标训练时间 训练所需总 FLOPs
其中:所需总 FLOPs,训练模型所需的计算量,取决于模型规模、训练 token 数量和架构设计;单 GPU 吞吐量,即每张 GPU 际每秒可执行的 FLOPs 数量;目标训练时长,就是你期望训练完成所需的时间。
ex:以 SmolLM3 为例,根据模型规模 30 亿参数、训练 token 数:11 万亿、目标训练时间约 4 周等信息,代入 GPU 需求公式得出的结果约为 379 GPUs。
这一计算结果指向了一个合理的范围:约 375–400 张 H100 GPU,而最后实际上是部署了 384 张 H100,这一规模既符合我们的并行化策略(parallelism strategy),也为训练中可能出现的节点故障、重启等意外情况预留了充足的缓冲空间,从而确保模型能在约 4 周时间内顺利完成训练。
五、RLVR强化学习
Reinforcement Learning with Verifiable Rewards (RLVR)
基于 RL 的训练的效率和稳定性在很大程度上取决于学习算法是on-policy还是off-policy。
GRPO 等方法通常属于on-policy算法类别,其中生成完成的模型(策略)与被优化的模型相同。虽然 GRPO 是一种on-policy的算法,但也有一些注意事项。首先,为了优化生成步骤,可以对几批代进行采样,然后 k 对模型进行更新,第一批是on-policy的,接下来的几批是稍微off-policy的。
由于从 LLM 生成自回归速度很慢,因此许多框架(如 verl 和 PipelineRL)添加了异步生成补全和模型权重的“动态”更新,以最大限度地提高训练吞吐量。这些方法需要更复杂和仔细的实施,但可以实现比同步训练方法高 4-5 倍的训练速度。正如我们稍后将看到的,这些训练效率的改进对于具有长尾token分布的推理模型来说尤为明显。
Reference
[1] ScaleRL: a massive flex from Meta to derive scaling laws for RL. Burns over 400k GPU hours to establish a training recipe that scales reliably over many orders of compute.
[2] DAPO: Bytedance shares many implementation details to unlock stable R1-Zero-like training for the community.DAPO:字节跳动分享了许多实现细节,为社区解锁稳定的 R1-Zero 类训练。
[3] LoRA without Regret: a beautifully written blog post which finds that RL with low-rank LoRA can match full-finetuning (a most surprising result)
[4] Dr. GRPO: one of the most important papers on understanding the baked-in biases with GRPO and how to fix them.Dr.GRPO:关于理解 GRPO 的固有偏见以及如何解决这些偏见的最重要的论文之一。