Flume安装部署
Apache Flume 1.9.0 实时采集数据到 HDFS 完整指南
本指南将详细介绍如何安装和配置 Apache Flume 1.9.0,使用 Netcat Source 接收数据,并通过 HDFS Sink 将数据实时写入 HDFS,并提供解决在 Hadoop 集成中常见的 Guava 库版本冲突问题的方法。
Ⅰ. Flume 环境搭建与准备
1. 软件上传、解压与重命名
将 Flume 压缩包上传至指定目录,并进行解压和重命名,保持环境整洁。
# 1. 上传文件 apache-flume-1.9.0-bin.tar.gz 到 /opt/software/ (手动操作)# 2. 解压文件到 /opt/module/ 目录下
tar -zxvf /opt/software/apache-flume-1.9.0-bin.tar.gz -C /opt/module/# 3. 修改解压后的文件夹名,方便后续引用
mv /opt/module/apache-flume-1.9.0-bin /opt/module/flume-1.9.0
2. 配置 Flume 运行环境
a. 配置 flume-env.sh 文件
进入 Flume 配置目录,复制模板文件并编辑,核心是指定正确的 JAVA_HOME 路径。
cd /opt/module/flume-1.9.0/conf
cp flume-env.sh.template flume-env.sh
vim flume-env.sh# 在 flume-env.sh 文件中添加或修改以下内容:
export JAVA_HOME=/opt/module/jdk1.8.0_261
b. 配置系统环境变量
为了能在任何目录下运行 flume-ng 命令,将 Flume 的 bin 目录添加到系统的 PATH 中。
# 在 ~/.bashrc 或 /etc/profile 文件中添加以下内容:
export FLUME_HOME=/opt/module/flume-1.9.0
export PATH=$PATH:$FLUME_HOME/bin# 使得配置立即生效
source ~/.bashrc # 或 source /etc/profile
c. 验证安装
flume-ng version
3. 安装 Netcat 工具
我们使用 Netcat (nc) 作为简单的数据发送工具,在测试环节模拟数据流。
# 使用 yum 安装 netcat 工具
yum install -y nc
Ⅱ. Flume Agent 配置(flume.conf)
本示例配置了一个 Agent,它通过 Netcat Source (r1) 监听数据,通过 Memory Channel (c1) 传输,最后由 HDFS Sink (hdfs-sink) 将数据写入 Hadoop。
vim /opt/module/flume-1.9.0/conf/flume.conf
配置内容如下:
# --- Agent 核心组件定义 ---
# 配置 Agent 各个组件的名称:Sources (r1), Channels (c1), Sinks (hdfs-sink)
agent.channels = c1
agent.sources = r1
agent.sinks = hdfs-sink# --- 1. 配置内存通道 (c1) ---
agent.channels.c1.type = memory# --- 2. 配置 Netcat Source (r1) ---
# Netcat Source 负责监听特定网络端口接收行文本数据
agent.sources.r1.type = netcat
# 主机名 (请根据您的实际环境修改,这里是 master 节点)
agent.sources.r1.bind = master
# 监听端口号
agent.sources.r1.port = 12345
agent.sources.r1.channels = c1# --- 3. 配置 HDFS Sink (hdfs-sink) ---
# HDFS Sink 负责将数据写入 HDFS
agent.sinks.hdfs-sink.type = hdfs
# HDFS 写入路径 (注意:需要事先启动 HDFS)
agent.sinks.hdfs-sink.hdfs.path = hdfs://master:8020/flume/events
agent.sinks.hdfs-sink.channel = c1
Ⅲ. Flume Agent 启动与测试
1. 准备 HDFS 路径与启动 HDFS
重要: 确保您的 HDFS 集群已启动,并且目标路径已创建。
# 事先要启动 HDFS (start-dfs.sh 等)# 新建 HDFS 路径,用于接收 Flume 写入的数据
hdfs dfs -mkdir -p /flume/events
2. 启动 Flume Agent
在终端执行命令,启动 Agent,并指定配置文件的位置和 Agent 的名称。
flume-ng agent --conf $FLUME_HOME/conf --conf-file $FLUME_HOME/conf/flume.conf --name agent -Dflume.root.logger=INFO,console
成功启动 Flume Agent
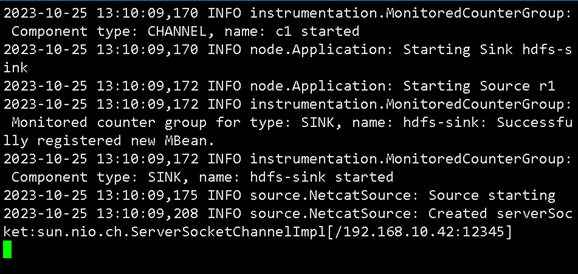
3. 发送测试数据
保持 Flume Agent 窗口运行,新建另一个终端窗口,使用 curl 命令向 Flume 监听的端口发送一条简单的 HTTP GET 请求,数据即为 w=helloworld。
# 向 master 主机的 12345 端口发送数据
curl -X GET http://master:12345?w=helloworld
通过 curl 命令测试 Flume Source

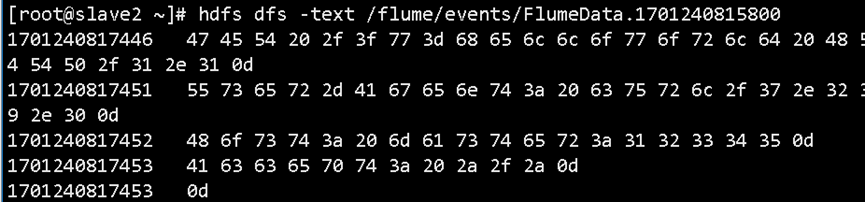
4. 查看 HDFS 接收数据
Flume Agent 接收到数据后,会通过 HDFS Sink 将其写入 HDFS 路径。
# 查看 HDFS 目标路径下写入的文件内容
hdfs dfs -text /flume/events/FlumeData*
查看 HDFS 中 Flume 写入的数据
Ⅳ. 故障排除:解决 Guava 库冲突(NoSuchMethodError)
在 Flume 1.9.0 与较新版本 Hadoop(例如 Hadoop 3.x)集成时,由于两者依赖的 Google Guava 库版本不兼容,可能会出现以下错误:
报错信息:
java.lang.NoSuchMethodError: com.google.common.base.Preconditions.checkArgument(ZLjava/lang/String;Ljava/lang/Object;)V
这表明 Flume 依赖的旧版本 Guava (如 11.0.2) 缺少 Hadoop 运行所需的特定方法。
解决办法:替换 Guava JAR 包
解决方案是使用 Hadoop 中更高版本的 Guava JAR 包替换 Flume 自身 lib 目录下的旧版本 JAR 包。
-
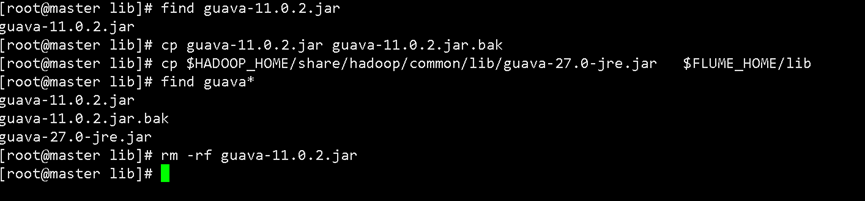
备份 Flume 中自带的 Guava JAR 包。
cd $FLUME_HOME/lib # 备份了 guava-11.0.2.jar 为 guava-11.0.2.jar.bak。 mv guava-11.0.2.jar guava-11.0.2.jar.bak -
复制 Hadoop 的新版本 Guava JAR 包。
- 找到 Hadoop 安装目录(通常在
share/hadoop/common/lib/)中的高版本 Guava JAR 包(例如:guava-27.0-jre.jar)。 - 将 Hadoop 的 guava-27.0-jre.jar 复制到了 Flume 的 lib 目录下。
# 示例:从 Hadoop 目录复制到 Flume lib 目录 cp /path/to/hadoop/share/hadoop/common/lib/guava-27.0-jre.jar $FLUME_HOME/lib/ - 找到 Hadoop 安装目录(通常在
3. 重启 Flume Agent:重新运行 Flume Agent 命令。
大功告成!解决 Guava 冲突后,数据就能顺利写入 HDFS。
HDFS 页面中 Flume 成功写入的数据目录
