机器学习周报二十一
文章目录
- 摘要
- Abstract
- 1 ELMO
- 1.1 RNN
- 1.2 LSTM
- 1.3 ELMO
- 2 swin-transformer代码
- 总结
摘要
本周学习了ELMo的论文,对GPT的和Transformer之前的语言模型有所了解,和借助pytorch实现swin-transformer,并且在小型数据集cifar-10来训练模型,下一步想借助swin-transformer训练cifar-100。
Abstract
This week I studied the ELMo paper, gained some understanding of GPT and pre-Transformer language models, implemented Swin-Transformer using PyTorch, and trained the model on the small CIFAR-10 dataset. The next step is to use Swin-Transformer to train on CIFAR-100.
1 ELMO
ELMO的提出是为了解决多义词问题,比如Apple(手机)和Apple(苹果)。
1.1 RNN
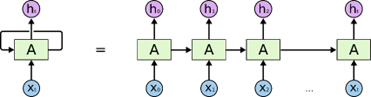
RNN(循环神经网络)是根据上一个隐藏状态输出和当前输入计算当前输出的模型,由于包含了上一个隐藏状态,所以RNN是具有记忆的,但是这个记忆在很长的序列中会消失,而且会带来梯度消失或梯度爆炸。
1.2 LSTM
LSTM(长短时记忆网络)是一种常用于处理序列数据的深度学习模型,与传统的 RNN(循环神经网络)相比,LSTM引入了三个门( 输入门、遗忘门、输出门,如下图所示)和一个 细胞状态(cell state),这些机制使得LSTM能够更好地处理序列中的长期依赖关系。

输入门决定哪些新信息应该被添加到记忆单元中。由一个sigmoid激活函数和一个tanh激活函数组成。sigmoid函数决定哪些信息是重要的,而tanh函数则生成新的候选信息。输入门的输出与候选信息相乘,得到的结果将在记忆单元更新时被考虑。
遗忘门决定哪些旧信息应该从记忆单元中遗忘或移除。遗忘门仅由一个sigmoid激活函数组成。
输出门决定记忆单元中的哪些信息应该被输出到当前时间步的隐藏状态中。输出门同样由一个sigmoid激活函数和一个tanh激活函数组成。sigmoid函数决定哪些信息应该被输出,而tanh函数则处理记忆单元的状态以准备输出。sigmoid函数的输出与经过tanh函数处理的记忆单元状态相乘,得到的结果即为当前时间步的隐藏状态。
1.3 ELMO
Embedding from Language Models.
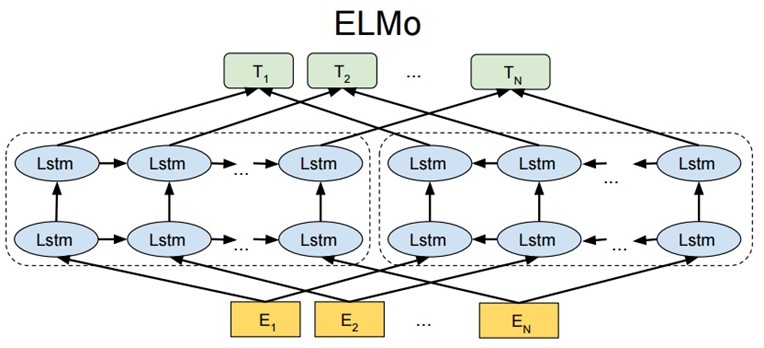
从静态的词向量表里查找单词的词向量 E(1), …, E(N) 用于输入。ELMo 使用 CNN-BIG-LSTM 生成的词向量作为输入。one-hot表征乘以Q矩阵即可完成查询过程。
将单词词向量 E(1), …, E(N) 分别输入第 1 层前向 LSTM 和后向 LSTM,得到前向输出 h(1,1,→), …, h(N,1,→),和后向输出 h(1,1,←), …, h(N,1,←)。
将前向输出 h(1,1,→), …, h(N,1,→) 传入到第 2 层前向 LSTM,得到第 2 层前向输出 h(1,2,→), …, h(N,2,→);将后向输出 h(1,1,←), …, h(N,1,←) 传入到第 2 层后向 LSTM,得到第 2 层后向输出 h(1,2,←), …, h(N,2,←)。
单词 i 最终可以得到的词向量包括 E(i), h(N,1,→), h(N,1,←), h(N,2,→), h(N,2,←),如果采用 L 层的 biLSTM 则最终可以得到 2L+1 个词向量。
首先在 ELMo 中使用 CNN-BIG-LSTM 词向量 E(i) 作为输入,E(i) 的维度等于 512。然后每一层 LSTM 可以得到两个词向量 h(i,layer,→) 和 h(i,layer,←),这两个向量也都是 512 维,拼接后是1024维,则对于单词 i 可以构造出 L+1 个词向量。
hi,jLMj=0,1,⋯,Lhi,0LM=[Ei;Ei]表示输入的词向量hi,jLM=[h→i,jLM;h←i,jLM]表示第j层LSTM的输出词向量\begin{aligned}h_{i,j}^{LM} j=0,1,\cdots,L \\ h_{i,0}^{LM}=[E_i;E_i]表示输入的词向量 \\ h_{i,j}^{LM}=[\overrightarrow{h}_{i,j}^{LM};\overleftarrow{h}_{i,j}^{LM}] 表示第j层LSTM的输出词向量 \end{aligned}hi,jLMj=0,1,⋯,Lhi,0LM=[Ei;Ei]表示输入的词向量hi,jLM=[hi,jLM;hi,jLM]表示第j层LSTM的输出词向量
h(i,0) 表示两个 E(i) 直接拼接,表示输入词向量,这是静态的,1024 维。
h(i,j) 表示第 j 层 biLSTM 的两个输出词向量 h(i,j,→) 和 h(i,j,←) 直接拼接,这是动态的,1024维。
ELMo 中不同层的词向量往往的侧重点往往是不同的,输入层采用的 CNN-BIG-LSTM 词向量可以比较好编码词性信息,第 1 层 LSTM 可以比较好编码句法信息,第 2 层 LSTM 可以比较好编码单词语义信息。
通过将 L+1 个输出加权融合在一起,公式如下。γ 是一个与任务相关的系数,允许不同的 NLP 任务缩放 ELMo 的向量,可以增加模型的灵活性。s(task,j) 是使用 softmax 归一化的权重系数。
ELMoitask=γtask∑j=0Lsjtaskhi,jLMELMo_i^{task} = \gamma^{task}\sum_{j=0}^L s_j^{task}h_{i,j}^{LM}ELMoitask=γtask∑j=0Lsjtaskhi,jLM
对于下游任务:
1.将句子 X 输入ELMo网络中,这样句子 X 中每个单词在ELMo网络中都能获得对应的三个Embedding;
2.之后赋予每个Embedding一个权重a,这个权重可以由学习得来,根据权重求和之后将三个Embedding整合为一个;
3.将整合后的Embedding作为相应的单词输入,作为新特征给下游任务使用;
2 swin-transformer代码
之前看了swin-transformer的论文,以为通过代码实现起来会很简单,但是后面发现难度很大,因为按照原文的实现,第一层PatchEmbed嵌入之后,图像从[B,C,H,W][B,C,H,W][B,C,H,W]变成了[B,patchnum,dmodel][B,patch_num,d_model][B,patchnum,dmodel]变成了三维,代表一个批次(Batch)的图片,每个图片有patch_num个patch,每个patch的长度变成d_model维,这在transformer中很好计算注意力,但是由于swin-transformer是窗口自注意力,在计算之前需要划分窗口,图片的patch向量是按照一列来排列的,假如说是[1,3,8,8]大小的图片按照patch大小为2划分出16个patch,然后这16个patch排成一列了,后面再按照窗口大小为2划分,划分出4个窗口,第一个窗口是[1,2,5,6]按照下标(从1开始),对于1列patch就不知道按什么规律来取出这个数据。
import mathimport torch
import torchvision
from torch import nn
from torch.utils.data import DataLoader
from torchvision import transformstorch.manual_seed(42)class Attention(nn.Module):def __init__(self, d_k):super().__init__()self.d_k = d_kdef forward(self, q, k, v, mask=None):scores = torch.matmul(q, k.transpose(-2, -1)) / math.sqrt(self.d_k)if mask is not None:scores = scores + mask * (-100)attention_weights = torch.softmax(scores, dim=-1)attention = torch.matmul(attention_weights, v)return attentionclass MultiHeadAttention(nn.Module):def __init__(self, d_model, num_heads):super().__init__()self.d_model = d_modelself.num_heads = num_headsself.d_k = d_model // num_headsassert d_model % num_heads == 0, "向量大小与头数要整除"self.w_q = nn.Linear(d_model, d_model)self.w_k = nn.Linear(d_model, d_model)self.w_v = nn.Linear(d_model, d_model)self.attention = Attention(self.d_k)self.linear = nn.Linear(d_model, d_model)def forward(self, q, k, v, mask=None):batch_size, seq_len = q.size(0), q.size(1)q = self.w_q(q)k = self.w_k(k)v = self.w_v(v)q = q.view(batch_size, seq_len, self.num_heads, self.d_k).transpose(1, 2)k = k.view(batch_size, seq_len, self.num_heads, self.d_k).transpose(1, 2)v = v.view(batch_size, seq_len, self.num_heads, self.d_k).transpose(1, 2)attention_output = self.attention(q, k, v, mask)attention_output = attention_output.transpose(1, 2).contiguous().view(batch_size, seq_len, self.d_model)output = self.linear(attention_output)return outputclass PatchEmbed(nn.Module):def __init__(self, patch_size, in_channels, d_model):super(PatchEmbed, self).__init__()self.patch_size = patch_sizeself.in_channels = in_channelsself.conv = nn.Conv2d(in_channels, d_model, kernel_size=patch_size, stride=patch_size)def forward(self, x):patches = self.conv(x)return patches.permute(0, 2, 3, 1)class PatchMerging(nn.Module):def __init__(self, d_model):super().__init__()self.d_model = d_modelself.linear = nn.Linear(4 * d_model, 2 * d_model, bias=False)self.norm = nn.LayerNorm(4 * d_model)def forward(self, x):B, H, W, C = x.shapeassert H % 2 == 0 and W % 2 == 0, f"x size ({H}*{W}) are not even."x0 = x[:, 0::2, 0::2, :] # B H/2 W/2 Cx1 = x[:, 1::2, 0::2, :] # B H/2 W/2 Cx2 = x[:, 0::2, 1::2, :] # B H/2 W/2 Cx3 = x[:, 1::2, 1::2, :] # B H/2 W/2 Cx = torch.cat([x0, x1, x2, x3], -1) # B H/2 W/2 4*Cx = x.view(B, -1, 4 * C) # B H/2*W/2 4*Cx = self.norm(x)x = self.linear(x) # B H/2*W/2 2*Creturn x.view(B, H // 2, W // 2, 2 * C)def window_partition(x, window_size):B, H, W, C = x.shapex = x.view(B, H // window_size, window_size, W // window_size, window_size, C)windows = x.permute(0, 1, 3, 2, 4, 5).contiguous().view(-1, window_size, window_size, C)return windowsdef window_reverse(windows, window_size, H, W):B = int(windows.shape[0] / (H * W / window_size / window_size))x = windows.view(B, H // window_size, W // window_size, window_size, window_size, -1)x = x.permute(0, 1, 3, 2, 4, 5).contiguous().view(B, H, W, -1)return xclass WindowAttention(nn.Module):def __init__(self, d_model, num_heads, window_size):super().__init__()self.d_model = d_modelself.num_heads = num_headsself.window_size = window_sizeself.attention = MultiHeadAttention(d_model, num_heads)def forward(self, x):B, H, W, C = x.shapewindow = window_partition(x, self.window_size)input = window.view(-1, self.window_size * self.window_size, C)attn = self.attention(input, input, input)output = attn.view(-1, self.window_size, self.window_size, C)return window_reverse(output, self.window_size, H, W)class ShiftWindowAttention(nn.Module):def __init__(self, d_model, num_heads, window_size):super().__init__()self.d_model = d_modelself.num_heads = num_headsself.window_size = window_sizeself.shift_size = window_size // 2self.attention = MultiHeadAttention(d_model, num_heads)self.mask = self._create_mask()def _create_mask(self):h, w = self.window_size, self.window_sizeshift = self.shift_sizecoords = torch.stack(torch.meshgrid(torch.arange(h), torch.arange(w), indexing='ij'))coords = coords.flatten(1).transpose(0, 1)i, j = coords[:, 0], coords[:, 1]label = (i >= shift) * 2 + (j >= shift)mask = (label[:, None] != label[None, :]).float() # [h*w, h*w]return mask.unsqueeze(0).unsqueeze(1)def forward(self, x):B, H, W, C = x.shapex = torch.roll(x, shifts=(-self.shift_size, -self.shift_size), dims=(1, 2))window = window_partition(x, self.window_size)input = window.view(-1, self.window_size * self.window_size, C)mask = self.mask.repeat(B * (input.shape[0] // B), 1, 1, 1).to(x.device)attn = self.attention(input, input, input, mask=mask)output = attn.view(-1, self.window_size, self.window_size, C)window = window_reverse(output, self.window_size, H, W)x = torch.roll(window, shifts=(self.shift_size, self.shift_size), dims=(1, 2))return xclass SwinTransformerBlock(nn.Module):def __init__(self, d_model, num_heads, window_size):super().__init__()self.d_model = d_modelself.norm1 = nn.LayerNorm(d_model)self.attn1 = WindowAttention(d_model, num_heads, window_size)self.norm2 = nn.LayerNorm(d_model)self.mlp1 = nn.Sequential(nn.Linear(d_model, d_model * 4),nn.GELU(),nn.Linear(d_model * 4, d_model))self.norm3 = nn.LayerNorm(d_model)self.attn2 = ShiftWindowAttention(d_model, num_heads, window_size)self.norm4 = nn.LayerNorm(d_model)self.mlp2 = nn.Sequential(nn.Linear(d_model, d_model * 4),nn.GELU(),nn.Linear(d_model * 4, d_model))def forward(self, x):shortcut = xx = self.norm1(x)x = self.attn1(x)x = x + shortcutshortcut = xx = self.norm2(x)x = self.mlp1(x)x = x + shortcutshortcut = xx = self.norm3(x)x = self.attn2(x)x = x + shortcutshortcut = xx = self.norm4(x)x = self.mlp2(x)x = x + shortcutreturn xclass SwinTransformer(nn.Module):def __init__(self, in_channels, patch_size, d_model, num_heads, window_size, stage, num_classes):super().__init__()self.window_size = window_sizeself.patches = PatchEmbed(patch_size=patch_size, in_channels=in_channels, d_model=d_model)self.stage = nn.ModuleList()for i in range(stage - 1):stage = nn.Sequential(SwinTransformerBlock(d_model=d_model, num_heads=num_heads, window_size=window_size),PatchMerging(d_model=d_model))d_model *= 2num_heads *= 2self.stage.append(stage)self.block = SwinTransformerBlock(d_model=d_model, num_heads=num_heads, window_size=window_size)# 分类头self.norm = nn.LayerNorm(d_model)self.linear = nn.Linear(d_model, num_classes)def forward(self, x):x = self.patches(x)for stage in self.stage:x = stage(x)x = self.block(x)x = self.norm(x)x = x.mean(dim=[1, 2])x = self.linear(x)return xdef train(model, epoches, train_loader, loss_func, optimizer,device):model.train()for epoch in range(epoches):total_loss = 0total = 0correct = 0for batch_idx, (data, target) in enumerate(train_loader):data, target = data.to(device), target.to(device)optimizer.zero_grad()output = model(data)loss = loss_func(output, target).to(device)loss.backward()optimizer.step()total_loss += loss.item()pred = output.argmax(dim=1)correct += (pred == target).sum().item()total += target.size(0)accuracy = 100. * correct / totalprint(f'Epoch {epoch + 1}, Loss: {total_loss / len(train_loader):.4f}, Accuracy: {accuracy:.2f}%')def test(model, test_loader, loss_func,device):model.eval()total_loss = 0total = 0correct = 0with torch.no_grad():for batch_idx, (data, target) in enumerate(test_loader):data,target = data.to(device), target.to(device)output = model(data)loss = loss_func(output, target)total_loss += loss.item()predicted = output.argmax(dim=1)total += target.size(0)correct += predicted.eq(target).sum().item()print(f'Test loss: {total_loss / len(test_loader):.4f}')print(f'Test accuracy: {100. * correct / total:.2f}% ({correct}/{total})')if __name__ == "__main__":# 设置设备device = torch.device("cuda" if torch.cuda.is_available() else "cpu")print(f"使用设备: {device}")transform = transforms.Compose([transforms.ToTensor(),transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5)),])train_data = torchvision.datasets.CIFAR10(root='data',train=True,download=False,transform=transform)train_loader = DataLoader(train_data,batch_size=32,shuffle=True)test_data = torchvision.datasets.CIFAR10(root='data',train=False,download=False,transform=transform,)test_loader = DataLoader(test_data,batch_size=32,shuffle=False)model = SwinTransformer(in_channels=3,patch_size=4,d_model=48,num_heads=4,window_size=2,stage=3,num_classes=10).to(device)print(f"模型参数量: {sum(p.numel() for p in model.parameters())}")loss_func = nn.CrossEntropyLoss()optimizer = torch.optim.Adam(model.parameters(), lr=0.0003)train(model=model,epoches=10,train_loader=train_loader,loss_func=loss_func,optimizer=optimizer,device = device)test(model=model,test_loader=test_loader,loss_func=loss_func,device=device)
'''
使用设备: cuda
模型参数量: 1267930
Epoch 1, Loss: 1.6575, Accuracy: 39.59%
Epoch 2, Loss: 1.3433, Accuracy: 51.51%
Epoch 3, Loss: 1.1856, Accuracy: 57.22%
Epoch 4, Loss: 1.0635, Accuracy: 61.87%
Epoch 5, Loss: 0.9611, Accuracy: 65.67%
Epoch 6, Loss: 0.8669, Accuracy: 68.99%
Epoch 7, Loss: 0.7692, Accuracy: 72.40%
Epoch 8, Loss: 0.6642, Accuracy: 76.38%
Epoch 9, Loss: 0.5614, Accuracy: 80.17%
Epoch 10, Loss: 0.4609, Accuracy: 83.69%
Test loss: 1.2460
Test accuracy: 62.71% (6271/10000)
'''最后模型在cifar-10数据集的效果比vision-transformer的效果要差,可能是没加入相对位置编码,使得全局建模的能力有所缺失,而且窗口尺寸小,捕捉特征的能力下降。在相当的参数下,Swin-Transformer的训练时间比Vision-Transformer的训练时间更短,Vision-Transformer在我的电脑使用CPU训练需要7个小时,而Swin-Transformer只需要一个小时。但是目前所实现的模型,还没有含有相对位置编码,这在swin-transformer的消融实验中,为下游任务提供了很大的作用,在物体检测任务中,相对位置编码的具有很大的重要性。
总结
本周实现了swin-transformer的代码,借助microsoft的源码,也有一些自己的思考,对其中的一些步骤仍有不清楚的地方,在原论文中清晰的结构在代码中实现起来却是困难重重,代码能力有所欠缺。目前只是解决于deepseek实现了模型对分类任务的代码,还没有实现模型对下游任务的能力。ELMo虽然与transformer系列关系不大,但是在学习bert和GPT时总会拿出来比较,几种架构之间的区别,总对这个ELMo有些疑惑,所以需要看一下这个模型的概念加深理解。