掌握RAG系统的七个优秀GitHub存储库
检索增强生成(RAG)的生态系统在过去几年中迅速崛起。如今,互联网上涌现出越来越多帮助开发人员构建RAG应用程序的开源项目。而RAG是一种通过外部知识源增强大型语言模型(LLM)的有效方法。因此,本文将介绍一些掌握RAG系统的优秀GitHub存储库。
在详细介绍之前,首先简单了解一下RAG及其应用程序。
RAG管道的工作流程如下:
•系统检索文件或数据;
•检索对完成用户提示上下文有帮助或有用的信息;
•系统将这些上下文信息输入LLM,以生成准确且符合上下文的响应。
如上所述,本文将探讨不同的开源RAG框架及其GitHub存储库,使用户能够轻松构建RAG系统。其目的是帮助开发人员、学生和技术爱好者选择适合自己需求的RAG工具包并加以利用。
为什么应该掌握RAG系统
检索增强生成(RAG)已经迅速成为人工智能领域最具影响力的创新技术之一。随着企业越来越注重实施具有上下文感知能力的智能系统,掌握RAG将成为必备技能。企业正利用RAG管道构建聊天机器人、知识助理和企业自动化工具,以确保其人工智能模型能够利用实时、特定领域的数据,而不是仅仅依赖于预训练的知识。
在RAG被用于构建更智能的聊天机器人、企业助手和自动化工具的时代,深入理解RAG可以让用户能够在人工智能开发、数据工程和自动化领域获得巨大的竞争优势。掌握构建和优化RAG管道的技能将获得更多的机遇,并最终提升市场竞争力,让职业生涯更具前瞻性。
图1 RAG的好处
在寻求掌握这些工具和技能的过程中,将介绍如何掌握RAG系统的顶级GitHub存储库。但在此之前,需要了解这些RAG框架究竟如何提供帮助。
RAG框架的作用
检索增强生成(RAG)框架是一种先进的人工智能架构,旨在通过将外部信息集成到响应生成过程中来提高LLM的能力。这使得LLM的响应更加丰富或具有时效性,而不是仅仅依赖于构建语言模型时使用的初始数据。该模型可以从外部数据库或知识库(API)中检索相关文档或数据,然后根据用户查询生成响应,而不是简单地依赖于最初训练模型的数据。
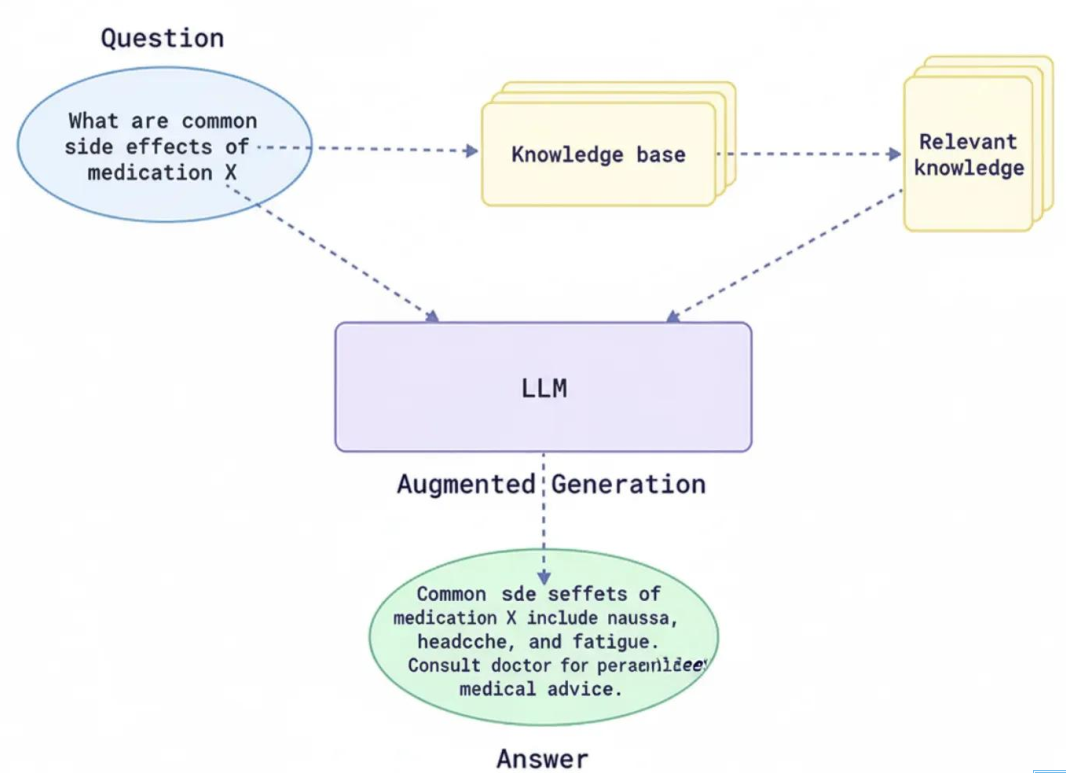
图2 RAG的架构
这使得模型能够处理问题并生成正确、对时间敏感或与上下文相关的答案。与此同时,它还能缓解知识截断和模型幻觉(即对提示的错误响应)等问题。通过将通用知识与特定领域信息相结合,RAG使人工智能系统能够提供负责任、可信的响应。
RAG技术的应用场景广泛,包括客户支持、搜索、合规性、数据分析等。此外,RAG系统还显著降低了对模型进行频繁重训练的需求,避免了为满足特定请求而专门调整模型的成本。
掌握RAG系统的优秀存储库
既然已经了解RAG系统如何提供帮助,以下将探索一些顶级GitHub存储库,这些存储库提供了详细的教程、代码和资源,帮助人们掌握RAG系统。这些GitHub存储库将帮助用户掌握使用RAG系统所需的工具、技能、框架和理论。
1.LangChain
LangChain是一个完整的LLM工具包,使开发者能够创建具有提示、记忆、代理和数据连接器等功能的复杂应用程序。从加载文档、拆分文本、嵌入和检索,到生成输出,LangChain为RAG管道的每个步骤都提供了模块。
LangChain拥有一个与OpenAI、Hugging Face、Azure等模型提供商集成的丰富生态系统,并支持Python、JavaScript和TypeScript等多种编程语言。LangChain的模块化架构采用分步流程设计,使用户能够灵活组合工具、构建智能代理工作流,并利用丰富的内置链式组件快速搭建应用程序。
•LangChain的核心功能包括工具链系统、丰富的提示模板,以及对代理和记忆模块的一流支持。
•LangChain采用开源协议(MIT许可证),拥有庞大的社区(GitHu Star超过70000个)。
•组件:提示模板、LLM封装器、向量库连接器、代理(工具+推理)、记忆模块等。
•集成:LangChain支持许多LLM提供商(OpenAI、Azure、本地LLM),嵌入模型和向量存储(FAISS, 、Pinecone、Chroma等)。
•用例:定制聊天机器人、文档问答、多步骤工作流程、RAG和代理任务。
使用示例
LangChain的高级API使简单的RAG管道简洁明了。例如,在这里使用LangChain来回答一个问题,使用OpenAI的嵌入和LLM的一小部分文档:
from langchain.embeddings import OpenAIEmbeddings
from langchain.vectorstores import FAISS
from langchain.llms import OpenAI
from langchain.chains import RetrievalQA
# Sample documents to index
docs = ["RAG stands for retrieval-augmented generation.", "It combines search and LLMs for better answers."]
# 1. Create embeddings and vector store
vectorstore = FAISS.from_texts(docs, OpenAIEmbeddings())
# 2. Build a QA chain (LLM + retriever)
qa = RetrievalQA.from_chain_type(
llm=OpenAI(model_name="text-davinci-003"),
retriever=vectorstore.as_retriever()
)
# 3. Run the query
result = qa({"query": "What does RAG mean?"})
print(result["result"])这段代码获取文档并使用OpenAI嵌入将其加载到FAISS向量存储中。然后,它使用RetrievalQA获取相关上下文并生成答案。LangChain抽象了检索和LLM调用。(有关其他说明请参阅LangChain API和教程。)
有关更多信息可以在此处查看Langchain的GitHub存储库。
2.deepset-ai的Haystack
Haystack是deepset团队开发的一款面向企业的RAG框架,是围绕可组合管道构建的。该框架采用图状管道设计,允许用户将检索器、阅读器和生成器等功能节点连接成有向图结构。Haystack专为prod中的部署而设计,并为文档存储和检索提供了多种后端选择,例如Elasticsearch、OpenSearch、Milvus、Qdrant等。
•它提供了基于关键字的检索(BM25)和密集检索功能,并且易于插入开源阅读器(Transformers QA模型)或生成式答案生成器。
•它是开源的(Apache 2.0许可证),并且非常成熟(GitHub Star超过10000个)。
•架构:以管道为中心且模块化,节点可以准确插入和替换。
•组件包括:文档存储(Elasticsearch、In-Memory等),检索器(BM25、Dense),读取器(例如,Hugging FaceQA模型)和生成器(OpenAI、本地LLM)。
•易于扩展:分布式设置(Elasticsearch集群)、GPU支持、REST API和Docker。
•可能的用例包括:用于搜索的RAG、文档问答、摘要应用、监控用户查询。
使用示例
以下是使用Haystack现代API(v2)创建小型RAG管道的简化示例:
from haystack.document_stores import InMemoryDocumentStore
from haystack.nodes import BM25Retriever, OpenAIAnswerGenerator
from haystack.pipelines import Pipeline
# 1. Prepare a document store
doc_store = InMemoryDocumentStore()
documents = [{"content": "RAG stands for retrieval-augmented generation."}]
doc_store.write_documents(documents)
# 2. Set up retriever and generator
retriever = BM25Retriever(document_store=doc_store)
generator = OpenAIAnswerGenerator(model_name="text-davinci-003")
# 3. Build the pipeline
pipe = Pipeline()
pipe.add_node(compnotallow=retriever, name="Retriever", inputs=[])
pipe.add_node(compnotallow=generator, name="Generator", inputs=["Retriever"])
# 4. Run the RAG query
result = pipe.run(query="What does RAG mean?")
print(result["answers"][0].answer)这段代码将一个文档写入内存,使用BM25查找相关文本,然后要求OpenAI模型回答。Haystack的Pipeline负责编排流程。有关更多信息可以查看此处的deepset repository。
3.LlamaIndex
LlamaIndex(前身为GPT Index)是一个以数据为中心的RAG框架,专注于为LLM使用索引和查询数据。你可以将LlamaIndex视为一套用于构建文档自定义索引(向量、关键词索引、图像)并查询它们的工具。LlamaIndex 是一种强大的方式,可以使用索引结构将文本文件、API和SQL等不同数据源连接到 LLM。
例如,可以创建所有文件的矢量索引,然后使用内置查询引擎回答任何问题,这一切都可以通过LlamaIndex实现。LlamaIndex提供了高级API和低级模块,以便自定义RAG流程的每个部分。
•LlamaIndex是开源的(MIT许可证),拥有不断壮大的社区(GitHub Star超过45,000个)。
•数据连接器:(用于PDF、文档、网页内容)、多种索引类型(向量存储、树、图)和能够高效导航的查询引擎。
•可以轻松插入LangChain或其他框架。LlamaIndex适用于任何大型语言模型/嵌入(OpenAI、Hugging Face、本地LLM)。
•通过自动创建索引,然后从索引中获取上下文,采用LlamaIndex可以更轻松地构建RAG代理。
使用示例
LlamaIndex使得从文档创建可搜索索引变得非常简单。例如,使用核心API:
from llama_index import VectorStoreIndex, SimpleDirectoryReader
# 1. Load documents (all files in the 'data' directory)
documents = SimpleDirectoryReader("./data").load_data()
# 2. Build a vector store index from the docs
index = VectorStoreIndex.from_documents(documents)
# 3. Create a query engine from the index
query_engine = index.as_query_engine()
# 4. Run a query against the index
response = query_engine.query("What does RAG mean?")
print(response)这段代码将读取./data目录中的文件,在内存中建立索引,然后查询该索引LlamaIndex以字符串形式返回答案。有关更多信息,可以查看Llamindex存储库。
4.RAGFlow
RAGFlow是InfiniFlow团队为企业设计的一款RAG引擎,旨在处理复杂和大规模的数据。其目标是实现“深度文档理解”,以便解析PDF、扫描文档、图像或表格等不同格式,并将它们总结成结构化的知识片段。
RAGFlow具有集成的检索模型、代理模板和用于调试的可视化工具,其关键要素包括基于模板的高级文档分块和引用标注概念。这有助于减少幻觉,因为可以知道哪些源文本支持哪些答案。
•RAGFlow是开源的(Apache-2.0许可证),拥有强大的社区(GitHub Star超过65,000个)。
•亮点:深层文档的解析(例如,分解图表、图像和多策略文档),使用模板规则(用于管理文档的自定义规则)对文档进行分块,以及引用以显示如何记录出处以回答问题。
•工作流:RAGFlow作为服务使用,这意味着可以启动一个服务器(使用Docker),然后通过用户界面或API索引文档。RAGFlow 还提供了用于构建聊天机器人的 CLI 工具和 Python/REST API。
•用例:处理大量文档的大型企业,以及对答案可追溯性和准确性有严格要求的用例。
使用示例
import requests
api_url = "http://localhost:8000/api/v1/chats_openai/default/chat/completions"
api_key = "YOUR_RAGFLOW_API_KEY"
headers = {"Authorization": f"Bearer {api_key}"}
data = {
"model": "gpt-4o-mini",
"messages": [{"role": "user", "content": "What is RAG?"}],
"stream": False
}
response = requests.post(api_url, headers=headers, jsnotallow=data)
print(response.json()["choices"][0]["message"]["content"])这个示例演示了RAGFlow的聊天补全API的使用方式,它与OpenAI兼容。它向“默认”助理发送聊天消息时,助手将使用索引文档作为上下文来生成回复。
5.txtai
txtai是一个一体化的人工智能框架,提供语义搜索、嵌入和RAG管道功能。它配备了一个可嵌入的向量搜索数据库,源自SQLite+FAISS,以及允许编排LLM调用的实用程序。使用txtai,一旦使用文本数据创建了嵌入索引,就应该在代码中人工将其连接到LLM,或者使用内置的RAG辅助工具。
txtai的真正优点在于其简单性:它可以100%地在本地运行(无需云平台),它内置了RAG 管道模板,甚至提供了自动生成的FastAPI服务。它也是开源的(Apache 2.0),易于原型设计和部署。
•开源(Apache-2.0许可证,GitHub Star超过7,000个)的Python包。
•功能:语义搜索索引(向量数据库)、RAG管道和FastAPI服务生成。
•RAG支持:txtai有一个RAG类,它接受一个Embeddings实例和一个LLM,它自动将检索到的上下文插入到LLM提示中。
•LLM灵活性:使用OpenAI、Hugging Face转换器、llama.cpp或任何想要的LLM接口模型。
使用示例
以下是使用内置管道在txtai中运行RAG查询的简单方法:
from txtai import Embeddings, LLM, RAG
# 1. Initialize txtai components
embeddings = Embeddings() # uses a local FAISS+SQLite by default
embeddings.index([{"id": "doc1", "text": "RAG stands for retrieval-augmented generation."}])
llm = LLM("text-davinci-003") # or any model
# 2. Create a RAG pipeline
prompt = "Answer the question using only the context below.\n\nQuestion: {question}\nContext: {context}"
rag = RAG(embeddings, llm, template=prompt)
# 3. Run the RAG query
result = rag("What does RAG mean?", maxlength=512)
print(result["answer"])这段代码片段选取了一个文档并运行了RAG管道。RAG助手从向量索引中管理相关段落的检索,并填充提示模板中的{context}。它将允许采用良好的结构(包括API和无代码UI)封装RAG管道代码。Cognita确实在底层使用了LangChain/LlamaIndex模块,但以结构化的方式组织它们:数据加载器、解析器、嵌入器、检索器和指标模块。有关更多信息可以查看此处的存储库。
6. LLMWare
LLMWare是一个完整的RAG框架,其核心理念是推崇使用更轻量、更安全、更快速的专用模型进行推理。与多数依赖大型云端LLM的框架不同,LLMWare旨在本地部署,只需在具备必要计算能力的桌面或服务器上即可流畅运行整套RAG流程。这一设计从源头上限制了数据外泄风险,使得用户能够安全地利用LLM进行大规模试点研究及多样化应用。
LLMWare为常见的RAG功能提供了无代码向导和模板,包括文档解析和索引功能。它还为各种文档格式(Office和PDF)提供了工具,这些为认知人工智能功能进行文档分析奠定了坚实基础。
•面向企业RAG的开源产品(Apache-2.0许可证,GitHub Star超过14000个)。
•一种专注于更小的LLM(如Llama 7B变体)的方法,并且推理可以在设备上运行,同时即使在ARM设备上也能提供RAG功能。
•工具:提供CLI和REST API、交互式UI以及管道模板。
•显著的特点:预先配置的管道,内置的事实检查功能,用于向量搜索和问答的插件功能。
•示例:追求RAG但无法将数据发送到云的企业,例如金融服务、医疗保健或移动/边缘人工智能应用程序的开发者。
使用示例
LLMWare的API设计易于使用。以下是基于其文档的简单示例:
from llmware.prompts import Prompt
from llmware.models import ModelCatalog
# 1. Load a model for prompting
prompter = Prompt().load_model("llmware/bling-tiny-llama-v0")
# 2. (Optionally) index a document to use as context
prompter.add_source_document("./data", "doc.pdf", query="What is RAG?")
# 3. Run the query with context
response = prompter.prompt_with_source("What is RAG?")
print(response)这段代码使用了一个LLMWare Prompt对象。首先指定一个模型(例如,来自Hugging Face的小型Llama模型)。然后,添加一个包含源文档的文件夹。LLMWare将“doc.pdf”解析为片段,并根据与用户问题的相关性进行过滤。然后,prompt_with_source函数发出请求,传递来自源的相关上下文。这将返回一个文本答案和元数据响应。有关更多信息,请查看此处的存储库。
7.Cognita
Cognita由TrueFoundary开发,是一个为可扩展性和协作而构建的生产就绪RAG框架。它主要致力于简化从笔记本或实验到部署/服务的过程。它支持增量索引,并具有一个Web UI,供非开发人员尝试上传文档、选择模型和实时查询。
•它是开源的(Apache-2.0许可证)。
•架构:完全基于API和容器化,可以通过Docker Compose(包括用UI)完全在本地运行。
•组件:用于解析器、加载器、嵌入器、检索器等的可重用库。所有组件都可以定制和扩展。
•UI-可扩展性:提供了一个用于实验的 Web 前端和一个用于管理 LLM/嵌入器配置的“模型网关”。当开发人员和分析师协作构建RAG管道组件时,这非常有用。
使用示例
Cognita主要通过其命令行界面和内部 API 访问,但以下是使用其Python API的概念性伪代码片段:
from cognita.pipeline import Pipeline
from cognita.schema import Document
# Initialize a new RAG pipeline
pipeline = Pipeline.create("rag")
# Add documents (with text content)
docs = [Document(id="1", text="RAG stands for retrieval-augmented generation.")]
pipeline.index_documents(docs)
# Query the pipeline
result = pipeline.query("What does RAG mean?")
print(result['answer'])在实际应用中,用户可以使用YAML来配置Cognita框架,或者使用其CLI来加载数据并启动服务。上述代码片段清晰地展示了核心操作流程:首先创建数据处理管道,接着构建索引,最后执行查询。Cognita文档有更多详细信息。有关更多信息,请查看此处的存储库。
结论
这些用于RAG系统的开源GitHub存储库为开发人员、研究人员和业余爱好者提供了丰富的工具包。
•LangChain和LlamaIndex为构建定制管道和索引解决方案提供了灵活的API。
•Haystack提供了经过生产环境测试的NLP管道,并关注数据摄取的扩展性。
•RAGFlow和LLMWare满足企业需求,LLMWare在某种程度上更侧重于设备上的模型和安全性。
•相比之下,txtai提供了一个轻量级的、简单的、一体化的本地RAG解决方案,而Cognita则通过一个简单的、模块化的、UI驱动的平台来处理一切。
上述所有应用于RAG系统的GitHub存储库均保持着良好的维护状态,并且都提供了可直接运行的示例代码。这些情况充分表明,RAG技术已经超越了学术研究的前沿范畴,如今已具备足够的成熟度,可以供任何有志于构建人工智能应用的人士直接使用。实际上,究竟哪一个是“最佳选择”,还需根据用户的具体需求和优先级来综合判断。