数据结构精讲:从栈的定义到链式实现,再到LeetCode实战
📚 数据结构精讲:从栈的定义到链式实现,再到LeetCode实战
目录导航
📚 数据结构精讲:从栈的定义到链式实现,再到LeetCode实战
1. 栈是什么?生活中的LIFO哲学
2. 栈的抽象数据类型(ADT)与核心操作
3. 顺序存储结构:数组实现栈的“游标”艺术
核心思想:用一个“游标”指向栈顶
4. 两栈共享空间:内存利用的智慧
设计思路
5. 链式存储结构:动态灵活的链表栈
核心设计:栈顶即链表头结点
链式栈的进栈与出栈操作详解
进栈 (Push) 操作
出栈 (Pop) 操作
6. 实战演练:用栈解决“有效的括号”问题
7. 总结与思考:为什么链表更适合实现队列?

1. 栈是什么?生活中的LIFO哲学
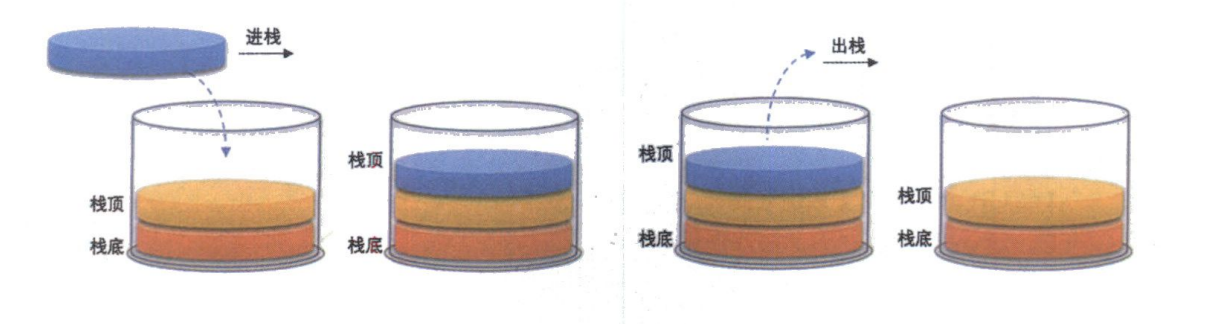
想象一下你家厨房里的盘子堆——你总是把新洗好的盘子放在最上面,而取盘子时也总是从最上面拿走。这就是栈(Stack)的核心思想:后进先出(Last In First Out, LIFO)。
在计算机世界里,栈的应用无处不在:
- 浏览器的“后退”功能:你点击链接浏览网页,每打开一个新页面,它就被“压入”栈顶;当你点击“后退”,最新访问的页面就从栈顶“弹出”,带你回到上一个页面。
- 软件的“撤销(Undo)”功能:无论是Word还是Photoshop,每一次操作都被记录在栈中,撤销就是弹出最近的操作。
核心定义:栈是一种限定仅在表尾进行插入和删除操作的线性表。我们称允许插入和删除的一端为栈顶(top),另一端为栈底(bottom)。不含任何元素的栈称为空栈。
小思考:你能想到哪些生活中的例子体现了栈的LIFO特性吗?欢迎在评论区分享!
2. 栈的抽象数据类型(ADT)与核心操作
栈作为一种抽象数据类型(ADT),其核心在于定义一组清晰的操作接口,而具体的实现细节则被隐藏起来。
// ADT Stack (stack)
Data:同线性表。元素具有相同的类型,相邻元素具有前驱和后继关系。Operation:InitStack(*S); // 初始化操作,建立一个空栈S。DestroyStack(*S); // 若栈存在,则销毁它。ClearStack(*S); // 将栈清空。StackEmpty(S); // 若栈为空,返回true,否则返回false。GetTop(S, *e); // 若栈存在且非空,用*e返回栈顶元素。Push(*S, e); // 若栈S存在,插入新元素e到栈S中并成为栈顶元素。Pop(*S, *e); // 删除栈S中栈顶元素,并用*e返回其值。StackLength(S); // 返回栈S的元素个数。
endADT这些操作非常直观:
Push就是“压入”或“进栈”。Pop就是“弹出”或“出栈”。GetTop是查看栈顶元素但不移除它。
关键点:栈的操作只发生在栈顶,这使得它的逻辑异常简洁,但也因此限制了其灵活性。
3. 顺序存储结构:数组实现栈的“游标”艺术
既然栈是线性表的特例,那么用数组来实现它是最直接的想法。这种实现方式被称为顺序栈。
核心思想:用一个“游标”指向栈顶
我们定义一个整型变量 top 来指示当前栈顶元素在数组中的位置。这个 top 就像物理实验中的游标卡尺,它可以在数组范围内滑动,但永远不会超出边界。
- 空栈:当
top = -1时,表示栈中没有任何元素。 - 满栈:当
top = MAXSIZE - 1时,表示栈已满,不能再插入新元素。 - 进栈:先将
top加1,然后将新元素放入data[top]。 - 出栈:先将
data[top]的值赋给返回变量,再将top减1。
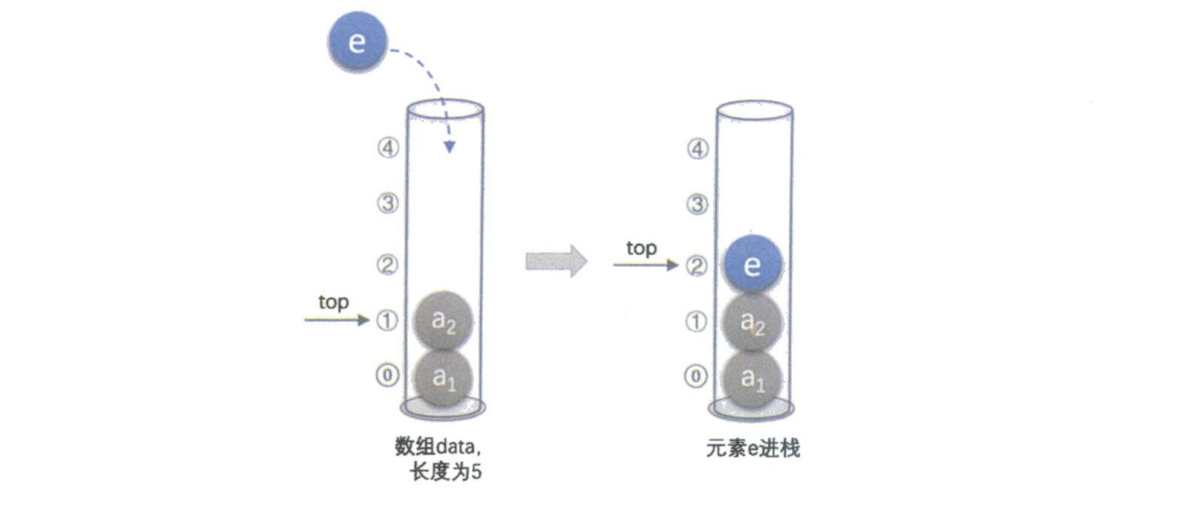
(图注:演示了元素 e 如何被压入栈顶的过程。)
代码实现:
typedef int SElemType; // 假设元素类型为inttypedef struct {SElemType data[MAXSIZE]; // 存储元素的数组int top; // 栈顶指针
} SqStack;/* 进栈操作 */
Status Push(SqStack *S, SElemType e) {if (S->top == MAXSIZE - 1) { // 判断是否栈满return ERROR;}S->top++; // 栈顶指针加1S->data[S->top] = e; // 将新元素赋值给栈顶空间return OK;
}/* 出栈操作 */
Status Pop(SqStack *S, SElemType *e) {if (S->top == -1) { // 判断是否栈空return ERROR;}*e = S->data[S->top]; // 将栈顶元素值赋给eS->top--; // 栈顶指针减1return OK;
}复杂度分析:由于没有循环语句,
Push和Pop操作的时间复杂度均为 O(1),效率极高。
4. 两栈共享空间:内存利用的智慧
顺序栈虽然简单高效,但它有一个致命缺陷:必须预先分配固定大小的数组。如果栈空间不足,程序就会溢出;如果空间太大,又会造成浪费。
一个聪明的解决方案是:两栈共享一个数组空间。
设计思路
- 让两个栈的栈底分别位于数组的两端。
- 两个栈的栈顶指针
top1和top2分别向数组中间增长。 - 当
top1 + 1 == top2时,表示整个空间已被占满,此时两个栈都满了。
代码实现:
typedef struct {SElemType data[MAXSIZE];int top1; // 栈1的栈顶指针int top2; // 栈2的栈顶指针
} SqDoubleStack;/* 入栈操作,需指定是哪个栈 */
Status Push(SqDoubleStack *S, SElemType e, int stackNumber) {if (S->top1 + 1 == S->top2) { // 栈满判断return ERROR;}if (stackNumber == 1) {S->data[++S->top1] = e; // 栈1入栈} else if (stackNumber == 2) {S->data[--S->top2] = e; // 栈2入栈}return OK;
}/* 出栈操作,同样需指定是哪个栈 */
Status Pop(SqDoubleStack *S, SElemType *e, int stackNumber) {if (stackNumber == 1) {if (S->top1 == -1) { // 栈1空return ERROR;}*e = S->data[S->top1--]; // 栈1出栈} else if (stackNumber == 2) {if (S->top2 == MAXSIZE) { // 栈2空return ERROR;}*e = S->data[S->top2++]; // 栈2出栈}return OK;
}适用场景:这种方法特别适用于两个栈的空间需求呈“此消彼长”的情况,比如买股票时“买入”和“卖出”操作的记录。
5. 链式存储结构:动态灵活的链表栈
顺序栈的缺点是空间固定,而链式栈则完美解决了这个问题。它使用单链表来实现,不需要预先分配空间,可以动态增长。
核心设计:栈顶即链表头结点
为了操作方便,我们通常将栈顶设置在链表的头部。这样,Push 和 Pop 操作都只需要修改头指针,时间复杂度依然是 O(1)。
- 空栈:头指针
top为NULL。 - 进栈:创建一个新节点,将其
next指向原栈顶,再将top指向新节点。 - 出栈:将
top指向的节点的值取出,然后top指向下一个节点,最后释放原栈顶节点。
链式栈的进栈与出栈操作详解
进栈 (Push) 操作
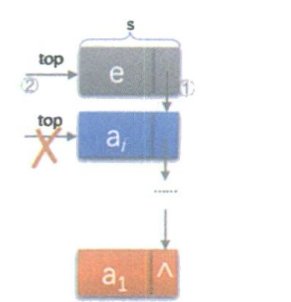
当我们要将一个新元素 e 压入栈中时,需要执行以下三步:
- 创建一个新节点
s。 - 将新节点
s的next指针指向当前的栈顶节点。 - 将栈顶指针
top指向新节点s。
出栈 (Pop) 操作
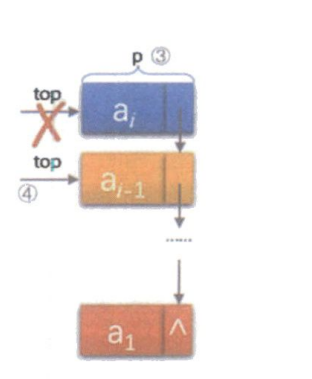
当我们要从栈中弹出一个元素时,也需要执行简单的三步:
- 保存当前栈顶节点
p的地址。 - 将栈顶指针
top指向下一个节点。 - 释放原栈顶节点
p的内存。
代码展示:
typedef struct StackNode {SElemType data;struct StackNode *next;
} StackNode, *LinkStackPtr;typedef struct {LinkStackPtr top; // 栈顶指针int count; // 栈中元素个数
} LinkStack;/* 进栈操作 */
Status Push(LinkStack *S, SElemType e) {LinkStackPtr s = (LinkStackPtr)malloc(sizeof(StackNode));if (!s) {return ERROR;}s->data = e;s->next = S->top; // 新节点指向原栈顶S->top = s; // 栈顶指针指向新节点S->count++;return OK;
}/* 出栈操作 */
Status Pop(LinkStack *S, SElemType *e) {LinkStackPtr p;if (S->top == NULL) { // 栈空return ERROR;}*e = S->top->data;p = S->top;S->top = S->top->next; // 栈顶指针下移free(p); // 释放原栈顶节点S->count--;return OK;
}复杂度分析:链式栈的
Push和Pop操作都非常简单,没有任何循环操作,时间复杂度均为 O(1)。选择建议:对比顺序栈和链栈,它们在时间复杂度上是一样的。对于空间性能,顺序栈需要事先确定一个固定的长度,可能存在内存空间浪费的问题,但它的优势是存取时定位方便。而链栈则要求每个元素都有指针域,这同时也增加了一些内存开销,但对于栈的长度无限制。所以,如果栈的使用过程中元素变化不可预料,有时很小,有时非常大,那么最好使用链栈;反之,如果它的变化在可控范围内,建议使用顺序栈会更好一些。
6. 实战演练:用栈解决“有效的括号”问题
理论知识学得再多,不如动手实践一次。让我们来看一道经典的LeetCode题目:
题目:有效的括号 (Valid Parentheses) 给定一个只包含
'(',')','{','}','[',']'的字符串,判断字符串是否有效。
解题思路:
- 遍历字符串中的每一个字符。
- 如果是左括号
(,{,[,则将其压入栈中。 - 如果是右括号
),},],则检查栈顶元素是否是对应的左括号。如果是,则弹出栈顶元素;如果不是,则字符串无效。 - 遍历结束后,如果栈为空,则字符串有效;否则无效。
参考代码:
#include <stdbool.h>
#include <stdlib.h>
#include <string.h>bool isValid(char * s){int len = strlen(s);char *stack = (char*)malloc(len * sizeof(char)); // 用数组模拟栈int top = -1;for (int i = 0; i < len; i++) {char c = s[i];if (c == '(' || c == '{' || c == '[') {stack[++top] = c; // 左括号入栈} else {if (top == -1) return false; // 栈空,却遇到右括号,无效char topChar = stack[top--]; // 弹出栈顶// 判断是否匹配if ((c == ')' && topChar != '(') ||(c == '}' && topChar != '{') ||(c == ']' && topChar != '[')) {return false;}}}free(stack);return top == -1; // 栈空则有效
}这就是栈的魅力:一个简单的LIFO结构,就能优雅地解决复杂的匹配问题。
7. 总结与思考:为什么链表更适合实现队列?
通过本文的学习,我们已经深入理解了栈的方方面面。现在,让我们来回答一个经典的问题:
为什么在实际应用中,链表比数组更适合实现队列?
- 队列的特点是FIFO(先进先出),这意味着元素的插入在队尾,删除在队头。
- 如果用数组实现队列,每次删除队头元素后,都需要将后面的所有元素向前移动一位,时间复杂度为 O(n),效率低下。
- 而用链表实现,我们只需要维护两个指针(队头和队尾),插入和删除操作都只需修改指针,时间复杂度为 O(1),且无需移动元素。
所以,对于需要频繁在两端进行操作的数据结构(如队列),链表是更优的选择。
结语
栈,这个看似简单的数据结构,却是计算机科学中最基础、最重要的概念之一。栈的引入简化了程序设计的问题划分了不同关注层次’使得思考范围缩小’更加聚焦于我们要解决的问题核心。 从浏览器历史到函数调用栈,从算法设计到操作系统内核,它的身影无处不在。希望这篇博客能帮助你建立起对栈的系统化认知,并激发你进一步探索数据结构的兴趣。
如果你觉得这篇文章对你有帮助,别忘了点赞、收藏和分享!也欢迎在评论区提出你的疑问或见解。
下一篇博客更新栈的应用。

