深入探索序列学习:循环神经网络(RNN)及其变体(LSTM、GRU)的详尽解析
前言
在人工智能的浪潮中,深度学习已经成为推动技术进步的核心引擎。其中,专门为处理序列数据而设计的神经网络架构——循环神经网络(Recurrent Neural Networks, RNNs)扮演着至关重要的角色。从自然语言处理到时间序列预测,RNN 及其先进的变体,如长短期记忆网络(Long Short-Term Memory, LSTM)和门控循环单元(Gated Recurrent Unit, GRU),已经彻底改变了我们处理和理解有序信息的方式。
本文将深入探讨 RNN 的核心原理,剖析其面临的挑战,并详细介绍 LSTM 和 GRU 如何通过精巧的门控机制克服这些挑战。更重要的是,我们将通过具体的代码实现,展示如何在实践中构建和应用这些强大的模型。
1. 序列数据的本质与传统模型的局限
在深入了解 RNN 之前,我们首先需要理解它所要处理的数据类型——序列数据。与独立的图像或表格数据不同,序列数据中的元素具有内在的顺序和时间依赖性。 典型的例子包括:
自然语言文本:单词的顺序决定了句子的含义。
时间序列数据:股票价格、天气读数或传感器数据,其当前值与历史值密切相关。
语音和音频:声波是随时间变化的连续信号。
视频:由一系列有序的图像帧组成。
传统的前馈神经网络(Feedforward Neural Networks, FNNs)或卷积神经网络(CNNs)在处理这类数据时会遇到根本性的困难。 它们假设所有输入都是相互独立的,无法捕捉到数据点之间的时序关系。 例如,在处理一个句子时,FNN 会孤立地看待每个单词,从而丢失了至关重要的上下文信息。为了解决这个问题,我们需要一种能够“记忆”过去信息的模型,而这正是 RNN 的设计初衷。
2. 循环神经网络(RNN):引入“记忆”
RNN 的核心思想是引入一个循环结构,允许信息在网络的时间步之间持续存在。 与 FNNs 中信息单向流动不同,RNNs 在每个时间步处理一个序列元素时,不仅会接收当前的输入,还会接收来自上一个时间步的隐藏状态(hidden state)。 这个隐藏状态可以被看作是网络对到目前为止所处理过的序列信息的“记忆”或摘要。
2.1 RNN 的结构与工作原理
一个简单的 RNN 单元可以被看作是一个带有环路的模块。在每个时间步 `t`,该单元接收当前输入 `x_t` 和前一时间步的隐藏状态 `h_{t-1}`,然后计算出当前时间步的隐藏状态 `h_t` 和输出 `y_t`。
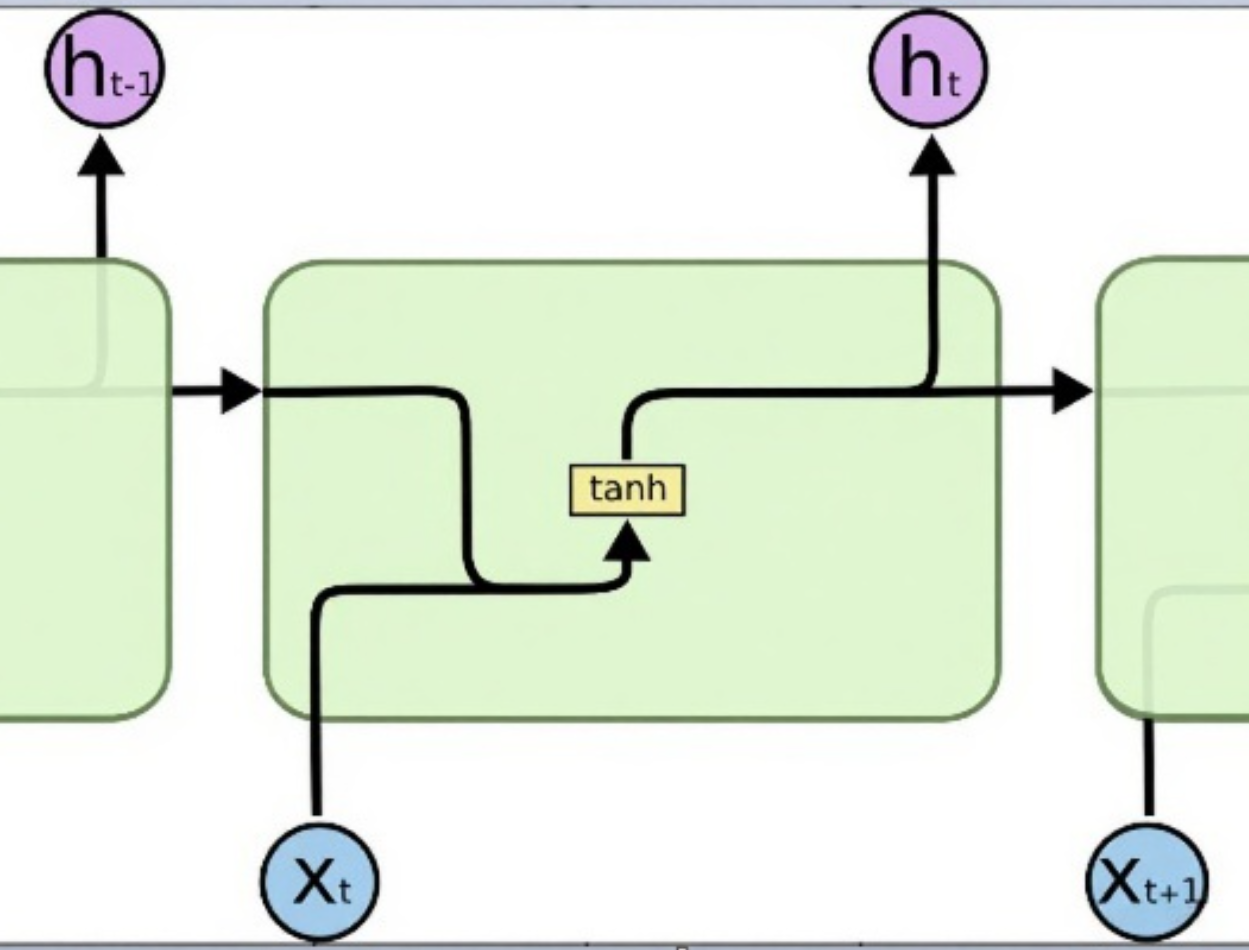
这个循环过程可以“展开”(unfold)成一个线性的序列,这样更容易理解信息是如何在时间步之间传递的。 展开后的网络看起来像一个很深的前馈网络,其中每一层都代表一个时间步,并且重要的是,所有时间步共享相同的权重矩阵。
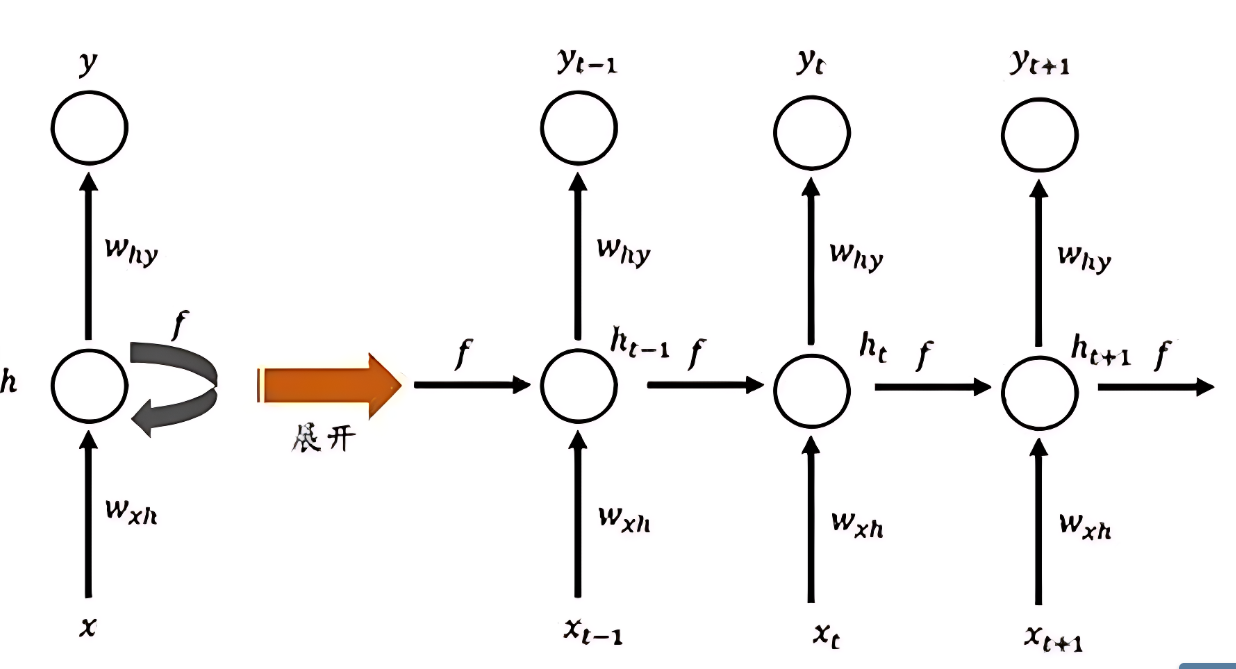
2.2 数学表达
简单 RNN 的核心计算可以用以下两个公式来描述:
1. 隐藏状态的计算:
`h_t = f(W_{hh} * h_{t-1} + W_{xh} * x_t + b_h)`
2. 输出的计算:
`y_t = W_{hy} * h_t + b_y`
其中:
`x_t`: 在时间步 `t` 的输入向量。
`h_{t-1}`: 在时间步 `t-1` 的隐藏状态。
`h_t`: 在时间步 `t` 的新隐藏状态。
`y_t`: 在时间步 `t` 的输出。
`W_{xh}`, `W_{hh}`, `W_{hy}`: 分别是输入到隐藏层、隐藏层到隐藏层、隐藏层到输出层的权重矩阵。这些权重在所有时间步中是共享的。
`b_h`, `b_y`: 分别是隐藏层和输出
2.3 训练算法:时间反向传播(BPTT)
RNN 的训练是通过一种名为“时间反向传播”(Backpropagation Through Time, BPTT)的算法来完成的。 BPTT 本质上是标准反向传播算法在展开后的 RNN 网络上的应用。 损失函数在每个时间步计算,然后将梯度从最后一个时间步开始,沿着时间序列反向传播,并用这些梯度来更新共享的权重矩阵。
2.4 简单 RNN 的挑战:长期依赖问题
尽管 RNN 的设计在理论上能够捕捉任意长度的序列依赖关系,但在实践中,它们很难学习到“长期依赖”(Long-Term Dependencies)。 这个问题主要源于梯度消失(Vanishing Gradients)和梯度爆炸(Exploding Gradients)。
梯度消失:在通过 BPTT 反向传播梯度时,如果激活函数(如 `tanh`)的导数持续小于 1,那么梯度在每一步传播时都会被乘以一个小于 1 的权重矩阵。经过许多时间步后,梯度会变得非常小,几乎接近于零。这导致网络无法有效地更新与早期时间步相关的权重,从而“忘记”了久远的信息。
梯度爆炸:相反,如果权重矩阵的值很大,梯度在反向传播过程中可能会指数级增长,导致数值溢出和训练过程的不稳定。 虽然梯度爆炸可以通过梯度裁剪(Gradient Clipping)等技术相对容易地解决,但梯度消失问题则更为棘手。
由于梯度消失问题,简单 RNN 的“记忆”实际上是相当短期的,这限制了它们在需要理解长篇文本或分析长期时间序列等任务中的应用。
2.5 代码实现:使用 TensorFlow/Keras 构建简单 RNN
点击链接深入探索序列学习:循环神经网络(RNN)及其变体(LSTM、GRU)的详尽解析阅读原文