庖丁解牛:深度剖析 Ascend C 算子开发流程与核心概念
摘要:本文作为 Ascend C 算子开发的系统性入门指南,将深入解析其两种核心开发流程、算子工程的基本结构、Host/Device 协同分工机制以及 Tiling 技术。文章不仅包含理论剖析,还提供了基于 Sigmoid 算子的完整代码案例,从工程创建到内核实现,逐步展示如何构建一个功能正确的 Ascend C 算子,为读者奠定坚实的实践基础。
1. 背景介绍:为何需要 Ascend C?
人工智能模型正变得日益复杂,对计算效率和能耗的要求达到了前所未有的高度。通用处理器(CPU)在处理大规模并行计算时显得力不从心,因此,专为 AI 计算设计的神经网络处理器(NPU, Neural Processing Unit),如华为的昇腾(Ascend)系列,应运而生。然而,硬件只是基础,要充分发挥其极致性能,离不开与之匹配的软件栈。
昇腾计算架构(CANN, Compute Architecture for Neural Networks)是华为推出的全栈AI软件平台,而 Ascend C正是 CANN 中面向昇腾 AI 处理器进行高性能算子开发的关键组件。它并非一种全新的编程语言,而是基于标准 C/C++ 的一套扩展语法和应用编程接口(API, Application Programming Interface)库。Ascend C 允许开发者直接、精细地控制 AI 核心的计算单元、内存体系和任务流水线,从而实现对各类算子(如卷积、池化、激活函数等)的深度优化,满足不同场景下对低延迟、高吞吐的严苛需求。掌握 Ascend C,意味着获得了在昇腾硬件上释放最大计算潜力的钥匙。
2. 两种算子开发流程详解与选择策略
根据素材,Ascend C 算子开发主要有两种主导流程,它们面向不同的开发阶段和目标。
2.1 基于 Kernel 的调试方式(Kernel-First Debugging)
这种方式的核心思想是“聚焦核心,快速迭代”。它允许开发者脱离上层AI框架(如MindSpore)的复杂性,在一个相对纯净的环境中,优先验证算子在设备(Device)(即AI核心)上的计算逻辑正确性和基础性能。
-
适用场景:算法原型验证、Kernel 性能瓶颈分析(如计算密度(Compute Intensity)评估)、新算子功能正确性初步检查。
-
流程特点:
-
环境隔离:编写独立的核函数(Kernel Function)和简单的测试用主机(Host)代码。
-
专用编译:使用
ascendcl或msopgen等工具直接编译生成可执行文件或.o目标文件。 -
直接运行:通过命令行工具(如
acl_exec)加载并执行 Kernel,获取结果和基础性能数据。
-
-
优势:反馈链路极短,能快速定位计算逻辑问题,非常适合算子开发的早期阶段。
2.2 基于命令行/图形的调试方式(Framework-Integrated Development)
这种方式是面向生产的“标准流程”,旨在开发出能被 AI 框架直接调用的、功能完整的算子。它涵盖了从算子实现到框架集成的全过程。
-
适用场景:为最终在推理或训练平台中部署而开发正式算子。
-
流程特点:
-
工程完备:需要创建符合 CANN 规范的完整算子工程,包含 Kernel 实现、应用程序二进制接口(ABI, Application Binary Interface)封装、算子信息库定义等。
-
框架对接:需要编写 TBE(Tensor Boost Engine)算子定义文件或插件代码,将 Ascend C Kernel 与框架(如MindSpore)的算子接口进行绑定。
-
集成调试:可以在框架内编写网络模型,调用自定义算子进行端到端的测试,验证算子在真实工作流中的行为。
-
-
优势:功能完整,成果可直接集成到AI应用中,是算子开发的“毕业设计”。
流程对比与选择决策图: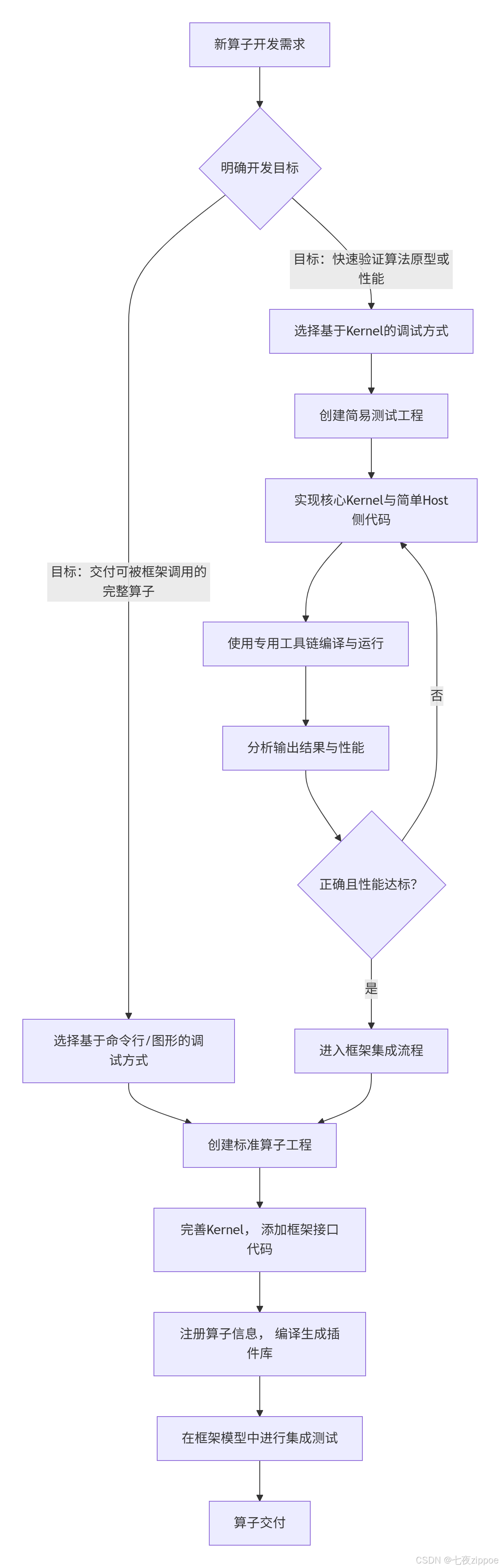
3. 算子工程核心结构:Host 与 Device 的协同作战
理解 Host 和 Device 的职责分工是编写 Ascend C 代码的基石。这是一种典型的异构计算(Heterogeneous Computing)模型。
3.1 Device 侧:计算任务的执行者
-
物理位置:昇腾 AI 核心。
-
核心职责:执行高度并行的张量(Tensor)计算。
-
关键概念:
-
核函数(Kernel Function):使用
__global__ __aicore__关键字修饰的函数,是计算任务的入口。当 Host 侧调用后,会在 AI Core 上启动大量实例(例如,一个实例处理一个数据分块),并行执行。 -
计算流水线(Pipeline):在 Kernel 内部,通过 Ascend C API 组织“数据搬运->计算->结果写回”的流水线操作,以隐藏内存访问延迟,提升计算单元利用率。
-
3.2 Host 侧:资源管理与任务调度的大脑
-
物理位置:中央处理器(CPU)。
-
核心职责:设备管理、资源分配、任务调度与同步。
-
关键任务:
-
设备初始化:通过
aclInit等 API 初始化昇腾设备运行环境。 -
内存管理:在主机内存(Host Memory)和设备内存(Device Memory)上为输入/输出张量分配空间(
aclMalloc)。 -
数据搬运:通过 直接内存访问(DMA, Direct Memory Access)或
aclrtMemcpy接口,在 Host 和 Device 间高效搬运数据。 -
内核启动:设置 Kernel 参数(数据指针、Tiling参数等),并通过
rtKernelLaunch将其放入任务队列,触发 Device 执行。 -
事件同步:使用
rtEvent等机制,等待 Kernel 执行完成,再安全地读取结果。
-
Host-Device 交互序列图:
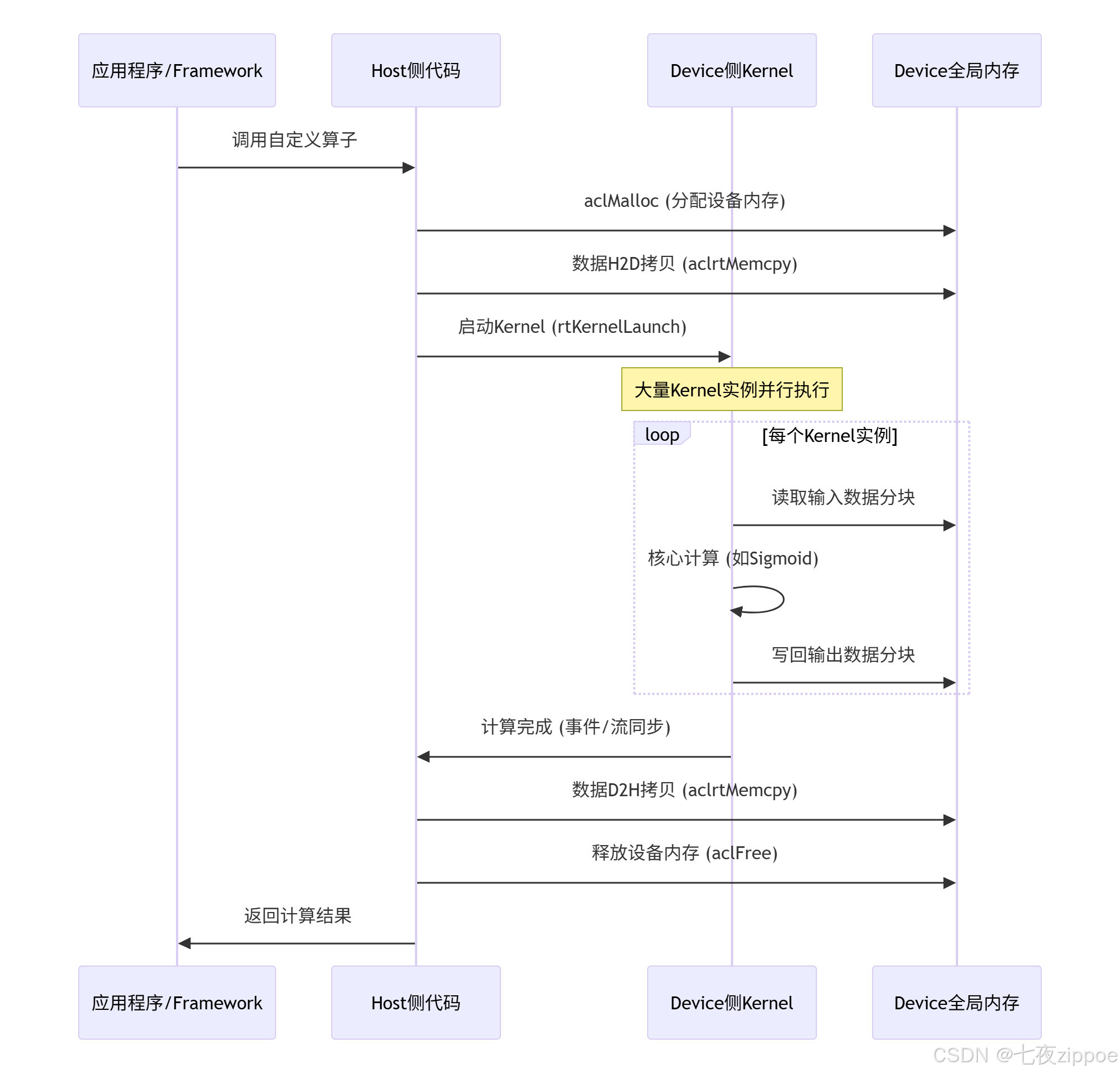
4. Tiling 技术:实现高效数据并行的关键
由于 AI 核心的片上缓存(On-chip Buffer)(如统一缓冲区(UB, Unified Buffer))容量有限,而待处理的张量可能非常大(例如,一个 1024x1024 的矩阵),无法一次性全部加载到片上进行高速计算。Tiling(分块)技术就是将这个大张量在逻辑上分割成许多个小块(Tiles),使得每个小块能够被单个 Kernel 实例处理并放入 UB 中。
Tiling 策略结构体示例(以Sigmoid为例):
素材中提到了 Sigmoid 算子的 Tiling 结构,我们可以在代码中定义如下:
// 示例:Sigmoid算子的Tiling参数结构体
// 该结构体在Host和Device侧需保持严格一致
typedef struct {uint32_t totalLength; // 数据的总长度(以字节或元素个数计)uint32_t tileLength; // 每个分块(Tile)的长度uint32_t tileNum; // 总的分块数量// 可能还有其他参数,如每个分块的对齐长度等
} SlogdTiling;-
Host 侧计算 Tiling:在 Host 侧,需要根据输入张量的形状(Shape)动态计算出 Tiling 参数。例如,总数据量
totalLength,再根据 UB 大小和数据类型确定最优的tileLength,最后计算出tileNum = (totalLength + tileLength - 1) / tileLength。 -
Kernel 侧使用 Tiling:每个 Kernel 实例通过内置的
GetBlockIdx()函数获取自己的块索引(Block Index),然后根据 Tiling 参数计算出自己负责的数据块的起始地址和长度。
5. 代码实战:实现一个完整的 Sigmoid 算子
下面我们以一个简单的 Sigmoid 算子为例,展示基于 Kernel 调试方式的代码框架。
步骤 1:定义 Kernel 函数(Device侧)
// sigmoid_kernel.h
#ifndef __SIGMOID_KERNEL_H__
#define __SIGMOID_KERNEL_H__#include <acl/acl.h>
#include <cce/cce.h>// 1. 定义Tiling结构体(必须与Host侧一致)
typedef struct {uint32_t totalLength;uint32_t tileLength;uint32_t tileNum;
} SlogdTiling;// 2. 声明核函数
extern "C" __global__ __aicore__ void sigmoid_custom(SlogdTiling* tiling, half* x, half* y);#endif // __SIGMOID_KERNEL_H__// sigmoid_kernel.cc
#include "sigmoid_kernel.h"// 3. 实现核函数
extern "C" __global__ __aicore__ void sigmoid_custom(SlogdTiling* tiling, half* x, half* y) {// 获取当前Kernel实例的块索引uint32_t idx = GetBlockIdx();// 计算该实例要处理的数据在全局内存中的偏移量uint32_t offset = idx * tiling->tileLength;// 计算实际要处理的数据长度(最后一个分块可能不满)uint32_t length = (idx == (tiling->tileNum - 1)) ? (tiling->totalLength - offset) : tiling->tileLength;// 检查有效性if (offset >= tiling->totalLength) {return;}// 核心计算循环:对每个数据元素应用Sigmoid函数: y = 1 / (1 + exp(-x))for (uint32_t i = 0; i < length; ++i) {half input_val = x[offset + i];// 使用Ascend C内置的exp函数(具体API名称需查阅文档)// half exp_val = exp(-input_val);// half output_val = 1.0 / (1.0 + exp_val);// 为简化示例,这里使用近似计算或查表法在实际中更常见// 此处用伪代码表示计算逻辑half output_val = 1.0 / (1.0 + exp(-(float)input_val)); // 注意类型转换和实际APIy[offset + i] = output_val;}
}代码说明:这是一个高度简化的示例。实际生产中,Sigmoid 计算会使用高度优化的指令(如 vec_sigmoid)或在 UB 中进行向量化计算,而非逐元素处理。
步骤 2:编写 Host 侧代码
// sigmoid_main.cc
#include <iostream>
#include "sigmoid_kernel.h"
#include "acl/acl.h"int main() {// 1. 初始化aclError ret = aclInit(nullptr);// ... 错误检查// 2. 设置设备int deviceId = 0;ret = aclrtSetDevice(deviceId);// ... 错误检查// 3. 准备数据:假设我们有一个长度为1024的half类型数组const uint32_t totalElements = 1024;size_t inputSize = totalElements * sizeof(half);half* hostInput = (half*)aclrtMallocHost(inputSize); // 分配Host锁页内存half* hostOutput = (half*)aclrtMallocHost(inputSize);// 初始化hostInput数据...for (int i = 0; i < totalElements; ++i) {hostInput[i] = (half)(i * 0.1f);}// 4. 分配Device内存half* deviceInput = nullptr;half* deviceOutput = nullptr;aclrtMalloc((void**)&deviceInput, inputSize, ACL_MEM_MALLOC_HUGE_FIRST);aclrtMalloc((void**)&deviceOutput, inputSize, ACL_MEM_MALLOC_HUGE_FIRST);// 5. 计算Tiling参数SlogdTiling tiling;tiling.totalLength = totalElements;tiling.tileLength = 256; // 假设每个块处理256个元素tiling.tileNum = (totalElements + tiling.tileLength - 1) / tiling.tileLength;// 分配并拷贝Tiling结构体到DeviceSlogdTiling* deviceTiling = nullptr;aclrtMalloc((void**)&deviceTiling, sizeof(SlogdTiling), ACL_MEM_MALLOC_HUGE_FIRST);aclrtMemcpy(deviceTiling, sizeof(SlogdTiling), &tiling, sizeof(SlogdTiling), ACL_MEMCPY_HOST_TO_DEVICE);// 6. 数据H2DaclrtMemcpy(deviceInput, inputSize, hostInput, inputSize, ACL_MEMCPY_HOST_TO_DEVICE);// 7. 启动Kernel (此处为伪代码,实际使用rtKernelLaunch)// ret = rtKernelLaunch(sigmoid_custom, tiling.tileNum, ...);std::cout << "Launching Kernel with " << tiling.tileNum << " blocks." << std::endl;// 8. 同步等待aclrtSynchronizeDevice();// 9. 数据D2HaclrtMemcpy(hostOutput, inputSize, deviceOutput, inputSize, ACL_MEMCPY_DEVICE_TO_HOST);// 10. 验证结果(简单打印前几个)std::cout << "First 5 results: ";for (int i = 0; i < 5; ++i) {std::cout << (float)hostOutput[i] << " ";}std::cout << std::endl;// 11. 释放资源aclrtFree(deviceTiling);aclrtFree(deviceInput);aclrtFree(deviceOutput);aclrtFreeHost(hostInput);aclrtFreeHost(hostOutput);aclrtResetDevice(deviceId);aclFinalize();return 0;
}6. 总结与思考
本文系统性地构建了 Ascend C 算子开发的整体认知框架。我们从两种开发流程的选择策略入手,深入剖析了 Host-Device 异构编程模型的分工与协作,并详解了 Tiling 这一核心优化技术。最后,通过一个完整的 Sigmoid 算子代码案例,将理论付诸实践,展示了从内存管理、任务下发到内核计算的全过程。
-
核心要点归纳:
-
流程选择:根据开发阶段(原型验证 vs. 生产交付)选择“Kernel优先”或“框架集成”流程。
-
异构思维:深刻理解 Host(管理)与 Device(计算)的职责分离是成功编程的关键。
-
性能基石:Tiling 是解决有限片上缓存与大规模数据矛盾、实现高效并行的核心技术。
-
实践出真知:通过完整的代码工程理解内存管理、数据搬运和内核启动的每一个细节。
-
-
讨论与思考:
-
在本文的 Sigmoid 示例中,Kernel 内的计算是逐元素进行的,效率很低。请思考,如何利用 Ascend C 的向量编程(Vector Programming)指令(如
vec_sigmoid)对计算进行优化? -
Tiling 策略中的
tileLength取值并非越大越好或越小越好。它受到哪些硬件资源(如 UB 大小)和软件因素(如数据对齐)的约束?如何理论推导或实验找到一个最优值?
-
7. 参考链接
-
华为昇腾社区:获取 CANN 软件包、模型、文档和教程的核心门户。
-
Ascend C 官方文档:最权威的编程指南、API参考手册和内核开发指南(需登录昇腾社区)。
-
MindSpore 算子开发指南:了解如何在 MindSpore 框架中集成自定义 Ascend C 算子。