MVCC核心原理解密:从隐藏字段到版本链的完整解析

一、背景
在数据库系统和分布式系统中,并发控制是确保数据一致性和系统性能的关键挑战。随着互联网应用的快速发展和用户规模的不断扩大,高并发场景下的数据访问需求日益增长,传统的基于锁的并发控制机制在性能方面逐渐暴露出明显的不足。
传统的基于锁的并发控制机制虽然能够保证数据一致性,但在高并发场景下往往会导致严重的性能问题,如读写阻塞、死锁等。为了解决这些问题,多版本并发控制(Multi-Version Concurrency Control,MVCC)技术应运而生。
MVCC作为一种高效的并发控制机制,被广泛应用于现代数据库系统中,如MySQL的InnoDB存储引擎、PostgreSQL、Oracle等。它通过保存数据的多个版本,使得读写操作可以并发执行而不互相阻塞,极大地提升了系统在高并发场景下的性能表现。
近年来,MVCC的思想也被扩展到分布式系统、内存数据库、浏览器环境等领域,成为构建高性能并发系统的重要技术基础。
二、MVCC解决的核心问题
2.1 传统锁机制的局限性
传统的基于锁的并发控制机制在处理并发访问时存在以下主要问题:
- 读写阻塞:读操作会被写操作持有的锁阻塞,写操作也会被读操作持有的锁阻塞,导致并发性能下降
- 死锁问题:多事务相互等待对方释放锁资源,可能导致死锁
- 锁粒度难以平衡:粗粒度锁(如表锁)并发性能差,细粒度锁(如行锁)管理开销大
- 长事务影响:长时间运行的事务持有锁会阻塞其他事务,降低系统吞吐量
- 隔离级别与性能矛盾:提高隔离级别通常需要更严格的锁机制,进一步降低性能
2.2 MVCC解决的问题
MVCC通过创新性的多版本管理机制,有效解决了以下关键问题:
- 读写冲突问题:通过为每个事务提供独立的数据快照,彻底消除了读写操作之间的阻塞
- 一致性读保证:确保事务看到的数据满足其隔离级别要求,不受其他并发事务的影响
- 提高并发性能:减少锁的使用,降低锁竞争,提升系统吞吐量
- 简化并发控制逻辑:基于乐观并发控制思想,简化了并发控制的实现复杂度
- 避免部分死锁场景:由于减少了显式锁的使用,降低了死锁发生的概率
- 支持不同隔离级别:通过灵活的Read View生成策略,支持不同的事务隔离级别
2.3 MVCC的优势体现
相比传统锁机制,MVCC的优势主要体现在:
- 高并发性能:读操作不阻塞写操作,写操作不阻塞读操作
- 更好的用户体验:读操作不会被长时间阻塞,响应更加迅速
- 资源利用率高:系统资源得到更充分的利用
- 可扩展性强:在高并发场景下表现更加稳定
- 适合读多写少场景:特别适合需要高读取性能的应用场景
三、MVCC核心概念与特性
3.1 基本概念
MVCC的核心思想是通过维护数据的多个版本,使得每个事务在读取数据时能够看到一个特定时间点的数据快照,而不受其他事务写入操作的影响。这种机制巧妙地解决了读写冲突问题,实现了"读取不阻塞写入,写入不阻塞读取"的理想并发模型。
3.2 关键特性
- 非阻塞读取:读操作不会被写操作阻塞,反之亦然
- 隔离性保证:为不同事务提供不同的数据视图,确保事务隔离
- 乐观并发控制:基于版本比较而非锁机制实现并发控制
- 提高并发性能:减少锁竞争,提升系统吞吐量
- 简化死锁处理:由于减少了显式锁的使用,降低了死锁发生的概率
- 多版本管理:同一数据项可以同时存在多个版本,满足不同事务的读取需求
3.3 算法核心思想
MVCC的算法核心思想可以概括为以下几点:
- 版本化数据:对每个数据修改操作,不直接覆盖原有数据,而是创建一个新的版本
- 快照隔离:每个事务在开始时获取一个数据快照,之后的所有读取操作都基于这个快照
- 可见性规则:定义了不同版本数据对不同事务的可见性规则
- 垃圾回收:定期清理不再被任何事务引用的旧版本数据
四、MVCC底层原理与实现机制
4.1 核心组成部分
MVCC的实现主要依赖于以下几个关键组件:
4.1.1 隐藏字段
在支持MVCC的数据库系统中,每行数据通常包含几个隐藏字段:
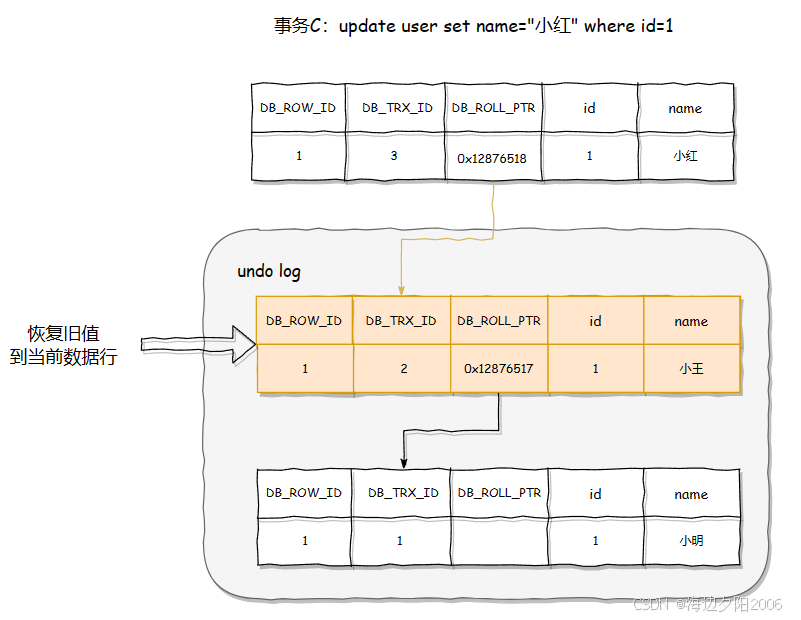
- 事务ID(DB_TRX_ID):该字段存储了当前行数据所属的事务ID。每个事务在数据库中都有一个唯一的事务ID。通过 DB_TRX_ID 字段,可以追踪行数据和事务的所属关系。
- 回滚指针(DB_ROLL_PTR):指向该行数据的上一个版本,形成版本链
- 行标识(DB_ROW_ID):隐含的自增ID(隐藏主键),用于唯一标识表中的每一行数据,如果数据表没有主键,数据库会自动以DB_ROW_ID产生一个聚簇索引

4.1.2 Undo Log(回滚日志)
Undo Log是MVCC实现的关键组件,它记录了数据修改前的状态,主要用于:
- 事务回滚
- 构建数据的历史版本
- 支持一致性读
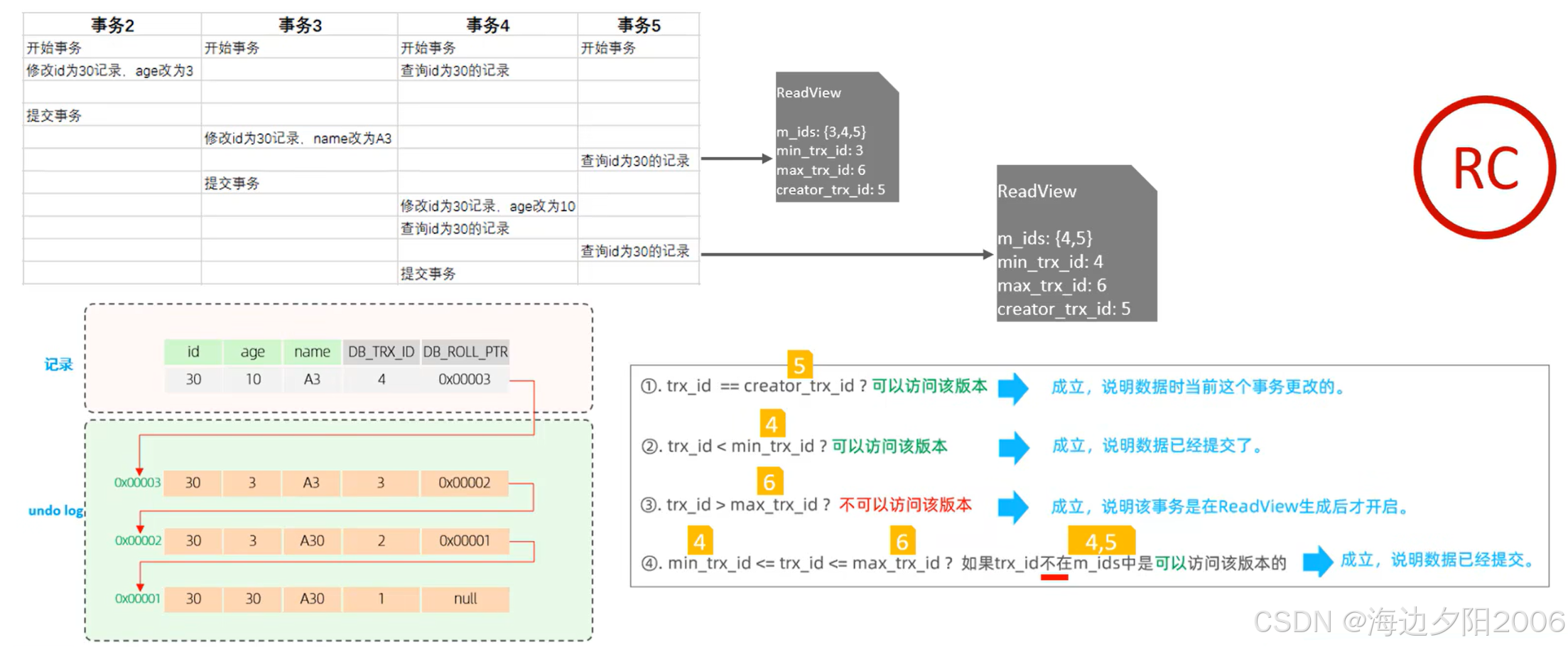
当事务修改数据时,数据库会先将修改前的数据保存到Undo Log中,然后再执行实际的数据修改。这样,当需要查看历史版本时,可以通过回滚指针链找到相应的Undo Log记录。如下图所示:
4.1.3 Read View(读视图)
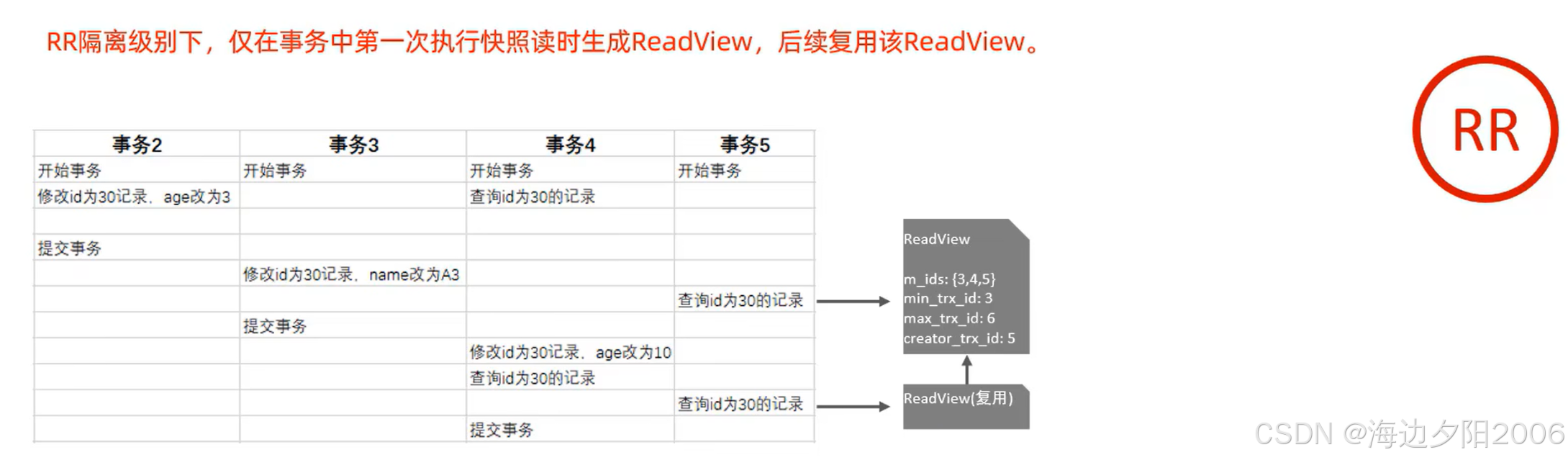
Read View是MVCC中用于判断数据版本可见性的重要结构,它包含以下关键信息:
- m_ids:当前活跃的事务ID列表
- min_trx_id:活跃事务中的最小事务ID
- max_trx_id:系统应该分配给下一个事务的ID
- creator_trx_id:创建该Read View的事务ID
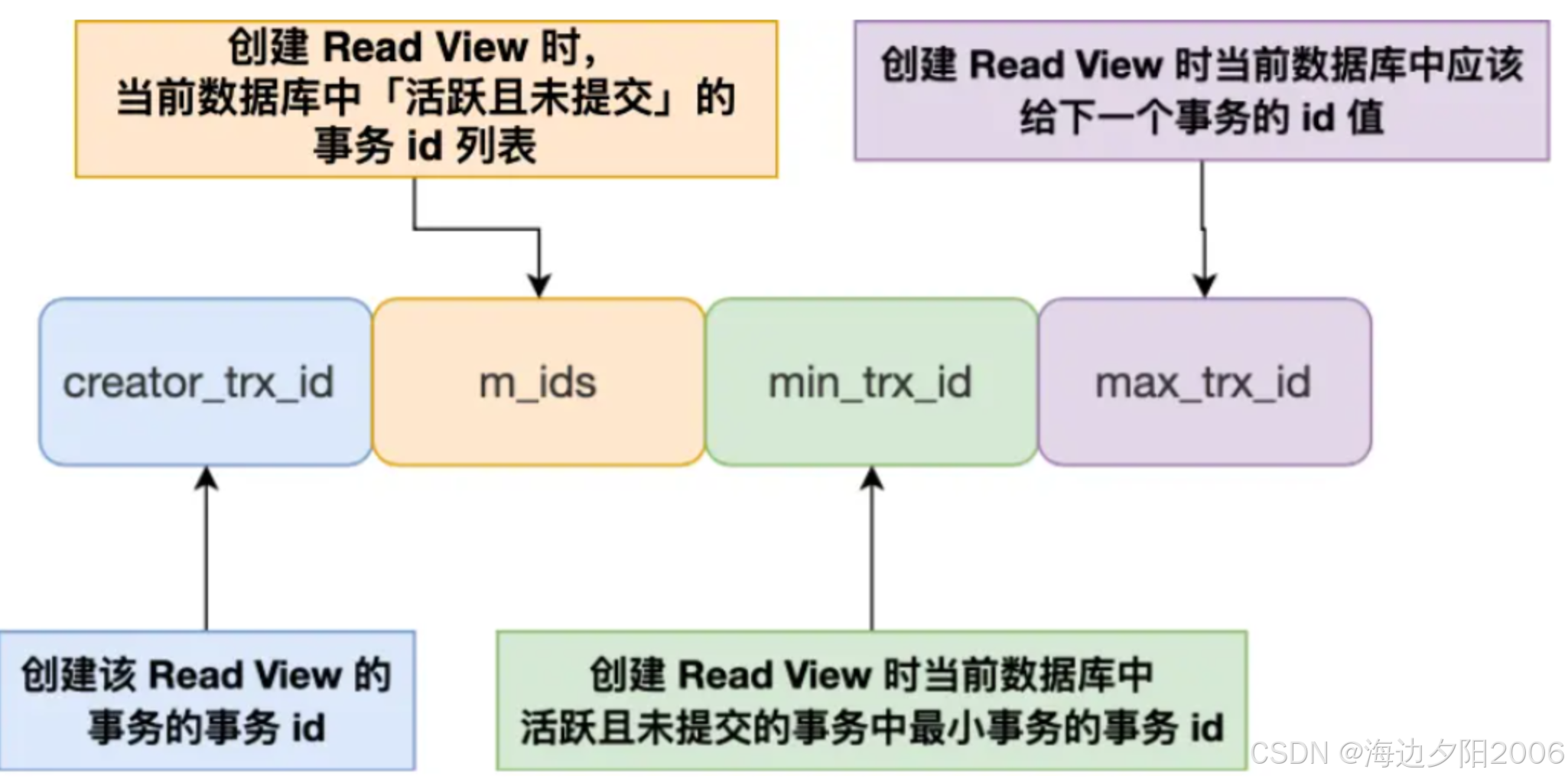
通过Read View,数据库可以判断某个版本的数据对当前事务是否可见,从而实现一致性读。
4.1.4 版本链
版本链是通过回滚指针将同一数据的多个版本连接起来形成的链表结构。
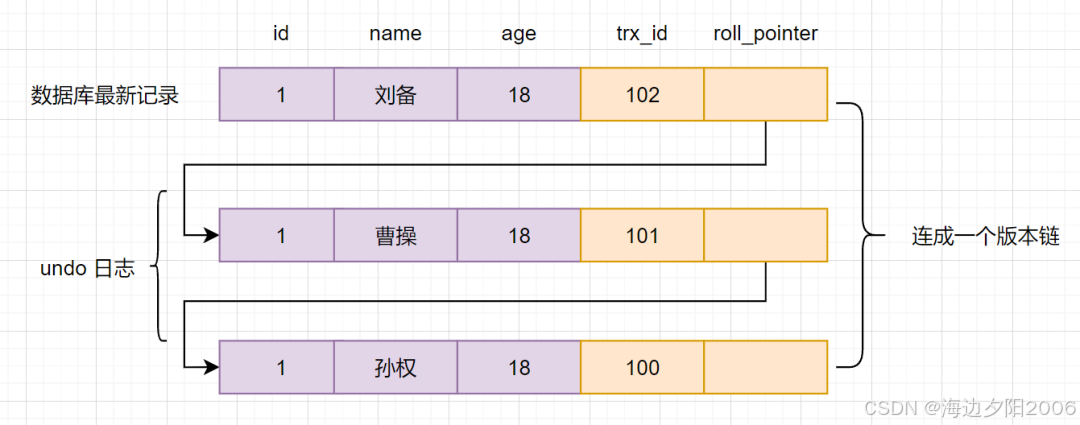
每当数据被修改时,数据库会:
- 将旧版本数据保存到Undo Log
- 在新数据中设置回滚指针指向Undo Log中的旧版本
- 更新事务ID为当前事务的ID
这样,通过回滚指针就可以遍历数据的所有历史版本。
4.2 可见性规则
在MVCC中,判断数据版本对某个事务是否可见的规则如下:
- 如果数据版本的事务ID等于当前事务的ID,则该版本对当前事务可见
- 如果数据版本的事务ID小于Read View中的min_trx_id,则表示该版本是由已提交的事务生成的,对当前事务可见
- 如果数据版本的事务ID大于等于Read View中的max_trx_id,则表示该版本是由当前事务创建Read View后启动的事务生成的,对当前事务不可见
- 如果数据版本的事务ID在min_trx_id和max_trx_id之间,则需要检查该事务ID是否在m_ids列表中:
- 如果在,表示该事务在当前事务创建Read View时还未提交,对当前事务不可见
- 如果不在,表示该事务在当前事务创建Read View时已经提交,对当前事务可见
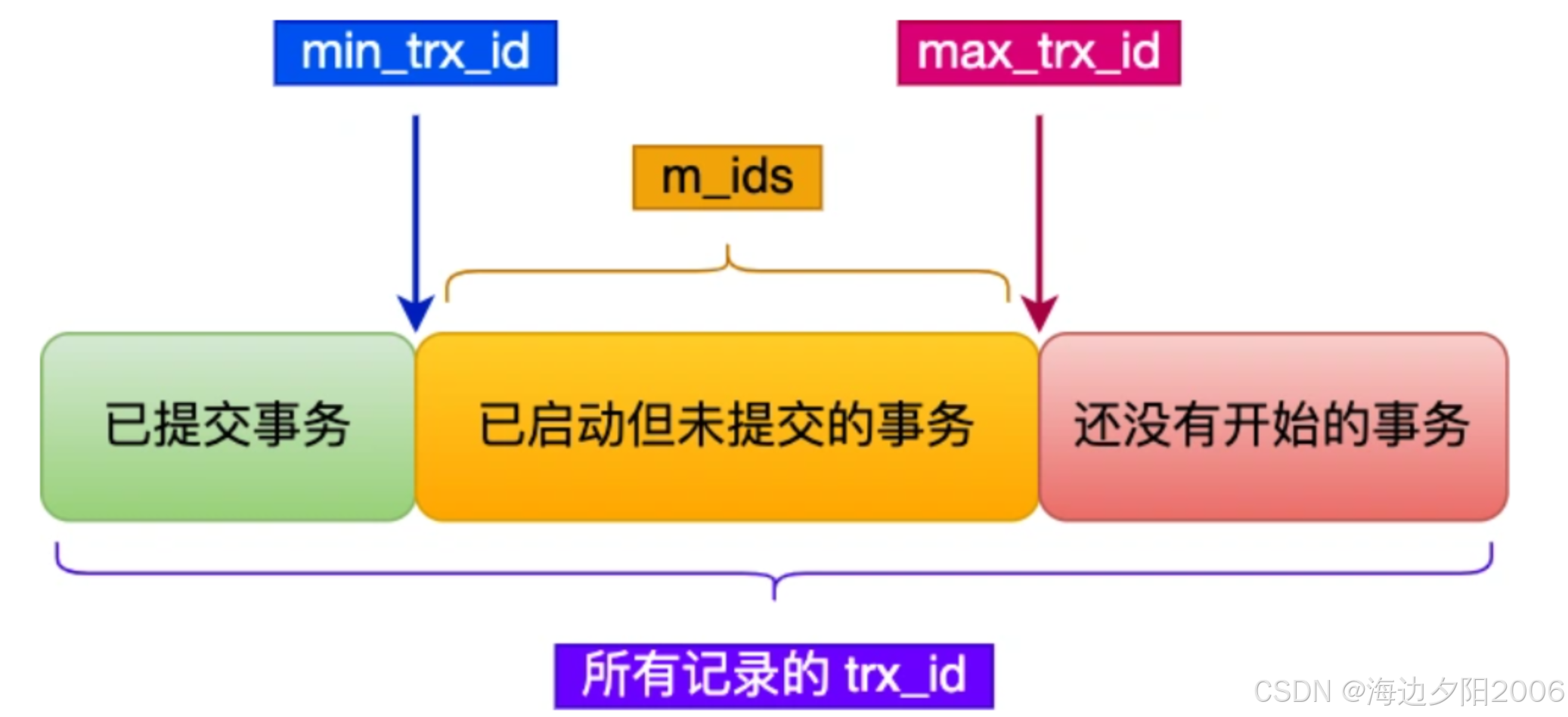
如果当前版本不可见,则通过回滚指针获取上一个版本,并重复上述判断过程,直到找到一个可见的版本或遍历完整个版本链。
4.3 事务隔离级别的实现
MVCC在不同事务隔离级别下的行为有所不同:
- READ UNCOMMITTED:不使用MVCC,直接读取最新数据
- READ COMMITTED:每次读取时都会创建新的Read View
- REPEATABLE READ:事务开始时创建一个Read View,并在整个事务期间复用
- SERIALIZABLE:通常会退化为锁机制
五、MVCC处理流程
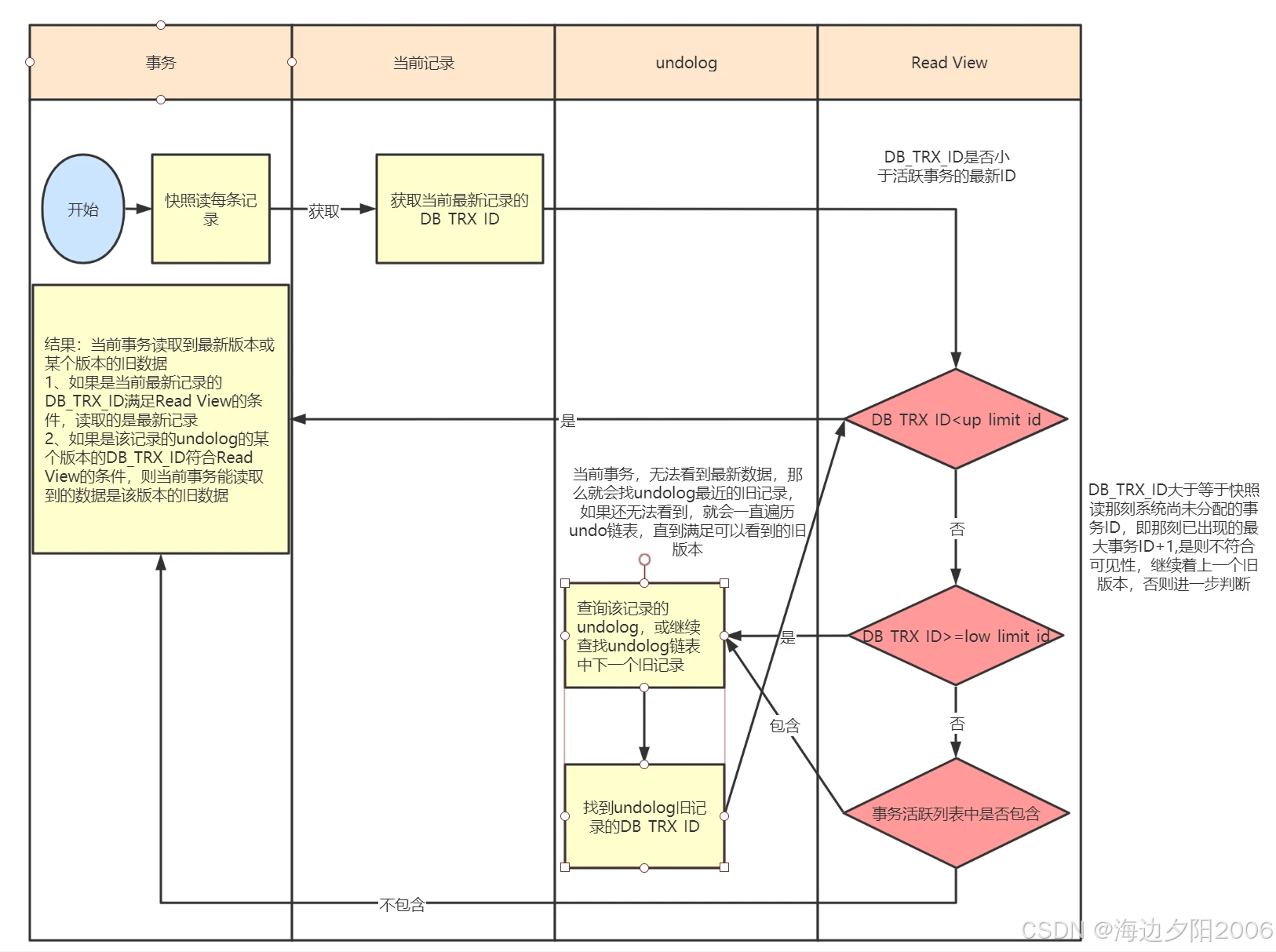
5.1 读取操作流程
当事务执行读取操作时,MVCC的处理流程如下:
- 根据事务隔离级别,创建或获取Read View
- 读取数据的最新版本
- 根据Read View和可见性规则,判断该版本是否对当前事务可见
- 如果可见,直接返回该版本数据
- 如果不可见,通过回滚指针找到上一个版本,并重复步骤3
- 直到找到一个可见的版本或遍历完整个版本链
5.2 写入操作流程
当事务执行写入操作时,MVCC的处理流程如下:
- 获取事务ID
- 读取数据的最新版本
- 如果需要修改,将修改前的数据保存到Undo Log中
- 创建新的数据版本,更新事务ID和回滚指针
- 执行实际的数据修改
- 事务提交时,数据版本生效;事务回滚时,通过Undo Log恢复数据
5.3 版本清理机制
为了避免版本链过长导致的性能问题和存储空间浪费,MVCC需要定期清理不再需要的旧版本数据:
- Purge操作:数据库后台会定期执行Purge操作,清理不再被任何活跃事务引用的旧版本数据
- 基于Read View的清理策略:通过分析活跃事务的Read View,确定哪些版本数据可以被安全删除
- 延迟清理:为了保证并发事务的正确性,通常会延迟一段时间后再清理旧版本数据
六、MVCC适用场景与实际应用
6.1 适用场景
MVCC特别适合以下场景:
- 读多写少的应用:如内容管理系统、新闻网站等
- 需要高并发读取性能的场景:如电商网站的商品浏览、搜索引擎结果展示等
- 对一致性要求较高但可以接受一定延迟的场景:如报表系统、数据分析等
- 需要长事务支持的场景:如复杂的业务流程处理
6.2 实际应用案例
6.2.1 MySQL InnoDB
MySQL的InnoDB存储引擎是MVCC的典型实现,它通过以下方式实现MVCC:
- 使用隐藏字段(DB_TRX_ID、DB_ROLL_PTR等)跟踪数据版本
- 利用Undo Log存储历史版本数据
- 通过Read View机制实现不同隔离级别的一致性读
6.2.2 PostgreSQL
PostgreSQL也实现了MVCC,它的特点是:
- 为每行数据维护xmin(插入事务ID)和xmax(删除/更新事务ID)
- 基于时间戳的可见性判断
- 定期执行VACUUM操作清理旧版本数据
6.2.3 分布式系统中的应用
在分布式系统中,MVCC也得到了广泛应用,如:
- etcd:使用MVCC实现一致性读和并发控制
- 分布式数据库:通过全局事务ID和版本管理实现分布式环境下的MVCC
- 内存数据库:如Redis的多版本特性
七、MVCC Java实现示例
下面是一个简单的Java代码示例,演示了MVCC的基本实现原理:
import java.util.*;
import java.util.concurrent.ConcurrentHashMap;
import java.util.concurrent.atomic.AtomicLong;/*** MVCC多版本并发控制简单实现*/
public class MVCCDemo {// 全局事务ID生成器private static final AtomicLong TRANSACTION_ID_GENERATOR = new AtomicLong(1); // 存储数据的多版本映射private static final ConcurrentHashMap<String, VersionChain> DATA_STORE = new ConcurrentHashMap<>(); // 活跃事务集合private static final Set<Long> ACTIVE_TRANSACTIONS = Collections.newSetFromMap(new ConcurrentHashMap<>());/*** 数据版本*/static class DataVersion {private final Object data; // 实际数据private final long trxId; // 创建该版本的事务IDprivate final DataVersion prev; // 前一个版本的引用public DataVersion(Object data, long trxId, DataVersion prev) {this.data = data;this.trxId = trxId;this.prev = prev;}}/*** 版本链*/static class VersionChain {private volatile DataVersion head; // 最新版本public synchronized void addVersion(Object data, long trxId) {head = new DataVersion(data, trxId, head);}public DataVersion getHead() {return head;}}/*** 读视图*/static class ReadView {private final Set<Long> activeTrxIds; // 活跃事务ID集合private final long minTrxId; // 最小活跃事务IDprivate final long maxTrxId; // 最大活跃事务IDprivate final long creatorTrxId; // 创建者事务IDpublic ReadView(long creatorTrxId) {this.creatorTrxId = creatorTrxId;// 复制当前活跃事务ID集合this.activeTrxIds = new HashSet<>(ACTIVE_TRANSACTIONS); // 计算最小和最大活跃事务IDif (activeTrxIds.isEmpty()) {this.minTrxId = Long.MAX_VALUE;this.maxTrxId = 0;} else {this.minTrxId = Collections.min(activeTrxIds);this.maxTrxId = Collections.max(activeTrxIds);}}/*** 判断数据版本是否可见*/public boolean isVisible(DataVersion version) {long trxId = version.trxId;// 1. 如果是当前事务修改的,可见if (trxId == creatorTrxId) {return true;} // 2. 如果事务ID小于最小活跃事务ID,表示该事务已提交,可见if (trxId < minTrxId) {return true;} // 3. 如果事务ID大于最大活跃事务ID,表示该事务是在ReadView创建后开始的,不可见if (trxId > maxTrxId) {return false;} // 4. 如果事务ID在活跃事务集合中,说明创建ReadView时该事务还未提交,不可见return !activeTrxIds.contains(trxId);}}/*** 事务类*/static class Transaction {private final long trxId;private final ReadView readView;private boolean active = true;public Transaction() {this.trxId = TRANSACTION_ID_GENERATOR.getAndIncrement();// 注册为活跃事务ACTIVE_TRANSACTIONS.add(trxId);// 创建读视图this.readView = new ReadView(trxId);}/*** 读取数据*/public Object read(String key) {if (!active) {throw new IllegalStateException("Transaction is not active");}VersionChain chain = DATA_STORE.get(key);if (chain == null) {return null;} // 查找可见的数据版本DataVersion version = chain.getHead();while (version != null) {if (readView.isVisible(version)) {return version.data;}version = version.prev;} return null;}/*** 写入数据*/public void write(String key, Object value) {if (!active) {throw new IllegalStateException("Transaction is not active");} DATA_STORE.computeIfAbsent(key, k -> new VersionChain()).addVersion(value, trxId);}/*** 提交事务*/public void commit() {if (!active) {throw new IllegalStateException("Transaction is not active");}active = false;// 从活跃事务集合中移除ACTIVE_TRANSACTIONS.remove(trxId);}/*** 回滚事务*/public void rollback() {if (!active) {throw new IllegalStateException("Transaction is not active");}active = false;// 从活跃事务集合中移除ACTIVE_TRANSACTIONS.remove(trxId); // 注意:在实际实现中,这里需要清理该事务创建的数据版本// 本示例简化处理}}/*** 开始新事务*/public static Transaction beginTransaction() {return new Transaction();}/*** 示例运行*/public static void main(String[] args) {// 初始化数据Transaction txInit = beginTransaction();txInit.write("user1", "Alice");txInit.commit();// 事务2: 开始读取Transaction tx2 = beginTransaction();System.out.println("Tx2 reads user1: " + tx2.read("user1")); // 应该读取到Alice// 事务3: 更新数据Transaction tx3 = beginTransaction();tx3.write("user1", "Bob");System.out.println("Tx3 updates user1 to Bob");// 事务2再次读取,应该仍然看到Alice(隔离级别为REPEATABLE READ)System.out.println("Tx2 reads user1 again: " + tx2.read("user1"));// 事务3提交tx3.commit();// 事务2再次读取,在REPEATABLE READ级别下仍然看到AliceSystem.out.println("Tx2 reads user1 after tx3 commit: " + tx2.read("user1"));// 事务2提交tx2.commit();// 新事务4读取,应该看到BobTransaction tx4 = beginTransaction();System.out.println("Tx4 reads user1: " + tx4.read("user1"));tx4.commit();}
}
这个示例演示了MVCC的核心概念:
- 版本链:每个数据项维护多个版本
- 事务ID:唯一标识每个事务
- Read View:判断数据版本可见性
- 活跃事务管理:跟踪当前活跃的事务
八、MVCC使用误区与常见问题
8.1 常见误区
- 误以为MVCC可以解决所有并发问题:MVCC主要解决读写冲突,但对于写写冲突仍需要锁机制
- 忽视版本链过长的性能影响:长期运行的事务可能导致版本链过长,影响查询性能
- 误解隔离级别:不同隔离级别下MVCC的行为不同,需要根据业务需求选择合适的隔离级别
- 认为MVCC不需要锁:MVCC与锁机制往往结合使用,MVCC解决读写冲突,锁机制解决写写冲突
8.2 性能考量
- 存储空间开销:维护多个版本需要额外的存储空间
- 垃圾回收压力:需要定期清理不再使用的旧版本
- 版本链遍历成本:查询时可能需要遍历较长的版本链
- 事务ID管理开销:分布式环境下事务ID的生成和管理更加复杂
8.3 最佳实践
- 避免长事务:长事务会阻止旧版本数据的回收,导致存储空间膨胀
- 合理设置事务隔离级别:根据业务需求选择适当的隔离级别
- 定期维护:对于使用MVCC的数据库,需要定期进行维护操作,如MySQL的purge操作或PostgreSQL的vacuum
- 优化索引:良好的索引设计可以减少版本链的遍历时间
- 监控版本链长度:定期监控版本链的长度,及时发现潜在问题
九、MVCC扩展与未来发展
9.1 MVCC在分布式系统中的应用
随着分布式系统的普及,MVCC思想也被应用到分布式事务处理中。例如,在分布式数据库中,全局事务ID的分配和管理变得更加复杂,需要考虑分布式环境下的一致性问题。
etcd等分布式协调系统也采用了MVCC机制,通过维护数据的多个版本,实现了高效的并发控制和一致性保证。分布式环境下的MVCC需要解决以下挑战:
- 全局事务ID的生成和分配
- 跨节点的版本同步
- 分布式环境下的垃圾回收
9.2 结合其他并发控制机制
现代数据库系统往往会结合MVCC和锁机制,以应对不同的并发场景。例如,对于热点数据的更新操作,可能会使用行锁来避免频繁创建新版本。
混合并发控制策略的优点:
- 结合MVCC的高并发读取性能
- 利用锁机制解决复杂的并发冲突
- 针对不同的数据特性和访问模式进行优化
9.3 新技术趋势
随着硬件技术的发展和数据库理论的进步,MVCC也在不断演进。一些新的发展趋势包括:
- 内存数据库优化:利用内存数据库技术,可以进一步提升MVCC的性能
- AI辅助优化:利用AI技术,可以智能优化版本管理策略
- 无服务器架构适配:为无服务器计算环境优化MVCC实现
- 边缘计算场景扩展:将MVCC机制扩展到边缘计算环境,支持分布式部署
- 浏览器环境实现:如PGlite在浏览器环境中实现MVCC,支持前端数据持久化和并发控制
十、总结与展望
MVCC作为一种高效的并发控制机制,已经成为现代数据库系统的核心技术之一。它通过巧妙的多版本管理机制,在保证数据一致性的同时,极大地提升了系统的并发性能。
MVCC的核心价值在于解决了读写冲突问题,使得读操作和写操作可以并发执行,这在当今高并发、大数据量的应用场景中具有重要意义。通过本文的学习,我们深入了解了MVCC的原理、实现机制和应用场景,以及如何在实际工作中正确使用和优化MVCC。
随着应用规模的不断扩大和并发需求的持续增长,MVCC技术将继续演进和完善。未来,我们可以期待更加高效、智能的MVCC实现,为各种复杂场景下的数据管理提供更好的支持。同时,MVCC的思想也将继续扩展到更多的计算领域,推动分布式系统、内存计算等技术的发展。
在实际应用中,我们需要根据具体的业务场景和性能要求,合理选择和配置MVCC相关参数,并结合其他优化策略,充分发挥MVCC的优势,构建高性能、高可靠的数据系统。