从一到无穷大 #55 提升Lakehouse查询性能:数据层面
 本作品采用知识共享署名-非商业性使用-相同方式共享 4.0 国际许可协议进行许可。
本作品采用知识共享署名-非商业性使用-相同方式共享 4.0 国际许可协议进行许可。
本作品 (李兆龙 博文, 由 李兆龙 创作),由 李兆龙 确认,转载请注明版权。
文章目录
- 引言
- 形式化证明
- 措施
- 数据本身
- 数据布局
- 维护额外信息
- 预计算
- 列更新与删除策略
- Cache
- 总结
引言
Lakehouse的加速可以总结为两个方面,计算引擎的优化和存储引擎(数据分布)的优化。之前的文章已经讨论了很多计算引擎方面的优化,本篇文章来总结基于数据分布的优化措施,用于指导技术选型以及明确当前的定位。
形式化证明
简单来说,如果计算引擎相同,一次实际读取的数据与实际需要读取的数据相差的越少,性能越高(也就是下面证明中提到的 Tightness Degree越接近1),形式化证明如下[1]:


如何使得读取的数据少,读取文件的过程快,这个过程就是本篇文章聚焦的内容,即数据层面优化方式。
措施
数据本身
- 编码算法
- 压缩算法
- Homomorphic Compression
- 文件格式
之前的文章讨论过,新的压缩方式层出不穷,基于数据特特征以及对于压缩比,数据库查询性能的取舍的不同很很多种选择:
- 数值型数据特征:包括数据规模(均值、方差、取值范围)、相邻值差异( delta 均值、方差)、重复率(连续重复值数量)、递增率(连续递增值数量)。例如重复率高的数据适配 RLE 类算法,delta 波动小的数据适配 TS_2DIFF 等差分编码。
- 文本型数据特征:包括值分布倾斜度(Zipfian 分布指数)、值域大小(不同文本值的数量)、文本长度(平均字符数)、字符重复率(连续重复字符概率)。例如分布倾斜度高的数据适配 HUFFMAN 编码,字符重复率高的数据适配 RLE 编码。
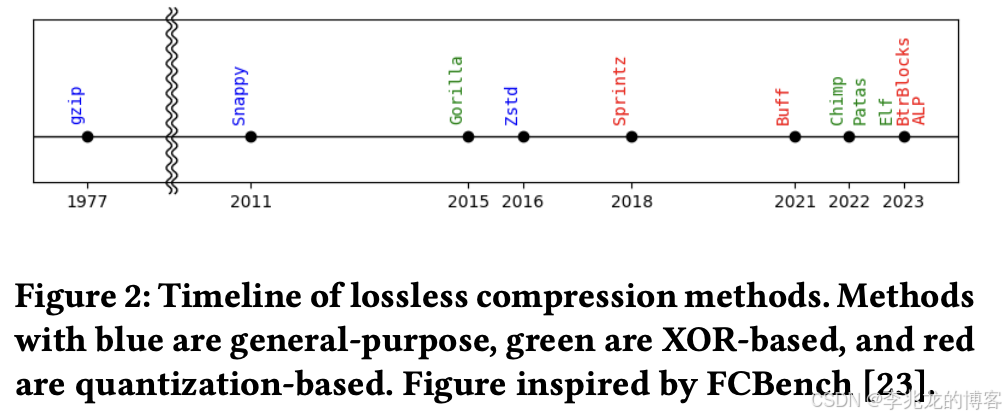 同态压缩也是一个可行的思路。
同态压缩也是一个可行的思路。
而文件格式也是一个优化的思路,伴随着宽表(特征存储),宽列(多模态数据存储)等场景的出现,基于HDFS衍生的Parquet等老牌文件格式已经出现了很多问题,比如IO放大,元数据开销高,查询内存问题等,而Lance,Nimble,Krypton等格式的演进已经很好的解决了这些问题,并均有工程使用,诸如F3等格式也解决了兼容性的问题,总而言之现在还处于新老格式的交替阶段。
Modular Encryption等安全方面的需求不在本篇文章讨论的范围内。
数据布局
- 分区:低基数、高选择度维度(如日期/地区)优先;避免过度分区造成小文件爆炸。
- Z-order/Hilbert curves:多维裁剪更友好;Hilbert 对局部性保持更好但构建复杂;Z-order 写入简单、适配广。
- Liquid Clustering:替代一次性 Z-order 的持续重排,随工作负载演化布局。
- 列重组:经常查询的列在物理布局上聚合在一起减少查询IO
- 列打包:行级查询热点列打包为 KV/稀疏行块,降低“行查询跨多列块”的 I/O。
- RowGroup合并:管理文件大小,定期重组文件,
分区自然是最简单且有效的方式,同时可以搭配查询计划的优化,减少各分区的查询条件,这在我们之前的实践中证明十分有效果。
Delta Lake中支持了Z-order和Hilbert curves,其本质思路是把高维(常见是2D/3D)数据线性化成一维键,同时尽量保留空间邻近性,这样做之后数据就可以用一维结构(排序文件)来高效存取,但仍能让范围查询/邻域查询尽可能聚簇、减少访问IO次数。后续专门写一篇文章讲 Space-filling curve。
Liquid Clustering是databricks的一个杀器级别的技术,但是这不是一种新的布局方式,而是一种自动识别用户查询模式,判断哪些分区健优势最大,再应用到现网的一种方法,这个思路我们之前用过,但是需要通过分裂修改分区方式,Liquid Clustering最大的优势是支持增量重排与更改聚簇键,这样就不需要重写整表了,当然我们之前是识别后改变分区的方式。
列重组是比较经典的解决宽列中低选择性查询的方式,通过把经常查询的列物理上组织在一起,以在查询时一次IO获取本来需要多次IO才能获取的数据。
列打包则是宽表中select * 这种扫描负载,典型的行存负载,通过把一行多个列打包在一个value中一次查询获取需要的多个指标。
RowGroup合并简单讲就是把小文件变成大文件,降低元数据开销,现网一般设定目标文件大小(常见 100MB–1GB)以平衡并行度与元数据开销。
维护额外信息
- 统计与 Zone Map(min/max、null 计数、行数):自动采集+查询时跳读;结合动态文件裁剪缩小扫描面。
- Bloom Filter:高选择度等值过滤列(如主键/设备ID/用户ID)。
- 倒排/全文/向量索引:半结构化/文本/多模态检索的旁路加速
关键点其实在与Page Index,这样可以极大的减小IO量,当前Velox parquet文件查询的单次IO是ColumnChunk级别,但是单车一天只产生6w条数据,现网文件组织格式中单个RowGroup 25MB(压缩后),存储100w行数据;Page大小定位64KB,内部2500行左右,PageIndex可以极大的降低IO大小。
但是只基于统计的做法在没有做数据聚合的时候效率非常低,比如物联网的单车查询,没10min一个文件,一天144个文件,单车的数据分布在全部的文件,如果不做数据聚合,数据就会分布在全局。
 BloomFilter对于高基数数据的过滤很有效果,[10]中给出了其测试效果
BloomFilter对于高基数数据的过滤很有效果,[10]中给出了其测试效果
在NDV 1,000, 1M cardinality的数据下表现非常好,但是也存在一些存储开销。
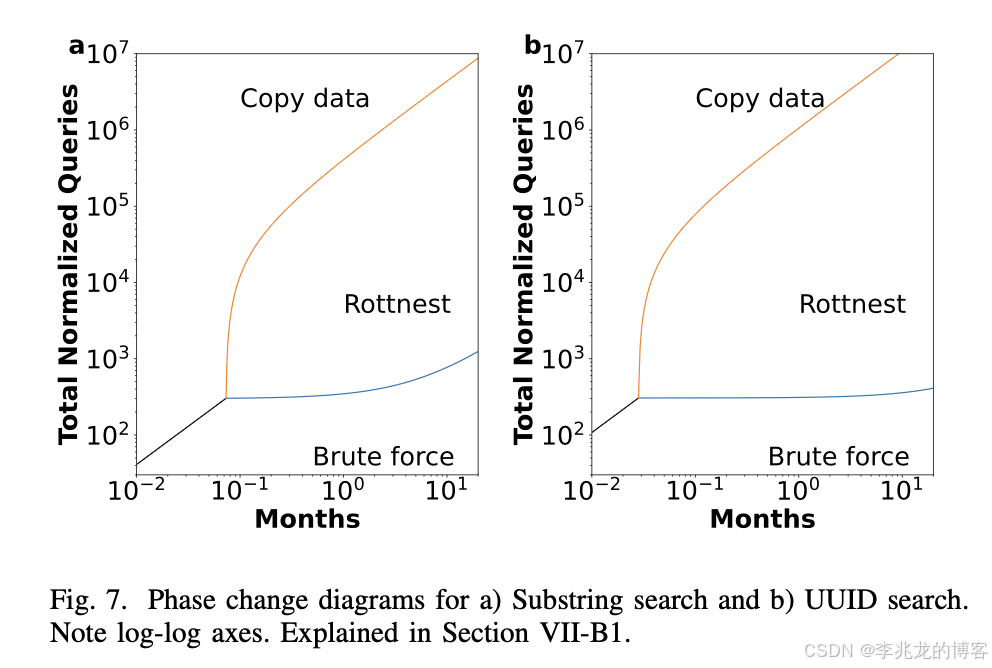
[3]中使用phase diagram描述了在不使用索引的暴力扫描,使用索引和将数据导入到三方存储中三种方法的TCO,显示在很多查询频率较少,存储时间较长的场景中,使用Lakehouse搭配索引是TCO最小的做法。
其具体的实现方式[2][3]索引具体的实现方案还是一个不断演化的过程:
- 倒排索引基本上以FST,多维hash工程化较多
- 全文索引有LogCloud FM-index;Lance,GrepTimedb也有对应的实现
- 向量索引演进太快了,不予评论
当然上面提到的都是分离索引的格式,在老版本的Influxdb中,使用的是统一索引,这样在时间线较少的时候可以极大的降低IO。
预计算
- 物化视图
- 降采样
物化视图的难点在于视图选择是一个NP难问题,存在以下问题:
- 组合爆炸性: 对于具有个字段的表,视图组合有2n2^n2n种选择,随着增加,组合数会呈指数级增长。例如表有27个字段,则搜索空间过亿,大宽表100个字段,则选择范围有21002^{100}2100。
- 与查询相关: 视图选择不仅仅考虑库表Schema信息,还需要分析查询行为,只有命中查询的视图才是有效的,需要从繁芜的查询中识别出可复用的共性部分。
- 多因素权衡: 除了查询分析,还需要权衡存储成本、更新成本和维护成本等多个因素,需解决在特定资源限制下进行最优化选择。
视图选择理论主要有三种类型: AND/OR视图、多重视图处理计划(MVPP)、Lattice Framework。其中Lattice Framework Lattice 在生产中广泛使用[15]。
关于物化视图和降采样的实现,我们之前实现了基于流计算的降采样,有非常多的运营问题;一种方式是给定一个计算集群,对对象存储发起查询以计算降采样和物化视图,iox就是这种方式;最后一种思路就是Clickhouse这种实现一个特化的引擎结构,专门用来做物化视图(MergeTree)。
列更新与删除策略
主要存在一些技术决策:
- 列更新是使用COW还是MOR,可以参考Magnus的MOR实现[18];当然在时序数据库中没有这样的问题,因为是SchemaLess的,都是查询的时候基于选择的文件动态合并出一个Schema的,查询计划产生时才能知道schema。
- 删除是使用文件式删除[17](IceBerg Equality Delete / Position Delete / Deletion Vector)还是将删除写入文件(Soft Delete),后者的问题是需要和查询引擎绑定,且需要携带LSN信息,多用于之前的单机引擎,IceBerg等表格式肯定还是使用第一种,因为不能操作数据本身。
Cache
- 文件缓存
- 元数据缓存
- 索引缓存
- 查询结果缓存
- 语义缓存
- First/Last Value Cache
- Distinct Cache
这里有很多点可以讨论,比如缓存本身的形态,缓存本身适用于哪些业务场景,淘汰算法,自动决策构建等,防止信息泄漏,这一节不详细介绍。
总结
定期总结,思路清晰了不少,哪些方法最有用还是要具体场景具体分析,不同阶段的瓶颈都是不一样的。
参考:
- Optimizing Cloud Data Lakes Queries vldb2025
- LogCloud: Fast Search of Compressed Logs on Object Storage 2025
- Rottnest: Indexing Data Lakes for Search ICDE2025
- Indexing cloud data lakes within the lakes
- Needle in a haystack queries in cloud data lakes
- Wiki Phase diagram
- Petabyte-Scale Row-Level Operations in Data Lakehouses
- GreptimeDB 存储架构深度剖析——JSONBench 榜单第一背后的秘密
- Data skipping for Delta Lake
- Using Parquet’s Bloom Filters
- Full-Text Search (FTS) Index
- Announcing General Availability of Liquid Clustering
- Announcing Automatic Liquid Clustering
- Delta Lake 3.1.0
- https://calcite.apache.org/docs/lattice.html
- Clickhouse MergeTree
- iceberg delete format
- Magnus: A Holistic Approach to Data Management for Large-Scale Machine Learning Workloads
- Optimizing Data Lakes’ Queries 比较详细