mak/Makefile和进度条
1.⾃动化构建-make/Makefile
• 会不会写makefile,从⼀个侧⾯说明了⼀个⼈是否具备完成⼤型⼯程的能⼒
• ⼀个⼯程中的源⽂件不计数,其按类型、功能、模块分别放在若⼲个⽬录中,makefile定义了⼀ 系列的规则来指定,哪些⽂件需要先编译,哪些⽂件需要后编译,哪些⽂件需要重新编译,甚⾄ 于进⾏更复杂的功能操作
• makefile带来的好处就是⸺⸺“⾃动化编译”,⼀旦写好,只需要⼀个make命令,整个⼯程完全⾃动编译,极⼤的提⾼了软件开发的效率。
• make是⼀个命令⼯具,是⼀个解释makefile中指令的命令⼯具,⼀般来说,⼤多数的IDE都有这个命令,⽐如:Delphi的make,Visual C++的nmake,Linux下GNU的make。可⻅,makefile 都成为了⼀种在⼯程⽅⾯的编译⽅法。
• make是⼀条命令,makefile是⼀个⽂件,两个搭配使⽤,完成项⽬⾃动化构建。
1.1Makefile/makefile文件
依赖关系
• myproc和myproc.c之间存在依赖关系。
• myproc是我们要生成的目标文件,myproc.c是生成目标文件所要依赖的依赖文件。
依赖⽅法
• gcc -o myproc myproc.c ,就是生成目标文件对应的依赖方法。
项⽬清理
• ⼯程是需要被清理的
• 像clean这种,没有被第⼀个⽬标⽂件直接或间接关联,那么它后⾯所定义的命令将不会被⾃动执⾏,不过,我们可以显⽰要make执⾏。即命令⸺“make clean”,以此来清除所有的⽬标 ⽂件,以便重编译。
• 但是⼀般我们这种clean的⽬标⽂件,我们将它设置为伪⽬标,⽤ .PHONY 修饰,伪⽬标的特性 是,总是被执⾏的。
• 可以将我们的 hello ⽬标⽂件声明成伪⽬标,测试⼀下。
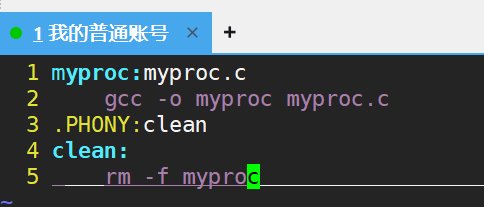
make的执行顺序
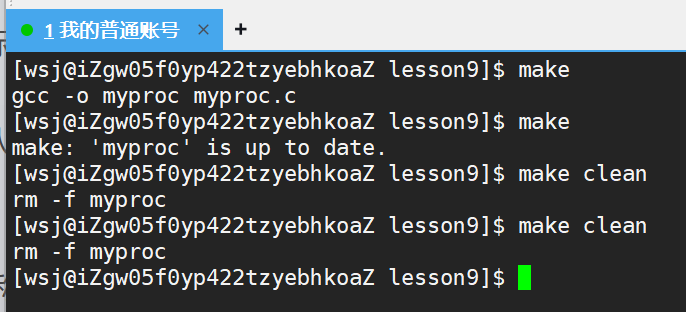
• make命令扫描makefile文件的时候,从上向下进行扫描,默认形成第一个目标文件,即上述的myproc文件
伪目标
• 在makefile中,被.PHONY修饰的目标称为伪目标
• 伪目标的特点:总是被执行。
• 如下:
- 普通目标:若依赖文件未修改,重复执行会提示目标已更新
- 伪目标:每次执行都会触发命令(例如`make clean`)伪对象的作用有两个:
1. 使目标对象无论如何都要重新生成。
2. 并不生成目标文件,而是为了执行一些指令。
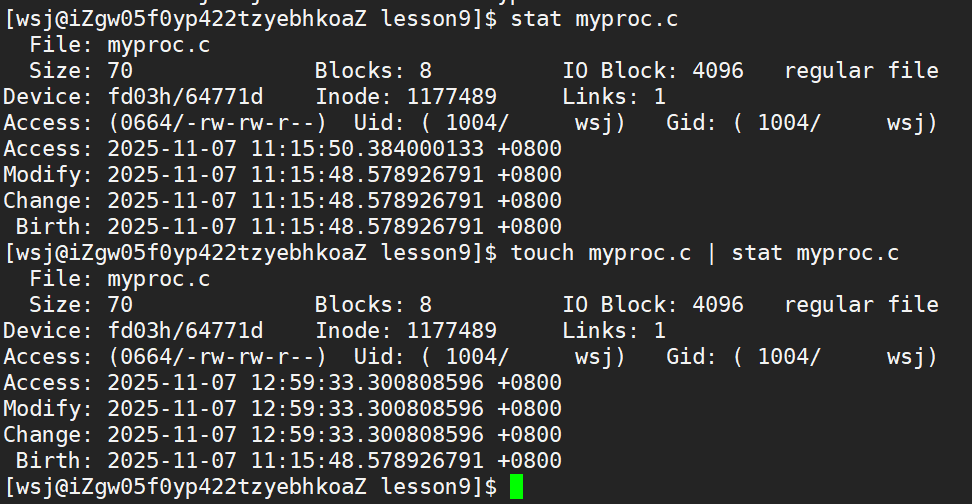
make怎么知道目标文件(bin)和依赖文件(.c)的新旧问题?
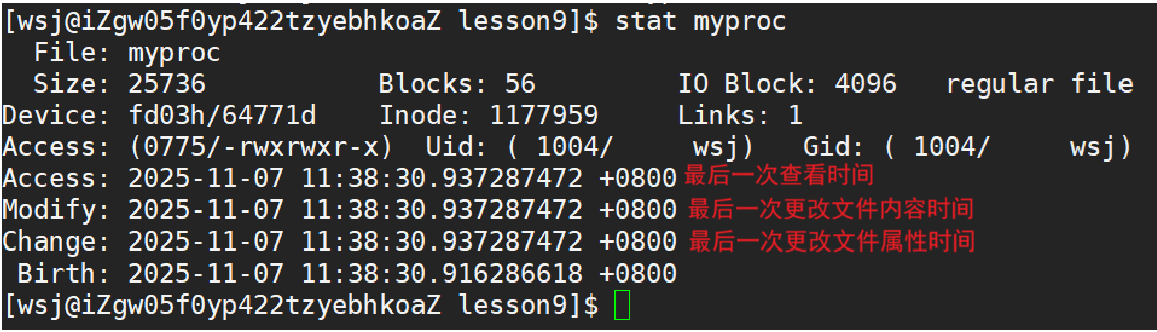
• 文件=内容+属性
• 文件属性里有三个时间:
1.Access:最后一次查看文件的时间
2.Modify:最后一次更改文件内容的时间
3.Change:最后一次更改文件属性的时间
更改文件内容的同时也会更改文件的属性,因为更改内容会导致文件大小size发生变化,而文件大小也是文件属性的一部分
• 而make就是根据目标文件和依赖文件的最后一次更改时间(Modify)来判断新旧的。
• 因为目标文件是根据依赖文件生成的,所以目标文件的Modify一定比依赖文件的Modify晚。如果依赖文件的Modify比目标文件的Modify晚,则说明依赖文件被修改,允许make更新目标文件。
• touch可以更新文件的三个时间
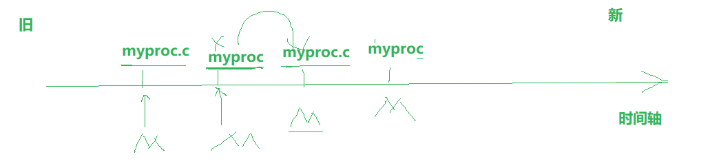
make的推导过程
• make是如何⼯作的,在默认的⽅式下,也就是我们只输⼊make命令。那么:
1. make会在当前⽬录下找名字叫“Makefile”或“makefile”的⽂件。
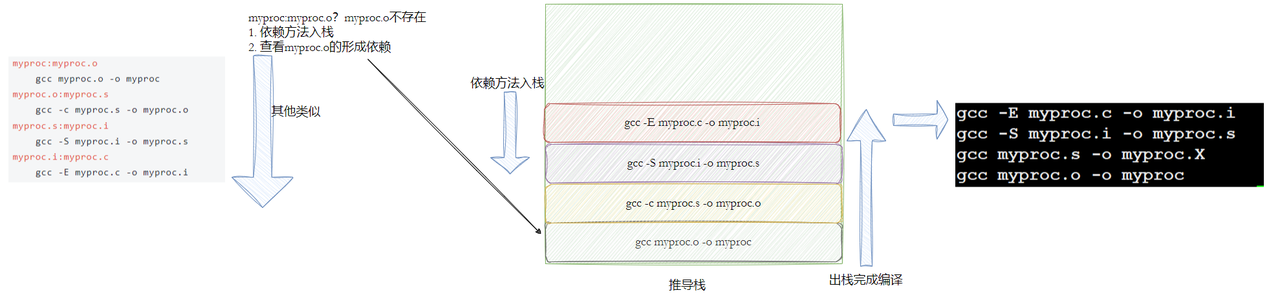
2.执行make时,默认以第一个文件为最终目标,如下面的第一个文件是myproc,那make就会以它为目标文件,然后按依赖链逆向推导构建:
检查myproc依赖myproc.o,myproc.o不存在,需先构建myproc.o;
myproc.o依赖myproc.s,myproc.s不存在,需先构建myproc.s;
myproc.s依赖myproc.i,myproc.i不存在,需先构建myproc.i;
myproc.i依赖myproc.c,myproc.c存在,执行gcc -E生成myproc.i;
回溯用myproc.i生成myproc.s(gcc -S),再生成myproc.o(gcc -c),最后链接生成myproc(gcc)。• 递归构建依赖:若依赖项不存在或比其自身的依赖项旧(即需要更新),make 会先构建该依赖项。这个过程类似 “栈” 的逻辑:先将最终目标的构建需求入栈,再依次将其依赖的构建需求入栈,直到找到最底层的依赖(如 myproc.c,假设已存在且最新)。
• 执行构建命令:从最底层依赖开始(如用 myproc.c 生成 myproc.i),按 “栈” 的顺序依次出栈执行对应命令,逐层回溯构建上层目标,最终完成最终目标(myproc)的生成。
• 这就是整个make的依赖性,make会⼀层⼜⼀层地去找⽂件的依赖关系,直到最终编译出第⼀个 ⽬标⽂件。
• 在找寻的过程中,如果出现错误,⽐如最后被依赖的⽂件找不到,那么make就会直接退出,并 报错,⽽对于所定义的命令的错误,或是编译不成功,make根本不理。
• make只管⽂件的依赖性,即,如果在我找了依赖关系之后,冒号后⾯的⽂件还是不在,那么对 不起,我就不⼯作啦。
myproc:myproc.o gcc myproc.o -o myproc myproc.o:myproc.s gcc -c myproc.s -o myproc.o myproc.s:myproc.i gcc -S myproc.i -o myproc.s myproc.i:myproc.c gcc -E myproc.c -o myproc.i.PHONY:clean clean: rm -f *.i *.s *.o myproc

1.2Makefile扩展语法
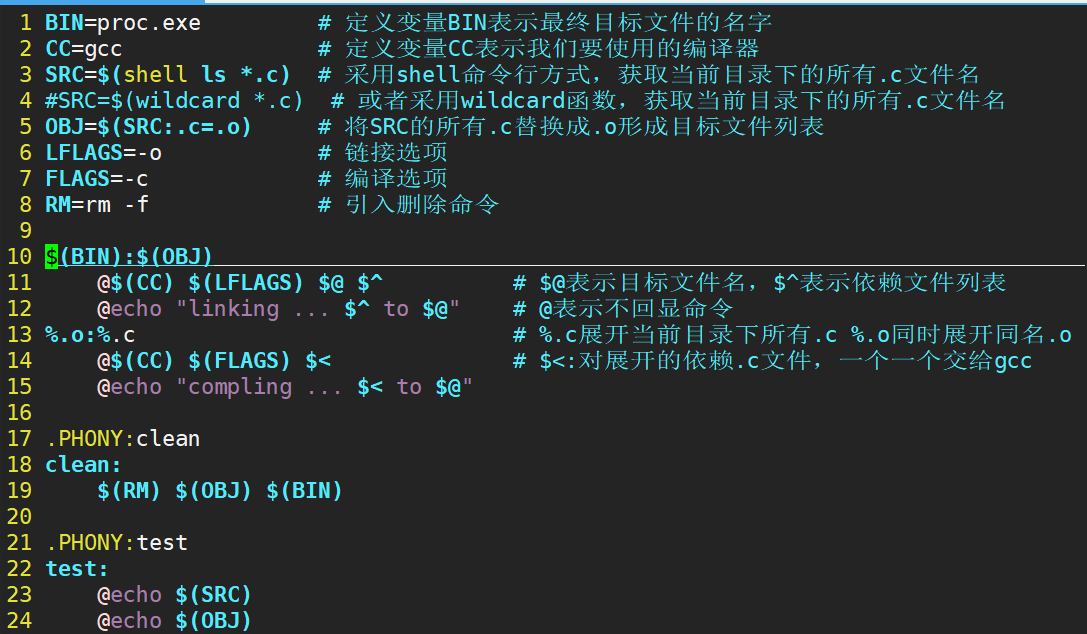
• SRC=$(shell ls *.c) :采用shell命令行方式,获取当前目录下的所有.c文件名
• SRC=$(wildcard *.c) :使用wildcard函数,获取当前目录下的所有.c文件名
• OBJ=$(SRC:.c=.o) :将SRC的所有.c替换成同名.o形成目标文件列表
• @:不回显命令
• $@:目标文件名
• $^:依赖文件名
• $<:对展开的依赖.c文件,一个一个交给gcc
BIN=proc.exe # 定义变量 CC=gcc #SRC=$(shell ls *.c) # 采⽤shell命令⾏⽅式,获取当前所有.c⽂件名 SRC=$(wildcard *.c) # 或者使⽤ wildcard 函数,获取当前所有.c⽂件名 OBJ=$(SRC:.c=.o) # 将SRC的所有.c 替换成为同名.o 形成⽬标⽂件列表 LFLAGS=-o # 链接选项 FLAGS=-c # 编译选项 RM=rm -f # 引⼊命令 $(BIN):$(OBJ) @$(CC) $(LFLAGS) $@ $^ # $@:代表⽬标⽂件名。 $^: 代表依赖⽂件列表 @echo "linking ... $^ to $@" %.o:%.c # %.c 展开当前⽬录下所有的.c。%.o: 同时展开同名.o@$(CC) $(FLAGS) $< # %<: 对展开的依赖.c⽂件,⼀个⼀个的交给gcc。 @echo "compling ... $< to $@" # @:不回显命令 .PHONY:clean clean:$(RM) $(OBJ) $(BIN) # $(RM): 替换,⽤变量内容替换它 .PHONY:test test: @echo $(SRC) @echo $(OBJ)
使用脚本语言批量创建文件
count=1; while [ $count -le 100 ]; do touch code${count}.c; let count++; done
创建100个code文件
make效果
2.Linux第⼀个系统程序−进度条
2.1回车换行
回车换行其实是两个操作。
• 回车:光标回到当前行的起始位置,不改变行号。
• 换行:光标移动到下一行的相同列位置,不改变列号。

2.2缓冲区问题
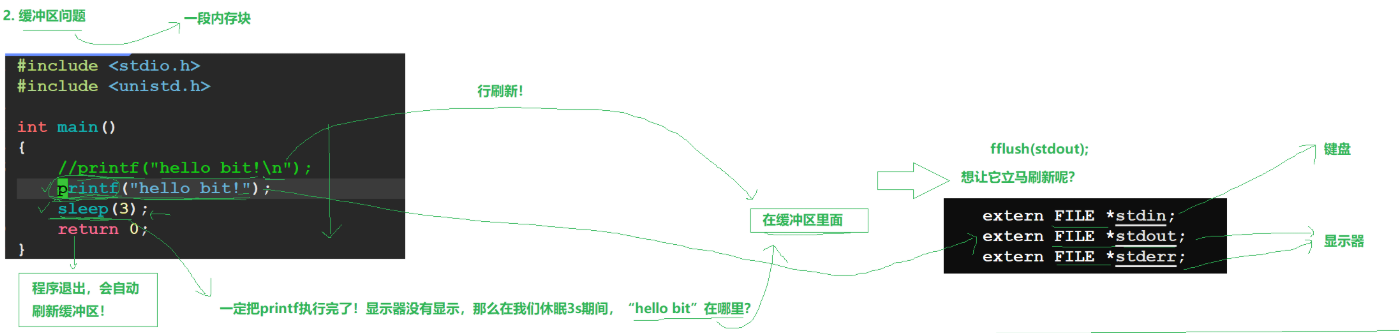
#include<stdio.h> #include<unistd.h>int main() {printf("hello\n");printf("world!");sleep(3);return 0; }执行以上代码的时候,我们会发现一个现象,我们会发现hello立马被输出了,而world却等了3秒才被输出,而我们知道,代码是从上到下依次执行的,不存在先执行sleep再执行输出world的情况。
出现这种情况的原因是printf里的内容会放入缓冲区中,而缓冲区是行刷新的,第一个printf结尾加了换行\n,因此刷新输出了,而第二个printf的内容里没换行\n,因此会一直在缓冲区之中,而随着程序结束,缓冲区再次被刷新,因此world被输出。
缓冲区类型:标准输出(stdout)在终端设备上默认使用行缓冲,即:
- 当遇到
\n时,缓冲区会立即刷新(输出内容到终端)。- 若缓冲区满(通常约 4096 字节),也会强制刷新。
- 程序结束时,无论缓冲区是否为空,都会自动刷新。
代码执行流程:
- 第一个
printf("hello\n")包含\n,触发行缓冲刷新,所以 "hello" 立即显示。- 第二个
printf("world!")无\n,内容暂存缓冲区,未输出。- 执行
sleep(3)时,程序休眠 3 秒,此时缓冲区未刷新,"world!" 仍在内存中。- 程序结束(
return 0)时,缓冲区被强制刷新,"world!" 才显示。
解决方法
因为printf的内容是输出至显示器(stdout)里的,所以我们刷新stdout即可。
fflush(stdout) 手动强制刷新标准输出缓冲区,"world!" 被立即输出到终端
#include<stdio.h> #include<unistd.h>int main() {printf("hello\n");printf("world!");fflush(stdout);sleep(3);return 0; }
2.3倒计时程序
利用 \r 回车使得每次都在改行开头进行输出,-2d则保证能以左对齐的格式输出2个字符宽度的数据,fflush(stdout)保证刷新标准输出缓冲区,使printf里的内容立马输出。
核心机制拆解:
\r的作用:回车符让光标回到当前行的起始位置,后续输出会覆盖该行原有内容,从而实现 “原地更新” 的视觉效果(避免一行行打印导致的刷屏)。
%-2d的妙用:
%2d指定输出宽度为 2 个字符(不足则补空格),确保 “10”“9”“8” 等数字在同一宽度内显示(例如 “9” 会显示为 “9 ”)。-表示左对齐,进一步保证数字在宽度内的位置一致性,避免右对齐时 “10” 到 “9” 的位移感。
fflush(stdout)的必要性:由于输出中没有\n,行缓冲不会自动刷新,必须手动调用fflush,才能让每次的数字更新即时显示在终端上,否则会等到缓冲区满或程序结束才批量输出,失去动态效果。
#include <stdio.h>
#include <unistd.h>int main()
{ int seconds = 10; while(seconds >= 0) { // \r表示回车,即每次都在该行开头输出2个字符宽度printf("%-2d\r", seconds); fflush(stdout); // 刷新标准输出缓冲区seconds--; sleep(1); } printf("\n"); return 0;
}
2.4进度条程序
version1---原理版本
效果:
进度条更新逻辑:
• 循环 101 次(i从 0 到 100),对应进度从 0% 到 100%。
• 每次循环通过printf输出 3 部分内容:
1.[%-100s]:左对齐的 100 字符宽度区域,用buffer中的'#'填充,随i增大逐步变长(buffer[i] = TYPE实现逐渐填充)。
2.[%-3d%%]:左对齐的 3 字符宽度百分比(如 5%、100%),%%表示输出%符号。
3.[%c]:当前旋转动画字符(通过i%len循环取rotate中的字符,实现/→-→|→\→/...的旋转效果)。
• \r:回车符,让光标回到行首,实现 “原地刷新”,避免进度条刷屏。
• fflush(stdout):强制刷新标准输出缓冲区,确保每次更新即时显示。
• usleep(50000):暂停 50 毫秒(50,000 微秒),控制进度条更新速度,让动画肉眼可见。

// 进度条,version1
#include<stdio.h>
#include<unistd.h>
#include<string.h>#define NUM 101
#define TYPE '#'int main()
{char buffer[NUM];// 下面是输出字符串,所以预留一个'\0'作为结尾// 将buffer地址向后的sizeof(buffer)个字节全初始化为0memset(buffer,0,sizeof(buffer));const char* rotate="/-|\\";// 旋转图形,表示有在更新进度int len=strlen(rotate);for(int i=0;i<101;i++){printf("[%-100s][%-3d%%][%c]\r",buffer,i,rotate[i%len]);fflush(stdout);buffer[i]=TYPE;usleep(50000);// 微妙级,10^-6s}printf("\n");return 0;
}
version2---真实版本
一个进度条,结合场景,边下载,边更新进度条。
• progress.c:1.实现FlushProgress函数,核心逻辑是根据当前下载量计算进度并动态刷新显示进度条。
2.相比version1版本,旋转图案位置增加变量静态变量cnt,这样子就算下载速度 speed 为0MB/s,但是因为有调用 FlushProgress 函数,所以图案还在继续更新,可以起到告知用户下载并没有卡死。每次调用FlushProgress时,cnt通过cnt % len循环获取旋转字符索引,再通过cnt++更新,确保动画连续。
• main.c:1.total = 1024.0:总下载量(单位 MB)。
2.speed = 1.0:下载速度(单位 MB/s)3.模拟下载过程(DownLoad函数),调用FlushProgress更新进度,控制下载的总大小、速度等参数。
4.用usleep(3000)模拟下载耗时(3 毫秒),current:记录当前已下载量,current += speed增加已下载量。
// progress.h
#pragma once#include<stdio.h>
#include<string.h>
#include<unistd.h>void FlushProgress(double total,double current);
// progress.c
#include"progress.h"#define NUM 101
#define TYPE '#'void FlushProgress(double total,double current)
{char buffer[NUM];memset(buffer,0,sizeof(buffer));const char* rotate="/-|\\";int len=strlen(rotate);// 根据下载比率,向下取整往buffer里填充#int num=(int)(current*100/total);int i=0;for(;i<num;i++){buffer[i]=TYPE;}static int cnt=0;cnt%=len;double ratio=current*100/total;// 下载百分率printf("[%-100s][%.2lf%%][%c]\r",buffer,ratio,rotate[cnt]);fflush(stdout);cnt++;// 当下载速度为0,但有执行该函数,旋转图标就会继续更新
}
// main.c
#include"progress.h"double total=1024.0; // 总下载量,mb
double speed=1.0; // 网速,mb/svoid DownLoad()
{double current=0.0;while(current<=total){FlushProgress(total,current);usleep(3000);// 充当下载数据的时间current+=speed;}printf("\ndownload %.2lfMB Done\n",total);// 打印下载资源情况}int main()
{DownLoad();return 0;
}
# Makefile文件
BIN=progress.exe
SRC=$(wildcard *.c)
OBJ=$(SRC:.c=.o)$(BIN):$(OBJ)@gcc -o $@ $^@echo "linking ... $(OBJ) to $(BIN)"
%.o:%.c@gcc -c $<@echo "compling ... $< to $@".PHONY:clean
clean:@rm -f $(OBJ) $(BIN).PHONY:test
test:@echo $(SRC)@echo $(OBJ)