第十章、GPT1:Improving Language Understanding by Generative Pre-Training(代码部分)
0 前言
对于代码部分首先先把代码运行起来,其次逐块来看每部分代码在做什么。
论文:https://cdn.openai.com/research-covers/language-unsupervised/language_understanding_paper.pdf
代码:https://github.com/openai/finetune-transformer-lm
1 代码运行
1.1 环境搭建
由于我现在用的显卡是50系的所以遇到了很多奇奇怪怪的难题,解决方法放在下面作为自己的记录,同时如果能给遇到同样问题的小伙伴带来一些帮助也非常荣幸。
改过的代码已经上传至github,感兴趣的小伙伴可以试试,按照上面的教程安装就可以~
https://github.com/Gaoxinyigithub/gpt1
问题包括(显卡没这么新的直接正常装就可以,忽略下面的内容)
-
直接下载最新版本的tensorflow不可以正常使用
pip install tf_nightly-2.20.0.dev0+selfbuilt-cp310-cp310-linux_x86_64.whl -i https://mirrors.aliyun.com/pypi/simple/ -
通过手动编译的形式下载,但是c++编译的部分会出问题
错误:
ImportError: /home/(你的地址)/anaconda3/envs/dmcgb/bin/../lib/libstdc++.so.6: version `GLIBCXX_3.4.30' not found (required by /lib/x86_64-linux-gnu/libLLVM-13.so.1)可以通过软链接的方式解决:
ln -sf /usr/lib/x86_64-linux-gnu/libstdc++.so.6 /home/(替换成你的地址)/anaconda3/envs/dmcgb/bin/../lib/libstdc++.so.6 -
确保显存大小够用
搭建环境完成后,在终端激活你的环境,并运行下述代码
python train.py --dataset rocstories --desc rocstories --submit --analysis
运行成功,终端显示如下:
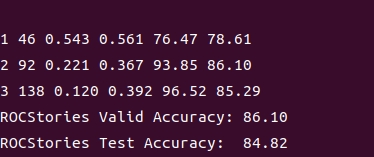
运行需要一段时间,运行结束后你会在finetune-transformer-lm文件夹下发现多了一个名为save的文件夹,最优模型参数会保存在save/rocstories/best_params.jl中;同时在log文件夹下也会生成一个log文件,其中会保存日志(如训练/验证损失和准确率等)。
【此处只对初步的体验运行结果做简单介绍,后面在代码详解部分还会有更细节的解释和叙述。】
1.2 数据集
训练数据集:代码中用到的是 ROCStories 语料库 https://cs.rochester.edu/nlp/rocstories/ ,接下来我们将对这个数据集做简单的介绍。
首先来介绍两个用来测试任务(用来评价模型):
- Narrative Cloze Test(叙事完形填空测试):给定一个事件序列,随机去掉一个事件,让模型预测缺失的事件。它主要考察模型对事件之间关系的理解。
- Story Cloze Test(故事完形填空测试):给定一个故事的开头(4句话)和两个可能的结尾,让模型判断哪个结尾更合理。它更贴近实际的故事理解和生成能力。
文章用的便是 Story Cloze Test(故事完形填空测试)这样一种测试方法,那么ROCStories 语料库,又是干吗的呢?实际上就是为了进行 Story Cloze Test(故事完形填空测试)而准备的一个数据库,那么自然而然的,这个数据库实际上是由5句话组成的大量常识故事组成。
这个语料库有两个独特之处:
- 它包含了大量日常事件之间的因果和时间常识关系(即事件之间的因果顺序和时间先后,反映了人们对日常生活逻辑的理解)。
- 它是一个高质量的日常生活故事集合,不仅可以用于理解故事,也适合用来生成新的故事。
该数据集既能帮助模型学习事件之间的常识关系,也能作为故事生成的优质素材。
1.3 model文件夹
encoder_bpe_40000.json:BPE分词器的编码器配置文件,用于将文本分词为模型可处理的token。vocab_40000.bpe:BPE分词的词表文件,定义了所有可用的token。params_shapes.json:模型参数的形状信息(每一层参数的维度),用于正确加载和重建参数。params_0.npy~params_9.npy:模型的预训练参数,分成多个npy文件存储(通常是权重和偏置)。- 这些文件共同用于模型初始化、分词和参数加载,是模型训练和推理的基础资源。
2 代码详解
2.1 结构梳理
首先在详细看代码之前,我们先来了解一下工程文件下的各个py文件,在整个工程中扮演着怎样的角色:
- analysis.py:用于评估和分析模型结果,比如计算验证集和测试集的准确率,输出日志。
- datasets.py:负责加载和处理数据集(如 ROCStories),包括读取 csv 文件、分割训练/验证/测试集等。
- opt.py:实现优化器(如 Adam)和学习率调度(如 warmup_linear、warmup_cosine)等训练相关算法。
- test.py:用于测试硬件环境(如 GPU 是否可用),通常不参与主流程。
text_utils.py:文本处理工具,主要实现分词、BPE 编码、文本标准化等功能。 - train.py:主训练脚本,负责模型构建、训练、验证、保存、预测等完整流程。
- utils.py:提供各种辅助函数,如数据编码、批处理、日志记录、参数初始化、梯度处理等。
代码中用的实际上是transflow1,随着该库的不断更新,实际上很多方法已经被改掉或弃用,但是没有关系,整体的框架和结构是不变的,只不过我们在后面的学习中会忽略一些更具体的代码的解释。
2.2 train.py
这实际上是最重要的一个问题,我们从训练开始来看gpt1到底是怎么实现的,我们以if __name__ == '__main__':为分界线将代码分为上下两个部分。
上半部分
1、激活函数
从头看是看,首先是两个函数的定义,gelu()及swish()熟悉神经网络的小伙伴应该一眼就明白这就是两个激活函数,用以增加整个模型的非线性表达能力的。
def gelu(x):return 0.5*x*(1+tf.tanh(math.sqrt(2/math.pi)*(x+0.044715*tf.pow(x, 3))))def swish(x):return x*tf.nn.sigmoid(x)
2、模型各个功能块
忽略掉3个字典继续往下看。
归一化:简单来说其实就是: x − μ σ \frac{x-\mu}{\sigma} σx−μ,只不过加了参数学习。
# 可学习的归一化
def _norm(x, g=None, b=None, e=1e-5, axis=[1]):u = tf.reduce_mean(x, axis=axis, keep_dims=True) # 计算均值s = tf.reduce_mean(tf.square(x-u), axis=axis, keep_dims=True) # 计算方差x = (x - u) * tf.rsqrt(s + e) # 标准化:减均值除以标准差if g is not None and b is not None:x = x*g + b # 仿射变换(可学习的缩放和平移)return x# 后面模型中实际用到的部分
# 在给定的 scope 下,创建可学习参数 g(初始为1)和 b(初始为0),长度等于最后一维(特征维度)。
def norm(x, scope, axis=[-1]):with tf.variable_scope(scope):n_state = shape_list(x)[-1]g = tf.get_variable("g", [n_state], initializer=tf.constant_initializer(1)) b = tf.get_variable("b", [n_state], initializer=tf.constant_initializer(0))return _norm(x, g, b, axis=axis)
dropout正则化:防止过拟合,训练时随机丢弃部分(按比例)神经元。
def dropout(x, pdrop, train):if train and pdrop > 0:x = tf.nn.dropout(x, 1-pdrop)return x
带掩码的attention权重:如果不熟悉这部分理论的化可以参考https://blog.csdn.net/m0_47719040/article/details/150608889 中的mask掩码部分有详细的叙述,其作用实际上就是保证当前单词只能结合它前面单词的上下文信息,实际上也是符合常识的,我们在看文章的时候也是从前往后读,在没读到后面的内容之前,我们也不知道有什么。
def mask_attn_weights(w):n = shape_list(w)[-1] # 获取最后一个维度的大小,n为序列长度b = tf.matrix_band_part(tf.ones([n, n]), -1, 0) # 生成下三角矩阵(主对角线及其下方为1,其余为0)b = tf.reshape(b, [1, 1, n, n]) # 调整形状以便与w矩阵相乘w = w*b + -1e9*(1-b) # 用极小值(-1e9)填充上三角部分,实现掩码return w
多头注意力机制:如果不熟悉这部分理论的化可以参考https://blog.csdn.net/m0_47719040/article/details/150608889 多头部分的实现,这个项目中的多头注意力机制也是一个非常标准的多头注意力。
# 计算单头得分
def _attn(q, k, v, train=False, scale=False):# q(query),k(key),v(value),都是多头分组后的张量。w = tf.matmul(q, k) # 点积if scale: # 如果需要缩放(通常用于防止梯度消失),将分数除以 sqrt(d_k)n_state = shape_list(v)[-1]w = w*tf.rsqrt(tf.cast(n_state, tf.float32))w = mask_attn_weights(w)w = tf.nn.softmax(w)w = dropout(w, attn_pdrop, train)a = tf.matmul(w, v)return a# 将权重参数分成n分用于n个头,以及算完后合并到一起
def split_states(x, n):x_shape = shape_list(x)m = x_shape[-1]new_x_shape = x_shape[:-1]+[n, m//n]return tf.reshape(x, new_x_shape)def merge_states(x):x_shape = shape_list(x)new_x_shape = x_shape[:-2]+[np.prod(x_shape[-2:])]return tf.reshape(x, new_x_shape)def split_heads(x, n, k=False):if k:return tf.transpose(split_states(x, n), [0, 2, 3, 1])else:return tf.transpose(split_states(x, n), [0, 2, 1, 3])def merge_heads(x):return merge_states(tf.transpose(x, [0, 2, 1, 3]))# 全连接:1D 卷积
def conv1d(x, scope, nf, rf, w_init=tf.random_normal_initializer(stddev=0.02), b_init=tf.constant_initializer(0), pad='VALID', train=False):with tf.variable_scope(scope):nx = shape_list(x)[-1] # 输入最后一维的大小(特征数)w = tf.get_variable("w", [rf, nx, nf], initializer=w_init) # 卷积/线性变换的权重b = tf.get_variable("b", [nf], initializer=b_init) # 偏置if rf == 1: # 1x1卷积(等价于全连接,速度快)c = tf.reshape(tf.matmul(tf.reshape(x, [-1, nx]), tf.reshape(w, [-1, nf]))+b, shape_list(x)[:-1]+[nf])else: # rf>1时,使用标准1D卷积c = tf.nn.conv1d(x, w, stride=1, padding=pad)+breturn c# 注意力机制
def attn(x, scope, n_state, n_head, train=False, scale=False):assert n_state%n_head==0 # 保证每个头的维度可以整除with tf.variable_scope(scope):c = conv1d(x, 'c_attn', n_state*3, 1, train=train) # 线性变换,生成Q、K、V的拼接q, k, v = tf.split(c, 3, 2) # 按最后一维分成3份,分别是query、key、valueq = split_heads(q, n_head) # 拆分成多头k = split_heads(k, n_head, k=True)v = split_heads(v, n_head)a = _attn(q, k, v, train=train, scale=scale) # 计算多头注意力a = merge_heads(a) # 合并多头a = conv1d(a, 'c_proj', n_state, 1, train=train) # 输出投影a = dropout(a, resid_pdrop, train) # 残差dropoutreturn a
前馈层:前馈层主要是进行非线性变换和空间映射,从而增加模型的表达能力和复杂性。
最原始的公式实际上是 F F N ( x ) = m a x ( 0 , x W 1 + b 1 ) W 2 + b 2 FFN(x)=max(0,xW_1+b_1)W_2+b_2 FFN(x)=max(0,xW1+b1)W2+b2
def mlp(x, scope, n_state, train=False):with tf.variable_scope(scope):nx = shape_list(x)[-1] # 输入的最后一维(特征数)act = act_fns[afn] # 选择激活函数(如gelu、relu、swish)h = act(conv1d(x, 'c_fc', n_state, 1, train=train)) # 线性变换+激活,升维h2 = conv1d(h, 'c_proj', nx, 1, train=train) # 线性变换,降回原维度h2 = dropout(h2, resid_pdrop, train) # dropout正则化return h2
transformer的一个完整的块:多头注意力+残差连接&归一化+前馈层+残差连接&归一化
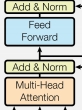
def block(x, scope, train=False, scale=False):with tf.variable_scope(scope):nx = shape_list(x)[-1]# 多头注意力a = attn(x, 'attn', nx, n_head, train=train, scale=scale)# 残差连接+归一化n = norm(x+a, 'ln_1')# 前馈层m = mlp(n, 'mlp', nx*4, train=train)# 残差连接+归一化h = norm(n+m, 'ln_2')return h
embed编码:
def embed(X, we):# 确保 we 可以参与梯度计算(有些情况下 embedding 可能是常量,需要转为 Tensor)。we = convert_gradient_to_tensor(we)# 对 we 进行索引,获取每个 token 的嵌入向量。e = tf.gather(we, X)# 对最后一维(size=2)做求和,将词 embedding 和位置 embedding 相加,得到最终的 token 表示。h = tf.reduce_sum(e, 2)return h
分类器函数:
def clf(x, ny, w_init=tf.random_normal_initializer(stddev=0.02), b_init=tf.constant_initializer(0), train=False):# 分类器函数,将输入特征映射为分类 logitswith tf.variable_scope('clf'):# 获取输入特征的维度(最后一维)nx = shape_list(x)[-1]# 创建权重变量,形状为 [特征维度, 类别数],正态分布初始化w = tf.get_variable("w", [nx, ny], initializer=w_init)# 创建偏置变量,形状为 [类别数],常数0初始化b = tf.get_variable("b", [ny], initializer=b_init)# 线性变换,输出 logits,形状为 [batch, 类别数]return tf.matmul(x, w)+b
整体模型:既能做语言建模(预测下一个 token),又能做分类(如 ROCStories 结局选择),loss部分也是加权的。
def model(X, M, Y, train=False, reuse=False):with tf.variable_scope('model', reuse=reuse):# 1. 创建词嵌入矩阵(包含词、特殊符号、位置),形状 [总词数, 嵌入维度]we = tf.get_variable("we", [n_vocab+n_special+n_ctx, n_embd], initializer=tf.random_normal_initializer(stddev=0.02))# 2. 对 embedding 参数做 dropout(训练时防止过拟合)we = dropout(we, embd_pdrop, train)# 3. 调整输入 X、M 的形状,合并 batch 维度,方便后续处理X = tf.reshape(X, [-1, n_ctx, 2])M = tf.reshape(M, [-1, n_ctx])# 4. 词嵌入 + 位置嵌入相加,得到每个 token 的输入表示h = embed(X, we)# 5. 堆叠 n_layer 个 Transformer block,逐层处理for layer in range(n_layer):h = block(h, 'h%d'%layer, train=train, scale=True)# 6. 语言模型(LM)分支:预测下一个 token# - 取除最后一个 token 外的所有输出lm_h = tf.reshape(h[:, :-1], [-1, n_embd])# - 用 embedding 矩阵做输出投影,得到 logitslm_logits = tf.matmul(lm_h, we, transpose_b=True)# - 计算每个位置的交叉熵损失(忽略第一个 token)lm_losses = tf.nn.sparse_softmax_cross_entropy_with_logits(logits=lm_logits, labels=tf.reshape(X[:, 1:, 0], [-1]))# - 恢复 batch 结构lm_losses = tf.reshape(lm_losses, [shape_list(X)[0], shape_list(X)[1]-1])# - 用 mask M 只统计有效 token 的损失,做归一化lm_losses = tf.reduce_sum(lm_losses*M[:, 1:], 1)/tf.reduce_sum(M[:, 1:], 1)# 7. 分类分支(cloze/ROCStories 任务)# - 展平成 [batch*2, n_embd],每个样本有两个选项clf_h = tf.reshape(h, [-1, n_embd])# - 找到每个样本中 [CLS] token 的位置(用 clf_token 标记)pool_idx = tf.cast(tf.argmax(tf.cast(tf.equal(X[:, :, 0], clf_token), tf.float32), 1), tf.int32)# - 取出每个样本的 [CLS] 表示,作为分类输入clf_h = tf.gather(clf_h, tf.range(shape_list(X)[0], dtype=tf.int32)*n_ctx+pool_idx)# - 恢复为 [batch, 2, n_embd],每个样本两个选项clf_h = tf.reshape(clf_h, [-1, 2, n_embd])# - 训练时可对分类输入做 dropoutif train and clf_pdrop > 0:shape = shape_list(clf_h)shape[1] = 1clf_h = tf.nn.dropout(clf_h, 1-clf_pdrop, shape)# - 再展平成 [batch*2, n_embd]clf_h = tf.reshape(clf_h, [-1, n_embd])# - 通过线性分类头,输出 logitsclf_logits = clf(clf_h, 1, train=train)# - 恢复为 [batch, 2],每个样本两个选项的分数clf_logits = tf.reshape(clf_logits, [-1, 2])# - 计算分类损失(交叉熵)clf_losses = tf.nn.sparse_softmax_cross_entropy_with_logits(logits=clf_logits, labels=Y)# 8. 返回分类 logits、分类损失、语言模型损失return clf_logits, clf_losses, lm_losses
之后的函数根模型本身相关性不大,我们只做解释不做详细叙述:
- mgpu_train, mgpu_predict:多 GPU 训练/预测的封装,支持数据并行。
- transform_roc:将 ROCStories 数据集转为模型输入格式。
- iter_apply, iter_predict:批量推理/预测,支持大数据集分批处理。
- save:保存当前模型参数到文件。
- log:在训练过程中记录和输出日志、保存最优模型。
- predict:对测试集进行预测并保存结果。
下半部分
首先就是一大堆的命令行参数设置
- –desc:实验描述字符串,用于命名日志和模型保存文件夹。
- –dataset:指定要使用的数据集名称(如 rocstories)。
- –log_dir:日志文件保存目录,记录训练过程(如损失、准确率),默认 log。
- –save_dir:模型参数保存目录,训练好的模型会保存在这里,默认 save/。
- –data_dir:数据集文件夹路径,默认 data。
- –submission_dir:预测结果(如测试集提交文件)保存目录,默认 submission/。
- –submit:布尔参数,若加上则在训练后生成预测结果文件。
- –analysis:布尔参数,若加上则在提交后进行结果分析。
- –seed:随机种子,保证实验可复现,默认 42。
- –n_iter:训练轮数(epoch),即遍历训练集的次数,默认 3。
- –n_batch:每个 GPU 的 batch size,默认 8。
- –max_grad_norm:梯度裁剪的最大范数,防止梯度爆炸,默认 1。
- –lr:初始学习率,默认 6.25e-5。
- –lr_warmup:学习率预热比例,默认 0.002。
- –n_ctx:最大上下文长度(序列长度),默认 512。
- –n_embd:embedding 维度,默认 768。
- –n_head:多头注意力的头数,默认 12。
- –n_layer:Transformer 层数,默认 12。
- –embd_pdrop:embedding 层 dropout 概率,默认 0.1。
- –attn_pdrop:注意力层 dropout 概率,默认 0.1。
- –resid_pdrop:残差连接 dropout 概率,默认 0.1。
- –clf_pdrop:分类器 dropout 概率,默认 0.1。
- –l2:L2 正则化系数,默认 0.01。
- –vector_l2:布尔参数,是否对向量级别做 L2 正则。
- –n_gpu:使用的 GPU 数量,默认 4。
- –opt:优化器类型,默认 ‘adam’。
- –afn:激活函数类型,默认 ‘gelu’。
- –lr_schedule:学习率调度策略,默认 ‘warmup_linear’。
- –encoder_path:分词器编码器文件路径,默认 encoder_bpe_40000.json。
- –bpe_path:BPE(字节对编码)词表路径,默认 vocab_40000.bpe。
- –n_transfer:迁移学习时加载的参数层数,默认 12。
- –lm_coef:语言模型损失的权重,默认 0.5。
- –b1:Adam 优化器的 beta1 参数,默认 0.9。
- –b2:Adam 优化器的 beta2 参数,默认 0.999。
- –e:Adam 优化器的 epsilon,默认 1e-8。
而后续的内容实际上同所有的模型训练都是一样的:数据预处理->损失函数设置->实例化模型(初始化参数)->有预训练参数加载预训练参数->进行训练
args = parser.parse_args()
print(args)
globals().update(args.__dict__)# 随机种子设置
random.seed(seed) # 设置 Python 随机种子,保证实验可复现
np.random.seed(seed) # 设置 numpy 随机种子
tf.set_random_seed(seed) # 设置 TensorFlow 随机种子# 日志和编码器初始化
logger = ResultLogger(path=os.path.join(log_dir, '{}.jsonl'.format(desc)), **args.__dict__) # 初始化日志记录器
text_encoder = TextEncoder(encoder_path, bpe_path) # 加载 BPE 编码器
encoder = text_encoder.encoder # 获取词表
n_vocab = len(text_encoder.encoder) # 词表大小# 数据集编码与处理
# 加载并编码训练、验证、测试数据集
(trX1, trX2, trX3, trY), (vaX1, vaX2, vaX3, vaY), (teX1, teX2, teX3) = encode_dataset(rocstories(data_dir), encoder=text_encoder)
# 设置分类类别数和特殊token。
n_y = 2 # 二分类
encoder['_start_'] = len(encoder) # 添加特殊 token
encoder['_delimiter_'] = len(encoder)
encoder['_classify_'] = len(encoder)
clf_token = encoder['_classify_'] # 分类 token
n_special = 3 # 特殊 token 数量
# 计算最大上下文长度,保证输入不会超出模型限制。
max_len = n_ctx//2-2
n_ctx = min(max([len(x1[:max_len])+max(len(x2[:max_len]), len(x3[:max_len])) for x1, x2, x3 in zip(trX1, trX2, trX3)]+ [len(x1[:max_len])+max(len(x2[:max_len]), len(x3[:max_len])) for x1, x2, x3 in zip(vaX1, vaX2, vaX3)]+ [len(x1[:max_len])+max(len(x2[:max_len]), len(x3[:max_len])) for x1, x2, x3 in zip(teX1, teX2, teX3)])+3, n_ctx)
# 转换数据格式,生成输入和mask。
trX, trM = transform_roc(trX1, trX2, trX3) # 训练集
vaX, vaM = transform_roc(vaX1, vaX2, vaX3) # 验证集
if submit:teX, teM = transform_roc(teX1, teX2, teX3) # 测试集(如需提交)# 批量与训练参数设置
n_train = len(trY) # 训练样本数
n_valid = len(vaY) # 验证样本数
n_batch_train = n_batch*n_gpu # 单次训练的总 batch size
n_updates_total = (n_train//n_batch_train)*n_iter # 总迭代步数# 定义输入占位符
X_train = tf.placeholder(tf.int32, [n_batch_train, 2, n_ctx, 2])
M_train = tf.placeholder(tf.float32, [n_batch_train, 2, n_ctx])
X = tf.placeholder(tf.int32, [None, 2, n_ctx, 2])
M = tf.placeholder(tf.float32, [None, 2, n_ctx])
Y_train = tf.placeholder(tf.int32, [n_batch_train])
Y = tf.placeholder(tf.int32, [None])# 构建多卡训练图
train, logits, clf_losses, lm_losses = mgpu_train(X_train, M_train, Y_train)
clf_loss = tf.reduce_mean(clf_losses) # 分类损失均值params = find_trainable_variables('model') # 获取模型参数
sess = tf.Session(config=tf.ConfigProto(allow_soft_placement=True)) # 创建会话
sess.run(tf.global_variables_initializer()) # 初始化参数# 加载预训练参数
shapes = json.load(open('model/params_shapes.json'))
offsets = np.cumsum([np.prod(shape) for shape in shapes])
init_params = [np.load('model/params_{}.npy'.format(n)) for n in range(10)]
init_params = np.split(np.concatenate(init_params, 0), offsets)[:-1]
init_params = [param.reshape(shape) for param, shape in zip(init_params, shapes)]
init_params[0] = init_params[0][:n_ctx]
init_params[0] = np.concatenate([init_params[1], (np.random.randn(n_special, n_embd)*0.02).astype(np.float32), init_params[0]], 0)
del init_params[1]# 控制参数迁移(可选微调层数)
if n_transfer == -1:n_transfer = 0
else:n_transfer = 1+n_transfer*12
sess.run([p.assign(ip) for p, ip in zip(params[:n_transfer], init_params[:n_transfer])])# 构建多卡和单卡的评估图
eval_mgpu_logits, eval_mgpu_clf_losses, eval_mgpu_lm_losses = mgpu_predict(X_train, M_train, Y_train)
eval_logits, eval_clf_losses, eval_lm_losses = model(X, M, Y, train=False, reuse=True)
eval_clf_loss = tf.reduce_mean(eval_clf_losses)
eval_mgpu_clf_loss = tf.reduce_mean(eval_mgpu_clf_losses)n_updates = 0
n_epochs = 0
if dataset != 'stsb':trYt = trY
if submit:save(os.path.join(save_dir, desc, 'best_params.jl')) # 保存初始参数
best_score = 0
# 主训练循环
for i in range(n_iter):for xmb, mmb, ymb in iter_data(*shuffle(trX, trM, trYt, random_state=None), n_batch=n_batch_train, truncate=True, verbose=True):cost, _ = sess.run([clf_loss, train], {X_train:xmb, M_train:mmb, Y_train:ymb}) # 训练一步n_updates += 1if n_updates in [1000, 2000, 4000, 8000, 16000, 32000] and n_epochs == 0:log() # 记录日志n_epochs += 1log() # 每轮结束记录日志
if submit:# 如果需要提交,加载最佳参数并预测sess.run([p.assign(ip) for p, ip in zip(params, joblib.load(os.path.join(save_dir, desc, 'best_params.jl')))])predict()if analysis:rocstories_analysis(data_dir, os.path.join(submission_dir, 'ROCStories.tsv'), os.path.join(log_dir, 'rocstories.jsonl'))