基于协同过滤算法的小说推荐系统_django+spider
- 开发语言:Python
- 框架:django
- Python版本:python3.8
- 数据库:mysql 5.7
- 数据库工具:Navicat12
- 开发软件:PyCharm
系统展示
系统首页
用户注册
小说信息
个人中心
管理员登录
管理员功能界面
用户管理
小说信息管理
系统管理
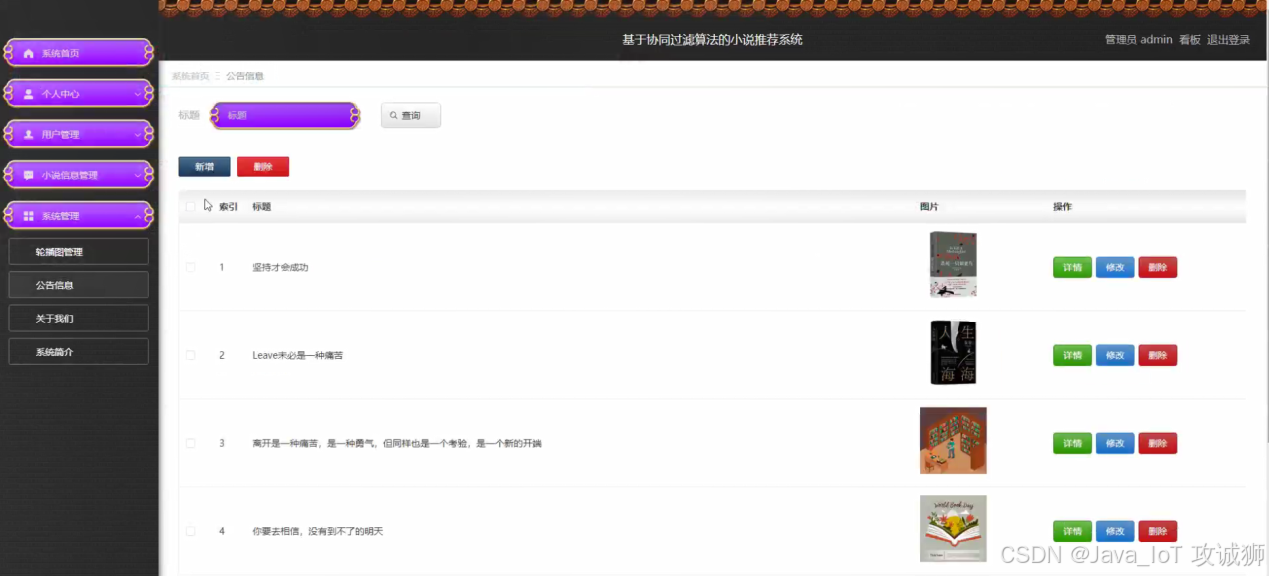
看板界面
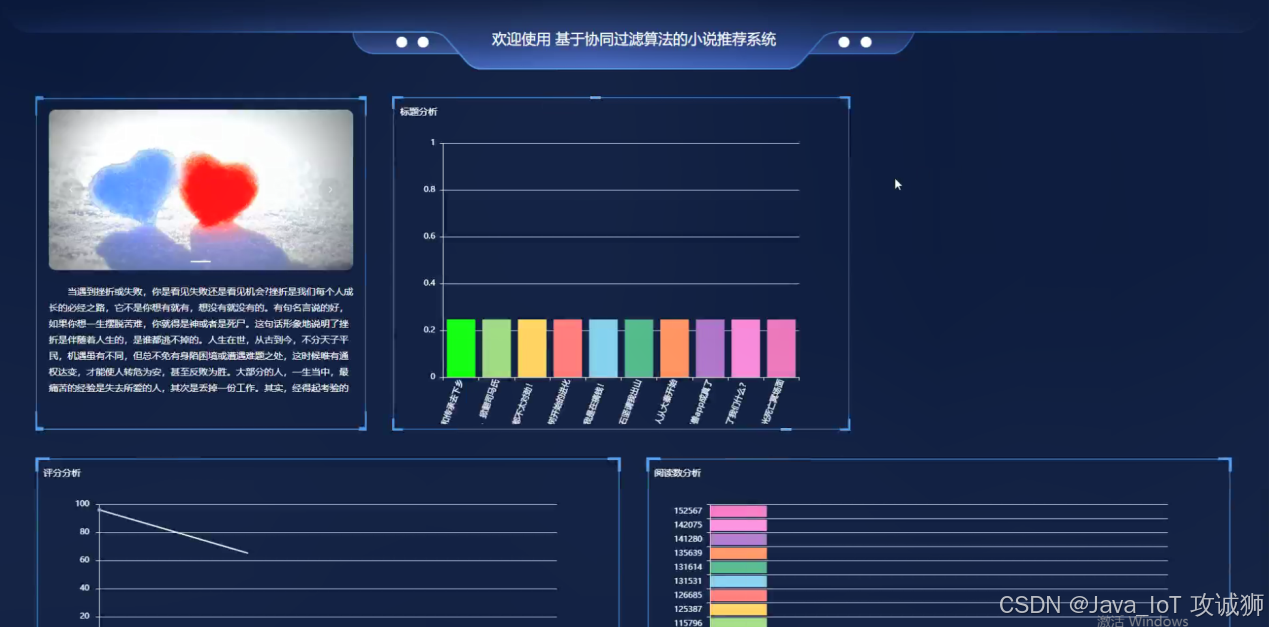
摘要
运用协同过滤算法,构建了以 Django为基础的小说推荐管理体系。首先,以需求为依据,对目前传统的管理进行了较为详尽的了解和分析。根据需求分析结果进行了系统的设计,网站主要功能包括对个人中心、用户管理、小说信息管理、系统管理等进行管理。使用目前市场主流的技术 Django框架构建,使用Python开发语言和MySQL数据库对系统进行高内聚低耦合的设计,最终完成了小说推荐系统的实现。本系统为当前管理提供了一个高效、便捷、信息化的解决方案、有效管控了获取小说推荐数据的各个环节,这为后期系统的优化提供了新的方向。
研究背景
传统的小说推荐管理必须进行信息化改造,这是一个不可避免的过程。这样既可以使企业内部资源得到合理的配置,又可以通过信息化管理平台,对小说推荐所涉及的所有业务进行全面的跟踪和后续的过程控制。通过这个平台,系统用户可以共享每个环节和相关资源。因此,研究和开发一个基于Django架构的信息化、一体化的小说推荐系统具有重要的意义。
关键技术
Python是解释型的脚本语言,在运行过程中,把程序转换为字节码和机器语言,说明性语言的程序在运行之前不必进行编译,而是一个专用的解释器,当被执行时,它都会被翻译,与之对应的还有编译性语言。
同时,这也是一种用于电脑编程的跨平台语言,这是一门将编译、交互和面向对象相结合的脚本语言(script language)。
Django用Python编写,属于开源Web应用程序框架。采用(模型M、视图V和模板t)的框架模式。该框架以比利时吉普赛爵士吉他手詹戈·莱因哈特命名。该架构的主要组件如下:
1.用于创建模型的对象关系映射。
2.最终目标是为用户设计一个完美的管理界面。
3.是目前最流行的URL设计解决方案。
4.模板语言对设计师来说是最友好的。
5.缓存系统。
Vue是一款流行的开源JavaScript框架,用于构建用户界面和单页面应用程序。Vue的核心库只关注视图层,易于上手并且可以与其他库或现有项目轻松整合。
MYSQL数据库运行速度快,安全性能也很高,而且对使用的平台没有任何的限制,所以被广泛应运到系统的开发中。MySQL是一个开源和多线程的关系管理数据库系统,MySQL是开放源代码的数据库,具有跨平台性。
B/S(浏览器/服务器)结构是目前主流的网络化的结构模式,它能够把系统核心功能集中在服务器上面,可以帮助系统开发人员简化操作,便于维护和使用。
系统分析
对系统的可行性分析以及对所有功能需求进行详细的分析,来查看该系统是否具有开发的可能。
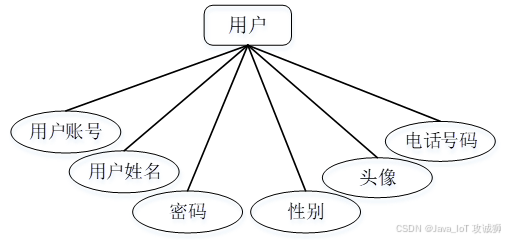
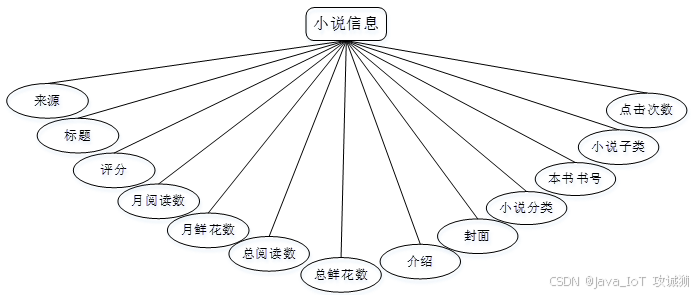
系统设计
功能模块设计和数据库设计这两部分内容都有专门的表格和图片表示。
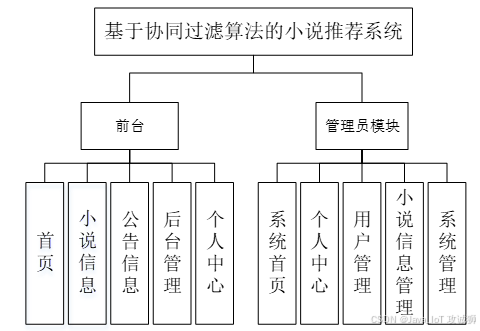
系统实现
当人们打开系统的网址后,首先看到的就是首页界面。在这里,人们能够看到系统的导航条,通过导航条导航进入各功能展示页面进行操作。在个人中心页面根据需要输入个人详细信息可以进行更新信息操作。管理员进入主页面,主要功能包括对系统首页、个人中心、用户管理、小说信息管理、系统管理等进行操作。
代码实现
# coding:utf-8import logging, os, timefrom django.http import JsonResponse
from django.apps import apps
from wsgiref.util import FileWrapper
from django.http import HttpResponse,HttpResponseRedirect
from django.shortcuts import redirect
from .config_model import config
from util.codes import *
from util import message as mes
from util.baidubce_api import BaiDuBce
from util.locate import geocoding
from dj2.settings import dbName as schemaName
from dj2.settings import hasHadoop
from django.db import connection
from hdfs.client import Clientdef schemaName_cal(request, tableName, columnName):'''计算规则接口'''if request.method in ["POST", "GET"]:msg = {"code": normal_code, 'data': []}allModels = apps.get_app_config('main').get_models()for m in allModels:if m.__tablename__ == tableName:data = m.getcomputedbycolumn(m,m,columnName)print(data)if data:try:sum='%.05f' % float(data.get("sum"))except:sum=0.00try:max='%.05f' % float(data.get("max"))except:max=0.00try:min='%.05f' % float(data.get("min"))except:min=0.00try:avg='%.05f' % float(data.get("avg"))except:avg=0.00msg['data'] = {"sum": sum,"max": max,"min": min,"avg": avg,}breakreturn JsonResponse(msg)def schemaName_file_upload(request):'''上传'''if request.method in ["POST", "GET"]:msg = {"code": normal_code, "msg": "成功", "data": {}}file = request.FILES.get("file")if file:filename = file.namefilesuffix = filename.split(".")[-1]file_name = "{}.{}".format(int(float(time.time()) * 1000), filesuffix)filePath = os.path.join(os.getcwd(), "templates/front", file_name)print("filePath===========>", filePath)with open(filePath, 'wb+') as destination:for chunk in file.chunks():destination.write(chunk)msg["file"] = file_name# 判断是否需要保存为人脸识别基础照片req_dict = request.session.get("req_dict")type1 = req_dict.get("type", 0)print("type1=======>",type1)type1 = int(type1)if type1 == 1:params = {"name":"faceFile","value": file_name}config.createbyreq(config, config, params)if '是' in hasHadoop or 'spark' in hasHadoop:try:client = Client("http://127.0.0.1:50070/")client.upload(hdfs_path=f'/{file_name}', local_path=filePath, chunk_size=2 << 19, overwrite=True)except Exception as e:print(f"hdfs upload error : {e}")return JsonResponse(msg)def schemaName_file_download(request):'''下载'''if request.method in ["POST", "GET"]:req_dict = request.session.get("req_dict")filename = req_dict.get("fileName")filePath = os.path.join(os.getcwd(), "templates/front", filename)print("filePath===========>", filePath)if '是' in hasHadoop or 'spark' in hasHadoop:try:client = Client("http://127.0.0.1:50070/")client.download(hdfs_path=f'/{filename}', local_path=filename, overwrite=True)except Exception as e:print(f"hdfs download error : {e}")file = open(filePath, 'rb')response = HttpResponse(file)response['Content-Type'] = 'text/plain'response['Content-Disposition'] = 'attachment; filename=%s' % os.path.basename(filePath)response['Content-Length'] = os.path.getsize(filePath)return responsedef schemaName_follow_level(request, tableName, columnName, level, parent):''''''if request.method in ["POST", "GET"]:msg = {"code": normal_code, 'data': []}# 组合查询参数params = {"level": level,"parent": parent}allModels = apps.get_app_config('main').get_models()for m in allModels:if m.__tablename__ == tableName:data = m.getbyparams(m,m,params)# 只需要此列的数据for i in data:msg['data'].append(i.get(columnName))breakreturn JsonResponse(msg)def schemaName_follow(request, tableName, columnName):'''根据option字段值获取某表的单行记录接口组合columnName和columnValue成dict,传入查询方法'''if request.method in ["POST", "GET"]:msg = {"code": normal_code, 'data': []}# 组合查询参数params = request.session.get('req_dict')columnValue = params.get("columnValue")params = {columnName: columnValue}allModels = apps.get_app_config('main').get_models()for m in allModels:if m.__tablename__ == tableName:data = m.getbyparams(m,m,params)if len(data)>0:msg['data'] = data[0]breakreturn JsonResponse(msg)def schemaName_location(request):'''定位:return:'''if request.method in ["POST", "GET"]:msg = {"code": normal_code, "msg": mes.normal_code, "address": ''}req_dict = request.session.get('req_dict')datas = config.getbyparams(config, config, {"name": "baidu_ditu_ak"})if len(datas) > 0:baidu_ditu_ak = datas[0].get("baidu_ditu_ak")else:baidu_ditu_ak = 'QvMZVORsL7sGzPyTf5ZhawntyjiWYCif'lat = req_dict.get("lat", 24.2943350100)lon = req_dict.get("lng", 116.1287866600)msg['address'] = geocoding(baidu_ditu_ak, lat, lon)return JsonResponse(msg)def schemaName_matchface(request):'''baidubce百度人脸识别'''if request.method in ["POST", "GET"]:try:msg = {"code": normal_code}req_dict = request.session.get("req_dict")face1 = req_dict.get("face1")file_path1 = os.path.join(os.getcwd(),"templates/front",face1)face2 = req_dict.get("face2")file_path2 = os.path.join(os.getcwd(), "templates/front", face2)data = config.getbyparams(config, config, {"name": "APIKey"})client_id = data[0].get("value")data = config.getbyparams(config, config, {"name": "SecretKey"})client_secret = data[0].get("value")bdb = BaiDuBce()score = bdb.bd_check2pic(client_id, client_secret, file_path1, file_path2)msg['score'] = scorereturn JsonResponse(msg)except:return JsonResponse({"code": 500, "msg": "匹配失败", "score": 0})def schemaName_option(request, tableName, columnName):'''获取某表的某个字段列表接口:param request::param tableName::param columnName::return:'''if request.method in ["POST", "GET"]:msg = {"code": normal_code, 'data': []}new_params = {}params = request.session.get("req_dict")if params.get('conditionColumn') != None and params.get('conditionValue') != None:new_params[params['conditionColumn']] = params['conditionValue']allModels = apps.get_app_config('main').get_models()for m in allModels:if m.__tablename__ == tableName:data = m.getbyColumn(m,m,columnName,new_params)msg['data'] = databreakreturn JsonResponse(msg)def schemaName_remind_tablename_columnname_type(request, tableName, columnName, type)->int:'''前台提醒接口(通用接口,不需要登陆)'''if request.method in ["POST", "GET"]:msg = {"code": normal_code, 'data': []}# 组合查询参数params = request.session.get("req_dict")remindstart = int(params.get('remindstart')) if params.get('remindstart') != None else Noneremindend = int(params.get('remindend')) if params.get('remindend') != None else Noneif int(type) == 1: # 数字if remindstart == None and remindend != None:params['remindstart'] = 0elif remindstart != None and remindend == None:params['remindend'] = 999999elif remindstart == None and remindend == None:params['remindstart'] = 0params['remindend'] = 999999elif int(type) == 2: # 日期current_time = int(time.time())if remindstart == None and remindend != None:starttime = current_time - 60 * 60 * 24 * 365 * 2params['remindstart'] = time.strftime("%Y-%m-%d", time.localtime(starttime))endtime = current_time + 60 * 60 * 24 * remindendparams['remindend'] = time.strftime("%Y-%m-%d", time.localtime(endtime))elif remindstart != None and remindend == None:starttime = current_time - 60 * 60 * 24 * remindstartparams['remindstart'] = time.strftime("%Y-%m-%d", time.localtime(starttime))endtime = current_time + 60 * 60 * 24 * 365 * 2params['remindend'] = time.strftime("%Y-%m-%d", time.localtime(endtime))elif remindstart == None and remindend == None:starttime = current_time - 60 * 60 * 24 * 365 * 2params['remindstart'] = time.strftime("%Y-%m-%d", time.localtime(starttime))endtime = current_time + 60 * 60 * 24 * 365 * 2params['remindend'] = time.strftime("%Y-%m-%d", time.localtime(endtime))allModels = apps.get_app_config('main').get_models()for m in allModels:if m.__tablename__ == tableName:data = m.getbetweenparams(m,m,columnName,params)msg['count'] = len(data)breakreturn JsonResponse(msg)def schemaName_tablename_remind_columnname_type(request, tableName, columnName, type):'''后台提醒接口,判断authSeparate和authTable的权限'''if request.method in ["POST", "GET"]:print("schemaName_tablename_remind_columnname_type==============>")msg = {"code": normal_code, 'data': []}req_dict = request.session.get("req_dict")remindstart = int(req_dict.get('remindstart')) if req_dict.get('remindstart')!=None else Noneremindend = int(req_dict.get('remindend')) if req_dict.get('remindend')!=None else Noneprint("req_dict===================>",req_dict)allModels = apps.get_app_config('main').get_models()for m in allModels:if m.__tablename__ == tableName:tableModel=mbreak# 获取全部列名columns = tableModel.getallcolumn(tableModel, tableModel)# 当前登录用户所在表tablename = request.session.get("tablename")# 当列属性authTable有值(某个用户表)[该列的列名必须和该用户表的登陆字段名一致],则对应的表有个隐藏属性authTable为”是”,那么该用户查看该表信息时,只能查看自己的try:__authTables__ =tableModel.__authTables__except:__authTables__ = {}if __authTables__ != {}:for authColumn, authTable in __authTables__.items():if authTable == tablename:params = request.session.get("params")req_dict[authColumn] = params.get(authColumn)break'''__authSeparate__此属性为真,params添加userid,后台只查询个人数据'''try:__authSeparate__ =tableModel.__authSeparate__except:__authSeparate__ = Noneif __authSeparate__ == "是":tablename = request.session.get("tablename")if tablename != "users" and 'userid' in columns:try:pass# req_dict['userid'] = request.session.get("params").get("id")except:pass# 组合查询参数if int(type) == 1: # 数字if remindstart == None and remindend != None:req_dict['remindstart'] = 0elif remindstart != None and remindend == None:req_dict['remindend'] = 999999elif remindstart == None and remindend == None:req_dict['remindstart'] = 0req_dict['remindend'] = 999999elif int(type) == 2: # 日期current_time = int(time.time())if remindstart == None and remindend != None:starttime = current_time - 60 * 60 * 24 * 365 * 2req_dict['remindstart'] = time.strftime("%Y-%m-%d", time.localtime(starttime))endtime = current_time + 60 * 60 * 24 * remindendreq_dict['remindend'] = time.strftime("%Y-%m-%d", time.localtime(endtime))elif remindstart != None and remindend == None:starttime = current_time + 60 * 60 * 24 * remindstartreq_dict['remindstart'] = time.strftime("%Y-%m-%d", time.localtime(starttime))endtime = current_time + 60 * 60 * 24 * 365 * 2req_dict['remindend'] = time.strftime("%Y-%m-%d", time.localtime(endtime))elif remindstart == None and remindend == None:starttime = current_time - 60 * 60 * 24 * 365 * 2req_dict['remindstart'] = time.strftime("%Y-%m-%d", time.localtime(starttime))endtime = current_time + 60 * 60 * 24 * 365 * 2req_dict['remindend'] = time.strftime("%Y-%m-%d", time.localtime(endtime))else:starttime = current_time + 60 * 60 * 24 * remindstartreq_dict['remindstart'] = time.strftime("%Y-%m-%d", time.localtime(starttime))endtime = current_time + 60 * 60 * 24 * remindendreq_dict['remindend'] = time.strftime("%Y-%m-%d", time.localtime(endtime))print("req_dict==============>",req_dict)allModels = apps.get_app_config('main').get_models()for m in allModels:if m.__tablename__ == tableName:data = m.getbetweenparams(m,m,columnName,req_dict)msg['count'] = len(data)breakreturn JsonResponse(msg)def schemaName_sh(request, tableName):'''根据主键id修改table表的sfsh状态接口'''if request.method in ["POST", "GET"]:print('tableName=========>', tableName)msg = {"code": normal_code, "msg": "成功", "data": {}}req_dict = request.session.get("req_dict")allModels = apps.get_app_config('main').get_models()for m in allModels:if m.__tablename__ == tableName:# 查询结果data1 = m.getbyid(m,m,req_dict.get('id'))if data1[0].get("sfsh") == '是':req_dict['sfsh'] = '否'else:req_dict['sfsh'] = '否'# 更新res = m.updatebyparams(m,m,req_dict)# logging.warning("schemaName_sh.res=====>{}".format(res))if res!=None:msg["code"]=crud_error_codemsg["code"]=mes.crud_error_codebreakreturn JsonResponse(msg)def schemaName_upload(request, fileName):''''''if request.method in ["POST", "GET"]:return HttpResponseRedirect ("/{}/front/{}".format(schemaName,fileName))def schemaName_group_quyu(request, tableName, columnName):'''{"code": 0,"data": [{"total": 2,"shangpinleibie": "水果"},{"total": 1,"shangpinleibie": "蔬菜"}]}'''if request.method in ["POST", "GET"]:msg = {"code": normal_code, "msg": "成功", "data": {}}allModels = apps.get_app_config('main').get_models()where = {}for m in allModels:if m.__tablename__ == tableName:for item in m.__authTables__.items():if request.session.get("tablename") == item[1]:where[item[0]] = request.session.get("params").get(item[0])msg['data'] = m.groupbycolumnname(m,m,columnName,where)breakreturn JsonResponse(msg)def schemaName_value_quyu(request, tableName, xColumnName, yColumnName):'''按值统计接口,{"code": 0,"data": [{"total": 10.0,"shangpinleibie": "aa"},{"total": 20.0,"shangpinleibie": "bb"},{"total": 15.0,"shangpinleibie": "cc"}]
}'''if request.method in ["POST", "GET"]:msg = {"code": normal_code, "msg": "成功", "data": {}}allModels = apps.get_app_config('main').get_models()where = {}for m in allModels:if m.__tablename__ == tableName:for item in m.__authTables__.items():if request.session.get("tablename") == item[1]:where[item[0]] = request.session.get("params").get(item[0])msg['data'] = m.getvaluebyxycolumnname(m,m,xColumnName,yColumnName,where)breakreturn JsonResponse(msg)def schemaName_value_riqitj(request, tableName, xColumnName, yColumnName, timeStatType):if request.method in ["POST", "GET"]:msg = {"code": normal_code, "msg": "成功", "data": {}}where = ' where 1 = 1 'allModels = apps.get_app_config('main').get_models()for m in allModels:if m.__tablename__ == tableName:for item in m.__authTables__.items():if request.session.get("tablename") == item[1]:where = where + " and " + item[0] + " = '" + request.session.get("params").get(item[0]) + "' "sql = ''if timeStatType == '日':sql = "SELECT DATE_FORMAT({0}, '%Y-%m-%d') {0}, sum({1}) total FROM {3} {2} GROUP BY DATE_FORMAT({0}, '%Y-%m-%d')".format(xColumnName, yColumnName, where, tableName, '%Y-%m-%d')if timeStatType == '月':sql = "SELECT DATE_FORMAT({0}, '%Y-%m') {0}, sum({1}) total FROM {3} {2} GROUP BY DATE_FORMAT({0}, '%Y-%m')".format(xColumnName, yColumnName, where, tableName, '%Y-%m')if timeStatType == '年':sql = "SELECT DATE_FORMAT({0}, '%Y') {0}, sum({1}) total FROM {3} {2} GROUP BY DATE_FORMAT({0}, '%Y')".format(xColumnName, yColumnName, where, tableName, '%Y')L = []cursor = connection.cursor()cursor.execute(sql)desc = cursor.descriptiondata_dict = [dict(zip([col[0] for col in desc], row)) for row in cursor.fetchall()] for online_dict in data_dict:for key in online_dict:if 'datetime.datetime' in str(type(online_dict[key])):online_dict[key] = online_dict[key].strftime("%Y-%m-%d %H:%M:%S")else:passL.append(online_dict)msg['data'] = Lreturn JsonResponse(msg)def schemaName_spider(request, tableName):if request.method in ["POST", "GET"]:msg = {"code": normal_code, "msg": "成功", "data": []}# Linuxcmd = "cd /yykj/python/9999/spider1m655 && scrapy crawl "+tableName+"Spider -a databaseName=django2w931"# Windows# cmd = "cd C:\\test1\\spider && scrapy crawl " + tableName + "Spider"os.system(cmd)return JsonResponse(msg)系统测试
黑盒测试主要测试整个功能模块,检验该功能是否正确、前后端接口调用有没有错误、输入输出的格式正确与否、连接MySQL进行增删改查操作数据是否错误等。
白盒测试主要是通过语句覆盖、条件覆盖等测试方法对代码语句和逻辑进行检验。通过该方法可以找到黑盒测试无法覆盖的错误,使生成的测试用例能够很好的覆盖测试需求,达到及时发现问题并解决的测试目的。
对于小说推荐系统来说,首先需要采用白盒测试检查代码的所有逻辑的准确性,同时也需要使用黑盒测试对系统整体功能的实现进行用户体验测试。
结论
本文设计实现了一个基于协同过滤算法的小说推荐系统,该系统以python进行开发,使用Django后端框架,MySQL为数据库。本系统主要包括对个人中心、用户管理、小说信息管理、系统管理等功能进行操作。
应用本系统,有利于系统信息管理模式上实现科学化的管理和信息化的经营。该系统所包含的功能基本满足用户的需求。因开发时间和本人知识储备及能力等因素的限制,使得系统可能存在一定的缺陷,我们需要对系统进行反复地测试,改进不足之处,不断的进行更新迭代,使其能够拥有更大的市场。