Langchain 和LangGraph 为何是AI智能体开发的核心技术
LangChain 和 LangGraph 是当前大语言模型(LLM)应用开发中非常重要的两个技术框架,它们在AI领域的技术底座落地中扮演不同角色,各有明确的应用场景和优势。以下从技术架构、应用场景和核心优势三个维度进行深度解析:
一、LangChain 的技术底座落地
1. 核心定位
LangChain 是一个模块化、通用化的LLM应用开发框架,核心目标是降低LLM应用开发门槛,提供数据连接、代理决策、记忆管理等能力。
2. 技术底座落地场景
- 数据增强型应用:通过
Retrieval-Augmented Generation (RAG)技术,将私有数据注入LLM推理流程(如企业知识库问答系统)。 - 代理式决策系统:结合工具调用(如API、数据库查询、代码执行),构建自主决策Agent(如自动化客服、数据分析助手)。
- 记忆管理:通过短期记忆(ConversationBufferMemory)和长期记忆(向量数据库存储)实现上下文感知的对话系统。
3. 核心优势
| 优势维度 | 具体表现 |
|---|---|
| 生态集成能力 | 支持300+ LLM和工具集成(OpenAI、HuggingFace、SQLAlchemy等),生态丰富性领先。 |
| 灵活性 | 模块化设计允许自由组合LLM、Prompt、Chain、Tool,适合快速原型开发。 |
| 数据处理能力 | 内置文档加载器(PDF/HTML/数据库)、文本分割器和向量存储,简化RAG流程开发。 |
| 成本控制 | 支持轻量级模型(如Llama.cpp)和流式处理,降低推理成本。 |
4. 典型代码示例(RAG应用)
from langchain_community.document_loaders import PyPDFLoader
from langchain_openai import OpenAIEmbeddings
from langchain_community.vectorstores import FAISS
from langchain.chains import RetrievalQA
from langchain_openai import ChatOpenAI# 加载PDF文档
loader = PyPDFLoader("company_report.pdf")
docs = loader.load()# 构建向量数据库
vectorstore = FAISS.from_documents(docs, OpenAIEmbeddings())# 创建RAG链
qa_chain = RetrievalQA.from_chain_type(llm=ChatOpenAI(model="gpt-3.5-turbo"),chain_type="stuff",retriever=vectorstore.as_retriever()
)# 执行查询
response = qa_chain.invoke({"query": "公司2023年营收增长率是多少?"})
print(response["result"])
二、LangGraph 的技术底座落地
1. 核心定位
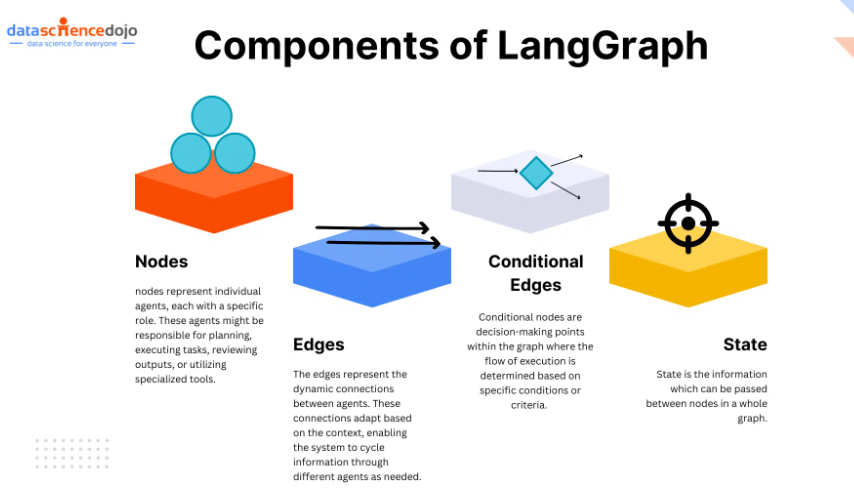
LangGraph 是 LangChain 的扩展框架,专注于基于状态的图计算(Stateful Graph Computation),解决复杂Agent流程编排问题。
2. 技术底座落地场景
- 多步骤工作流:如电商客服系统需依次执行意图识别→商品查询→订单处理→反馈收集。
- 状态持久化:在长时间运行的对话系统中(如游戏NPC、虚拟助手),需要保存和恢复用户状态。
- 条件分支逻辑:根据用户输入动态调整流程(如贷款审批中的信用评估→风控审核→放款决策)。
3. 核心优势
| 优势维度 | 具体表现 |
|---|---|
| 流程编排能力 | 通过图节点(Node)和边(Edge)定义复杂状态机,支持条件跳转和并行执行。 |
| 状态管理 | 内置Checkpointer机制(支持Redis/DynamoDB等),实现状态持久化和故障恢复。 |
| 可观察性 | 提供Execution History追踪,便于调试和审计(如显示每个节点的输入输出)。 |
| 扩展性 | 支持自定义节点逻辑和路由规则,适应复杂业务需求。 |
4. 典型代码示例(客服对话流程)
from langgraph.graph import StateGraph, END# 定义状态结构
class AgentState(TypedDict):user_input: strintent: strproduct_info: dictorder_status: str# 定义节点函数
def detect_intent(state: AgentState):# 意图识别逻辑if "订单" in state["user_input"]:return {"intent": "order_inquiry"}return {"intent": "product_search"}def fetch_product_info(state: AgentState):# 产品信息查询return {"product_info": {"price": 299, "stock": 50}}def check_order_status(state: AgentState):# 订单状态查询return {"order_status": "已发货"}# 构建图流程
workflow = StateGraph(AgentState)
workflow.add_node("intent_detection", detect_intent)
workflow.add_node("product_search", fetch_product_info)
workflow.add_node("order_inquiry", check_order_status)# 添加边
workflow.add_edge("intent_detection", "product_search")
workflow.add_edge("intent_detection", "order_inquiry")# 条件路由
def route_intent(state: AgentState):return "product_search" if state["intent"] == "product_search" else "order_inquiry"workflow.add_conditional_edges("intent_detection", route_intent)
workflow.set_entry_point("intent_detection")
workflow.add_edge("product_search", END)
workflow.add_edge("order_inquiry", END)# 编译并运行
app = workflow.compile()
result = app.invoke({"user_input": "我的订单状态如何?"})
print(result)
三、LangChain vs LangGraph 对比总结
| 维度 | LangChain | LangGraph |
|---|---|---|
| 核心能力 | 通用LLM应用开发框架 | 状态驱动的流程编排框架 |
| 适用场景 | 单次任务、数据增强、简单代理 | 多步骤工作流、状态持久化、复杂决策 |
| 学习曲线 | 低(模块化API友好) | 中高(需理解状态机概念) |
| 性能开销 | 轻量级(适合快速响应) | 略高(状态追踪和持久化开销) |
| 最佳搭档 | Streamlit/FastAPI(前端集成) | Redis/PostgreSQL(状态存储) |
四、技术选型建议
选择LangChain的场景:
- 需要快速构建RAG系统、数据问答机器人
- 项目需求以单次交互为主(如文档摘要生成)
- 团队对LLM开发经验不足,需要快速上手
选择LangGraph的场景:
- 需要构建长期运行的对话系统(如企业级客服)
- 流程包含多步骤条件分支(如医疗问诊系统)
- 要求严格的流程审计和状态恢复能力
协同使用方案:
- 用LangChain实现单节点功能(如文档检索、工具调用)
- 用LangGraph编排这些节点形成完整业务流程
五、技术演进趋势
- LangChain:正在强化与AI代理框架(如AutoGen)的集成,增加可视化工具(LangSmith)。
- LangGraph:向分布式计算(如Kafka消息队列支持)和低代码方向发展,降低状态机设计门槛。
通过合理选择LangChain和LangGraph,可以构建从轻量级问答系统到企业级智能流程自动化的完整AI技术底座。在实际项目中,建议优先用LangChain验证核心功能,再通过LangGraph升级为可维护的生产级系统。
阿里百炼生成信息
我是通过阿里百炼的大模型配置到chatboxAI采用知识助手来生成信息比对,下面是token消耗情况和大模型:
- tokens used: 3220,
- model: 阿里云百炼 (qwen3-235b-a22b)