LORA参数微调
文章目录
- 序
- 原始博客
- 结论
- 详细
- 1. α\alphaα越大越好
- 2. 调节学习率与α\alphaα作用一样
- 3. rsLORA在困难任务上有用
序
LORA中最重要的是缩放因子α\alphaα与秩rrr,它们共同决定LORA矩阵在推理中作用大小。其公式如下:
h=W0x+αrBAxh = W_0x+\frac{\alpha}{r}BAx h=W0x+rαBAx
关于这两个参数的关系,网上有很多不同的观点,有说他们应该是2倍关系,有人说要大很多,也有人说应该是其他的关系。这些都不重要的,可以做为参考,在实际中,最好您都试试,尽量多多的尝试吧。
原始博客
内容来自以下博客Finding the best LoRA parameters 作者基于自己的简易任务,做了一些实验并输出了实验内容。
结论
- LORA原论文推荐,保持默认α\alphaα不变,调节rrr和学习率即可。
- 固定rrr下,α\alphaα大值效果更好。
- 固定rrr下,α\alphaα与学习率作用类似。
详细
1. α\alphaα越大越好
在博客中,他们分别固定r=128和r=2r=128和r=2r=128和r=2下,分别尝试了α值为0.5,2,8,32,128,256,512\alpha值为0.5, 2, 8, 32, 128, 256, 512α值为0.5,2,8,32,128,256,512,神奇的是无论rrr的大小,都表明α\alphaα越大收敛越快,最终效果也越好。实验结果如下:
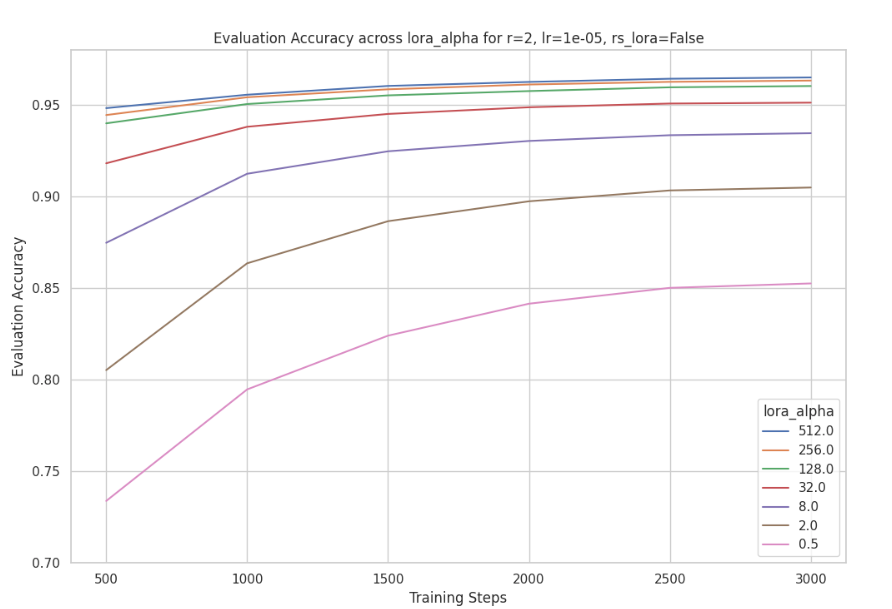
2. 调节学习率与α\alphaα作用一样
设置了三组实验,结果表明,lr与α\alphaα具有类似作用或者等价,其结果如图所示:
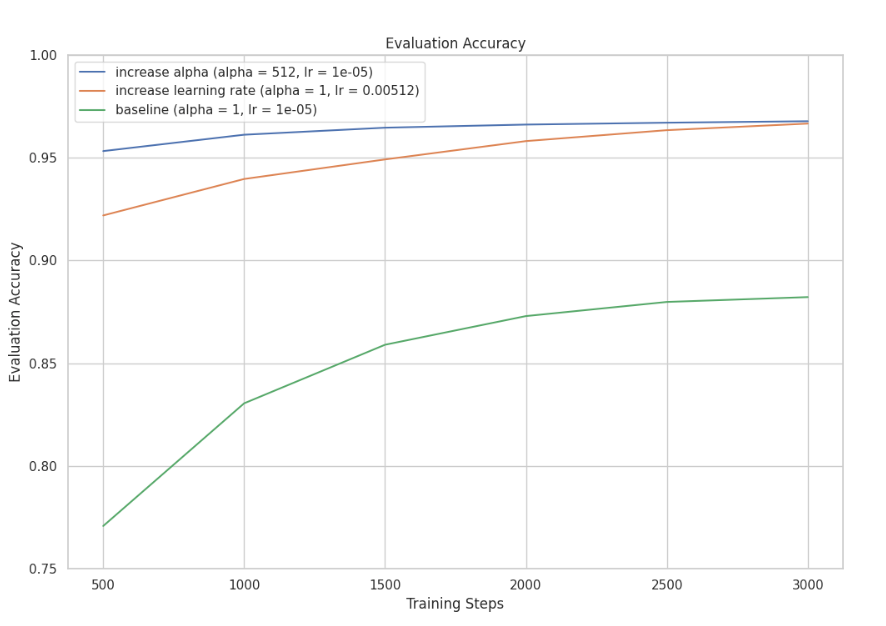
3. rsLORA在困难任务上有用
rsLORA主要是改动了整个缩放因子,整个新公式如下。改动原因是原作文发现,训练LORA效果不稳定,原因是缩放因子过小,导致难以发挥出来其作用。αr\frac{\alpha}{r}rα比较激进,导致整体的缩放因子较小,所以难以发挥大秩r的作用。
h=W0x+αrBAxh = W_0x+\frac{\alpha}{\sqrt{r}} BAxh=W0x+rαBAx
在简单任务下,rslora效果一般,但是在复杂训练场景下,rslora效果比较好。