JVM(Java Virtual Machine)
JVM概述
在Java学习的起初就提到了JVM
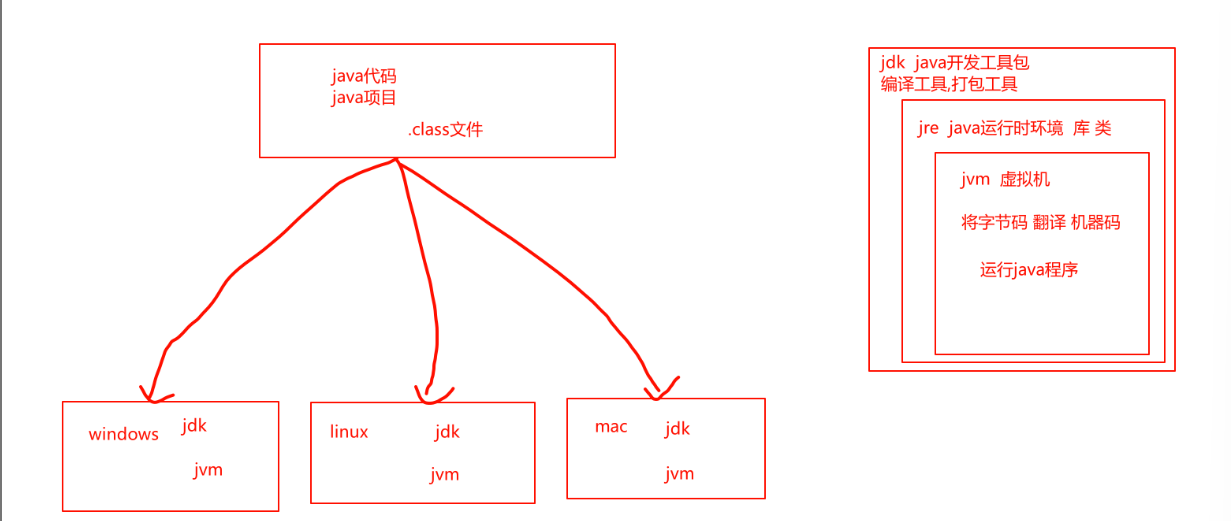
JVM的作用
装载字节码 将字节码转换为对应平台的机器码
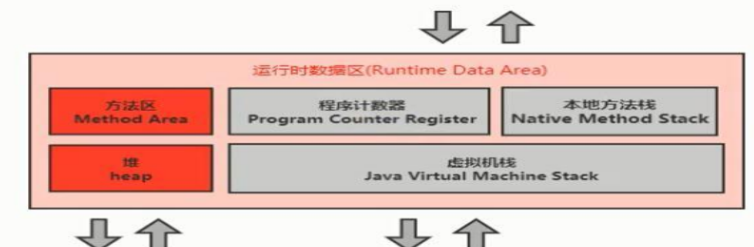
JVM构成
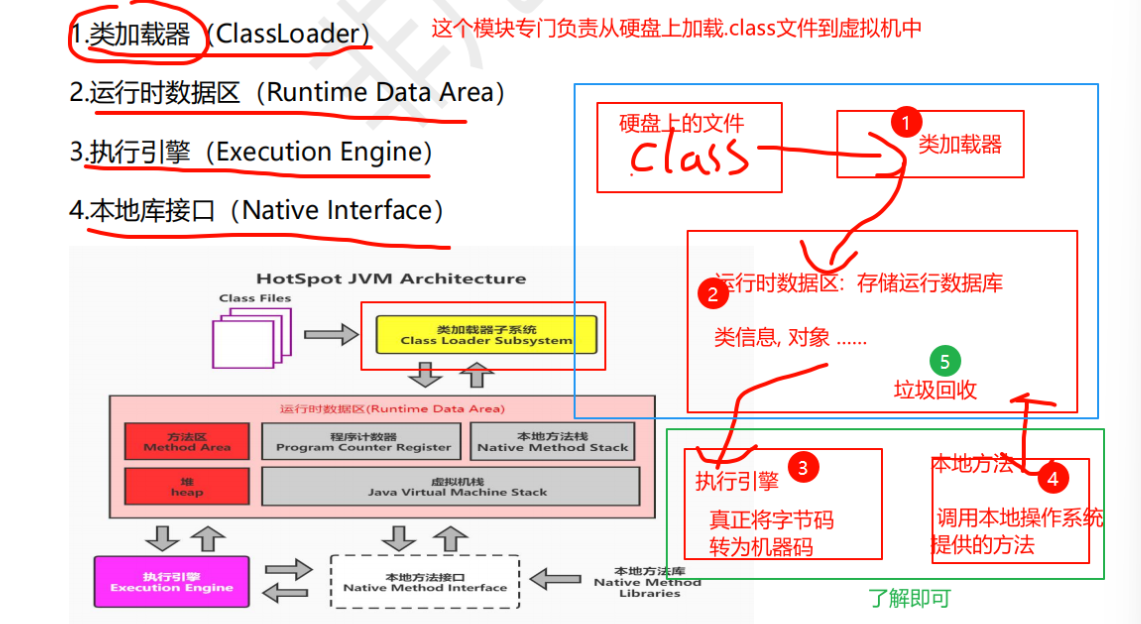
1.类加载器 (重点)
2.运行时数据区 (重点)
3.执行引擎 (了解)
4.本地库接口 (了解)
5.针对运行时数据区提供的垃圾回收 (重点)
一,类加载
概念:
通过类加载模块将硬盘上的.class文件加载到运行时数据区中
类加载过程:
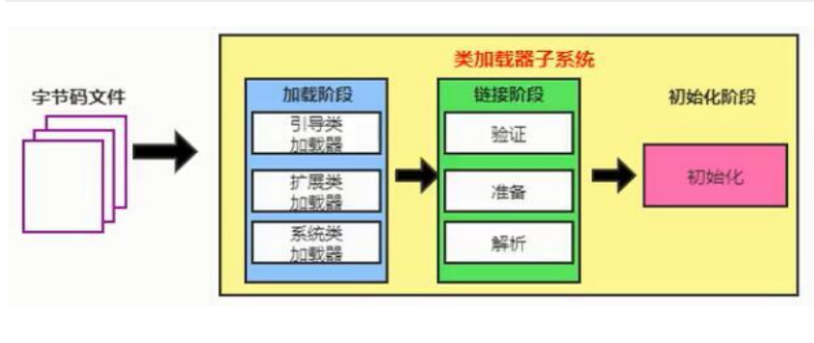
1.加载阶段(利用IO的读取字节码)
2.链接阶段
验证 字节码是否被污染(格式不对)
准备
解析
3.初始化 对类中的静态成员初始化赋值
当类加载完成初始化阶段时,一个类才真正完成了了加载的整个过程
例:面试题:类什么时候被加载
类被使用时会加载类
1.创建某个类的对象时,new Hellow();
2.访问类中的静态成员
3.反射机制加载类 Class.forName("com.ffyc.javapro.jvm.Hello")
4.执行某个类中的main方法
5.子类被加载时,会加载对应的父类
还有两种特殊情况,看似使用了类,但是类不会被加载
1.只是用了类中的静态值
2.类被当做类型使用,如创建一个Hello类型的数组Hello[] hellos = new Hello[10]
二,类加载器
概述:理解为专门加载类的类
类加载器的分类:

1.启动类加载器(引导类加载器)
不是java语言写的,有c/c++写的,嵌入到虚拟机中,用于虚拟机启动时,读取java核心类库(系统中类)
2.扩展类加载器
这种类加载器是由java语言写的,继承ClassLoader类,读取\jre\lib\ext目录下的类,这个目录中类属于扩展类,自己也可以写一些类,放在此目录下
3.应用程序类加载器
也是由java语言写的,专门读取程序员写的应用程序中的类
package com.ffyc.javapro.jvm;public class TestClassLoader {public static void main(String[] args) {
System.out.println(String.class.getClassLoader());//null 说明String类是由引导类加载器加载的 System.out.println(Hello.class.getClassLoader());//sun.misc.Launcher$AppClassLoader@18b4aac2 说明Hello类是由应用程序类加载器加载的System.out.println(Hello.class.getClassLoader().getClass().getClassLoader());//null 说明应用程序加载器的加载其也是由引导类加载器加载的}
}
4.自定义类加载器(继承ClassLoader类)
程序员自己定义的类加载器
双亲委派机制
jvm加载类时,遵循双亲委派机制
当加载一个类时,先让上级的类加载器去加载,优先加载系统中的类,如果系统中没有,才会委派给下级类加载器,下级如果找到了,那么久加载该类,如果下级也没有找到,就抛出类找不到异常(ClassNotFoundException)
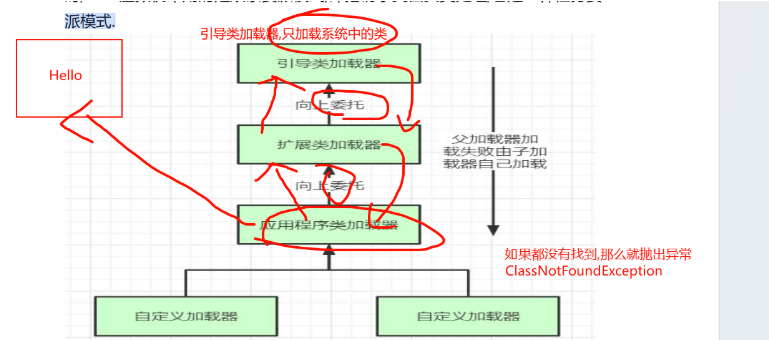
为什么使用双亲委派机制
为了安全,避免我们自己写的类替换了系统中类
如何打破双亲委派机制
可以通过自定义类加载器打破
写一个类继承ClassLoader类
重写findClass()方法
例:
package com.ffyc.javapro.jvm;import java.io.BufferedInputStream;
import java.io.ByteArrayOutputStream;
import java.io.FileInputStream;
import java.io.IOException;/*** 自定义类加载器*/
public class MyClassLoader extends ClassLoader{//类的路径private String classPath;public MyClassLoader(ClassLoader parent, String codePath) {super(parent);this.classPath = codePath;}public MyClassLoader(String codePath) {this.classPath = codePath;}@Overrideprotected Class<?> findClass(String name) throws ClassNotFoundException {BufferedInputStream bis=null;ByteArrayOutputStream baos=null;//完整的类名String file = classPath+name+".class";try {//初始化输入流bis = new BufferedInputStream(new FileInputStream(file));//获取输出流baos=new ByteArrayOutputStream();int len;byte[] data=new byte[1024];while ((len=bis.read(data))!=-1){baos.write(data,0,len);}//获取内存中的字节数组byte[] bytes = baos.toByteArray();//调用defineClass将字节数组转换成class实例Class<?> clazz = defineClass(null, bytes, 0, bytes.length);return clazz;} catch (Exception e) {e.printStackTrace();}finally {try {bis.close();} catch (IOException e) {e.printStackTrace();}try {baos.close();} catch (IOException e) {e.printStackTrace();}}return null;}public static void main(String[] args) {MyClassLoader myClassLoader = new MyClassLoader("E:/");try {Class<?> clazz = myClassLoader.findClass("Hello"); //ClssLoader中lodClass走正常的双亲委派机制加载类//打印具体的类加载器,验证是否是由我们自己定义的类加载器加载的System.out.println("测试字节码是由"+clazz.getClassLoader().getClass().getName()+"加载的。。");Object o = clazz.newInstance();System.out.println(o.toString());} catch (Exception e) {e.printStackTrace();}}
}
三,运行时数据区
当程序启动运行时,类信息,对象信息等都存储在运行时数据区, 顾名思义就是存储运行时数据的区域.
运行时数据区可以分为5个区域:
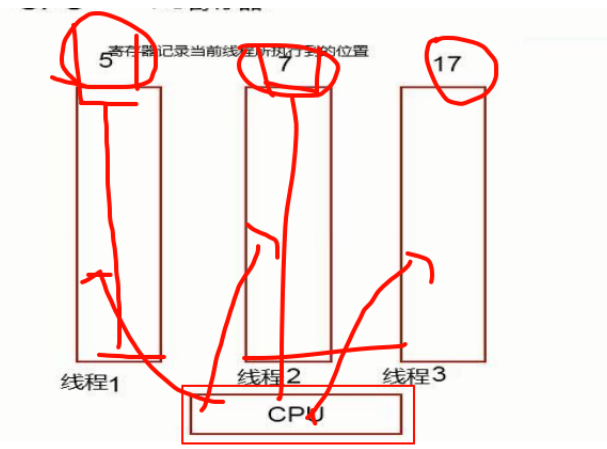
1.程序计数器
作用:程序计数器用来记录cpu执行到程序指令的位置。
cpu要切换执行许多的程序,在切换之前需要记录程序本次执行的位置,下次回来继续接着执行
特点:
内存空间小,运行速度快
线程私有的,每个线程都有一个自己的私有的程序计数器
生命周期与线程生命周期一致(线程创建启动后 计数器开始工作,线程结束程序计数器也就结束)
程序计数器中不存在内存溢出情况(内存不够用),也不会出现垃圾回收
2.虚拟机栈
作用:栈是运行的结构设计,管的是程序(方法)如何执行,虚拟机栈是用来运行Java语言写的方法
java总是main方法先执行,main第一个被压入到栈中,在调用其他的方法,继续被压入到栈中,方法用完就出栈,最顶上的就是当前正在运行的方法
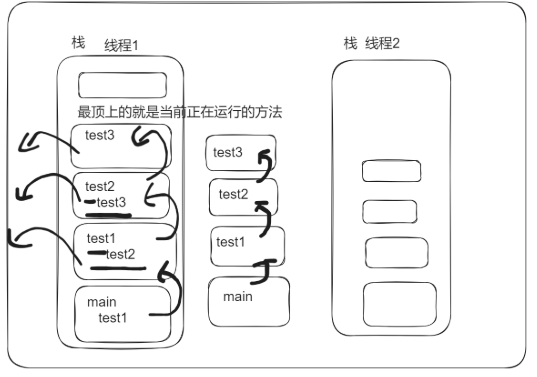
特点:
虚拟机栈是线程私有的,每个线程创建就会创建一个虚拟机栈
方法入栈后,称为一个栈帧(保存方法中的信息)
栈空间不存在垃圾回收
可能存在内存溢出问题(内存不够用),如递归调用次数过多,栈中放不了
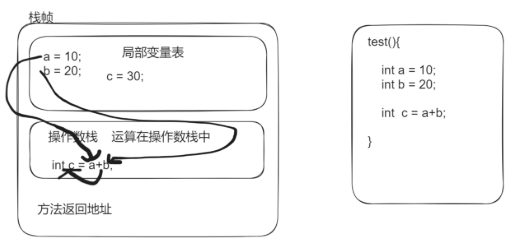
栈帧结构
1.存储方法中生命的局部变量
2.操作数栈,所有程序的运算都在操作数栈中进行
3.方法返回地址
3.本地方法栈
本地方法栈是用来运行本地方法的(c/c++写的系统方法)
本地方法栈也是线程私有的
不会出现垃圾回收,
但是可能会出现内存溢出
4.堆
作用:Java中创建的对象,都存储在堆空间中
特点:堆是运行时数据区中最大的一块内存区域
堆是线程共享,所有的线程共享堆中的数据
堆的大小可以调整(通过一些参数进行设置)
堆空间是垃圾回收的重点区域
堆空间是可能出现内存溢出的
堆内存区域划分
新生代(年轻代,新生区)
伊甸园区
幸存者0
幸存者1
老年区(老年区)
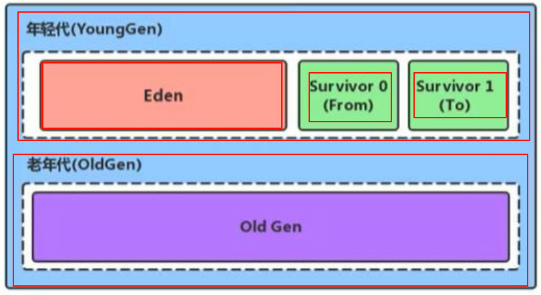
为什么要分区
把不同生命周期的对象存储在不同的区域(有的对象存活时间不长),针对不同的区域采用不同的回收算法,频繁的回收新生代,较少的回收老年代
对象内存分配过程
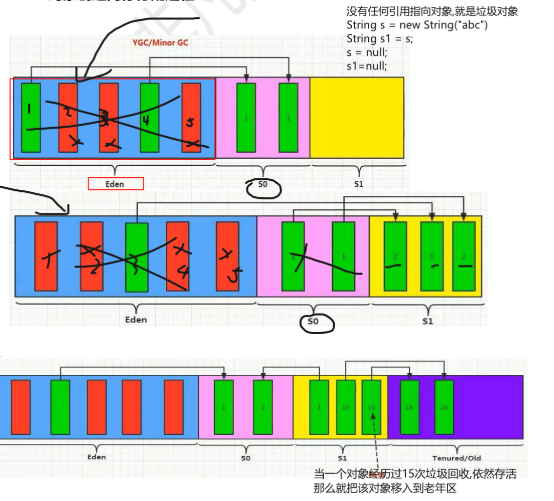
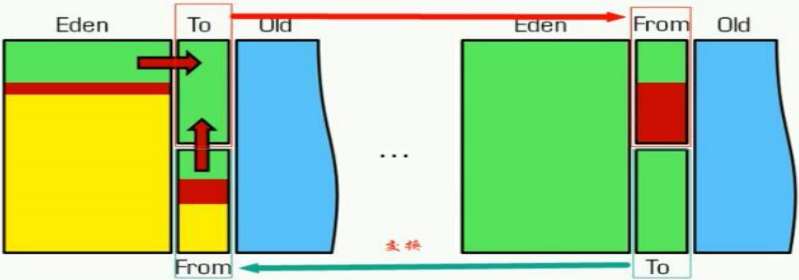
Java中新创建的对象,都存储在新生代的伊甸园区,当垃圾回收发生时,会将伊甸园中的存活对象移动到幸存者0区
清空伊甸园区,继续创建对象,当下次垃圾回收执行时,将伊甸园区和幸存者0区存活的对象都移动到幸存者1区
每次垃圾回收只是用一个幸存者区
当一个对象默认回收15次后,依旧存活那么将该对象移动到老年代
为什么回收次数最大为15次?能不能改?
对象头有一块记录分代年龄的区域,最大4个bit位,表示最大为15
-XX:MaxTenuringThreshold=<N>

堆空间的参数设置(了解)
堆空间的大小如何设置(jvm调优)
-XX:+PrintFlagsInitial
查看所有参数的默认初始值
-Xms:初始堆空间内存
-Xmx:最大堆空间内存
-Xmn:设置新生代的大小
-XX:MaxTenuringTreshold:设置新生代垃圾的最大年龄
-XX:+PrintGCDetails 输出详细的 GC 处理日志
注:参数调节可以在idea中进行修改
Edit Configuration
勾选红圈中的Add VM option
然后将调节参数添加到绿圈中的位置在点击apply
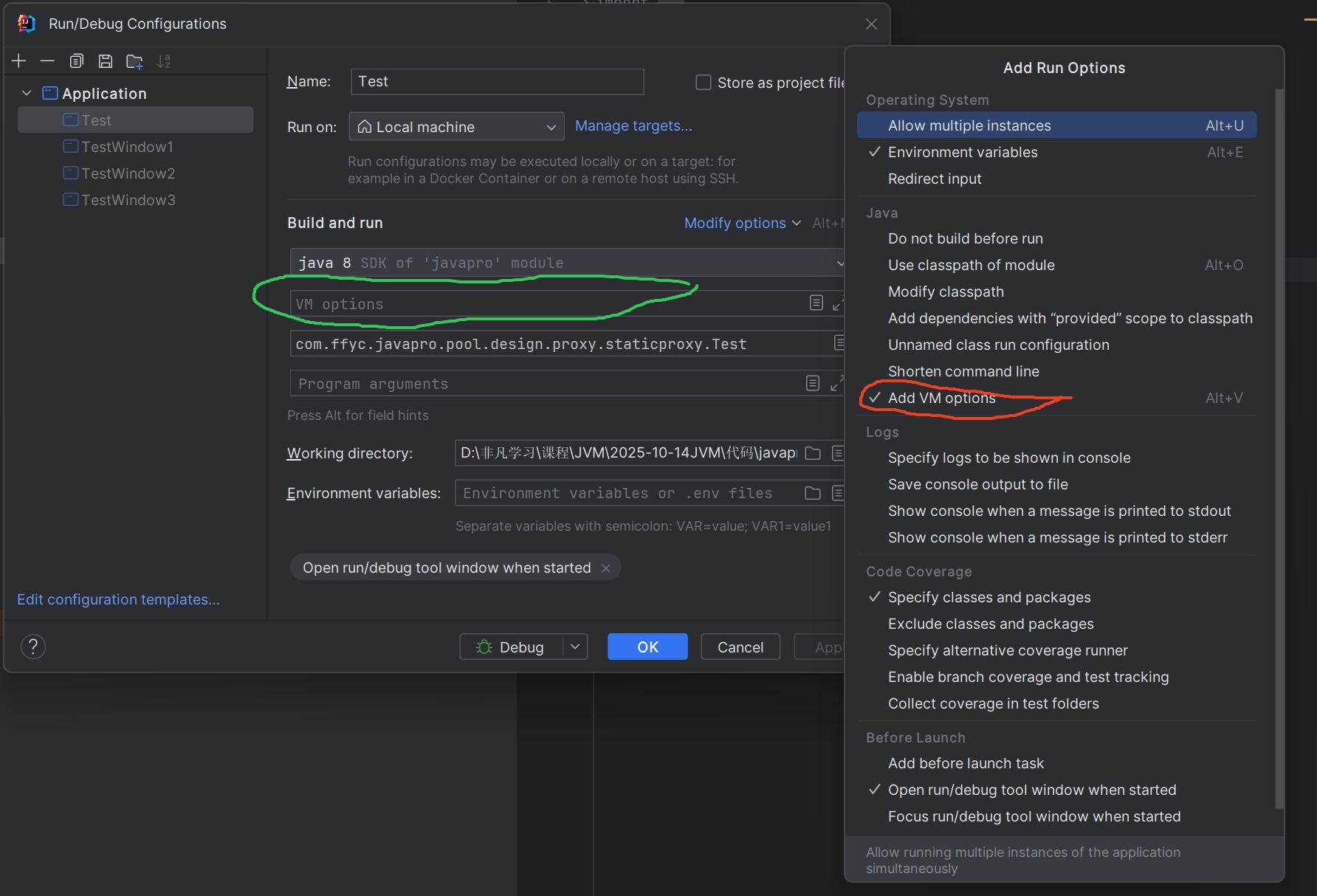
这属于临时修改
想要对每个项目都进行修改,需要在jdk中进行修改
5.方法区
作用:
方法去也称为元空间
主要用来存储类信息(方法,变量,静态变量,静态常量……)

大小设置
方法区大小是可以进行设置的
-XX:MetaspaceSize
方法区是会存在内存溢出问题的,当加载的类信息很多时,方法区空间不足,就会报错
方法区垃圾回收
方法区是存在垃圾回收的,方法区的垃圾回收的主要信息是类信息
但是类信息的回收条件很苛刻,一般我们认为类被加载后,类信息就不卸载了
类卸载的条件比较苛刻,需要同时满足以下3个条件:
1.该类的对象,以及该类的子类对象都已经被回收
2.加载该类的类加载器已经被回收
3.给类对应的Class对象没有任何地方被引用
四,本地方法接口
什么是本地方法
native关键字修饰的方法
不是用Java语言实现的
为什么要使用Native Method
Java语言是用应用层语言,Java语言没有权限直接操作计算机硬件设备(内存,硬盘),操作系统就为上层语言写好了一些操作硬件的接口,上层语言只需要调用这些系统接口即可,底层实现由操作系统处理
本地方法接口模块就是在虚拟机中赋值调用本地方法的入口
五,执行引擎
作用:
执行引擎是虚拟机中最核心之一的内容
负责加载字节码到虚拟中,将字节码解释/编译为机器码(字节码是虚拟机中指定的指令(汇编语言)),不是机器码
前端编译:通过javac命令,把.java文件编译成.class文件
后端运行:在运行时,由执行引擎把字节码编译为机器码
为什么执行引擎中设计为半解释,半编译模式将字节码翻译为机器码
高级语言------->机器码 一般由两种方式: 1.解释执行, 2.编译执行
解释执行: web前端 html css js , sql , python
解释执行特点: 一行一行由解释器解释执行, 缺点: 效率慢 . 不需要编译,可以由解释器直接解释执行编译执行: c c++ java ----> 整体编译 编译后执行效率高, 但是编译是花时间的.执行引擎可以对某些
执行比较频繁的热点代码进行追踪, 将热点代码编译后缓存起来,下次使用时省去了编译时间,可以直接拿来使用.
程序刚开始运行时, 先通过解释器解释执行,提高响应速度, 当热点代码编译后,使用编译执行,提高后续程序执行速度.
六,垃圾回收
垃圾回收概述
什么是垃圾对象
在程序运行时,如果一个对象没有被任何引用变量所指向,那么这个对象就是垃圾对象。
垃圾对象如果不及时清理,长期占用内存空间,会导致新创建的对象空间不足,最终发生内存溢出错误
public void test(){1 Hello h1 = new Hello()2 Hello h2 = h1; h1 = null;h2 = null;
}main(){test();} 解释:在test运行时如果没有h1 = nul; h2 = null;那么创建出来的对象的引用时间就会持续到test方法执行结束然后被垃圾回收,如果h1 = nul; h2 = null;语句存在,那么该对象在h2 = null语句结束后就不再被引用,触发垃圾回收原则,若只有h1 = null语句,那么与不存在h1 = nul; h2 = null;语句效果相同,因为生成的对象地址被h2锁引用
早期的垃圾回收
c语言 malloc() 申请内存空间
free() 释放内存空间
C++ 也是手动申请,手动释放
手动内存管理好处: 对内存管理更精确,用时申请,用完销毁
不足: 麻烦, 忘记释放内存,导致内存泄漏
现在的语言很多都支持自动内存管理(自动垃圾回收)
垃圾回收的重点区域
垃圾回收的重点区域是堆,方法区也存在垃圾回收
频繁回收新生代,较少回收老年代
内存溢出和内存泄漏
内存溢出:Out Of Memory,简称OOM,指的是内存空间不够了,后续创建的对象放不下了,此时程序会崩溃终止运行
内存泄露:一个对象已经不再被使用了,但是由于种种原因垃圾回收器去不能回收该对象了,悄悄占用着有效的内存空间,这种现象被称为内存泄漏
例如:IO,数据链接,socker通信等对象,都提供close()用于释放对象,但是我们如果不调用close(),垃圾回收期此时不能自作主张回收掉这些对象的,那么这些对象就悄悄的占用着内存空间
垃圾回收相关算法
标记阶段
主要就是对堆空间中的对象进行标记,标记处哪些对象是有用的,哪些对象已经是垃圾对象了。
标记阶段涉及到两种算法
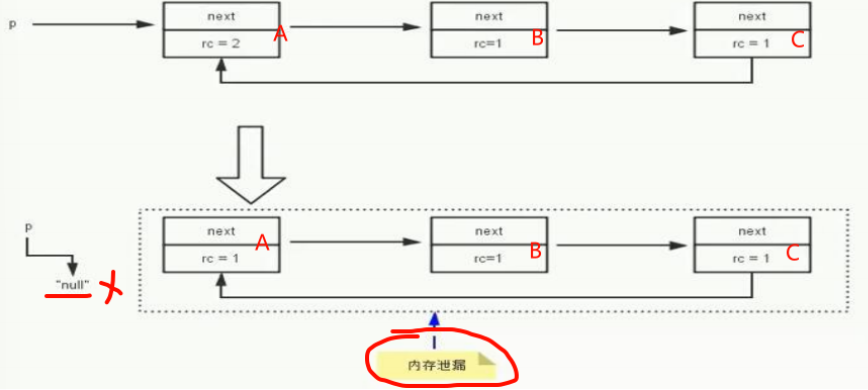
1.引用计数算法(目前没有被使用)
Hello h1 = new Hello(); 对象中有一个计数器 1 +1 2
Hello h2= h1;
h2 = null; -1-->1
h1 = null; -1-->0
引用计数算法虽然实现起来比较简单,
但是也存在一些问题:
1.计数器需要占用空间
2.可能会频繁的加减计数器,占用时间开销
3.存在一个致命的缺陷,不能解决循环引用问题,会造成内存泄漏
2.可达性分析算法(根搜索算法)
从一些活跃对象(GCRoots)开始进行查找,凡是与活跃对象相关联的对象,都是存活对象
一旦某些对象,与活跃对象没有任何链接,那么这些对象就可以判定为垃圾对象
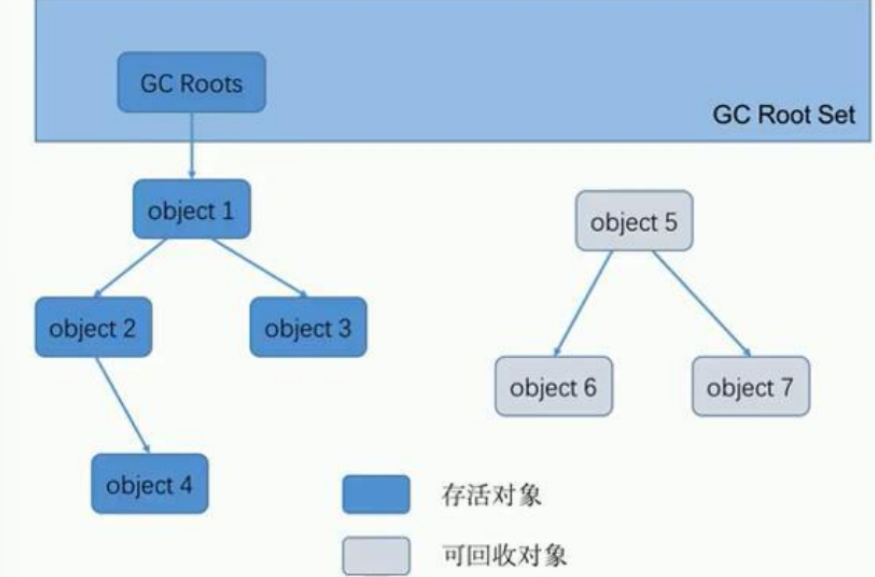
那些对象可以被算作是活跃对象(根对象 GCRoots)
1.虚拟机栈中引用的对象,入栈后等待运行
2.类中定义的成员变量(全局)
3.作为同步锁对象的
4.系统中的对象,如class对象,异常对象
回收阶段
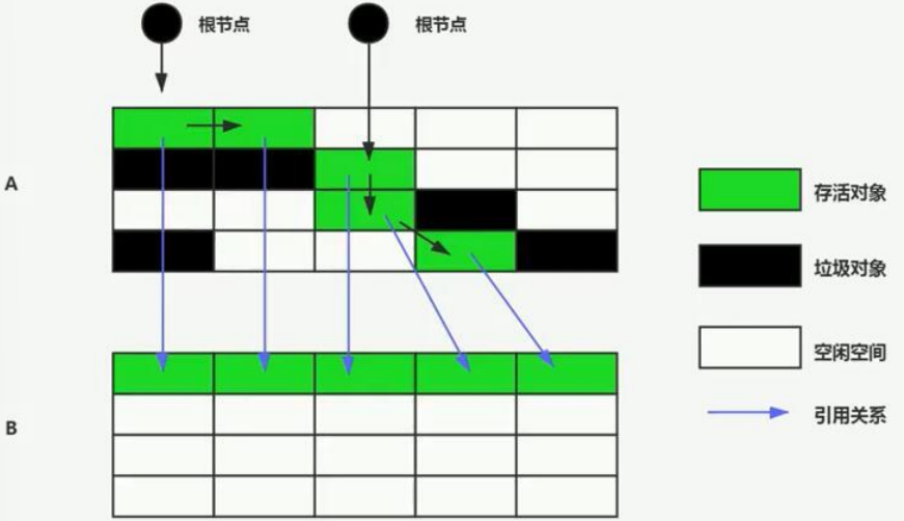
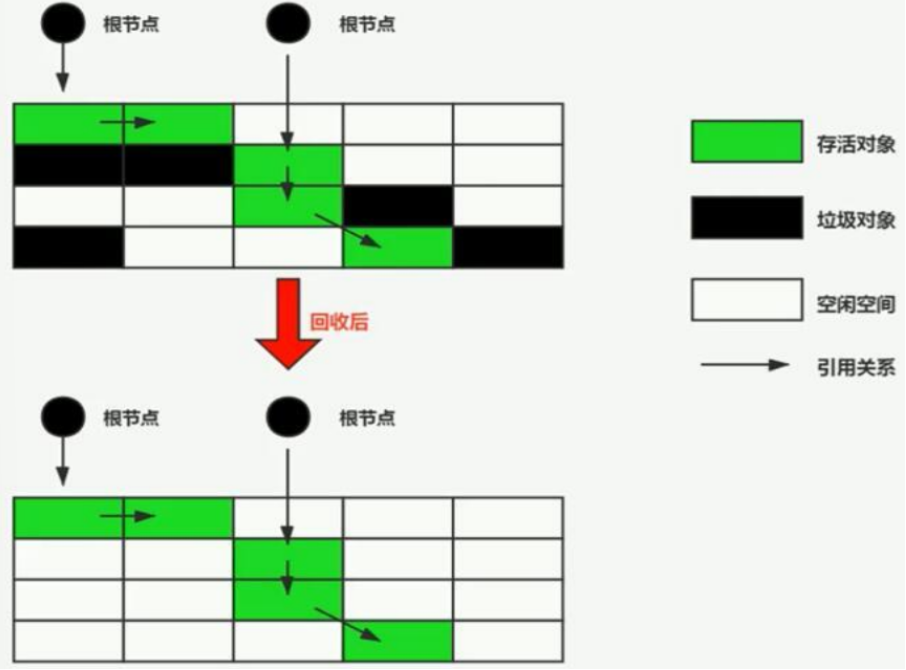
标记-复制算法
由多块内存,每次有一块时空闲的,回收时,把正在使用的内存块中存在对象都移动(复制)到空闲内存块中,清空当前正在使用的内存块,互换角色
复制算法,特别适合新生代的垃圾回收,因为新生代垃圾对象多,存活对象少
这种回收算法可以减少内存中的碎片
标记-清除算法
保持存活对象不动,清除垃圾对象即可,标记算法适合老年代的垃圾回收,因为老年代对象存活时间长,也有的对象比较,减少移动次数。会产生内存碎片
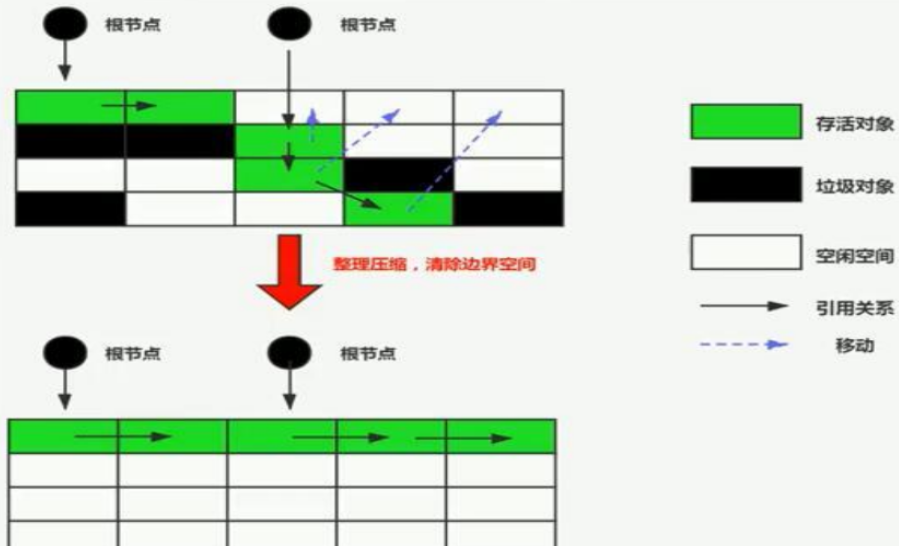
标记-压缩算法
在把垃圾对象清理后,把存活对象压缩到内存的一端,进行重新排放,减少内存碎片产生,但是要移动存活对象
垃圾回收器
概述

垃圾回收器分类
按照线程数量分:单线程垃圾回收器
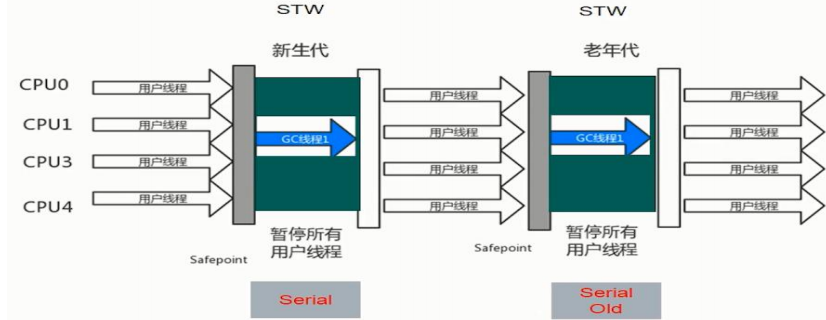 多线程垃圾回收器
多线程垃圾回收器
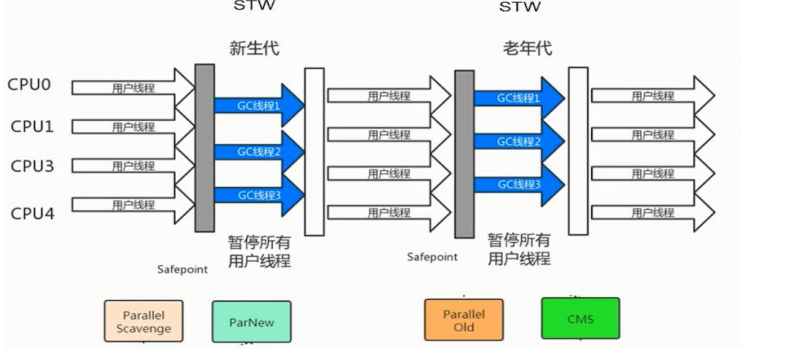
按照工作模式分:独占式垃圾回收器(垃圾回收线程执行时,其他用户线程需要暂停,不能执行)
并发式垃圾收集器(垃圾收集线程和用户线程可以做到同时执行)

按照工作的内存区间分:新生代垃圾回收器
老年代垃圾回收器
GC性能指标
吞吐量:运行代码的时间占总运行时间的比例(总运行时间:程序的运行时间+内存回收的时间)
用户线程暂停时间(用户线程暂停时间越短越好
jdk8中内置的垃圾回收器
Serial,Serial Old,ParNew,Paeallel Scavenge,Parallel Old,CMS,G1
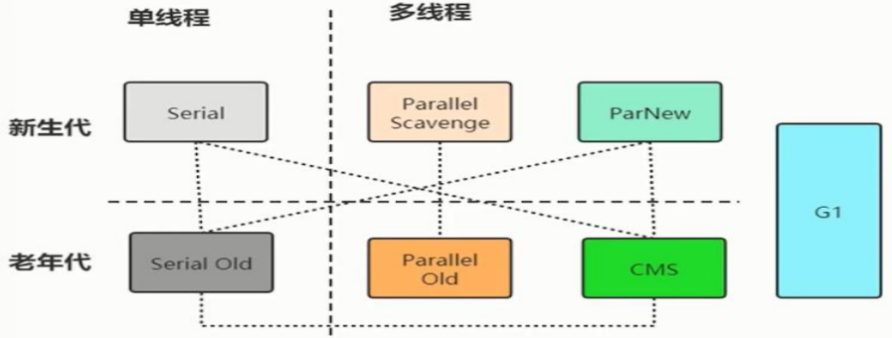
(虚线表示相连的两个垃圾回收器可以配合运行)
CMS
CMS(Concurrent Mark Sweep) 并发标记清除,cms垃圾收集器首次做到了垃圾收集线程和用户线程可以同时执行
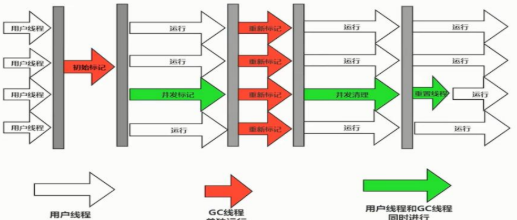
初始标记:用户线程会暂停,垃圾收集线程时独占的
并发标记:垃圾收集线程和用户线程一起执行
重新标记:用户线程会暂停,垃圾收集线程时独占的
并发清理:垃圾收集线程和用户线程一起执行
G1
Garbage First收集器
G1垃圾收集器,主要是面向服务器端使用场景
特点:
1.将堆中的每个分区(伊甸园区,幸存者区,老年区)再次拆分成若干个小的区域,每次回收时,优先回收垃圾最多的小区域,所以叫G1(垃圾优先)
2.可以做到对整个堆进行回收(不在区分老年区还是新生区)
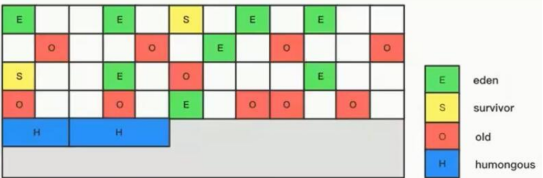
3.G1垃圾回收器,也可以做到用户线程和垃圾收集线程同时执行
如何设置选择垃圾回收器
打印默认的垃圾收集器:
-XX:+PrintCommandLineFlags -version
设置选择指定的垃圾收集器:
-XX:+PrintGCDetails -version