【论文精读】Lumiere:重塑视频生成的时空扩散模型
标题:Lumiere: A Space-Time Diffusion Model for Video Generation
作者:Hila Chefer, Yuval Alaluf, Yael Pritch, Shiran Ziv, Daniel Cohen-Or, Inbar Mosseri, Michal Irani
单位:Google Research, Tel Aviv University, Adobe Research
发表:2024 年计算机视觉顶会 CVPR(Conference on Computer Vision and Pattern Recognition)
论文链接:https://arxiv.org/abs/2403.19310
项目主页:https://lumiere-video.github.io/
代码链接:官方代码未公布;使用方法可以参考一下这里https://github.com/lucidrains/lumiere-pytorch
关键词:视频生成;时空扩散模型;时空 U-Net(STUNet);MultiDiffusion;条件生成
一、论文背景介绍
在聊技术细节前,我们先搞懂一个关键问题:视频生成的核心痛点是什么?答案很简单——时空连贯性。你肯定见过不少AI生成的视频:要么单帧质量很高但动作卡顿(比如人物走路突然瞬移),要么运动勉强连贯但画质模糊,更要命的是大多只能生成2-3秒的短片段。
传统模型(比如Imagen Video、AnimateDiff)为什么解决不了?因为它们都用"级联式架构":先生成间隔很远的关键帧,再用时间超分(TSR)模型补全中间帧。这种方式天生有三大缺陷:①关键帧间隔太大导致快速运动模糊(时域混叠);②补帧时只能看局部窗口,全局连贯没法保证;③训练和推理存在领域鸿沟,补帧模型练的是真实视频降采样,推理时却要补AI生成的关键帧,误差越积越大。
而Lumiere的横空出世,直接推翻了这套逻辑!它的核心创新就一句话:用时空U-Net(STUNet)一次性生成完整时长的视频,彻底抛弃级联补帧。这一改动带来了质的飞跃:能生成80帧16fps(也就是5秒)的全帧率视频,而且运动连贯性、画质细节都达到SOTA。更牛的是,基于这个核心架构,它还能轻松扩展到图像转视频、视频修复、风格迁移等多个场景,实用性拉满。
先放一张官方的样本展示图,感受下它的实力(图1):第一行是文本生成视频,第二行是图像转视频,第三行是风格迁移和视频修复,每一项的运动都自然到不像AI生成!

Lumiere的"一次性生成"思路不仅适用于视频,还能迁移到3D生成、动态图像等领域。
二、核心架构拆解:时空U-Net(STUNet)如何实现"一步生成"?
Lumiere能颠覆传统架构,全靠它的核心——时空U-Net(STUNet)。我们先回顾下传统U-Net的逻辑:在图像生成中,通过空间下采样压缩分辨率、提取全局特征,再通过空间上采样恢复分辨率,同时用跳跃连接保留细节。但视频比图像多了一个时间维度,传统U-Net只做空间采样,时间维度全程保持固定分辨率,计算量爆炸且无法捕捉长时依赖,所以只能用级联补帧。
STUNet的突破就在于:在空间采样的基础上,加入了时间维度的下采样和上采样,把视频的"空间-时间"特征一起压缩、一起处理,最终一次性生成完整视频。具体怎么实现的?我们分3个部分拆解:架构整体设计、核心模块、与传统架构的对比。
2.1 架构整体:从预训练文本图像模型"膨胀"而来
Lumiere没有从零训练,而是站在了巨人的肩膀上——基于预训练的文本到图像扩散模型(Imagen的基础模型)进行"时空膨胀"。这么做有两个好处:①复用文本图像模型的强大视觉生成能力和文本理解能力,不用再从头训练文本-视频对齐;②只训练新增的时空模块,大大降低训练成本。
具体膨胀逻辑是这样的(图4):在预训练图像U-Net的每个空间采样模块后,插入时间下采样/上采样模块;在网络的不同层级插入时空卷积和时间注意力模块,让模型学会捕捉时间维度的依赖关系。整个过程中,预训练的图像模型权重固定不动,只训练新增的时空模块和少量适配层。
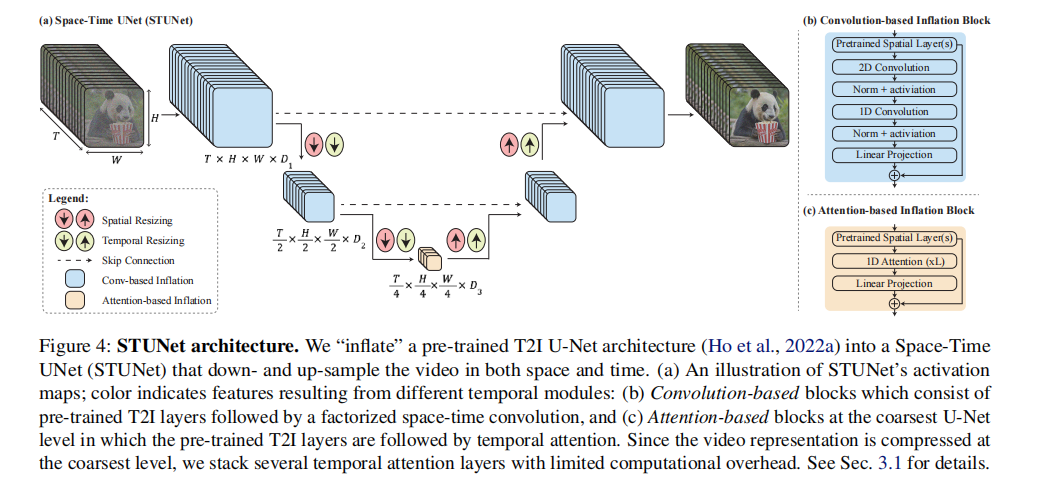
从图4a能清晰看到STUNet的激活图变化:颜色代表不同的时间模块,随着网络层级加深,空间和时间维度同时被压缩,模型在低分辨率的时空特征图上做主要计算,既节省显存又能捕捉全局依赖。到了上采样阶段,再同时恢复空间和时间分辨率,最终输出完整视频。
2.2 两大核心模块:时空卷积+时间注意力,兼顾效率与效果
STUNet的性能,全靠两个核心模块的配合:在网络大部分层级用因式分解时空卷积,在最粗粒度层级用时间注意力,既保证计算效率,又能捕捉长时依赖。
先看因式分解时空卷积(图4b):传统的3D卷积(时空一起卷积)计算量太大,而1D时间卷积又只能捕捉局部时间依赖。Lumiere用的因式分解卷积,把3D卷积拆成"空间卷积+时间卷积"的组合,既保留了时空交互的能力,又把计算量降了下来。而且它是在预训练的图像卷积层后插入的,能复用图像特征提取能力,新增的计算成本极低。
再看时间注意力(图4c):注意力机制能捕捉长时依赖,但计算量和序列长度的平方成正比——如果在高分辨率层级用,80帧的视频直接把显存撑爆。所以Lumiere只在最粗粒度的层级用时间注意力:此时经过多次时空下采样,时间维度已经被压缩到很小(比如从80帧压缩到10帧),计算量完全可控。而且在粗粒度特征图上,注意力能更精准地捕捉全局时间依赖(比如人物走路的周期性动作),这是传统卷积做不到的。
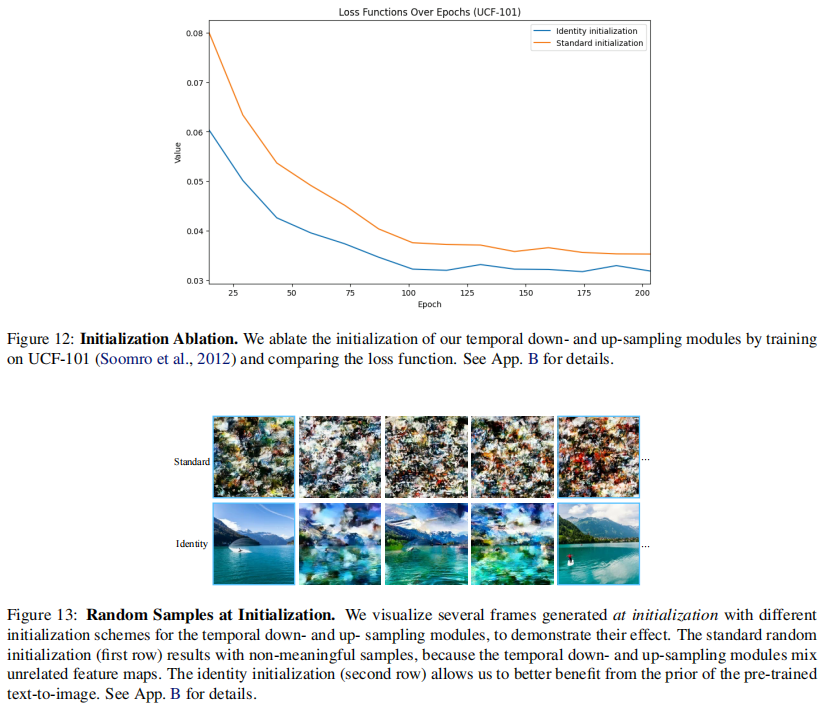
这里有个细节值得注意:STUNet的初始化很有讲究。因为加入了时间采样模块,没法像传统"膨胀"方法那样让初始化后的模型等价于原图像模型。作者通过实验发现,把时间下采样初始化为"最近邻下采样"、时间上采样初始化为"帧复制+1D卷积",能让模型一开始就复用原图像模型的能力,训练收敛速度提升30%以上(后续实验部分会详细说这个消融实验)。
2.3 与传统架构对比:一次性生成vs级联补帧,差距在哪?
为了更直观地理解Lumiere的优势,我们直接对比它和传统架构的 pipeline(图3):
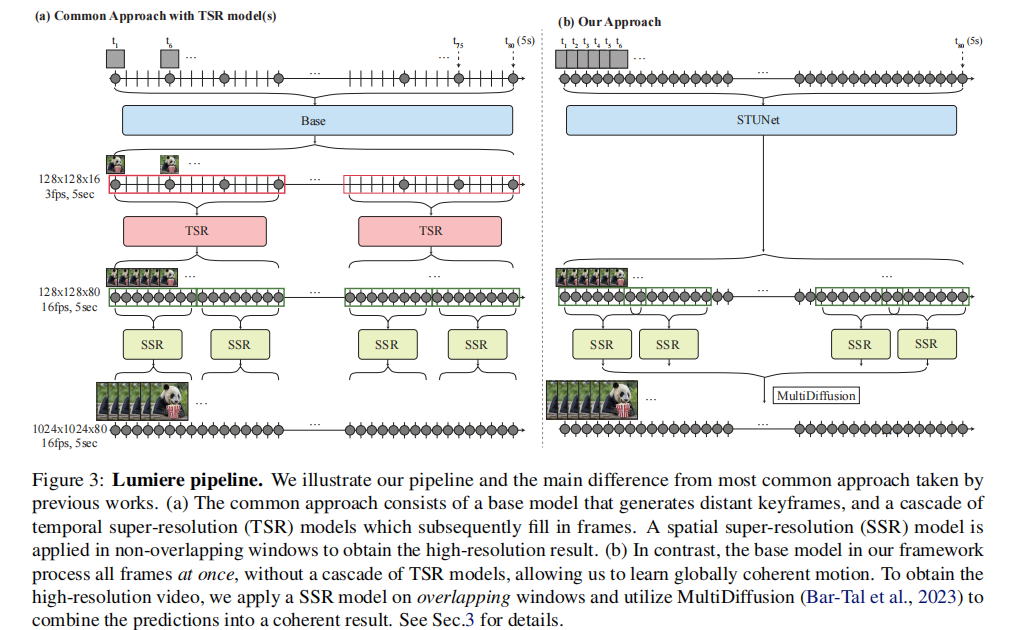
传统架构(图3a):①基础模型生成稀疏关键帧(比如每10帧生成1帧);②多个时间超分模型(TSR)分阶段补全中间帧,每次只处理局部窗口;③空间超分模型(SSR)再分窗口提升分辨率。整个过程像"搭积木",每个阶段都可能引入误差,而且窗口处理会导致全局连贯差。
Lumiere架构(图3b):①基础模型(STUNet)一次性生成128×128分辨率的完整80帧视频;②空间超分模型(SSR)用多扩散(MultiDiffusion)方法提升到1024×1024。这里的关键是,空间超分虽然也分窗口,但用MultiDiffusion做全局融合,避免了传统窗口处理的边界 artifacts。
一句话总结:传统架构是"分步补全",Lumiere是"一步生成+全局超分",从根源上解决了连贯性格局。
三、关键技术突破:除了STUNet,还有哪些关键技术
Lumiere的成功,除了核心的STUNet架构,还有两个关键技术加持:MultiDiffusion空间超分和灵活的条件生成机制。这两个技术让它不仅能"生成得好",还能"用得爽"。
3.1 MultiDiffusion空间超分:解决高分辨率生成的"窗口边界问题"
我们知道,视频的空间超分比图像难多了——要处理80帧的序列,显存根本扛不住全序列超分。传统做法是把视频切成非重叠的时间片段,逐个片段超分再拼接,但这样会导致片段之间出现明显的边界 artifacts(比如前一帧人物肤色偏白,后一帧突然偏黄)。
Lumiere借鉴了图像生成中的MultiDiffusion思想,并把它扩展到时间维度。具体做法是:①把80帧的视频切成重叠的时间片段(比如每个片段20帧,重叠2帧);②对每个片段单独做空间超分,得到多个超分结果;③在每个扩散步骤中,通过优化问题把多个片段的超分结果融合——目标是找到一个全局一致的结果,让它和每个片段的超分结果误差最小。
这个方法的妙处在于,重叠片段和全局融合能彻底消除边界 artifacts。论文里做了消融实验(图14):没有MultiDiffusion时,片段之间的帧差异(Frame Diff)会出现尖峰(说明边界不一致);用了之后,差异曲线平滑,边界完全消失。

3.2 灵活的条件生成机制:一个模型搞定N个场景
好的生成模型不仅要能做基础任务,还要能灵活适配不同场景。Lumiere通过一套统一的条件生成机制,轻松扩展到图像转视频、视频修复、风格迁移、动态图像(Cinemagraphs)等多个任务。核心逻辑是:在模型输入中加入"条件信号+掩码",通过微调少量参数实现任务适配。
具体来说,模型的输入从原来的"噪声视频+文本提示",扩展为"噪声视频+文本提示+条件信号C+掩码M",通道数从3扩展到7(噪声视频3通道+条件信号3通道+掩码1通道)。然后只微调第一个卷积层(适配7通道输入)和新增的时空模块,预训练的图像特征提取部分不动。不同任务的区别,只在于条件信号C和掩码M的设计:
-
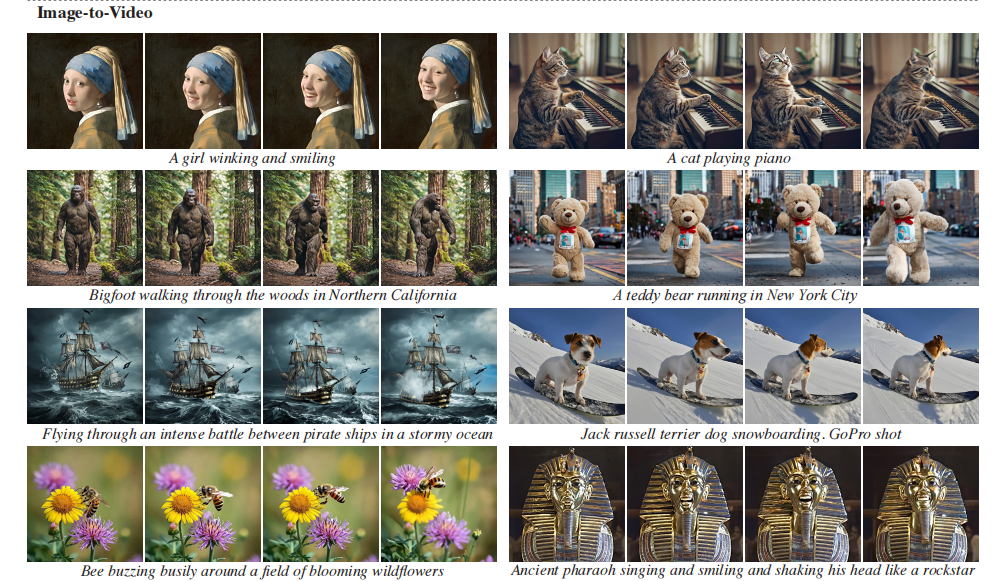
图像转视频:条件信号C是"输入图像+后续79帧空白帧",掩码M是"第一帧为1(不掩码)+后续79帧为0(掩码)"。模型会学习"保留第一帧的内容,生成后续连贯的运动"。从图5的第二行能看到,输入一张静态的宇航员图片,模型能生成他走路的连贯视频,动作自然且和原图一致。
-
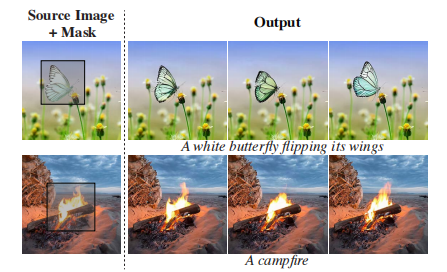
视频修复:条件信号C是"原始视频",掩码M是"要修复的区域为0,其他区域为1"。模型会学习"复制未掩码区域的内容,在掩码区域生成符合文本提示的内容"。图7展示了修复效果:左边是原始视频和掩码,右边是修复后的结果,掩码区域的内容和原视频融合得天衣无缝。

-
风格迁移:传统风格迁移容易出现"风格套上了,但运动卡顿"的问题。Lumiere的做法是:①用风格图像微调文本图像模型,得到风格化的权重W_style;②把W_style和原模型权重W_orig做线性插值(W_interpolate = α·W_style + (1-α)·W_orig);③用插值后的权重生成视频。α的取值很关键,0.5-1之间能平衡风格和运动连贯性。图6展示了不同风格的迁移效果,线条画风格会生成"铅笔绘制"的动态效果,水彩风格则保持细腻的运动纹理。

-
动态图像(Cinemagraphs):这是个很有意思的场景——让静态图像的局部动起来(比如让湖面波动,其他部分不动)。条件信号C是"静态图像复制80帧",掩码M是"第一帧全为1+后续帧'非运动区域为1,运动区域为0'"。模型会学习"第一帧全保留,后续帧只让掩码区域动起来",图8的例子中,只让花朵动,背景完全静止,效果堪比专业动态图像工具。
四、实验评估:用数据证明SOTA实力
论文从定量、定性、用户研究三个维度做了全面评估,结果都证明了模型的SOTA地位。
4.1 实验设置
先看训练数据和配置:用3000万条带文本标注的视频训练,每条视频80帧16fps(5秒);基础模型输出128×128,空间超分后输出1024×1024。评估用了两个数据集:①109个文本提示(包含91个前人常用提示+18个新增的复杂场景提示);②UCF101数据集做零样本评估。
对比基线模型包括:开源模型(Imagen Video、AnimateDiff、SVD、ZeroScope等)和商业模型(Gen-2、Pika),覆盖了当前主流的视频生成方案,对比非常全面。
4.2 定量评估:FVD和IS双指标 competitive
定量评估用了视频生成的两个核心指标:FVD(弗雷歇视频距离,越低越好,衡量生成视频和真实视频的分布差异)和IS( inception分数,越高越好,衡量生成内容的多样性和质量)。从表1能看到:
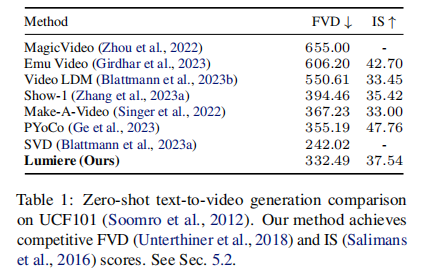
Lumiere的FVD是332.49,虽然比SVD的242.02高,但要知道SVD只能做图像转视频,不能做文本生成;而在能做文本生成的模型中,Lumiere的FVD仅次于SVD,远超Make-A-Video(367.23)、PYoCo(355.19)等模型。IS分数37.54,也处于上游水平,说明它生成的视频不仅连贯,多样性和画质也很能打。
不过论文也坦诚,定量指标有局限性——FVD和IS容易受低层次细节影响,而且UCF101是真实视频数据集,和模型训练的"文本-视频"数据分布有差异,不能完全反映人类感知。所以更重要的是定性评估和用户研究。
4.3 定性与用户研究:人类评分碾压所有基线
先看定性对比(图11):Gen-2和Pika的单帧质量高,但运动极少(几乎是静态图循环);Imagen Video有运动,但画质模糊且有 artifacts;AnimateDiff和ZeroScope运动明显,但时长短(分别只有2秒和3.6秒)且细节粗糙。而Lumiere的5秒视频,既有丰富的运动(比如宇航员走路、汽车行驶),又有细腻的画质,连贯性更是碾压。

用户研究更有说服力:用2AFC协议(强迫选择),让参与者对比Lumiere和基线模型的视频,从"视觉质量和运动连贯性"、"文本匹配度"两个维度打分。每个基线都收集了约400个评分,结果如图10所示:Lumiere在所有对比中都获胜,尤其是和开源模型相比,优势非常明显;即使和商业模型Gen-2、Pika比,也有显著优势。

这里有个细节:对比AnimateDiff和ZeroScope时,Lumiere会把自己的5秒视频裁剪到和它们一致的时长,保证公平性。即便如此,参与者还是更偏好Lumiere,说明它的优势不是时长带来的,而是运动质量和画质的硬实力。
4.4 消融实验:关键设计的必要性验证
论文还做了关键的消融实验,验证了STUNet核心设计的必要性:
-
时空采样的必要性:如果去掉时间下采样/上采样,只保留空间采样,模型根本无法生成5秒连贯视频,运动出现明显卡顿。
-
初始化策略的重要性:用传统的He初始化(随机初始化)比用"最近邻采样+恒等映射"初始化,训练损失更高(图12),而且初始生成的视频完全无意义(图13第一行);而好的初始化能让模型一开始就复用图像模型的能力,生成的视频有明显的视觉结构(图13第二行)。
五、局限性与未来方向:理性看待SOTA,找到下一个创新点
虽然Lumiere很牛,但它也有局限性,这恰恰是我们做研究或项目的创新方向:
-
无法生成多镜头视频:目前只能生成单个镜头的5秒视频,不能做镜头切换或场景过渡,这是所有单次生成模型的通病,也是未来的重要方向。
-
依赖像素空间的预训练模型:Lumiere基于像素空间的Imagen模型,需要空间超分才能达到高分辨率。如果能基于 latent 扩散模型(比如Stable Diffusion)做时空膨胀,能进一步降低显存占用,提升生成速度。
-
运动复杂度有限:虽然比之前的模型好,但对于非常复杂的运动(比如多人舞蹈、快速动作切换),还是会出现偶尔的卡顿或不合理。
针对这些局限性,论文提出了未来方向:①研究多镜头生成的叙事逻辑;②结合 latent 扩散提升效率;③引入更精细的运动建模(比如结合动作捕捉数据)。
六、总结:Lumiere给我们的3个核心启示
读到这里,相信你对Lumiere已经有了全面的理解。最后总结一下,它给我们的启示远不止一个SOTA模型那么简单:
-
架构创新比参数堆砌更重要:传统模型靠级联多个子模型提升性能,而Lumiere靠"一次性生成"的架构创新,直接解决了核心痛点。做AIGC研究,与其盲目加大模型参数量,不如先思考现有架构的根本缺陷。
-
善用预训练模型的"迁移能力":Lumiere基于文本图像模型做时空膨胀,既降低了训练成本,又保证了文本理解和画质基础。这提醒我们,做跨模态生成时,要充分复用现有SOTA模型的能力,而不是从零开始。
-
实用性是模型落地的关键:Lumiere不仅生成质量高,还能轻松扩展到多个场景,这让它有很强的落地潜力。做技术不能只追求论文指标,还要考虑实际应用中的灵活性和扩展性。
Lumiere的出现,让我们看到了视频生成"告别级联、一步到位"的可能,也为后续研究指明了方向。相信在它的基础上,很快会有更强大的视频生成模型出现。
你对Lumiere有什么疑问?比如时空U-Net的具体实现细节、MultiDiffusion的数学原理等,欢迎在评论区留言讨论~