7.无监督学习
一.聚类:
1. 概念:
- 聚类算法会查看多个数据点,并自动找到相关/相似的数据点;
【例】给定一个包含特征x1、x2的数据集,在有监督学习中,我们有一个包含输入特征x与标签y的训练集,绘制如图所示数据集并拟合(比如使用逻辑回归算法/神经网络来学习决策边界 );
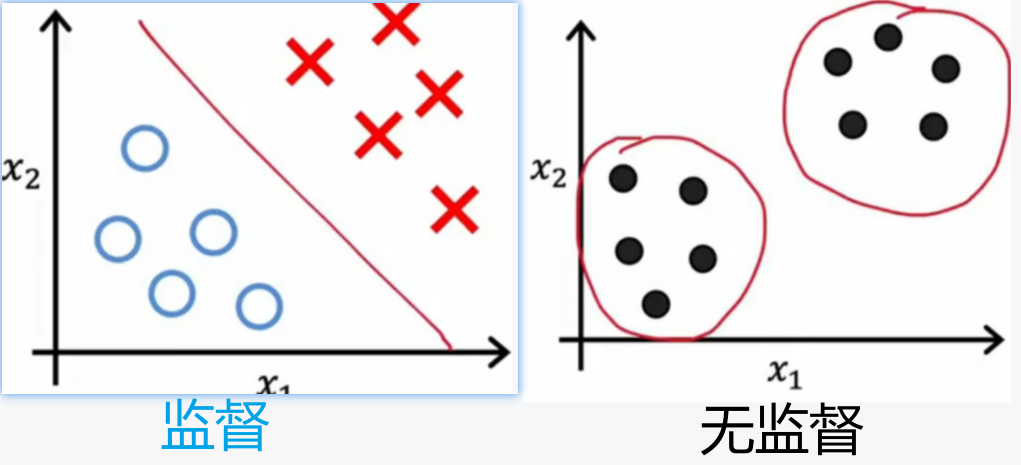
无监督学习中,你只能得到数据集只有x(没有标签y),我们要求算法发现数据中的结构;聚类算法会在数据中寻找一种特定的结构类型(换句话说会查看数据集并尝试可否将其分组为彼此相似的组 );
2.K-means:
- 又称K均值聚类算法;
- k-means会反复做:将点分配到簇的质心;移动簇的质心分配到所有点的平均位置(质心即中心);
2.1.工作原理:
如图所示,绘制一个包含30个未标记训练样本数据集,在该数据集上运行K-means算法,假设希望分类从两个簇。K-means首先会随机猜测两个中心的位置,希望找到簇;
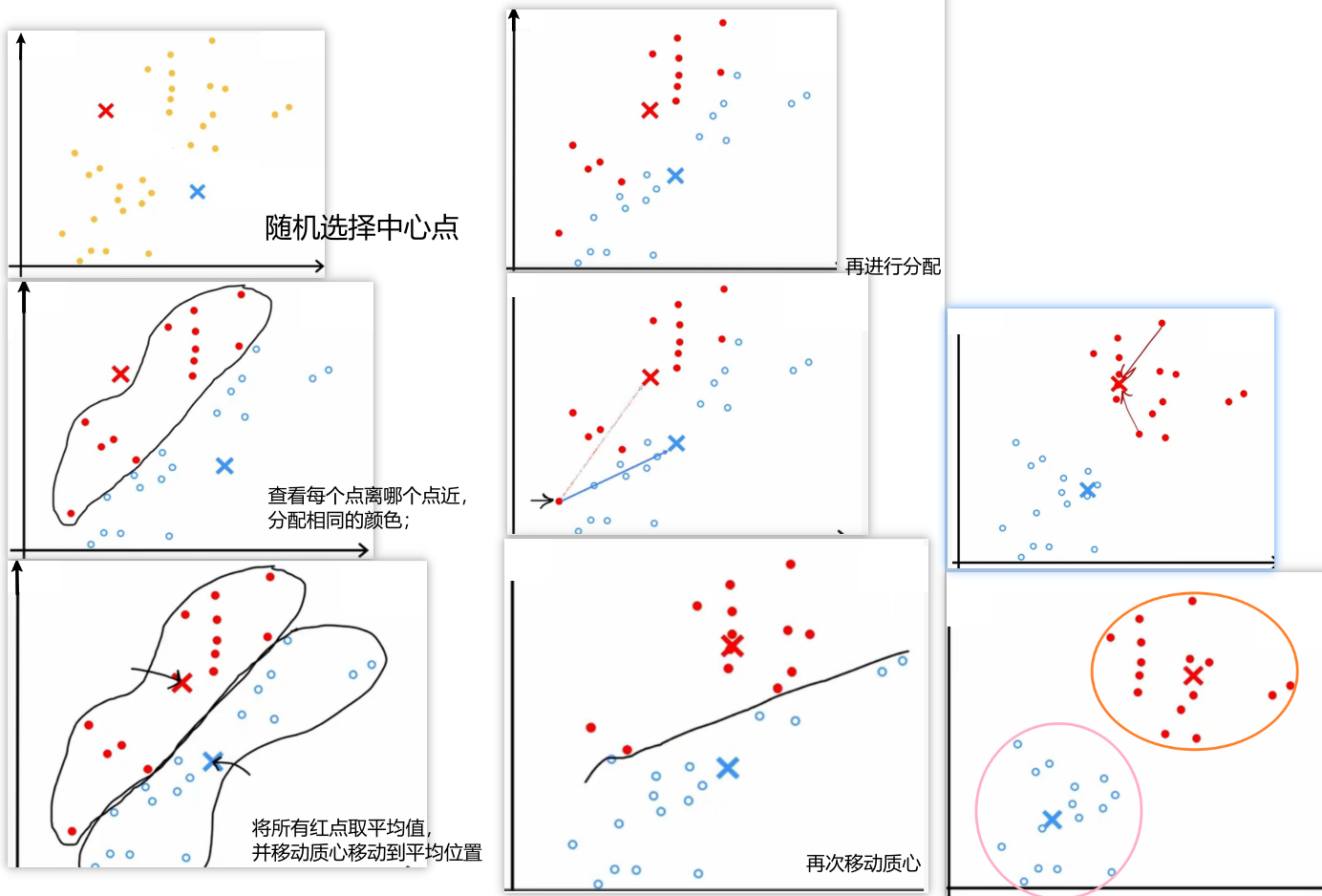
如图所示,