Redis_6_String
Redis中的string
Redis中的value字符串,直接就是按照二进制的方式存储的,它不会做任何编码转换,存的是啥,取出来的就还是啥,因此,redis遇到乱码问题的概率会很小。而在讲MySQL的时候,我们知道MySQL的默认字符集,是拉丁文,插入中文就会失败。
由于redis的字符串是按照二进制方式存储的,因此它不仅仅可以存储文本数据~~整数、普通的文本字符串、JSON、xml、二进制数据(图片、视频、音频……)
但是这里的视频音频体积可能比较大,Redis对于String类型,限制大小最大是512M,Redis单线程模型,希望进行操作都能比较快速~~因此音频、视频一般不存储在redis中。
常见命令
SET
SET key value [expiration EX seconds|PX milliseconds] [NX|XX]时间复杂度:O(1)
redis文档给出的语法格式说明:[ ]相当于一个独立的单元,表示可选项(可有可无的),其中 | 表示“或者”的意思,多个只能出现一个。
[ ]和[ ]之间,是可以同时存在的


那后面的nx和xx又是什么呢?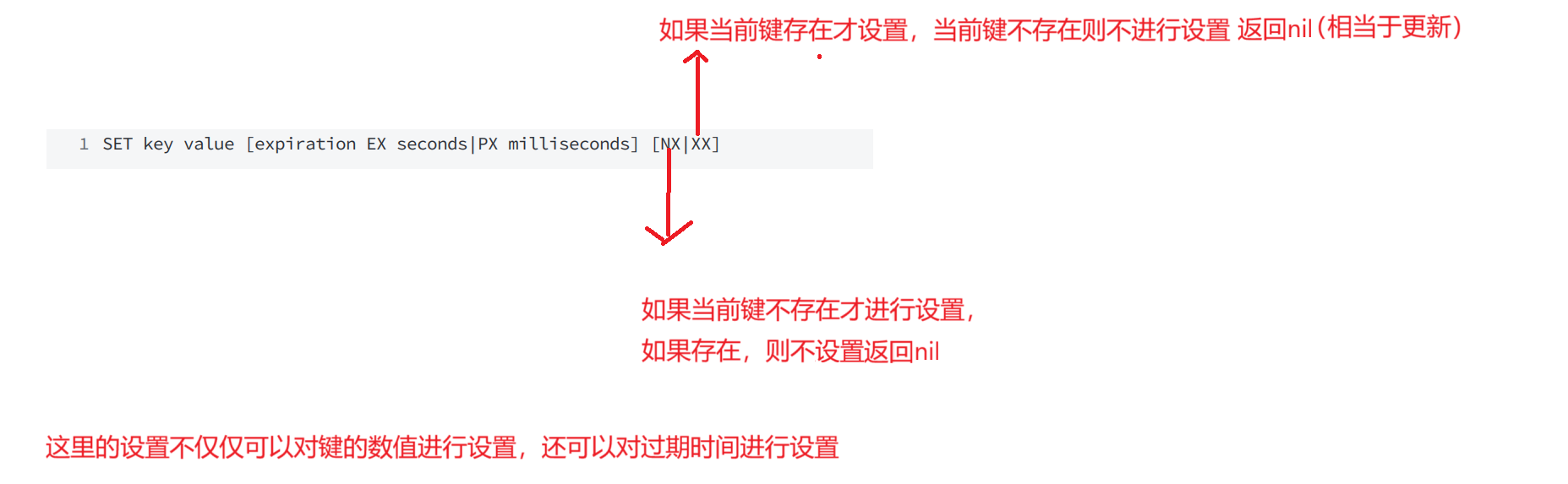
nx:如果当前键不存在才进行设置,如果存在,则不设置返回nil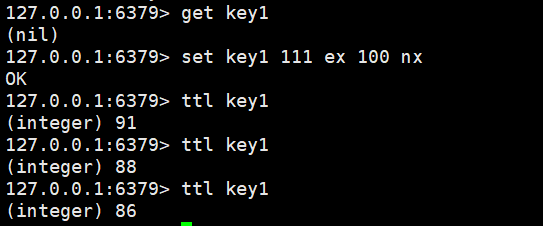
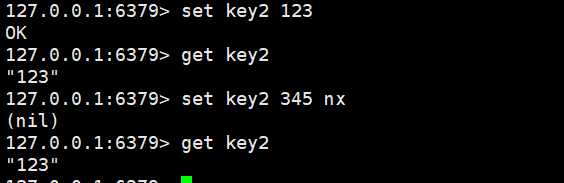
xx:如果当前键存在才设置,当前键不存在则不进行设置,返回nil(相当于更新)


上面的指令后面均可以通过:SETNX、SETEX、SETPX进行替代。
补充:
删库(失去年终奖)小技巧:flushall ==》 可以把redis上的所有键值对都带走~~
以后在公司中,尤其是生产环境下的数据库,可千万千万不敢这么干!!!
现在学习阶段,为了更好测试,敲一敲还好~~
GET
GET key时间复杂度:O(1)
返回值:当前key的value
注意:当前的get只能支持获取string类型的value,如果value是其他类型,此时GET获取就会出错!!
MSET/MGET
一次性设置多个key的值
MSET key value [key value ...]一次性获取多个key的值
MGET key [key ...]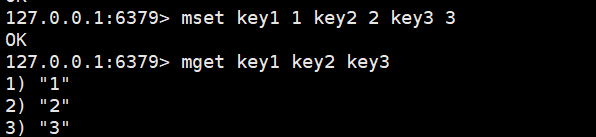
这两个命令是非常有用的,它能够减少网络通信的次数,从而达到提高增改查的效率。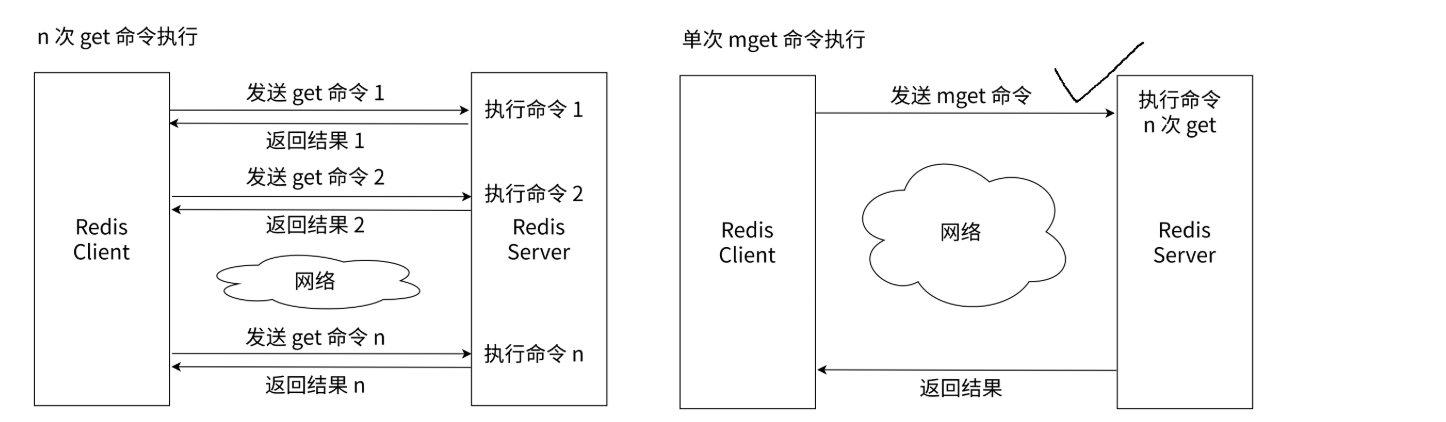
1000次get和1次mget查询1000个数据时间对比:

这两个命令的时间复杂度均为O(k),k为当前命令中要设置/查询的key的数量。
那这两个命令这么方便,我能不能一次性设置/获取10w个键值对呢?不能,这么干就会产生像keys * 那样的效果,把redis给阻塞住了!!!
SETNX/SETEX/PSETEX
这三个命令是针对我们刚才set的一些常见用法,进行了缩写。之所以这样搞,是为了让操作更符合人的直觉,要背的东西也就更少。
setnx key valuesetex key timeout valuepsetex key milltimeout value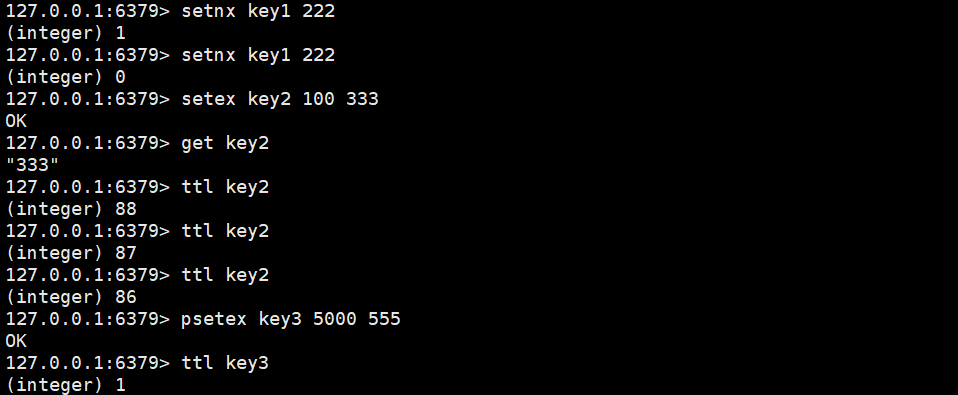
时间复杂度:O(1)
incr
将key对应的value的数字加1。如果key不存在,则视为key对应的value是0。如果key对应的value不是一个整型或者范围超过了64位有符号整型(相当于Java中的Long),则报错。
incr key时间复杂度:O(1)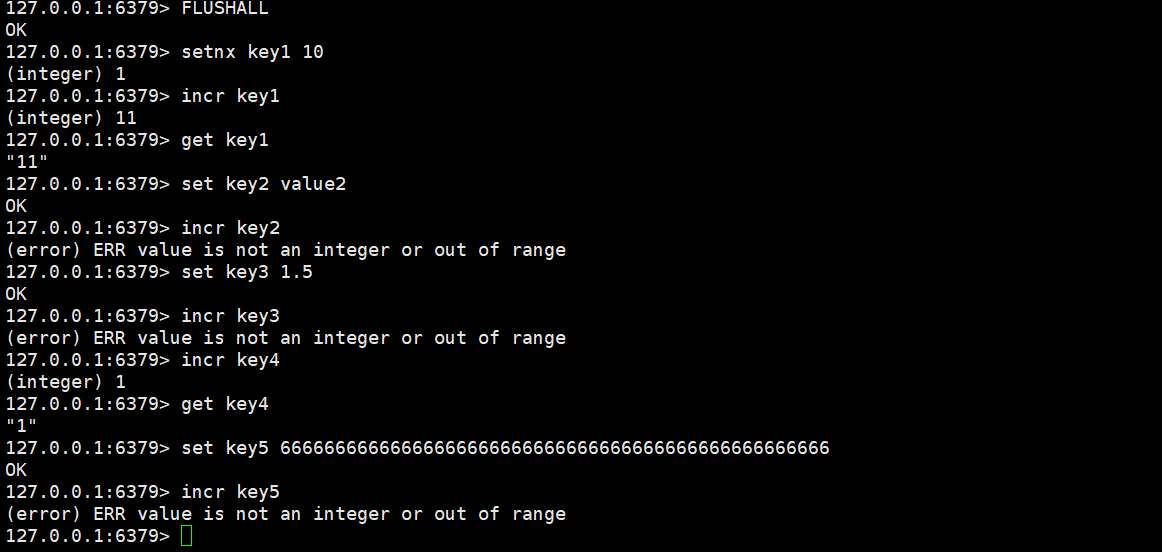
incrby
将key对应的value的数字加n(n的值可以自己设置)。如果key不存在,则视为key对应的value是0。如果key对应的value不是一个整型或者范围超过了64位有符号整型(相当于Java中的Long),则报错。
incr key increment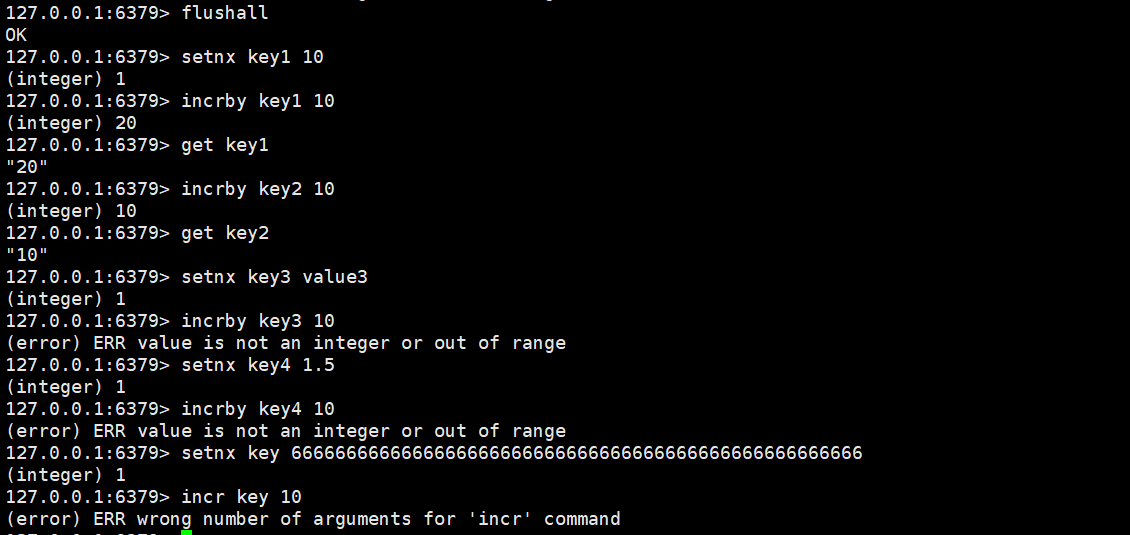
decr
将key对应的value的数字减1。如果key不存在,则视为key对应的value是0。如果key对应的value不是一个整型或者范围超过了64位有符号整型(相当于Java中的Long),则报错。
decr key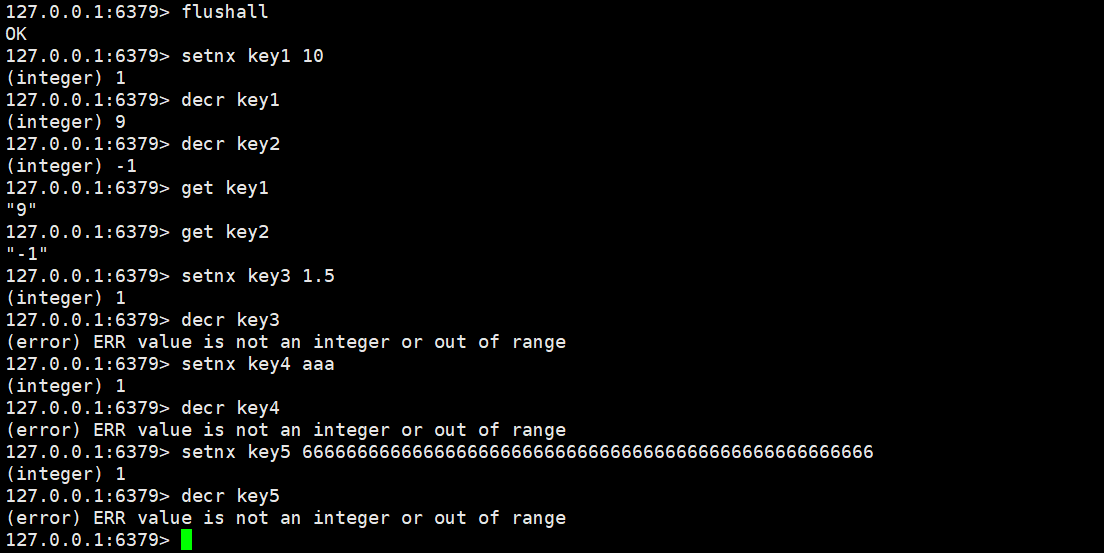
decrby
将key对应的value的数字减去n(n的值可以自己设置)。如果key不存在,则视为key对应的value是0。如果key对应的value不是一个整型或者范围超过了64位有符号整型(相当于Java中的Long),则报错。
decrby key decrement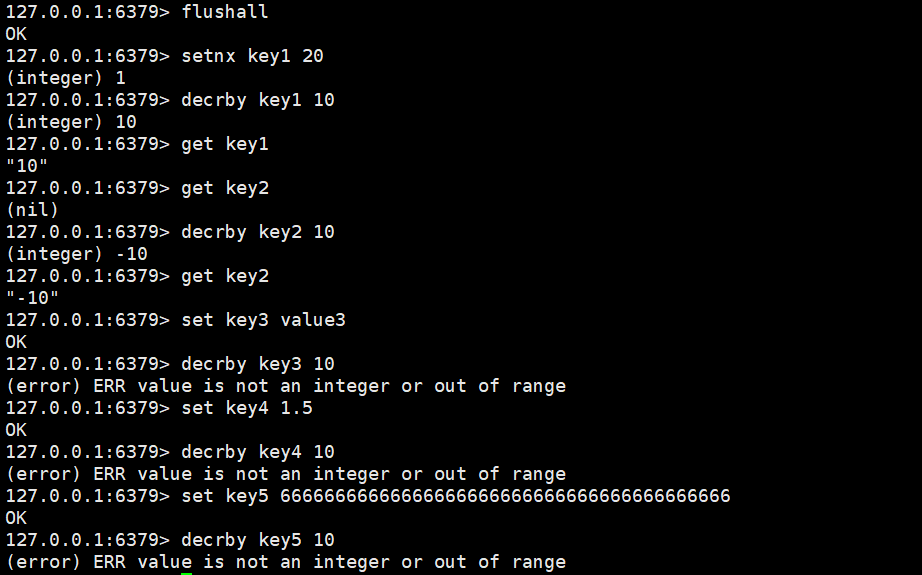
increbyfloat
incrbyfloat key decrement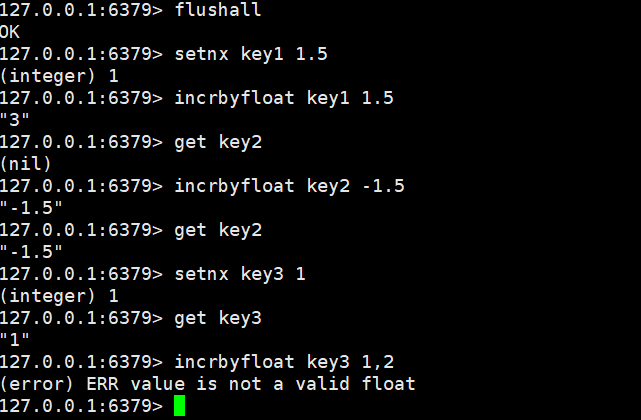
注意:上述针对value进行加减操作的时间复杂度都是O(1),由于redis处理命令的时候,是单线程模型,多个客户端针对同一个key进行incr操作,不会引起“线程安全”问题。
其他命令
我们知道:在java中,字符串支持一些常用的操作,拼接、获取、修改字符串的部分内容,获取字符串长度等。
这些操作,redis中同样支持。
append
如果key已经存在并且是一个string,命令会将value追加到原有string的后面。如果可以不存在,则效果等同于set。
时间复杂度:O(k),k为追加字符串的长度,追加字符串一般较短,可以视为O(1).
返回值:追加完成之后的string的长度
append key value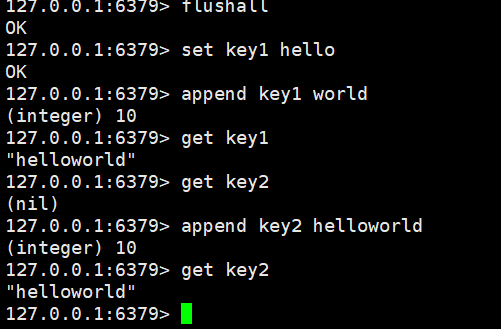
此处append的返回值,长度的单位是字节!!redis的字符串,不会对字符编码做任何处理(redis不认识字符,只认识字节)!!
那么假如我们追加的文字是中文会怎么样呢?
这里显示,咱们输入的“你好”是6个字节的,这是为什么呢?
这是因为我们当前使用的xshell终端,默认的字符编码是utf8的,在终端中输入的汉字也是按照utf8编码的~~一个汉字在utf8字符集中,通常是三个字节的。
那下面我们get到的这串东西又是啥呢?
使用utf8编码转换器:十六进制转字符串,文本转16进制-ME2在线工具
输入你好之后,可以看到“你好”的16进制utf8编码就是上面那串东西,至于多出来的“\x”,“\”表示分隔符,“x”表示16进制。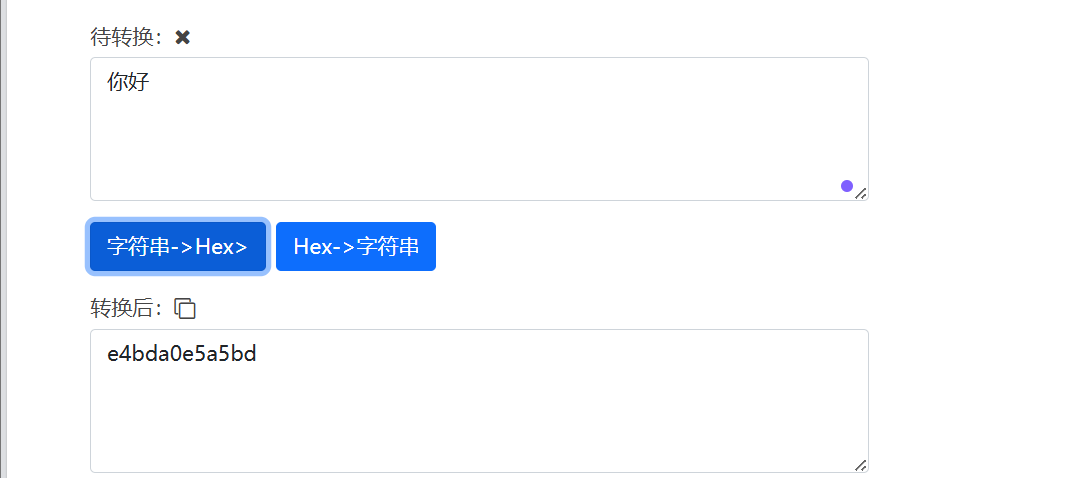
那问题来了咱们如果要显示中文应该如何操作呢?
我们可以在启动redis客户端,加上一个--raw这样的选项,就可以使redis客户端能够自动地把二进制数据尝试翻译。
先按crtl+D退出redis客户端

这里注意:在按crtl+D的时候不要按到旁边的crtl+S,crtl+S在xshell中的作用使“冻结当前画面”,一般是用来查看日志的。万一按到了,就使用crtl+Q解除冻结
可以看到在添加上--raw选项之后就可以正常显示中文了。
getrange
这个命令相当于Java中的substring方法,不同的是它的下标可以使用负数表示,且这里的开始下标和结束下标均是闭区间。
返回key对应的string的子串,由start和end确定(左闭右闭)。可以使用负数表示倒数,-1表示倒数第一个字符,-2表示倒数第二个,其他与此类似。超过范围的偏移量会根据string的长度调整成正确的值。
getrange key start end时间复杂度:O(k),k为[start,end]区间的长度。由于string通常比较短,可以视为是O(1)
返回值:string类型的子串

那如果对刚才的中文进行切割会怎么样呢?
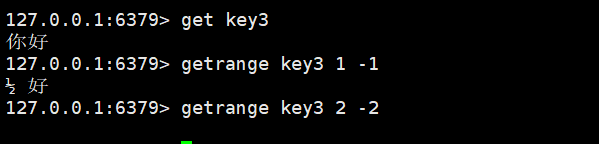
如果字符串中保存的是汉字,此时进行子串切分,很可能切出来的就不是完整的汉字了~~
但是同样的切分,在Java中就没事,因为Java中的字符串是以字符为单位的,相当于帮我们把汉字的编码转换都处理好了。
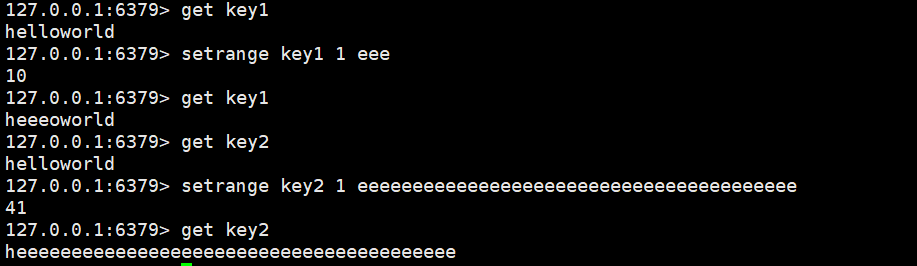
setrange
覆盖字符串的一部分,从指定的偏移开始。
setrange key offset value时间复杂度:O(k),k为value的长度。由于一般给的value比较短,通常为O(1).
返回值:替换后的string的长度。
如果当前是一个中文字符串,进行setrange会怎么样呢?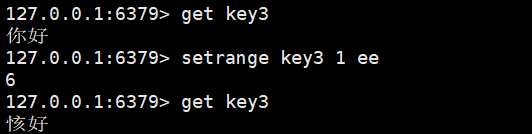
可以看到当前的中文字符串被搞出问题了~~
那如果setrange一个不存在的key,并且不从0下标开始设置又会怎么样呢?
可以看到当前仍然是4字节,但是显示出的内容只有3个字节的内容,这是因为前面凭空生成了一个字节,但这个字节并没有显示出来,这个字节里的内容是0x00,aaa被追加到了0x00的后面了。
结论:setrange针对不存在的key也是可以操作的,不过会把offset之前的内容填充成0x00。
strlen
获取key对应的string的长度。当key存放的类型不是string时,报错。
strlen key时间复杂度:O(1)
返回值:string的长度(单位是字节)。或者当key不存在时,返回0。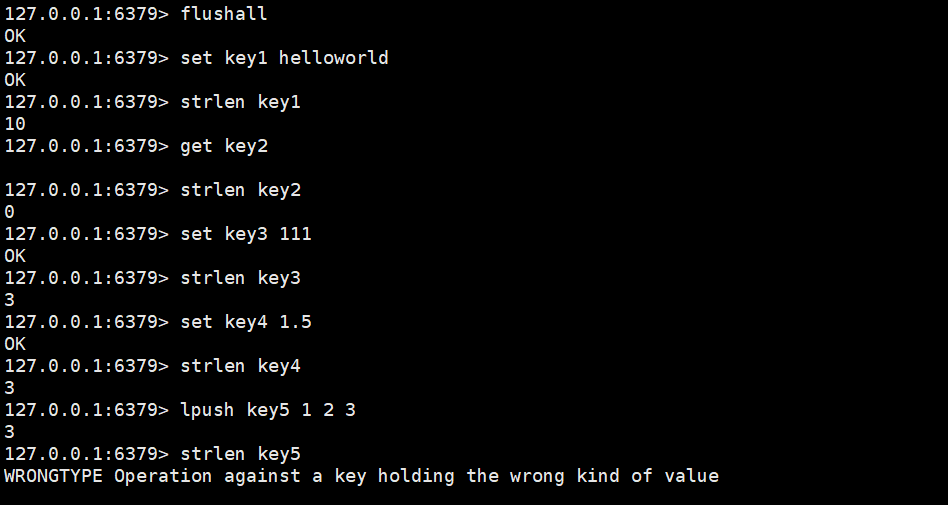
刚才我们讲到,Java中的字符串是以字符为单位的,Java中的一个char == 2个字节~~
Java中的char基于unicode这样的编码方式,就能够表示中文等符号~
那我们刚才说半天,一个汉字通常是3个字节的呀~~(编码方式是utf8),Java里头咋一个2字节的char就能表示汉字呢??
Java中的char是用的unicode,一个汉字使用两个字节,String则是使用utf8,一个汉字就是3个字节了。Java的标准库内部,在进行上述操作过程中,程序员一般是感知不到编码方式的变换的~~
总结
string的编码方式
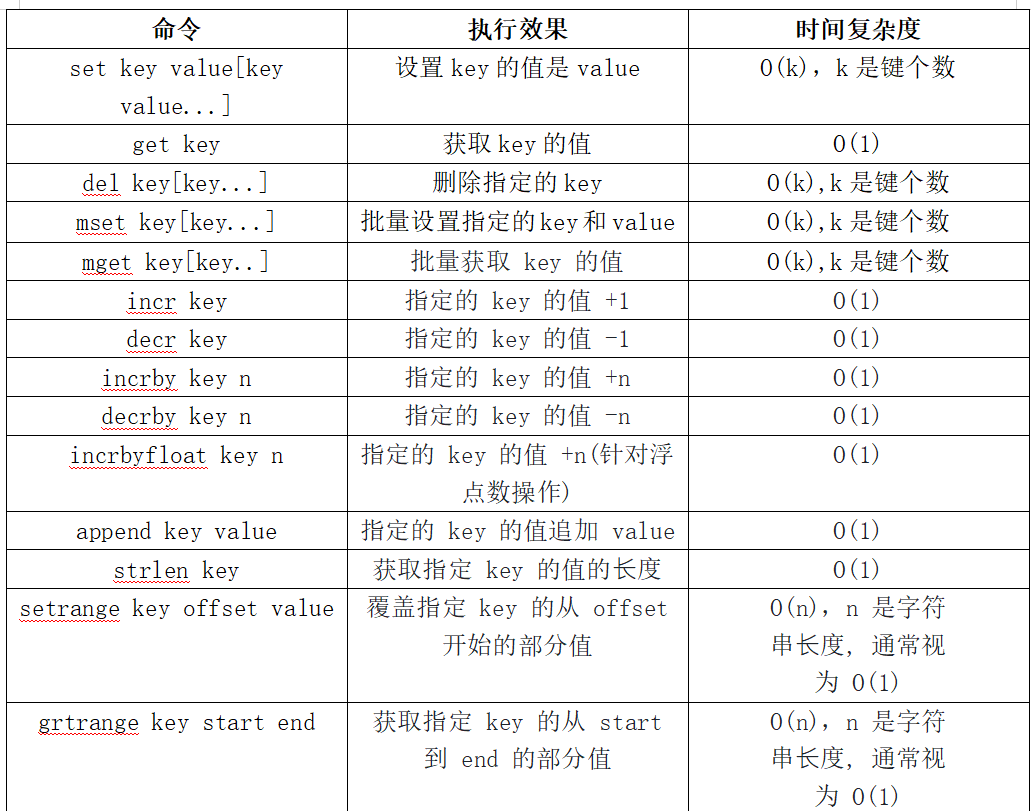
之前我们已经讲过,string内部有三种编码方式:
1、int 64位/8字节的整数
2、embstr 压缩字符串,适用于比较短的字符串
3、raw 普通字符串,适用于表示更长的字符串,只是单纯地持有字节数组
这里依旧不建议大家去记,长度为多少时由embstr转变为raw,因为这个长度是可以根据业务的不同进行配置的。
假设某个业务场景,有很多很多的key,类型都是string,但是每个value的string长度都是100左右~~
这个业务场景更关注与整体的内存空间,因此这样的字符串考虑使用embstr来存储也是可以的。
那上述效果具体要怎么实现呢?
1、先看redis是否提供了对应的配置项,可以修改39这个数字~~
2、如果没有提供配置项,就需要针对redis源码进行魔改。
为啥很多大厂,往往都是自己造轮子,而不是直接使用业界成熟的呢?
开源的组件往往考虑的是通用性,但是大厂往往都会遇到极端的业务场景~~往往就需要根据当前的极端业务,针对上述的开源组件进行定制化~~
那现在又有一个问题了,小数是通过什么编码方式来存的呢?
实践出真知:
redis存储小数,本质上还是当做字符串来存储。这就和整数差别很大了,整数是直接使用int来存(准确来说是一个Java中的long),是比较方便算数运算的。而小鼠使用字符串来存,意味着每次算数运算,都需要把字符串转成小鼠,进行运算,结果再转回字符串保存。
String类型的应该用场景
1、缓存(Cache)功能
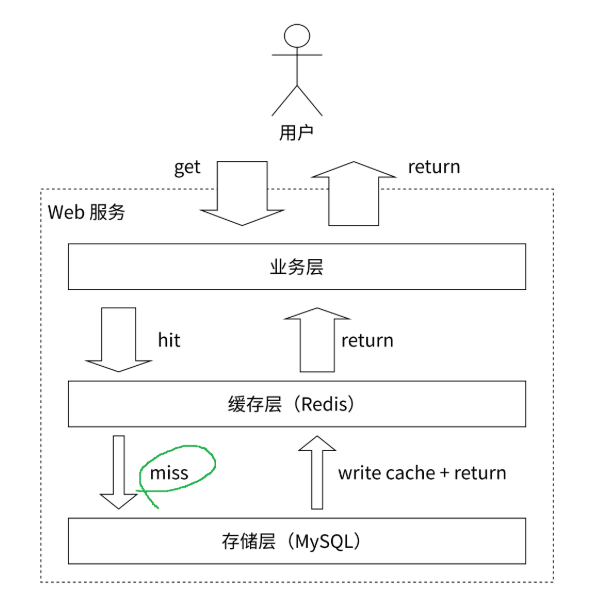
整体思路:
应用服务器访问数据的时候,先查询Redis。如果Redis上数据存在了,就直接从Redis取数据交给应用服务器,不继续访问数据库了。
如果Redis上数据不存在,再读取MySQL,把读到的结果,返回给应用服务器。同时,把这个数据也写入到Redis中。
Redis这样的缓存,经常被用来存储“热点”数据。而“热点数据”(高频被使用的数据),结合业务场景是有很多的定义方式的。比如在刚才上述描述的过程中,相当于把最近用到的数据作为热点数据。此处暗含着一层假设:某个数据一旦被用到了,那么很可能反复用到。
上述策略,存在一个明显的问题:随着时间的推移,肯定会有越来越多的key在redis上访问不到,从而从mysql读取并写入redis了。从而从mysql读取并写入redis了。此时redis的数据不是越来越多吗?
此时有两种策略解决这个问题:
1、在把数据写入redis的同时,给这个key设置一个过期时间。
2、redis也在内存不足的时候,提供淘汰机制。(这个我们后面再细说)
2、计数功能
这个功能一般用来收集用户的数据。那么为啥要统计用户的数据呢?
进一步明确用户需求,根据需求改进和迭代产品~~
事实上,Redis并不擅长数据统计。想象一个业务场景,统计播放量前100的视频有哪些~~基于redis搞就会很麻烦~~相比之下,如果是mysql来存储上述数据,一个sql就搞定了。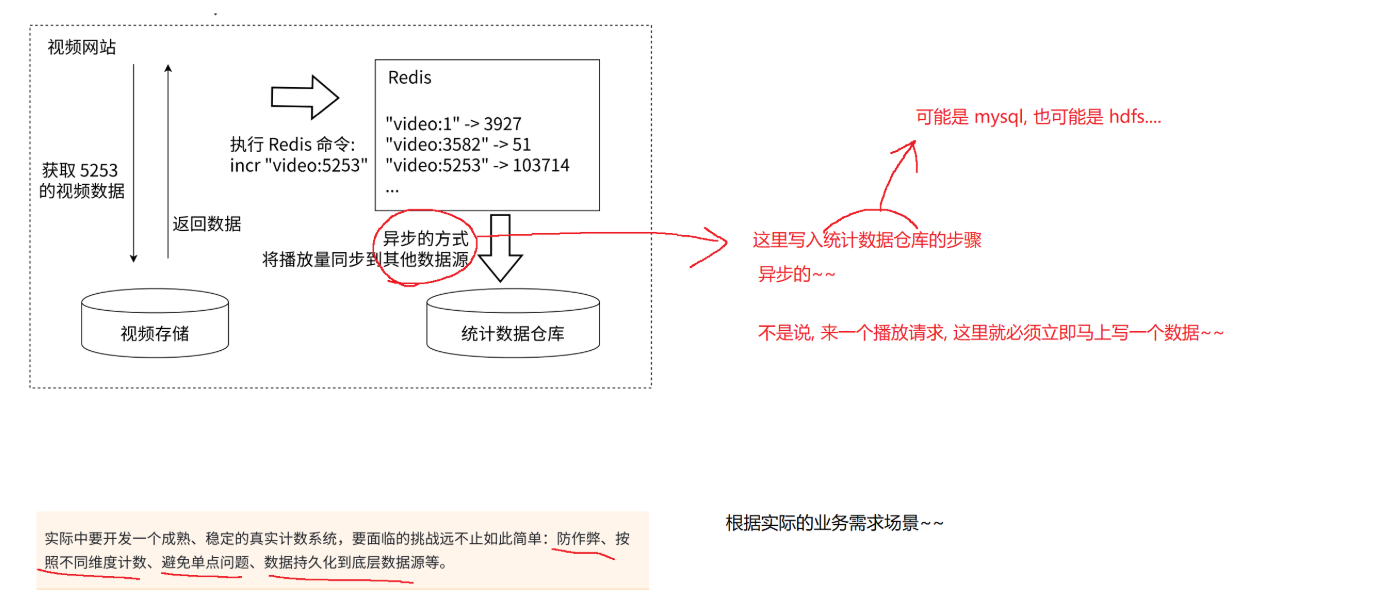
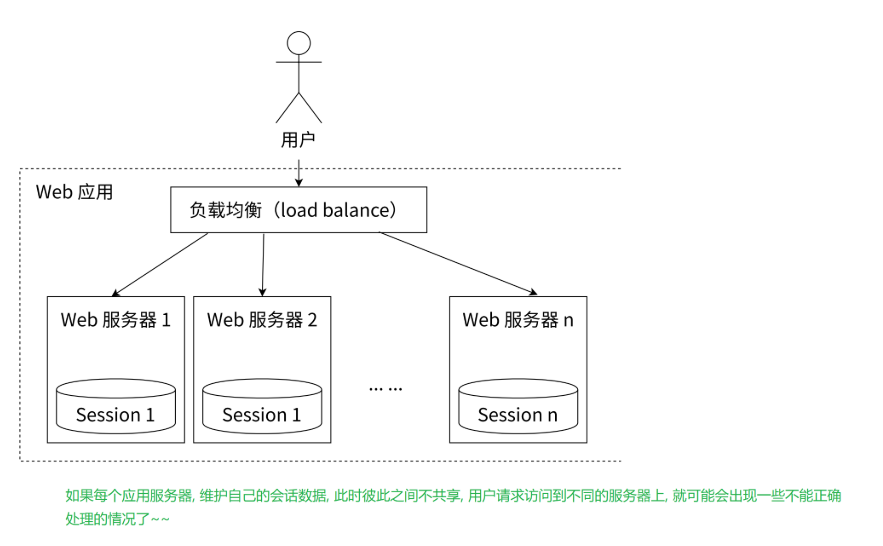
3、共享Session
先来复习下什么是Session把,Cookie是浏览器这边存储数据的机制,而Session则是服务器这边存储数据的机制,它们都是以键值对的形式进行存储的。
举个栗子,前端时间,我打球被人拌了。于是,我去医院挂了个骨科的专家号。此时,医生就给了我一些药让我回去涂抹,并且让我一周后回来复诊~~很快一周过去了,我去复查,发现之前我来看病的那个专家不在,我心想:这咋整?虽然今天也有一个医生,但是这个医生之前没给我看过,他不了解我的情况~~于是,我硬着头皮还是去找了他。但其实医院为了应对这种情况也是有相应的机制的——“就诊卡”。这个新的医生就拿着我的就诊卡,一刷~~它的电脑上就出现了我之前的病例~~
此时,我这个病人就相当于一个客户端,医生给我诊病,提供服务,就相当于服务器。由于病人需要多次访问服务器,服务器这边就需要很好地了解到病人每次复查时候的状态~~医院很多个医生,多个服务器。这些服务器,是以负载均衡的方式来提供服务的~~同一个病人,两次来医院看病,遇到的医生可能是不同的~~此时,如果每个医生只是靠自己的记忆来存储病人的状态。此时两次访问到不同的医生,医生就很难知道病人之前的情况了~~
医院的做法:使用一套系统,记录病人的病历,诊断结果,治疗情况(这个就是所谓的会话,客户端和服务器在交互过程中产生的一些专属于改客户端中间状态的数据~~),这些治疗情况就能让多个医生共享。
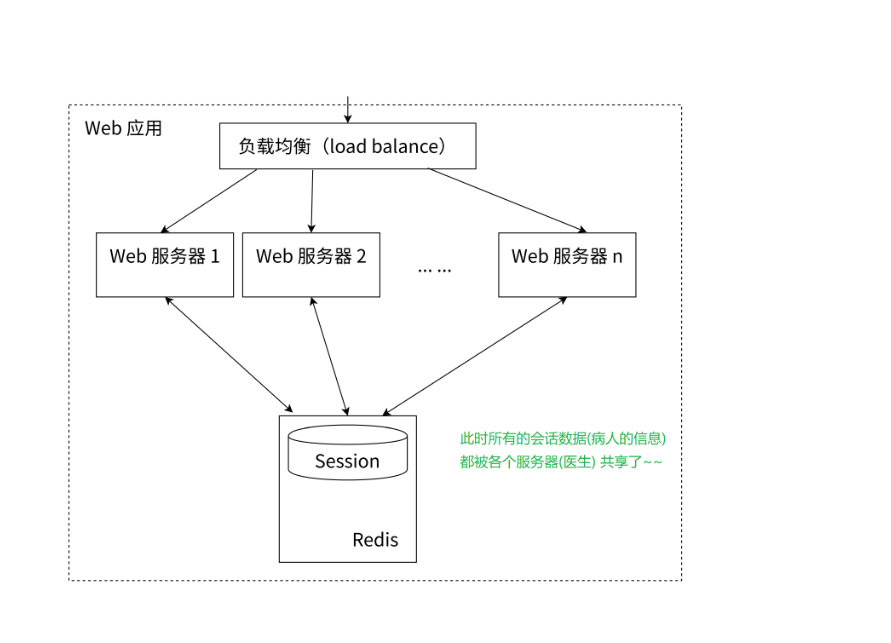
4、手机验证码
手机验证码的过程大致可以分为两步:
1、生成验证码
用户输入一下手机号,点击获取验证码(限制1分钟之内,最多获取5次验证码(将value设为获取验证码的次数,使用incr ++value,超过5次直接返回)或者每次获取验证码必须间隔30秒(setnx key value ex 30)),这里设置这些机制主要还是怕用户频繁获取验证码,对于我们服务器压力过大~~
2、检查验证码
把短信收到的验证码这一串数,提交到系统中~~系统进行验证的验证码是否正确~~
什么是业务?
业务其实就是一个公司/一个产品,是如何解决一个/一系列问题的~~解决问题的过程就可以称为业务。一个公司/产品想要生存,就得赚钱;要想赚钱,就得帮别人解决问题……
比如学校的业务是啥?教育
展开来说:
1、校企合作
2、提供教育资源
3、校园招聘
4、开展讲座
……
解决问题:
为学生提供学习场所,提升学生综合能力,提高就业竞争力
业务是非常重要的!!!很多时候,优化技术解决不了的问题,可以通过优化业务来解决~~实际开发过程中,必须结合实际的业务场景来做一些技术上的调整~~
调整业务解决问题的实际例子:
12306
12306这个网站背后的技术积累,可以说全国甚至全世界,独一档~~这个网站支撑的业务是及其恐怖的!!
在春运的时候,抢火车票~~此时意味着:超高的并发量!!最开始时,12306体验是非常差的。虽然当时引入了非常多的技术,提高网站的访问速度和可用性~~但是在放票的时候,整体压力还是很大,容易出现问题。一般是提前15天放票,在这个放票的时候,因为抢的人太多了~~就会导致服务器压力一下子拉满。
在经过一系列的技术优化之后发现优化效果并不明显。此时,就有人提出了一个方案:分批次放票,15天前放一批、7天前放一批、3天前放一批……本来一次放所有票,现在分三次,每次放1/3,这样就相当于把服务器的压力降低到原来的1/3了。
因此,我们在考虑解决问题时不仅仅要考虑技术上的优化,还要多考虑业务上进行优化!!!