【BUG调查日记】用于压测的机器人进程内存压不住且脱离分配器的管理
文章目录
- 前言
- 分析
- 查内存泄漏无果
- 试图观察内存分布
- 找到根源
- 总结
前言
做外网服务器压测的时候,发现机器人进程在运行一段时间后,内存会逐步爬升,5个机器人进程在运行几个小时后会把机器的32g内存吃完,然后出现oom。
分析
机器人进程的架构是 C + lua,分配器采用的是jemalloc,当用 luajit 时,jit会自己管理lua内存。
机器人运行时我们采集到三处内存数据,top命令展示的进程实际占用总内存,jemalloc提供的接口输出的分配器持有内存,以及lua的垃圾回收接口输出的lua内存。
按理说,top展示的内存应该跟je输出的内存值相当或者差距不大,但是从日志可以看到top以及oom之后从/var/log/messages 里看到的内存值远大于je输出的值。也就是说,导致机器人进程oom的巨大内存的分配绕过了jemalloc。
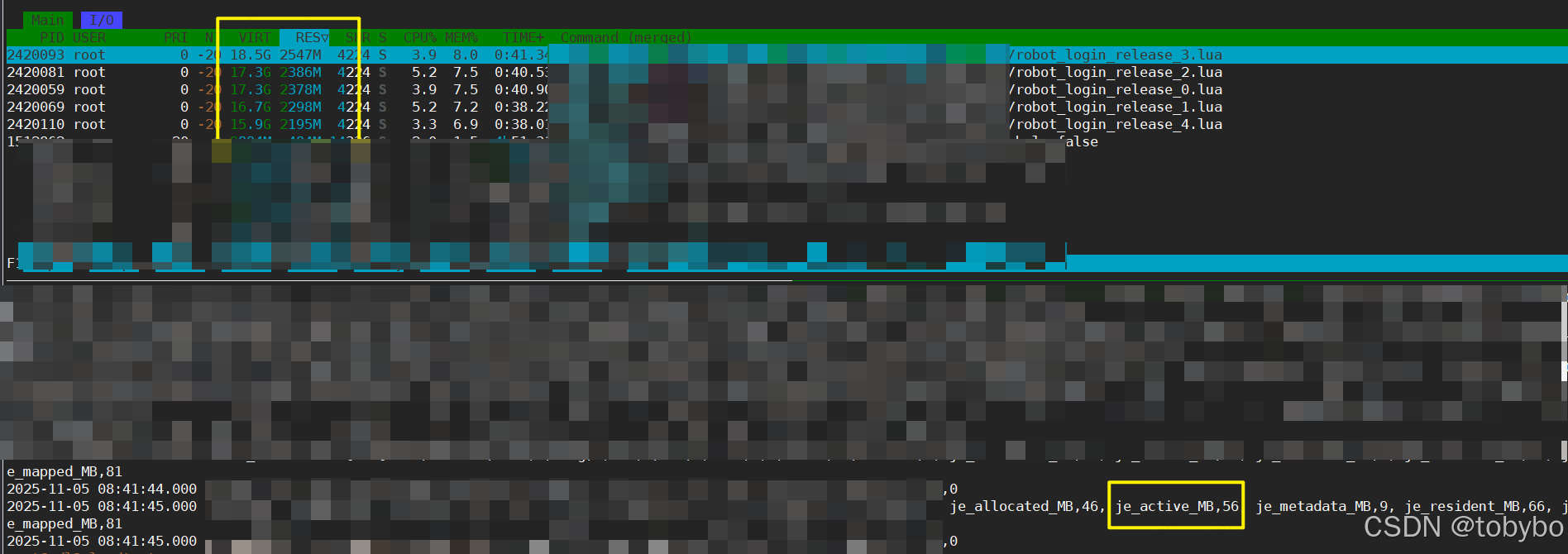
查内存泄漏无果
这样引发了一个猜想:是不是机器人进程编译时链接的第三方库中有接口分配了额外的内存,且产生了内存泄漏?
首先,通过查AI了解到:
- 如果你的主程序链接了 jemalloc(静态库版本),并且 jemalloc 定义了 malloc、free、calloc、realloc 这些符号,
- 链接器会用 jemalloc 的实现替换所有未显式绑定的 malloc 调用,无论它来自主程序还是其他静态库。
而 review 了一下我们链接的静态库后,没有发现有自定义分配器的库。
接着我只能怀疑产生了内存泄漏,这个泄漏甚至可能是jemalloc产生的,也许能勉强解释je没有统计到这部分内存。
查内存泄漏就用上了常用的工具,sanitizer。
启动加入了 sanitizer 编译选项的进程后,到进程终止,我得到的sanitizer日志中只看到终止应用程序不规范而泄漏的几百K:

试图观察内存分布
从sanitizer的分析结果来看,进程并没有明显的内存泄漏。貌似走进了死胡同。内存统计信息明确的告诉我们有内存泄漏,但是权威的工具告诉我们没有。
没有办法的办法,尽量看能不能找到多出来的内存占用的分布情况,查询AI后使用以下命令获得一些信息:
cat /proc/<PID>/smaps
smaps 会详细列出每个内存映射段(堆、栈、shared library)的大小、内存页属性
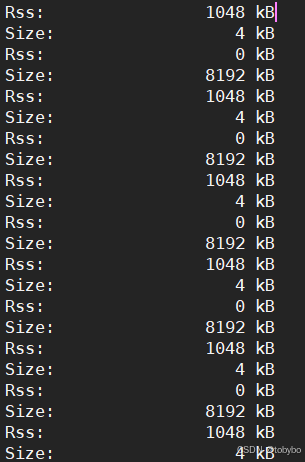
看到以上内存信息,尤其是如此多且整齐分布的8192kB,我出于直觉,做了一个小统计:

由于下班了,查到这里就暂停了。
晚上睡觉前突然想到4000这个敏感的数字,当时我启动机器人的时候,就是5个机器人,每个机器人进程跑4k个号。所以猜想这部分内存是不是 socket 连接产生的。
第二天上班的时候,我再次启动机器人,每个机器人只跑1k的号,最终得到的内存统计,果然刚好是1k多一点的8192kB,佐证了这一猜想,至少这部分内存跟socket连接是有关的。
找到根源
当我确定内存问题跟socket连接有关之后,我第一反应怀疑的肯定不是Linux的套接字系统有什么bug,肯定是开始review我们进程发起连接的代码,在这之前我有查询AI,connect是比accept消耗更多的资源,但是也不可能是这个级别的内存消耗。
我在网络模块的代码里发现了一个非常可疑的调用:
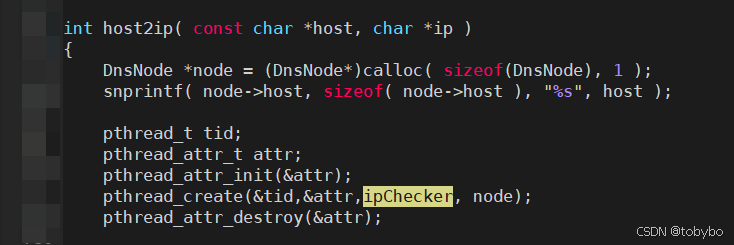
如果目标host是域名的形式,那么每发起一个socket连接,就会通过该接口创建一个线程来查询目标的IP地址。这就很接近了,之前我写过一个博客,讨论的就是linux上一个线程的内存消耗问题,跟8M的虚拟内存占用匹配上了。
查到这里,我先用最简单的方法验证一下是否就是这里产生了内存泄漏,把服务器的网关地址从动态查询域名修改为了显式的IP地址。再次启动机器人后,内存占用很美妙。
总结
通过查询AI得知,创建的线程,首先,内存分配是内核直接完成的,不会被应用的分配器接管。其次,线程没有按合理的方式销毁,就会产生内存泄漏。该逻辑长期存在而没被发现问题是由于该逻辑在作为服务器的进程中,没有对外发起大量连接的需求,一般只需要连接网关、数据库等服务器。

