Spring AI Advisors API与 Ollama 的结合及实战示例
Spring AI 与 Ollama 的结合及实战示例
Advisors API 是 Spring AI 中用于拦截、增强 AI 模型交互的核心机制,而 Ollama 是一款轻量工具,支持在本地部署和运行大语言模型(如 Llama 2、Mistral、Qwen 等)。当两者结合时,Advisors API 可对与 Ollama 本地模型的交互进行灵活管控(如请求增强、响应处理、上下文管理等)。以下是具体解析与示例:
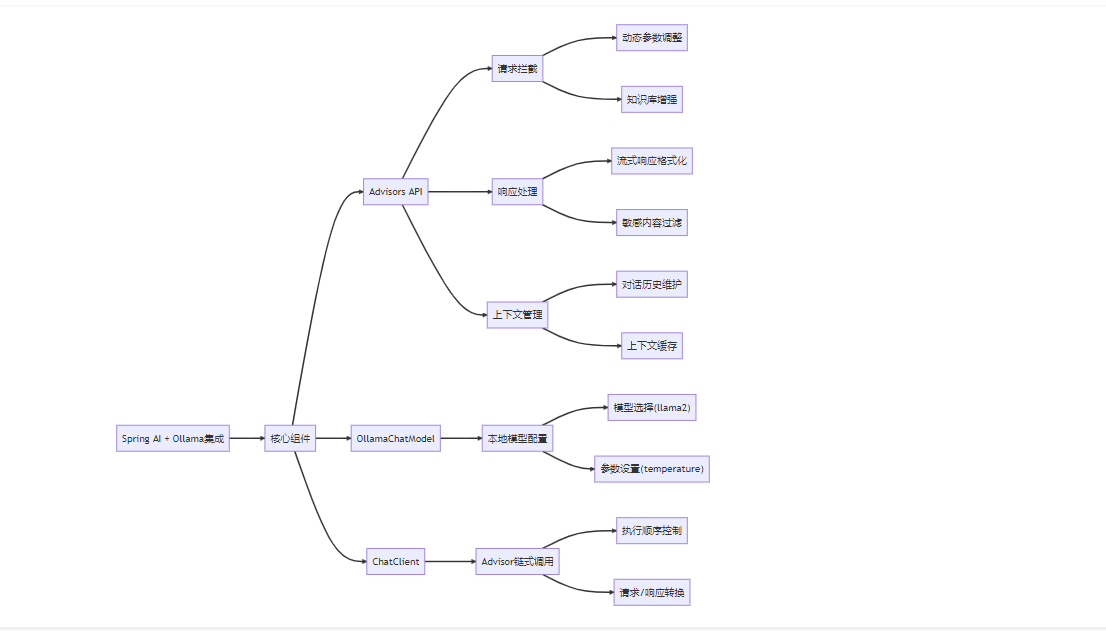
一、基础集成:Spring AI + Ollama
首先需通过 Spring AI 集成 Ollama,确保能通过 ChatClient 与本地 Ollama 模型交互,为 Advisors API 提供基础环境。
1. 依赖配置(Maven)
<dependencies><!-- Spring AI 核心 --><dependency><groupId>org.springframework.ai</groupId><artifactId>spring-ai-core</artifactId><version>1.0.0-SNAPSHOT</version></dependency><!-- Ollama 集成 --><dependency><groupId>org.springframework.ai</groupId><artifactId>spring-ai-ollama</artifactId><version>1.0.0-SNAPSHOT</version></dependency></dependencies>
2. 配置 Ollama 模型与 ChatClient
需指定本地 Ollama 服务地址(默认 http://localhost:11434)和使用的模型(如 llama2),并构建包含 Advisors 的 ChatClient:
import org.springframework.ai.chat.ChatClient;import org.springframework.ai.ollama.OllamaChatModel;import org.springframework.ai.ollama.api.OllamaApi;import org.springframework.context.annotation.Bean;import org.springframework.context.annotation.Configuration;import java.util.List;@Configurationpublic class OllamaConfig {// 1. 配置 Ollama API 客户端(连接本地 Ollama 服务)@Beanpublic OllamaApi ollamaApi() {return new OllamaApi("http://localhost:11434"); // 本地 Ollama 默认地址}// 2. 配置 Ollama 聊天模型(指定使用的本地模型,如 llama2)@Beanpublic OllamaChatModel ollamaChatModel(OllamaApi ollamaApi) {return new OllamaChatModel(ollamaApi,OllamaChatModel.OllamaChatOptions.builder().withModel("llama2") // 本地部署的模型名称.withTemperature(0.7f) // 模型参数:温度(控制随机性).withMaxTokens(1024) // 最大生成 tokens.build());}// 3. 构建带 Advisors 的 ChatClient(整合所有顾问)@Beanpublic ChatClient chatClient(OllamaChatModel ollamaChatModel, List<Advisor> advisors) {return ChatClient.builder(ollamaChatModel).advisors(advisors) // 注入自定义或内置顾问.build();}}
二、Advisors API 在 Ollama 交互中的核心作用
与调用 OpenAI 等云端模型不同,Ollama 运行本地模型,Advisors API 的作用聚焦于:
-
优化本地模型的输入(如补充本地知识库上下文);
-
处理本地模型的输出(如格式化响应、过滤敏感内容);
-
管理本地交互的上下文(减少重复输入,提升效率);
-
动态调整 Ollama 模型参数(如根据请求类型修改 temperature)。
三、实战示例:自定义 Advisors 增强 Ollama 交互
示例 1:动态调整 Ollama 模型参数(请求拦截)
场景:根据用户问题类型(如 “事实性问题” vs “创意写作”)动态修改 Ollama 的 temperature 参数(事实性问题用低温度保证准确性,创意问题用高温度增加多样性)。
import org.springframework.ai.advisor.AdvisedRequest;import org.springframework.ai.advisor.AdvisedResponse;import org.springframework.ai.advisor.CallAroundAdvisor;import org.springframework.ai.advisor.CallAroundAdvisorChain;import org.springframework.ai.ollama.OllamaChatModel;import org.springframework.core.Ordered;import org.springframework.stereotype.Component;@Componentpublic class DynamicTemperatureAdvisor implements CallAroundAdvisor {@Overridepublic String getName() {return "dynamicTemperatureAdvisor";}@Overridepublic int getOrder() {return Ordered.HIGHEST\_PRECEDENCE; // 最高优先级,先于其他请求处理}@Overridepublic AdvisedResponse aroundCall(AdvisedRequest request, CallAroundAdvisorChain chain) {String userQuestion = request.userText();OllamaChatModel.OllamaChatOptions options = (OllamaChatModel.OllamaChatOptions) request.options();// 根据问题类型调整 temperatureif (isFactualQuestion(userQuestion)) {// 事实性问题:低温度(0.1-0.3),减少随机性options.setTemperature(0.2f);} else {// 创意问题:高温度(0.7-1.0),增加多样性options.setTemperature(0.8f);}// 将修改后的参数设置回请求,并继续执行后续顾问/模型调用request.options(options);return chain.nextAroundCall(request);}// 判断是否为事实性问题(简单示例:含“是什么”“为什么”等关键词)private boolean isFactualQuestion(String question) {return question.contains("是什么") || question.contains("为什么") || question.contains("如何");}}
示例 2:本地知识库增强(RAG 结合 Ollama)
场景:通过 Advisor 拦截用户请求,从本地知识库(如文件、数据库)检索相关信息,拼接为提示给 Ollama 模型,实现本地化 RAG(检索增强生成)。
import org.springframework.ai.advisor.AdvisedRequest;import org.springframework.ai.advisor.AdvisedResponse;import org.springframework.ai.advisor.CallAroundAdvisor;import org.springframework.ai.advisor.CallAroundAdvisorChain;import org.springframework.core.Ordered;import org.springframework.stereotype.Component;@Componentpublic class LocalKnowledgeAdvisor implements CallAroundAdvisor {// 模拟本地知识库检索(实际可集成向量库如 FAISS、Chroma)private String retrieveFromLocalKnowledge(String query) {// 此处简化:根据 query 从本地文档中检索相关内容if (query.contains("Spring AI")) {return "本地知识库信息:Spring AI 是 Spring 生态的 AI 工具包,支持多模型集成...";}return "未检索到相关本地知识";}@Overridepublic String getName() {return "localKnowledgeAdvisor";}@Overridepublic int getOrder() {return Ordered.HIGHEST\_PRECEDENCE + 10; // 优先级低于参数调整顾问}@Overridepublic AdvisedResponse aroundCall(AdvisedRequest request, CallAroundAdvisorChain chain) {// 1. 从本地知识库检索相关信息String localKnowledge = retrieveFromLocalKnowledge(request.userText());// 2. 增强用户请求:拼接本地知识作为提示前缀String enhancedPrompt = String.format("基于以下本地知识回答问题:\n%s\n\n用户问题:%s",localKnowledge,request.userText());request.userText(enhancedPrompt);// 3. 继续调用后续顾问和 Ollama 模型return chain.nextAroundCall(request);}}
示例 3:流式响应处理(适配 Ollama 流式输出)
Ollama 支持流式生成(如 stream: true),通过 StreamAroundAdvisor 可处理逐段返回的响应(如实时显示、格式化)。
import org.springframework.ai.advisor.AdvisedRequest;import org.springframework.ai.advisor.AdvisedResponse;import org.springframework.ai.advisor.StreamAroundAdvisor;import org.springframework.ai.advisor.StreamAroundAdvisorChain;import org.springframework.core.Ordered;import org.springframework.stereotype.Component;import reactor.core.publisher.Flux;@Componentpublic class OllamaStreamFormatAdvisor implements StreamAroundAdvisor {@Overridepublic String getName() {return "ollamaStreamFormatAdvisor";}@Overridepublic int getOrder() {return Ordered.LOWEST\_PRECEDENCE; // 最后处理流式响应}@Overridepublic Flux<AdvisedResponse> aroundStream(AdvisedRequest request, StreamAroundAdvisorChain chain) {// 1. 获取 Ollama 的流式响应(Flux 类型,逐段返回)Flux<AdvisedResponse> originalStream = chain.nextAroundStream(request);// 2. 格式化每一段响应(如添加前缀、过滤空内容)return originalStream.filter(response -> !response.message().isEmpty()) // 过滤空片段.map(response -> {String formattedMessage = "\[本地模型] " + response.message();return response.withMessage(formattedMessage);});}}
四、内置 Advisors 与 Ollama 的结合
Spring AI 内置的顾问(如对话历史管理、内容安全过滤)同样适用于 Ollama,只需在配置中注入即可:
1. 对话历史管理(ChatMemoryAdvisor)
本地模型交互中,通过 ChatMemoryAdvisor 自动维护上下文,避免重复输入历史对话:
import org.springframework.ai.advisor.chat.ChatMemoryAdvisor;import org.springframework.context.annotation.Bean;import org.springframework.context.annotation.Configuration;@Configurationpublic class OllamaAdvisorConfig {// 注入对话历史顾问(默认使用内存存储)@Beanpublic ChatMemoryAdvisor chatMemoryAdvisor() {return new ChatMemoryAdvisor();}}
效果:多轮对话时,Ollama 会自动获取上一轮上下文,无需手动拼接历史消息。
2. 内容安全过滤(SafeGuardAdvisor)
本地模型生成内容可能存在风险,通过顾问过滤敏感词:
import org.springframework.ai.advisor.safety.SafeGuardAdvisor;import org.springframework.context.annotation.Bean;import org.springframework.context.annotation.Configuration;@Configurationpublic class SafetyConfig {@Beanpublic SafeGuardAdvisor safeGuardAdvisor() {return new SafeGuardAdvisor(// 敏感词列表(本地模型需过滤的内容)List.of("暴力", "违法", "敏感政治"));}}
效果:Ollama 响应中若包含敏感词,会被自动替换或拦截。
五、执行流程与注意事项
-
执行顺序:Advisors 按
getOrder()排序,请求阶段从低到高执行,响应阶段从高到低执行(与云端模型一致)。 -
本地特性适配:
-
Ollama 模型参数(如
temperature、max_tokens)需通过OllamaChatOptions修改,Advisor 中需强转类型(如示例 1)。 -
本地模型性能受硬件限制,Advisor 逻辑需轻量化(避免复杂计算影响响应速度)。
- 调试与监控:通过
AdvisorContext记录本地模型的调用信息(如耗时、生成 tokens 数),便于优化本地部署性能。
六、适用场景
-
隐私敏感场景:本地模型 + Advisors 实现全链路数据本地化(如医疗、金融数据处理),避免数据上传云端。
-
离线环境:在无网络环境下,通过 Advisors 增强本地模型的交互能力(如离线知识库查询)。
-
低成本调试:用 Ollama 本地模型测试 Advisors 逻辑,无需消耗云端 API 费用。
通过 Advisors API 与 Ollama 的结合,可在本地环境中灵活管控 AI 交互,兼顾隐私性、灵活性与成本优势,尤其适合对数据本地化要求高的场景。