无需人类标注!Meta提出SPICE:让AI在文档语料库中自我对弈,推理能力持续进化


今天要和大家分享一篇有意思的论文——Meta AI团队在2025年10月28日发布的《SPICE:在语料库环境中自我对弈提升推理能力》。这篇论文提出了一种全新的AI自我提升方法。
为什么AI需要“自我对弈”?
我们都知道,现在的大语言模型在数学、编程等需要推理的领域已经表现出色。但有一个问题:这些能力大多依赖于人类标注的数据进行训练。就像教孩子做数学题,需要老师不断出题和批改,成本高且难以规模化。
那么,AI能不能自己给自己出题,自己批改,然后自我提升呢?这就是自我对弈的概念。早在围棋AI AlphaGo中,自我对弈就证明了其价值——通过与自己不断对战,AI可以超越人类水平。
但在语言模型领域,自我对弈却遇到了瓶颈。论文指出,现有的方法存在两个致命问题:
1. 幻觉放大:AI在自我对弈中会产生事实错误,这些错误会在训练过程中不断累积,就像传话游戏一样越传越离谱。
2. 信息对称:出题者和解题者是同一个模型,知识储备完全一样,无法真正挑战对方,最终会陷入简单重复的模式。
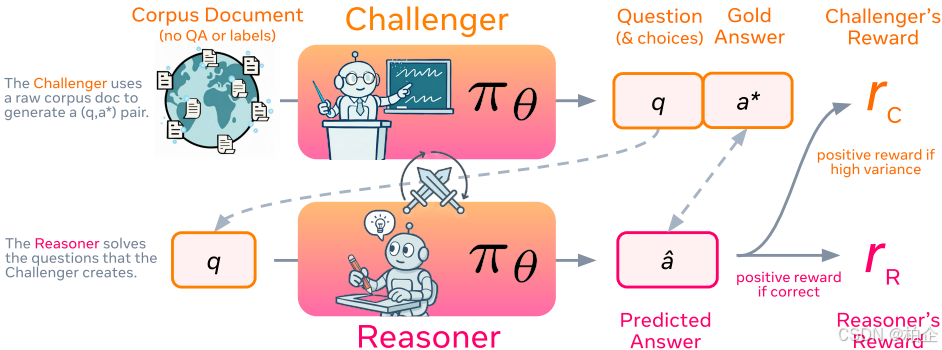
SPICE的巧妙设计:当AI学会“藏私”
Meta团队提出的SPICE框架有一个核心洞察:打破信息对称性。
想象一下,如果两个学生在备考,一个人偷偷看了答案然后给另一个人出题,这样就能真正检验对方的水平。SPICE正是利用了这个思路!
整个系统只需要一个模型,但扮演两个角色:
挑战者:可以访问文档语料库,基于真实文档出题并知道正确答案
推理者:只能看到问题,不能访问文档,需要凭自己的知识回答
这种信息不对称的设计太关键了!挑战者有了“作弊”的优势,可以不断拿出基于真实知识的难题来考验推理者。而推理者为了不被难倒,就必须不断提升自己的推理能力。
双角色协作的技术细节
让我们深入看看这个“猫鼠游戏”的具体规则:
挑战者如何出题?
给定一个文档,挑战者生成问题和正确答案。SPICE支持两种题型:
选择题:四个选项,其中一个正确答案
开放式问题:答案可能是整数、表达式或字符串
关键创新在于挑战者的奖励机制。它不是随便出题就能得分,而是需要出难度恰到好处的题目:
τσσ
其中σ是推理者回答的正确率方差,σ是最佳方差(对应50%正确率)。
这个公式的意思是:当推理者有50%的概率能答对时,挑战者获得最高奖励。太简单或太难的题目得分都很低。这样就自然形成了一个自适应课程——随着推理者能力提升,挑战者也会相应调整题目难度。
推理者如何得分?
这个就比较直观了:答对得分,答错不得分。
训练过程:真正的“左右互搏”
在训练中,模型不断切换角色:
先作为挑战者,从文档库采样并生成问题
然后作为推理者,尝试回答刚才生成的问题
根据双方表现更新模型参数
整个过程完全自监督,不需要任何人工干预!只需要提供一个文档语料库即可。
实验结果:SPICE真的有效吗?
理论很美好,但实际效果如何?论文在多个模型和基准测试上进行了全面评估:
测试模型:Qwen3-4B/8B、OctoThinker-3B/8B
对比基线:原始模型、使用更强挑战者的方法、无语料库的自我对弈等
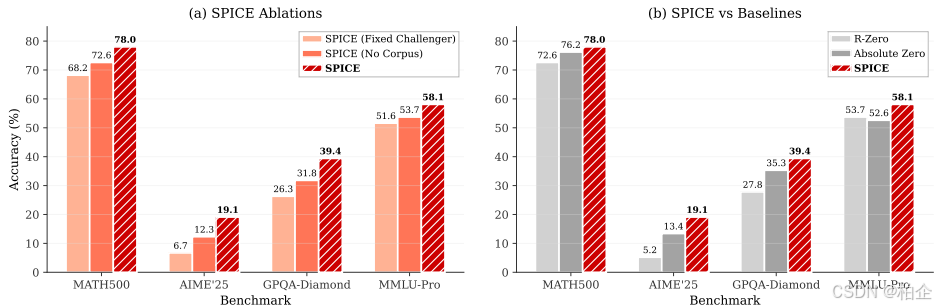
结果令人印象深刻:
Qwen3-4B:从35.8%提升到44.9%(+9.1%)
OctoThinker-8B:从20.5%提升到32.4%(+11.9%)
提升覆盖了数学推理和通用推理两大类任务,证明SPICE培养的是通用推理能力,而不是针对特定任务的过拟合。
训练动态:看着AI越来越“狡猾”
最有趣的是观察训练过程中两个角色的博弈过程:
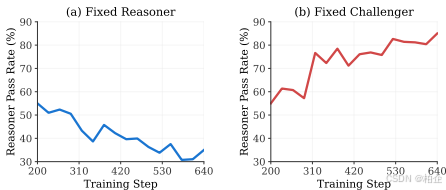
当固定推理者(用第200步的版本)而让挑战者不断进化时,答题通过率从55%降至35%——说明挑战者确实学会了出更难的题。
相反,当固定挑战者而让推理者进化时,通过率从55%升至85%——推理者解题能力显著提升。
这种对抗性协同进化正是SPICE成功的关键!
语料库的重要性:知识来源决定上限
论文还做了一个关键实验:比较有/无语料库 grounding的效果。
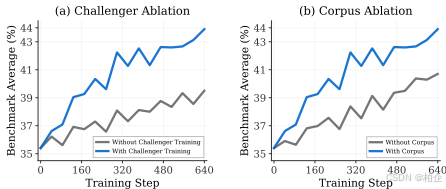
结果很明显:有语料库的情况下性能更好(43.9% vs 40.7%)。语料库提供了几乎取之不尽的知识源泉,防止模型陷入自我重复的怪圈。
从简单到复杂:AI出题的进化之路
论文展示了一些具体例子,让我们看到SPICE是如何逐渐提升难度的:
早期训练(第50步):问题很简单,直接询问文档中的明确事实
“月球的直径是多少?”
→ 直接从文档中提取数字即可
后期训练(第480步):问题需要多步推理和概念理解
“一个外星文明有直径3475公里的月球,能产生完美日食。如果他们的恒星与我们的太阳直径相同,月球轨道距离为374,000公里,那么行星到恒星的距离是多少?”
→ 需要理解角大小概念和比例关系
同样,推理者的回答也从简单猜测进化到系统性的多步推理,展现出真正的推理能力而非记忆。
为什么SPICE如此重要?
SPICE代表了AI训练范式的转变:
摆脱人类标注:不再依赖昂贵且有限的人工标注数据
持续自我提升:理论上可以无限循环,不断突破模型能力边界
领域通用:不同于只能在数学或代码领域工作的现有方法,SPICE适用于任何有文档的领域
这项研究的作者团队来自Meta FAIR和新加坡国立大学,包括Bo Liu、Chuanyang Jin等研究人员。他们成功地将游戏AI中的自我对弈理念与语言模型的推理能力提升相结合,开辟了一条全新的技术路径。
展望未来
想象一下,如果给AI接入整个互联网作为语料库,它能否通过不断自我挑战,最终达到甚至超越人类水平的推理能力?SPICE为这个愿景提供了切实可行的技术路径。
这项研究也引发我们思考:真正的智能是否源于与环境持续互动、不断挑战自我边界的过程? 或许不仅是AI,人类的学习机制也有着类似的规律。
对于AI行业来说,SPICE意味着我们可能正在进入一个自主智能的新时代——AI不再只是被动执行任务,而是能够主动学习和进化。