机器学习 大数据情境下blending-示例
blending
当数据量极大时,Blending 是更高效的选择,但我们可以通过 「分层Blending」+「分布式计算」 实现高性能融合。以下是针对大数据场景的优化方案,结合了 Blending 的速度优势和 Stacking 的数据利用率:
🚀 大数据场景下的混合融合方案
import numpy as np
import pandas as pd
from sklearn.model_selection import train_test_split
from joblib import Parallel, delayed# 生成大规模示例数据 (100万样本)
X, y = make_classification(n_samples=1_000_000, n_features=50, random_state=42)# ====================== 分层Blending优化 ======================
# 策略:将数据分为三层,最大化利用数据
X_full, y_full = X, y# 第一层:划分训练集和保留集 (98% : 2%)
X_train, X_holdout, y_train, y_holdout = train_test_split(X_full, y_full, test_size=0.02, random_state=42
)# 第二层:将训练集分为Blending的A/B部分 (90% : 10%)
X_blend_A, X_blend_B, y_blend_A, y_blend_B = train_test_split(X_train, y_train, test_size=0.1, random_state=42
)# ====================== 分布式训练基模型 ======================
# 定义高效且多样化的基模型(适合大数据)
base_models = [('lgbm', LGBMClassifier(n_estimators=500,learning_rate=0.05,num_leaves=127,subsample=0.8,colsample_bytree=0.8,n_jobs=4 # 单模型并行)),('xgb', XGBClassifier(n_estimators=500,learning_rate=0.05,max_depth=6,subsample=0.8,colsample_bytree=0.8,tree_method='hist', # 大数据优化n_jobs=4)),('hist_gbm', HistGradientBoostingClassifier(max_iter=500,learning_rate=0.05,max_bins=255,categorical_features=None)),('lr', LogisticRegression(C=0.1,solver='lbfgs',max_iter=1000,n_jobs=4))
]# 并行训练函数
def train_model(model, X, y):model.fit(X, y)return model# 使用joblib并行训练 (每个模型独立进程)
trained_models = Parallel(n_jobs=len(base_models))(delayed(train_model)(model, X_blend_A, y_blend_A)for _, model in base_models
)# ====================== 生成元特征 ======================
# 创建Blending元特征矩阵
blend_features = np.zeros((len(X_blend_B), len(trained_models)))
for i, model in enumerate(trained_models):blend_features[:, i] = model.predict_proba(X_blend_B)[:, 1]# 添加统计特征增强信息量
blend_df = pd.DataFrame(blend_features, columns=[name for name, _ in base_models])
blend_df['max_prob'] = blend_df.max(axis=1)
blend_df['min_prob'] = blend_df.min(axis=1)
blend_df['std_prob'] = blend_df.std(axis=1)# ====================== 训练元模型 ======================
# 使用高效线性模型
from sklearn.linear_model import LogisticRegression
meta_model = LogisticRegression(C=0.1, solver='lbfgs', max_iter=1000)
meta_model.fit(blend_df.values, y_blend_B)# ====================== 利用保留集验证 ======================
# 在未使用的2%数据上验证
holdout_features = []
for model in trained_models:holdout_features.append(model.predict_proba(X_holdout)[:, 1])holdout_df = pd.DataFrame(np.array(holdout_features).T, columns=[name for name, _ in base_models])
holdout_df['max_prob'] = holdout_df.max(axis=1)
holdout_df['min_prob'] = holdout_df.min(axis=1)
holdout_df['std_prob'] = holdout_df.std(axis=1)holdout_preds = meta_model.predict_proba(holdout_df.values)[:, 1]
print(f"保留集AUC: {roc_auc_score(y_holdout, holdout_preds):.5f}")# ====================== 预测全量测试集 ======================
# 假设X_test是测试集
test_features = []
for model in trained_models:test_features.append(model.predict_proba(X_test)[:, 1])test_df = pd.DataFrame(np.array(test_features).T, columns=[name for name, _ in base_models])
test_df['max_prob'] = test_df.max(axis=1)
test_df['min_prob'] = test_df.min(axis=1)
test_df['std_prob'] = test_df.std(axis=1)final_predictions = meta_model.predict_proba(test_df.values)[:, 1]
💡 大数据场景优化策略详解
1. 分层数据划分 (98%-2%-10%结构)
- 保留集 (2%):完全独立的数据,用于最终验证,避免过拟合
- Blend A部分 (88.2%):训练基模型的核心数据
- Blend B部分 (9.8%):生成元特征的数据
📊 数据利用率对比:
- 传统Blending:70%训练基模型,30%训练元模型 → 30%数据未用于基模型训练
- 本方案:98%数据参与训练(88.2%直接训练+9.8%间接参与),仅2%完全独立验证
2. 基模型选择原则(大数据优化版)

⚠️ 避免使用以下模型:
- KNN/SVM:时间复杂度O(n²),内存消耗大
- 复杂神经网络:训练时间长,需大量调参
3. **分布式训练技巧
# 关键配置:每个模型独立进程 + 单模型内部并行
Parallel(n_jobs=4)( # 同时训练4个模型delayed(train)(model) for model in models
)# LightGBM单模型并行配置
LGBMClassifier(n_jobs=4) # 使用4个线程
- 两级并行:外层并行不同模型,内层并行单个模型的训练
- 内存控制:对于超大数据,使用partial_fit或分块训练
4. **元特征增强
# 添加统计特征提升元模型效果
blend_df['max_prob'] = blend_df.max(axis=1) # 最大概率值
blend_df['min_prob'] = blend_df.min(axis=1) # 最小概率值
blend_df['std_prob'] = blend_df.std(axis=1) # 概率标准差
- 揭示基模型间的一致性程度
- 当std_prob大时,说明模型分歧大,需元模型仲裁
🚀 性能对比:Blending vs Stacking (大数据场景)
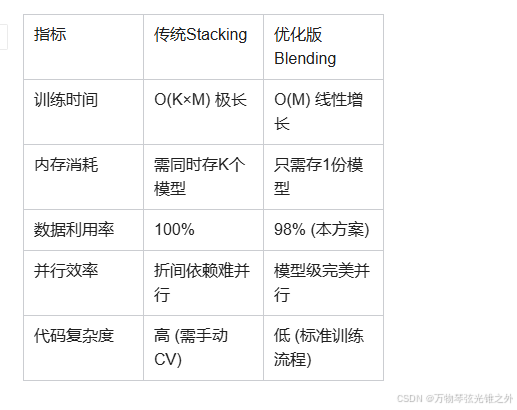
💎 终极建议:何时选择哪种方案
- 数据量 < 100万条 → 用标准Stacking (5折)
- 100万条 < 数据量 < 1000万条 → 用本方案的优化Blending
- 数据量 > 1000万条 → 采用「分块Blending」:
# 将数据分为10块
chunks = np.array_split(X, 10)
# 每块单独做Blending
chunk_predictions = []
for chunk in chunks:model = train_large_model(chunk)preds = model.predict(test)chunk_predictions.append(preds)
# 合并时加权平均(大块权重高)
final_pred = np.average(chunk_predictions, weights=chunk_sizes)
实际在Kaggle竞赛中,顶级团队处理亿级数据时常用分层Blending+特征工程方案,既能保证效率又不显著损失精度。