CANN算子开发实战:从动态Shape到测试验证的深度解析
文章目录
- 一、 引言:为什么动态Shape算子至关重要?
- 二、 核心变革:从固定Shape到动态Shape的改造
- 1. 关键机制:Tiling结构体
- 2. 固定Shape vs. 动态Shape:实现对比
- 3. 核函数(Kernel)的改造
- 三、 算子开发的中枢:Host侧实现与注册
- 1. 算子原型注册 (Operator Prototype Registration)
- 2. Shape推导 (Shape Inference)
- 3. Tiling实现与注册 (Tiling Implementation)
- 4. 信息库配置 (.ini)
- 四、 保证质量:功能调试与测试验证
- 1. 功能调试:TKC++孪生调试技术
- 2. 测试验证:UT与ST的双重保障
- 五、 性能调优:使用msprof洞察算子瓶颈
- 六、 总结
摘要:
在现代
AI应用中,高性能计算和模型迭代速度是决定性的竞争因素。华为CANN(Compute Architecture for Neural Networks)作为昇腾(Ascend)AI处理器的核心,其算子(Operator)的性能和灵活性直接影响着整个AI框架的效率。本文将深度剖析CANN算子开发的关键流程,重点从固定Shape算子到动态Shape算子的演进出发,详细阐述其实现机理、调试方法、UT/ST(单元/系统)测试验证全流程,并介绍如何使用msprof进行性能采集,旨在为AI开发者提供一份全面而深入的CANN算子开发实战指南。
昇腾训练营报名链接: https://www.hiascend.com/developer/activities/cann20252#cann-camp-2502-intro
训练营简介: 2025 年昇腾 CANN 训练营第二季,基于 CANN 开源开放全场景,推出 0 基础入门系列、码力全开特辑、开发者案例等专题课程,助力不同阶段开发者快速提升算子开发技能。获得 Ascend C 算子中级认证,即可领取精美证书,完成社区任务更有机会赢取华为手机,平板、开发板等大奖
声明: 该文仅是为了记录 CANN 训练营的学习过程所用,不参与任何商业用途
一、 引言:为什么动态Shape算子至关重要?
在 AI 模型,特别是 CV 和 NLP 领域,输入的 Shape(如图片分辨率、句子长度)常常是变化的。传统的固定Shape算子在编译时固定了所有维度信息,这意味着每当遇到一个新的输入 Shape,AI 框架就可能需要重新编译、加载一个新的算子二进制文件
这种模式存在两大弊端:
- 编译开销大:模型推理或训练前的图编译时间会急剧增加。
- 二进制文件臃肿:项目中会产生大量针对不同Shape的二进制文件,导致存储和管理困难。
为了解决这一痛点,动态Shape算子应运而生。其核心思想是将 Shape 信息从“编译时常量”转变为“运行时变量”,通过参数传入核函数(Kernel Function),使单一的算子二进制文件能够处理不同 Shape 的输入数据,极大提升了框架的灵活性和执行效率

二、 核心变革:从固定Shape到动态Shape的改造
将一个固定 Shape 算子改造为动态 Shape 算子,其本质是将原先硬编码在代码中或作为全局变量的 Shape 信息,转变为通过一个特定结构体在运行时传入。在 CANN TIK C++ 开发中,这个关键的结构体就是 Tiling
1. 关键机制:Tiling结构体
Tiling 结构体是 Host 侧(CPU)与 Device 侧(NPU 核函数)之间传递“切分策略”的桥梁。它通常包含了算子在 NPU 上执行所必需的调度信息。
下面是一个Tiling结构体的示例(在op_host/add_tik2_tiling.h中定义):
// op_host/add_tik2_tiling.h
// BEGIN_TILING_DATA_DEF宏用于定义结构体的开始
BEGIN_TILING_DATA_DEF(AddTik2TilingData)// TILING_DATA_FIELD_DEF(变量名, 变量类型)TILING_DATA_FIELD_DEF(blockDim, uint32_t) // 并行计算使用的核数TILING_DATA_FIELD_DEF(totalLength, uint32_t) // 总共需要计算的数据个数TILING_DATA_FIELD_DEF(tileNum, uint32_t) // 每个核上计算数据分块的个数
END_TILING_DATA_DEF(AddTik2TilingData)
2. 固定Shape vs. 动态Shape:实现对比
为了更直观地展示差异,我们用一个表格来总结:
| 对比维度 | 固定Shape算子 (Fixed Shape) | 动态Shape算子 (Dynamic Shape) |
|---|---|---|
| Shape信息来源 | 编译时常量、全局变量 | 运行时通过 Tiling 结构体参数传入 |
| 核函数入参 | 主要是输入/输出数据的指针 | 额外增加 Tiling 结构体指针 (uint8_t* tilingData) |
| 核函数实现 | 循环边界、偏移量计算等直接使用全局常量 | 必须首先解析 tilingData 指针,获取Shape信息后再进行计算 |
Init 函数 | 逻辑地址区分等可能依赖全局变量 | 调度参数从 Tiling 中获取,常存储在类成员变量中 |
| 灵活性 | 低,每个 Shape 需要一个二进制文件 | 高,一个二进制文件支持多种Shape |
| 编译开销 | 高(当 Shape 多变时) | 低(一次编译,到处运行) |
3. 核函数(Kernel)的改造
改造核函数是动态 Shape 的核心
-
固定Shape实现 (示例):
注意
BLOCK_DIM和TOTAL_LENGTH是全局或宏定义的。// op_kernel/add_tik2_kernel_fixed.cpp // 全局变量或宏定义 const uint32_t BLOCK_DIM = 8; const uint32_t TOTAL_LENGTH = 1024; const uint32_t TILE_NUM = (TOTAL_LENGTH + BLOCK_DIM - 1) / BLOCK_DIM;extern "C" __global__ __aicore__ void add_tik2_fixed(__gm__ uint8_t* x, __gm__ uint8_t* y, __gm__ uint8_t* z) {// 直接使用全局常量uint32_t loop_max = TILE_NUM; // ... 业务逻辑 ... } -
动态Shape实现 (示例):
Tiling信息通过tilingData指针传入,并在核函数内部首先被解析。// op_kernel/add_tik2_kernel_dynamic.cpp #include "add_tik2_tiling.h" // 引入Tiling定义extern "C" __global__ __aicore__ void add_tik2_dynamic(__gm__ uint8_t* x, __gm__ uint8_t* y, __gm__ uint8_t* z, __gm__ uint8_t* tilingData) // 关键:Tiling指针作为入参 {// 关键:在核函数内部解析Tiling数据GET_TILING_DATA(tiling, tilingData, AddTik2TilingData);// 使用从Tiling中解析出的变量uint32_t loop_max = tiling.tileNum; uint32_t core_id = GetBlockIdx();// ... 业务逻辑 ... }

三、 算子开发的中枢:Host侧实现与注册
算子不仅仅是 NPU 上的核函数,更需要 Host 侧(CPU)的代码来“管理”它,使其能被 AI 框架(如 TensorFlow, PyTorch)正确调用。这部分工作主要在 op_host/add_tik2.cpp 文件中完成
1. 算子原型注册 (Operator Prototype Registration)
这是算子对外的“接口声明”。它告诉 CANN 框架这个算子叫什么名字、有几个输入(Input)、几个输出(Output)以及它们的名称
// op_host/add_tik2.cpp
#include "ge/ge_op_define.h"namespace ge {
// 注册算子原型
GE_OPERATOR_STORE_BEGIN(AddTik2, "AddTik2")// 注册输入:名称"x",数据类型"DT_FLOAT".Input("x", ge::DT_FLOAT)// 注册输入:名称"y",数据类型"DT_FLOAT".Input("y", ge::DT_FLOAT)// 注册输出:名称"z",数据类型"DT_FLOAT".Output("z", ge::DT_FLOAT)
GE_OPERATOR_STORE_END(AddTik2)
} // namespace ge
2. Shape推导 (Shape Inference)
这是实现动态 Shape 支持的关键步骤。Host侧需要提供一个InferShape函数,该函数在图编译阶段被调用,根据输入 Tensor 的 Shape 推导出 输出 Tensor 的 Shape
// op_host/add_tik2.cpp
namespace ge {
// 实现InferShape函数
IMPLEMT_INFERFUNC(AddTik2, AddTik2InferShape) {// 简单示例:Add算子,输出Shape应与输入Shape一致// 实际场景下需要做更复杂的检查和广播(broadcast)处理const Operator& op = OPOBJECT_TO_OPERATOR(opObject);ge::TensorDesc out_desc = op.GetInputDesc("x"); op.UpdateOutputDesc("z", out_desc); // 更新输出"z"的Shape描述return GRAPH_SUCCESS;
}// 注册InferShape函数
REGISTER_INFERFUNC(AddTik2, AddTik2InferShape)
} // namespace ge
3. Tiling实现与注册 (Tiling Implementation)
TilingFunc 是 Host 侧的核心逻辑。它在运行时被调用,根据当前真实的输入Shape,计算出具体的 Tiling 参数(如 BLOCK_DIM, TOTAL_LENGTH 等),然后将这个 Tiling 结构体传递给 NPU 核函数
// op_host/add_tik2.cpp
namespace ge {
// 实现Tiling函数
IMPLEMT_TILING_FUNC(AddTik2, AddTik2TilingFunc) {// 1. 获取输入Tensor的Shapeauto shape = op.GetInputDesc("x").GetShape();uint32_t totalLength = shape.GetShapeSize(); // 假设是简单一维// 2. 实例化Tiling结构体AddTik2TilingData tiling;// 3. 计算Tiling策略 (这是算子性能优化的核心)tiling.blockDim = 8; // 假设固定使用8个核tiling.totalLength = totalLength;tiling.tileNum = (totalLength + tiling.blockDim - 1) / tiling.blockDim;// 4. 将Tiling数据设置到Op中,以便传递给Kernelop.SetTilingData(tiling.SaveToBuffer(), tiling.GetSize());return GRAPH_SUCCESS;
}// 注册Tiling函数
REGISTER_TILING_FUNC(AddTik2, AddTik2TilingFunc)
} // namespace ge
4. 信息库配置 (.ini)
最后,开发者需要配置 op_host/add_tik2.ini 文件,将算子的核函数、TilingFunc等信息注册到 CANN 的算子信息库中
[AddTik2] ; 算子类型
opInterface = "AddTik2" ; TilingFunc的注册名
kernelName = "add_tik2_dynamic" ; NPU核函数名 (必须与.cpp中一致)
binFileName = "./add_tik2" ; 编译生成的.o或.so的相对路径
四、 保证质量:功能调试与测试验证
一个能跑的算子不等于一个好算子。严格的调试和测试是保证算子功能正确、性能达标的必要条件
1. 功能调试:TKC++孪生调试技术
CANN 提供了TKC++孪生调试技术,允许开发者在 CPU 模式下运行和调试 NPU 代码
-
GDB调试:
开发者可以直接使用GDB工具,在CPU模式下对算子代码进行单步调试
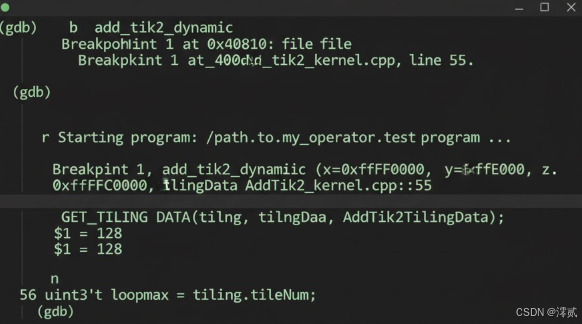
# GDB调试命令示例 (gdb) b add_tik2_dynamic # 在核函数入口打断点 (gdb) r # 运行 (gdb) p tiling.tileNum # 打印Tiling解析出的变量 (gdb) n # 单步执行 -
打印调试:
printf或std::cout语句只在CPU模式下生效。必须使用CCE_KT_TEST宏进行隔离:// op_kernel/add_tik2_kernel_dynamic.cpp extern "C" __global__ __aicore__ void add_tik2_dynamic(...) {GET_TILING_DATA(tiling, tilingData, AddTik2TilingData);// 只在CPU模式下编译和执行#ifdef CCE_KT_TESTprintf("Debug: CoreID=%u, tileNum=%u\n", GetBlockIdx(), tiling.tileNum);#endif// ... 业务逻辑 ... }
2. 测试验证:UT与ST的双重保障
-
UT (Unit Testing, 单元测试):
- 目的:验证算子核函数的逻辑正确性。
- 运行:
UT在CPU模拟环境下运行,不依赖NPU硬件 - 执行:
build.sh -u tik2
-
ST (System Testing, 系统测试):
- 目的:验证算子在真实NPU硬件上的功能和精度。
- 流程:
-
定义测试用例 (
add_tik2.json):
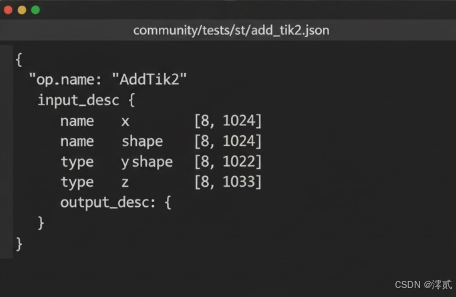
{"op_name": "AddTik2","input_desc": [{ "name": "x", "shape": [8, 1024], "type": "float32" },{ "name": "y", "shape": [8, 1024], "type": "float32" }],"output_desc": [{ "name": "z", "shape": [8, 1024], "type": "float32" }] } -
定义期望数据 (
test_add_tik2_data.py):
msopst工具会调用此Python脚本,使用Numpy等标准库生成“黄金数据”用于精度对比import numpy as npdef get_golden_data(input_data):"""使用Numpy实现Add算子的标准计算"""input_x = input_data[0]input_y = input_data[1]# 黄金数据expected_output = np.add(input_x, input_y)return [expected_output] -
执行与对比:
run_case.sh脚本会自动调用msopst工具,在NPU上执行算子,并将输出结果与get_golden_data的Numpy结果对比 -
生成报告:最终生成
st_report.json报告

-
五、 性能调优:使用msprof洞察算子瓶颈
功能正确只是第一步,算子性能是最终追求。CANN 提供了强大的性能采集工具 msprof
msprof 允许开发者收集算子在 NPU 上执行时的详细硬件指标,如 AI Core 利用率、L0/L1/L2 Cache 命中率、DDR 带宽占用等
性能采集步骤:
-
设置环境变量:
source /usr/local/Ascend/ascend-toolkit/set_env.sh -
编译NPU可执行文件:
bash run.sh add_tik2 ascend910 Aicore npu -
使用msprof采集:执行采集命令,指定要分析的应用和收集的指标。
# 示例:采集AI Core的管线利用率(pipeUtilization) msprof --application="./add_tik2_npu" \--output="./out" \--ai-core=on \--aic-metrics="pipeUtilization" -
分析报告:
msprof会在out/device_0/summary/目录下生成.csv报告
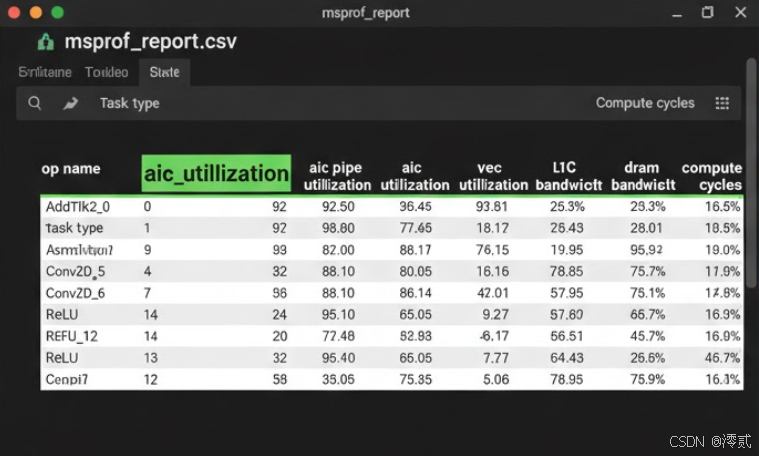
通过分析这些数据,开发者可以精确地定位性能瓶颈(例如是计算受限还是访存受限),并针对性地优化 Tiling 策略或核函数逻辑
六、 总结
CANN 算子开发是一个严谨且精密的工程。从应对真实场景需求的动态Shape改造(Tiling结构体与核函数解析),到连接框架的Host侧注册(GE_OPERATOR, InferShape, TilingFunc),再到保证质量的UT/ST测试验证(gtest, msopst),最后到追求极致性能的msprof调优,每一步都环环相扣且有“码”可依
掌握这一全栈流程,不仅能使开发者在昇腾平台上游刃有余地实现自定义算子,更是深入理解 AI 硬件架构和高性能计算的必经之路