Milvus:索引概述(十二)

一、索引概述
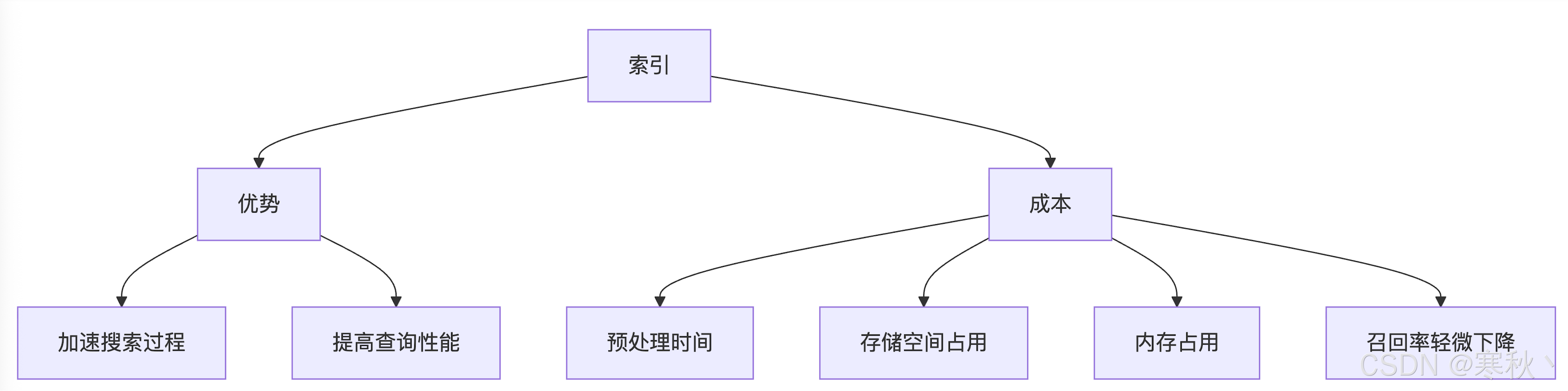
1.1 索引基本概念
- 预处理时间:构建索引需要额外消耗计算资源和时间,数据量越大、索引类型越复杂,耗时越长。
- 存储空间:索引本身需占用磁盘空间,量化类索引的空间开销较小,而原始向量索引(如 FLAT)开销与原始数据相当。
- 内存占用:搜索过程中,索引的核心部分需加载到内存(RAM)中,否则会因频繁磁盘 IO 导致查询延迟飙升。
- 召回率影响:近似索引会通过 “牺牲少量精度” 换取性能提升,这种损失通常在可接受范围内,但对精度敏感的场景需重点评估。
1.2 Milvus 索引特性
- 字段特异性:索引与数据字段一一绑定,例如为 FLOAT_VECTOR 类型字段构建 HNSW 索引,为 VARCHAR 类型字段构建反转索引,互不影响。
- 类型多样性:针对向量、标量、JSON 等不同数据类型,提供专属优化的索引类型,避免 “一刀切” 的性能瓶颈。
- 性能优化:聚焦向量搜索(核心场景)和标量过滤(辅助筛选)的协同优化,支持 “索引 + 过滤” 的高效查询组合。
二、数据类型与索引映射关系
2.1 向量数据类型索引
向量数据是 Milvus 的核心处理对象,不同向量类型的索引适配场景差异显著。
2.1.1 浮点向量
支持的向量类型包括 FLOAT_VECTOR(32 位浮点)、FLOAT16_VECTOR(16 位浮点)、bfloat16_vector(16 位脑浮点)、INT8_VECTOR(8 位整数量化向量),适用索引类型及场景如下:
索引类型 | 核心特点 | 适用场景 |
FLAT(平面索引) | 无压缩、无近似,召回率 100% | 小数据集(万级以内)、高精度需求 |
IVF_FLAT | 聚类分桶 + 原始向量存储 | 中大规模数据集、平衡性能与精度 |
IVF_SQ8 | 聚类分桶 + 标量量化(8 位) | 内存受限场景、追求高吞吐量 |
IVF_PQ | 聚类分桶 + 乘积量化 | 超大规模数据集、内存资源紧张 |
IVF_RABITQ | 增强型乘积量化,精度更优 | 内存受限且精度要求较高的场景 |
GPU_IVF_FLAT | 基于 GPU 加速的 IVF_FLAT | 大规模数据、高并发查询场景 |
GPU_IVF_PQ | 基于 GPU 加速的 IVF_PQ | 超大规模数据、GPU 资源充足 |
HNSW | 分层图结构,低延迟 | 高维向量、低延迟查询需求 |
DISKANN | 磁盘优化索引,内存占用极低 | 数据量超内存、稳定延迟需求 |
示例代码:为 FLOAT_VECTOR 字段构建 HNSW 索引
from pymilvus import connections, Collection, FieldSchema, CollectionSchema, DataType# 1. 连接 Milvus 服务
connections.connect("default", host="localhost", port="19530")# 2. 定义集合结构(含 FLOAT_VECTOR 字段)
fields = [FieldSchema(name="id", dtype=DataType.INT64, is_primary=True),FieldSchema(name="embedding", dtype=DataType.FLOAT_VECTOR, dim=128) # 128维浮点向量
]
schema = CollectionSchema(fields, description="示例集合")
collection = Collection(name="float_vector_collection", schema=schema)# 3. 定义 HNSW 索引参数并创建
index_params = {"index_type": "HNSW","metric_type": "L2", # 距离度量方式:L2(欧氏距离)、IP(内积)等"params": {"M": 16, # 每个向量的邻居数量,范围4-64,越大索引精度越高、构建耗时越长"efConstruction": 200 # 构建时的候选集大小,范围100-500,越大构建质量越高}
}
collection.create_index(field_name="embedding", index_params=index_params)2.1.2 二进制向量
- BIN_FLAT:无近似的二进制向量索引,召回率 100%,适用于小规模二进制向量数据集。
- BIN_IVF_FLAT:聚类分桶的二进制向量索引,适用于大规模二进制向量场景,查询速度远快于 BIN_FLAT。
# 定义二进制向量字段(dim 为向量维度)
fields = [FieldSchema(name="id", dtype=DataType.INT64, is_primary=True),FieldSchema(name="bin_embedding", dtype=DataType.BINARY_VECTOR, dim=256)
]
schema = CollectionSchema(fields, description="二进制向量集合")
collection = Collection(name="binary_vector_collection", schema=schema)# 定义 BIN_IVF_FLAT 索引参数
index_params = {"index_type": "BIN_IVF_FLAT","params": {"nlist": 1024 # 聚类分桶数量,建议为数据集大小的开平方(如100万数据设为1024)}
}
collection.create_index(field_name="bin_embedding", index_params=index_params)2.1.3 稀疏浮点向量
- MINHASH_LSH:基于局部敏感哈希的索引,适用于稀疏向量的快速去重和相似性搜索。
- 稀疏反转索引:通过记录非零元素的位置和值构建索引,大幅减少无效计算,提升查询效率。
2.2 标量数据类型索引
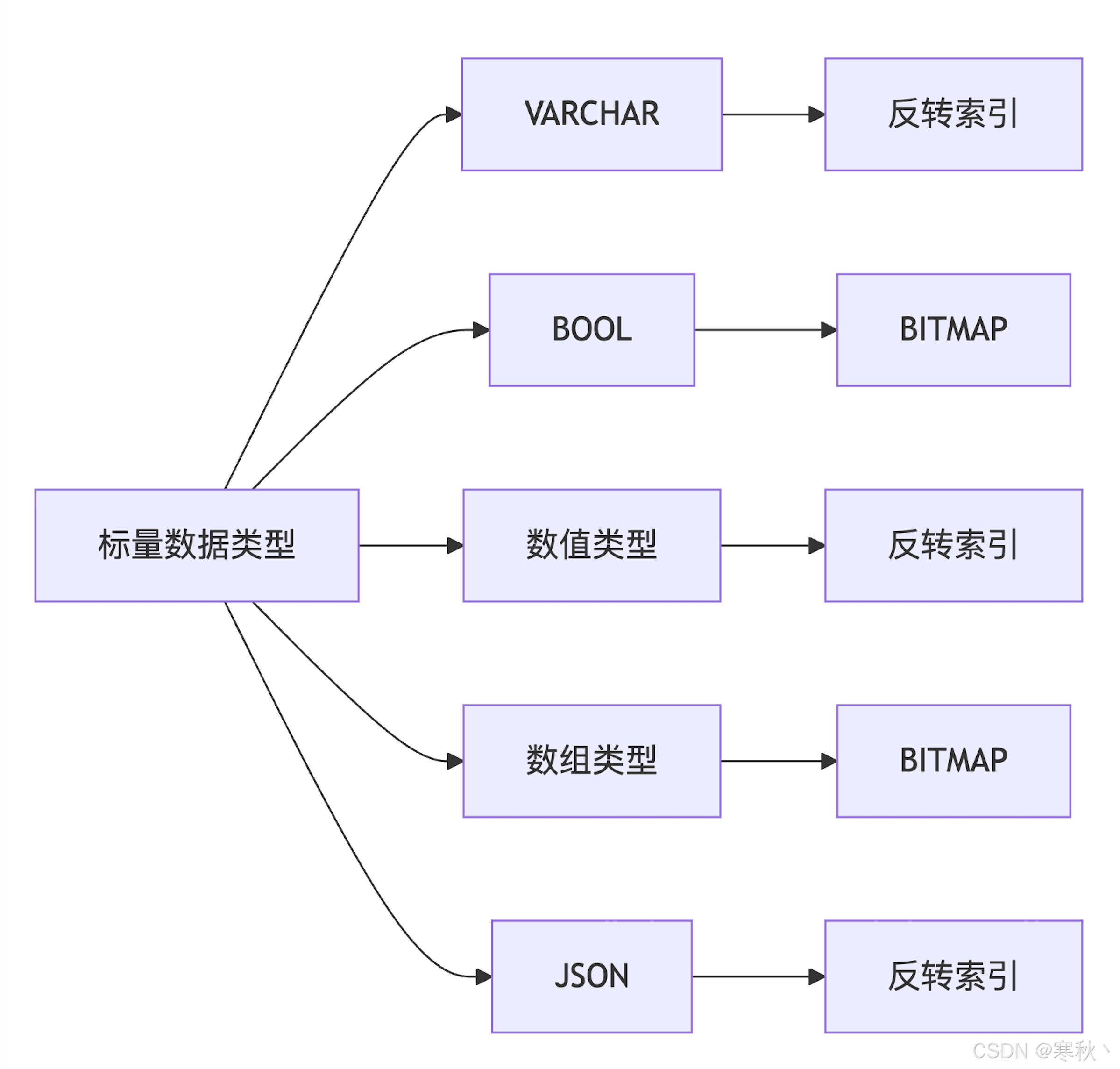
2.2.1 字符串类型(VARCHAR)
- 推荐索引:反转索引(默认推荐),支持模糊查询(如 like '%keyword%')、前缀查询(如 like 'prefix%'),查询效率高。
- 其他选项:BITMAP(适用于低基数字符串,如性别、类别标签)、Trie(适用于前缀匹配场景,如字典查询)。
fields = [FieldSchema(name="id", dtype=DataType.INT64, is_primary=True),FieldSchema(name="product_name", dtype=DataType.VARCHAR, max_length=100) # 字符串字段
]
schema = CollectionSchema(fields, description="商品集合")
collection = Collection(name="product_collection", schema=schema)# 定义反转索引参数(字符串字段默认索引类型为反转索引)
index_params = {"index_type": "INVERTED","params": {}
}
collection.create_index(field_name="product_name", index_params=index_params)# 示例查询:筛选商品名称包含"手机"的记录
collection.load()
query_expr = "product_name like '%手机%'"
results = collection.query(expr=query_expr, output_fields=["id", "product_name"])2.2.2 布尔类型(BOOL)
- 推荐索引:BITMAP(默认),适用于高并发的布尔过滤(如 where is_active = True),查询速度极快。
- 其他选项:反转索引,适用于布尔字段与其他标量字段的联合过滤场景。
2.2.3 数值类型
- 反转索引:支持范围查询(如 price between 100 and 200)、等值查询(如 category_id = 5),适配所有数值类型。
- STL_SORT:仅限整数类型,基于排序的索引,范围查询效率优于反转索引,但插入更新性能较差。
fields = [FieldSchema(name="id", dtype=DataType.INT64, is_primary=True),FieldSchema(name="category_id", dtype=DataType.INT64) # 整数类型字段
]
schema = CollectionSchema(fields, description="分类集合")
collection = Collection(name="category_collection", schema=schema)# 定义 STL_SORT 索引参数(仅支持整数类型)
index_params = {"index_type": "STL_SORT","params": {}
}
collection.create_index(field_name="category_id", index_params=index_params)# 示例查询:筛选 category_id 在 1-10 之间的记录
collection.load()
query_expr = "category_id in [1,2,3,4,5,6,7,8,9,10]"
results = collection.query(expr=query_expr, output_fields=["id", "category_id"])2.2.4 数组类型
- 推荐索引:BITMAP(适用于低基数数组元素,如标签数组 ["tag1", "tag2"])。
- 适用索引:反转索引(适用于高基数数组元素,如数值数组 [100, 200, 300])。
2.2.5 JSON 类型
fields = [FieldSchema(name="id", dtype=DataType.INT64, is_primary=True),FieldSchema(name="user_info", dtype=DataType.JSON) # JSON 字段
]
schema = CollectionSchema(fields, description="用户集合")
collection = Collection(name="user_collection", schema=schema)# 为 JSON 字段构建反转索引
index_params = {"index_type": "INVERTED","params": {}
}
collection.create_index(field_name="user_info", index_params=index_params)# 示例查询:筛选年龄大于 25 且城市为 Beijing 的用户
collection.load()
query_expr = 'json_extract(user_info, "$.user.age") > 25 and json_extract(user_info, "$.user.city") == "Beijing"'
results = collection.query(expr=query_expr, output_fields=["id", "user_info"])三、向量索引架构解析
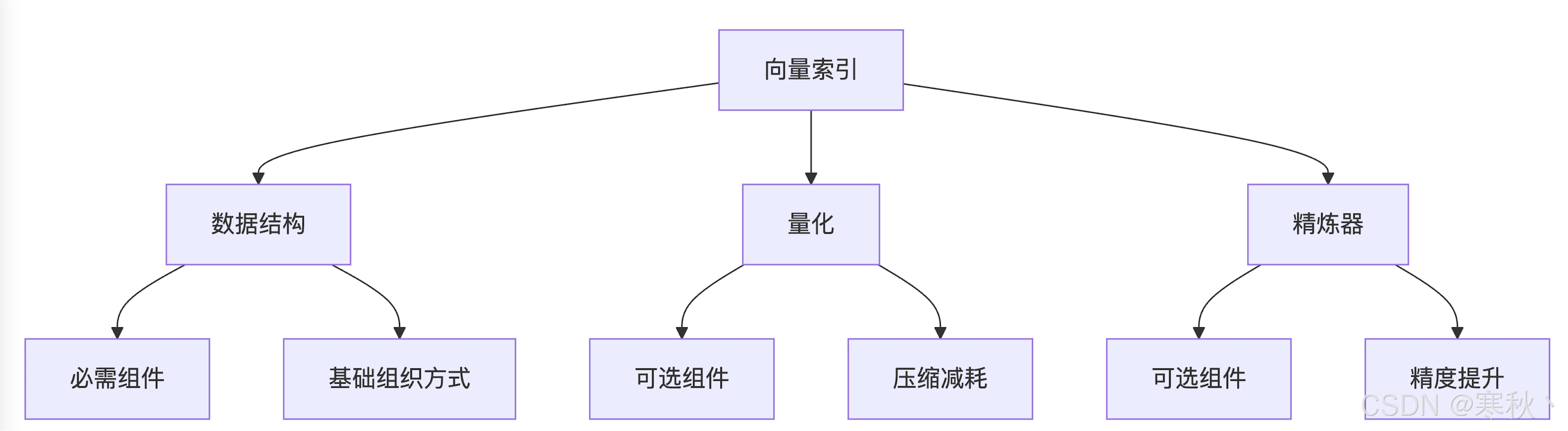
3.1 索引核心组件
Milvus 向量索引的架构采用 “模块化设计”,由三个核心部分组成,支持灵活组合以适配不同场景:
组件 | 必要性 | 核心作用 | 示例 |
数据结构 | 必需 | 定义向量的组织方式,决定搜索效率 | IVF 的 “聚类分桶”、HNSW 的 “分层图” |
量化 | 可选 | 压缩向量数据,降低内存 / 存储开销 | SQ8 的标量量化、PQ 的乘积量化 |
精炼器 | 可选 | 修正量化误差,提升召回率 | FP32 精炼器(用原始精度重算距离) |
3.2 索引工作流程
3.2.1 创建阶段
- 根据选定的索引类型,初始化对应的数据结构(如 IVF 的聚类分桶、HNSW 的分层图)。
- 若启用量化(如 IVF_PQ、HNSW-PQ),则训练量化模型(如 PQ 的编码本),并将原始向量压缩为量化后的数据。
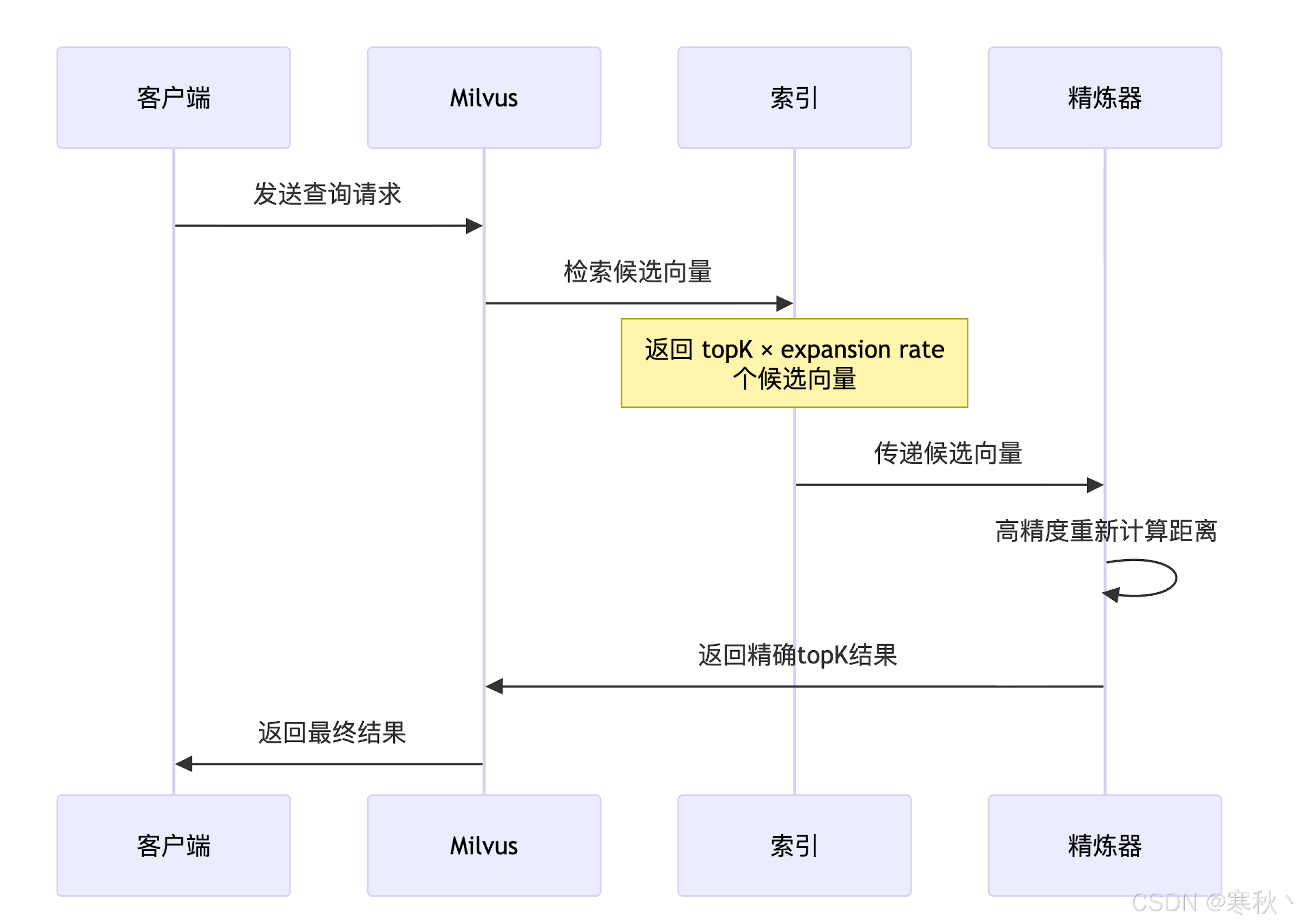
- 确定最佳扩展率(expansion rate),即候选集规模为 topK × expansion rate,用于平衡查询速度和召回率(默认值通常为 5,可手动调整)。
3.2.2 查询阶段
- 客户端发送查询请求(含查询向量、topK、过滤条件等参数)。
- Milvus 加载索引核心数据到内存,根据数据结构快速检索 topK × expansion rate 个候选向量(如 IVF 扫描邻近桶、HNSW 遍历分层图)。
- 若启用精炼器,对候选向量使用更高精度重新计算距离(如 FP32 精度),筛选出最精准的 topK 结果。
- 将最终结果返回给客户端。
四、索引数据结构详解
4.1 倒排文件(IVF)系列
4.1.1 工作原理
- 聚类分桶:构建索引时,使用 k-means 算法将所有向量聚类为 nlist 个桶(簇),每个桶有一个中心点向量。
- 索引存储:记录每个向量所属的桶 ID,以及桶内向量的存储位置(原始向量或量化向量)。
- 查询过程:
- 计算查询向量与所有桶中心点的距离,筛选出距离最近的 nprobe 个桶(nprobe 为查询参数,默认 10)。
- 仅遍历这 nprobe 个桶内的向量,计算与查询向量的距离。
- 排序后返回 topK 结果。
4.1.2 核心参数说明
参数名 | 作用 | 调整建议 |
nlist | 聚类分桶数量 | 建议为数据集大小的开平方(如 100 万数据设为 1024) |
nprobe | 查询时扫描的桶数量 | 越大召回率越高、速度越慢(默认 10,范围 1-nlist) |
4.1.3 适用场景
- 大规模数据集(百万级及以上),需要高吞吐量查询。
- 计算成本敏感的应用场景(如 CPU 资源有限)。
- 大 topK 搜索(topK > 2000),性能优于基于图的索引。
# 1. 构建 IVF_PQ 索引
index_params = {"index_type": "IVF_PQ","metric_type": "IP","params": {"nlist": 2048, # 分桶数量"m": 8, # PQ 子向量数量(需整除向量维度,如128维设为8则每个子向量16维)"nbits": 8, # 每个子向量的编码位数(通常为8,压缩率=32/nbits)"nprobe": 32 # 查询时扫描的桶数量(默认10,此处调高以提升召回率)}
}
collection.create_index(field_name="embedding", index_params=index_params)# 2. 加载集合并查询
collection.load()
query_vectors = [[0.1, 0.2, ..., 0.128]] # 128维查询向量
search_params = {"params": {"nprobe": 32} # 查询时的 nprobe 可覆盖索引构建时的参数
}
results = collection.search(data=query_vectors,anns_field="embedding",param=search_params,limit=10, # topK=10output_fields=["id"]
)4.2 基于图的结构(HNSW)
4.2.1 工作原理
- 分层图构建:
- 为每个向量构建多层邻居关系,上层为稀疏图(用于快速导航),下层为稠密图(用于精准筛选)。
- 构建时随机为每个向量分配一个层级,高层向量可覆盖更大范围的导航,低层向量聚焦局部精准匹配。
- 查询过程:
- 从最高层的一个随机节点开始,遍历其邻居节点,找到距离查询向量最近的节点,作为下一层的起始节点。
- 逐层向下遍历,直到最底层,最终筛选出距离最近的 topK 向量。
- 搜索复杂度为 O (log n),远低于 IVF 的 O (n/k)。
4.2.2 核心参数说明
参数名 | 作用 | 调整建议 |
M | 每个向量的邻居数量 | 范围 4-64,越大精度越高、构建耗时越长(默认 16) |
efConstruction | 构建时的候选集大小 | 范围 100-500,越大构建质量越高(默认 200) |
ef | 查询时的候选集大小 | 范围 10-1000,越大召回率越高、速度越慢(默认 100) |
4.2.3 适用场景
- 高维向量空间(如 512 维、1024 维向量),IVF 性能下降明显时。
- 低延迟查询需求(如实时推荐、在线检索,要求响应时间毫秒级)。
- 小 topK 搜索(topK < 2000),召回率和速度表现最优。
# 1. 构建 HNSW 索引(高维向量场景,如256维)
index_params = {"index_type": "HNSW","metric_type": "L2","params": {"M": 32, # 邻居数量增加,提升精度"efConstruction": 400 # 构建候选集增大,提升索引质量}
}
collection.create_index(field_name="embedding", index_params=index_params)# 2. 低延迟查询配置(ef 设为 50,平衡速度和精度)
collection.load()
query_vectors = [[0.05, 0.1, ..., 0.256]] # 256维查询向量
search_params = {"params": {"ef": 50} # ef 越小,查询速度越快
}
results = collection.search(data=query_vectors,anns_field="embedding",param=search_params,limit=20, # topK=20output_fields=["id"]
)4.3 两种结构对比
特性 | IVF 系列 | 基于图的结构(HNSW) |
数据结构 | 聚类分桶 | 分层导航图 |
搜索复杂度 | O (n/k)(k 为 nlist) | O(log n) |
内存占用 | 较低(支持量化压缩) | 较高(原始向量或轻量量化) |
构建时间 | 中等(聚类过程耗时) | 较长(分层图构建复杂) |
适用场景 | 大规模数据集、高吞吐量、大 topK | 高维空间、低延迟、小 topK |
召回率调整 | 通过 nprobe 调整(灵活) | 通过 ef 调整(灵活) |
五、量化技术
5.1 标量量化(SQ8)
5.1.1 工作原理
- 压缩过程:计算所有向量在每个维度上的最大值和最小值,将该维度的浮点值映射到 0-255 的整数区间。
- 解压过程:查询时将 8 位整数反向映射回浮点值,再计算距离。
5.1.2 核心特点
- 内存节省:相比原始 32 位浮点向量,减少 75% 内存使用(如 128 维向量从 512 字节压缩到 128 字节)。
- 精度损失:较小,适合对精度要求适中、内存受限的场景。
- 计算成本:低,压缩和解压过程简单,CPU 开销小。
5.1.3 适用场景
- 平衡型应用,既要控制内存开销,又不想大幅牺牲召回率。
- 中等规模数据集(百万级),CPU 资源有限。
5.2 乘积量化(PQ)
5.2.1 工作原理
- 向量分割:将原始向量分割为 m 个互不重叠的子向量(如 128 维向量分割为 8 个 16 维子向量)。
- 聚类编码:对每个子向量使用 k-means 算法聚类为 2^nbits 个簇,每个簇分配一个编码(码字)。
- 压缩存储:每个子向量用 nbits 位编码表示,整个向量的编码长度为 m×nbits 位。
5.2.2 核心参数说明
参数名 | 作用 | 调整建议 |
m | 子向量数量 | 需整除向量维度(如 128 维设为 8、16) |
nbits | 每个子向量的编码位数 | 通常为 8(256 个簇),支持 4-16 |
5.2.3 核心特点
- 压缩率:灵活可调,4:1 到 32:1(如 m=8、nbits=8 时压缩率为 4:1;m=16、nbits=4 时压缩率为 8:1)。
- 内存节省:75% - 97%,压缩率远高于 SQ8。
- 精度损失:中等,压缩率越高,精度损失越大。
- 计算成本:中等,子向量聚类和编码过程比 SQ8 复杂。
5.2.4 适用场景
- 内存敏感环境(如内存不足以存储原始向量或 SQ8 压缩向量)。
- 超大规模数据集(千万级及以上),需控制索引内存开销。
5.3 两种量化技术对比
指标 | 标量量化(SQ8) | 乘积量化(PQ) |
压缩率 | 固定 4:1 | 4:1 到 32:1(可调) |
内存节省 | 75% | 75% - 97% |
精度损失 | 较小 | 中等 |
计算成本 | 低 | 中等 |
适用场景 | 平衡型应用 | 内存敏感环境 |
示例代码:量化索引性能对比测试
import time
import numpy as np# 生成测试数据(100万条128维向量)
n_data = 1000000
dim = 128
vectors = np.random.randn(n_data, dim).astype(np.float32)
ids = np.arange(n_data).astype(np.int64)# 定义集合(省略字段和 schema 定义,同前)
collection = Collection(name="quantization_test", schema=schema)# 插入数据
collection.insert([ids, vectors])# 1. 构建 IVF_SQ8 索引并测试
sq8_index_params = {"index_type": "IVF_SQ8","metric_type": "L2","params": {"nlist": 1024}
}
collection.create_index("embedding", sq8_index_params)
collection.load()# 测试查询速度
query_vectors = np.random.randn(10, dim).astype(np.float32) # 10个查询向量
start_time = time.time()
sq8_results = collection.search(data=query_vectors, anns_field="embedding", param={"params": {"nprobe": 20}}, limit=10)
sq8_time = time.time() - start_time
print(f"IVF_SQ8 查询耗时:{sq8_time:.4f}s")# 2. 构建 IVF_PQ 索引并测试
collection.drop_index("embedding") # 删除原有索引
pq_index_params = {"index_type": "IVF_PQ","metric_type": "L2","params": {"nlist": 1024, "m": 8, "nbits": 8}
}
collection.create_index("embedding", pq_index_params)start_time = time.time()
pq_results = collection.search(data=query_vectors, anns_field="embedding", param={"params": {"nprobe": 20}}, limit=10)
pq_time = time.time() - start_time
print(f"IVF_PQ 查询耗时:{pq_time:.4f}s")# 对比召回率(以 FLAT 索引为基准)
collection.drop_index("embedding")
flat_index_params = {"index_type": "FLAT", "metric_type": "L2"}
collection.create_index("embedding", flat_index_params)
flat_results = collection.search(data=query_vectors, anns_field="embedding", param={}, limit=10)# 计算召回率(简化计算:交集数量/FLAT结果数量)
def calculate_recall(approx_results, flat_results):recall_sum = 0.0for approx_res, flat_res in zip(approx_results, flat_results):approx_ids = set([hit.id for hit in approx_res])flat_ids = set([hit.id for hit in flat_res])intersection = approx_ids & flat_idsrecall_sum += len(intersection) / len(flat_ids)return recall_sum / len(query_vectors)sq8_recall = calculate_recall(sq8_results, flat_results)
pq_recall = calculate_recall(pq_results, flat_results)
print(f"IVF_SQ8 召回率:{sq8_recall:.4f}")
print(f"IVF_PQ 召回率:{pq_recall:.4f}")六、精炼器机制
6.1 作用原理
- 量化索引检索出 topK × expansion rate 个候选向量后,精炼器对这些候选向量使用更高精度(如 FP32)重新计算距离。
- 过滤掉因量化误差导致的 “伪近邻” 向量,保留真正距离最近的 topK 结果,从而提升召回率。
6.2 常用精炼器:FP32 精炼器
- 索引检索阶段:量化索引返回 topK × expansion rate 个候选向量(量化形式或原始形式)。
- 精炼阶段:加载候选向量的原始 FP32 精度数据,重新计算与查询向量的距离。
- 结果筛选:根据重新计算的距离排序,返回 topK 结果。
6.3 适用场景
- 搜索效率和精度需要权衡的应用(如既想使用量化索引节省内存,又不想牺牲过多召回率)。
- 语义搜索、推荐系统等对结果质量敏感的场景(召回率直接影响用户体验)。
# 构建 IVF_PQ 索引并启用 FP32 精炼器
index_params = {"index_type": "IVF_PQ","metric_type": "IP","params": {"nlist": 2048,"m": 8,"nbits": 8,"refiner_type": "FP32", # 启用 FP32 精炼器"expansion_rate": 10 # 候选集规模 = topK × 10(默认5,调高提升召回率)}
}
collection.create_index(field_name="embedding", index_params=index_params)# 查询时自动触发精炼器
collection.load()
results = collection.search(data=query_vectors,anns_field="embedding",param={"params": {"nprobe": 32}},limit=10
)七、性能权衡分析
7.1 关键性能指标
7.1.1 构建时间
- 定义:从索引创建请求发起,到索引构建完成的总时间。
- 影响因素:数据量、索引类型、量化参数、硬件性能(CPU/GPU)。
- 对比:FLAT 索引构建时间最短(仅需存储原始向量);HNSW 索引构建时间最长(分层图构建复杂);IVF 系列居中(聚类分桶耗时)。
7.1.2 QPS(每秒查询次数)
- 定义:单位时间内可处理的查询请求数量,反映系统吞吐量。
- 对比:
- 基于图的索引(HNSW):小 topK 场景下 QPS 通常优于 IVF 变体。
- IVF 变体:大 topK 场景(topK > 2000)下 QPS 更高(聚类分桶可减少无效计算)。
- GPU 加速索引(GPU_IVF_FLAT):QPS 远高于 CPU 版本,适合高并发场景。
7.1.3 召回率
- 定义:查询结果中真正相关的向量占所有相关向量的比例,反映结果准确性。
- 对比:
- FLAT 索引:召回率 100%(无近似)。
- PQ vs SQ8:相同压缩率下,PQ 召回率通常更高,但计算成本略高。
- 精炼器:启用后可提升召回率 5%-15%,但会增加少量查询延迟。
7.2 容量考虑
7.2.1 内存适配策略
- 1/4 数据适合内存:考虑使用 DiskANN 索引,数据主要存储在磁盘 / SSD,内存仅加载索引元数据,延迟稳定。
- 全部数据适合内存:优先选择基于内存的索引(HNSW、IVF_FLAT),搭配 mmap 技术(内存映射文件),平衡内存使用和查询速度。
- 内存极度受限:使用 IVF_PQ 索引,通过高压缩率换取最大容量,必要时启用精炼器补偿精度。
7.2.2 磁盘使用
- DiskANN 优势:当大部分数据无法装入内存时,DiskANN 通过磁盘优化的索引结构,提供比 mmap 更稳定的查询延迟。
- mmap 限制:mmap 依赖操作系统的页面缓存,当数据量超过内存时,会频繁触发页面置换,导致延迟波动。
八、召回率优化策略
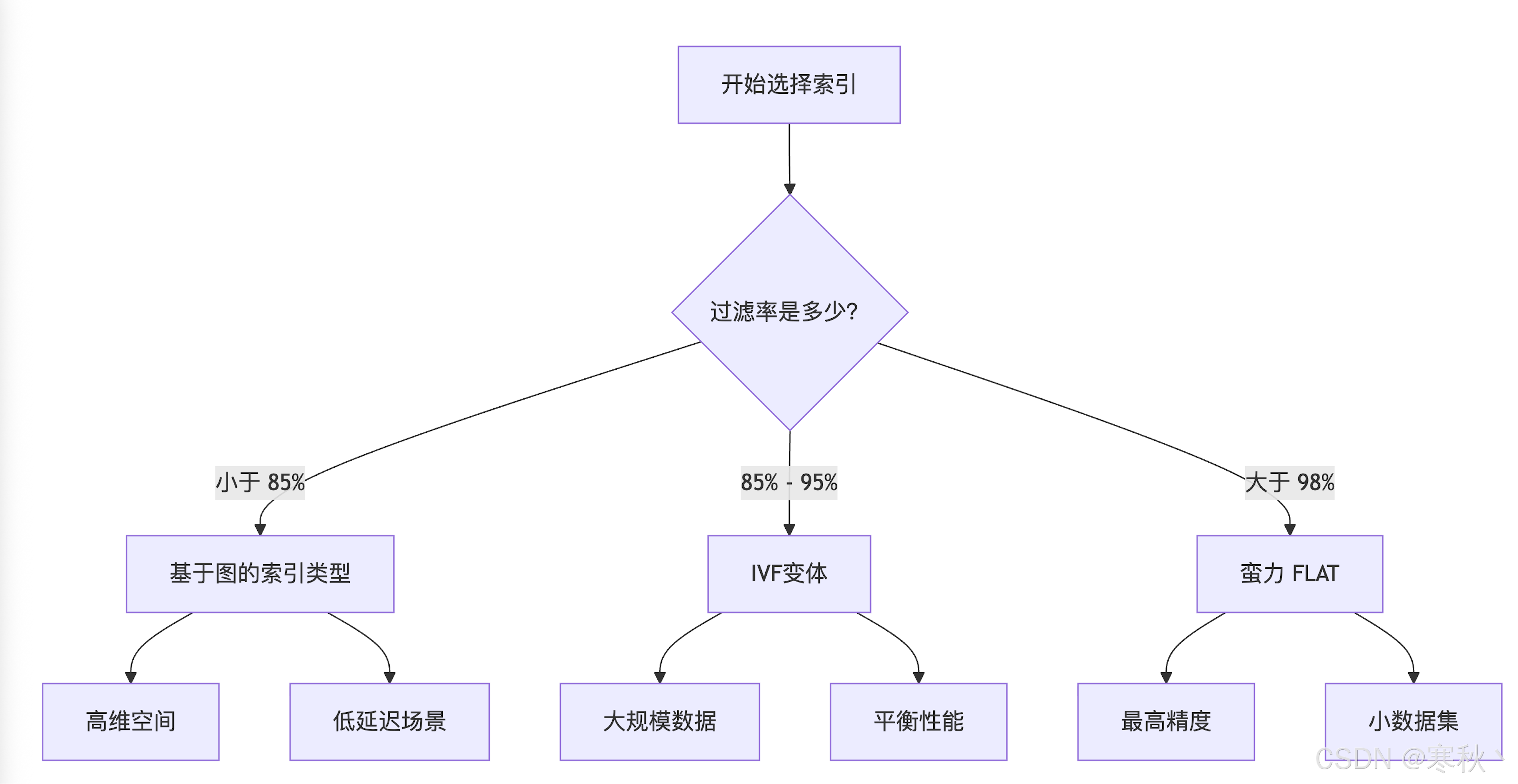
8.1 过滤率与索引选择
过滤率(Filter Rate)是指查询中符合过滤条件的向量占总向量的比例,直接影响索引性能,推荐匹配关系如下:
过滤率范围 | 推荐索引类型 | 说明 |
< 85% | 基于图的索引(HNSW) | 过滤后有效数据量少,低延迟优势明显 |
85% - 95% | IVF 变体(IVF_FLAT) | 平衡性能与召回率,性价比最高 |
> 98% | 蛮力(FLAT) | 过滤后数据量接近全量,索引优势不明显,直接遍历更高效 |
8.2 搜索性能与 Top-K
8.2.1 小 Top-K 搜索(topK ≤ 2000)
- 需求:高召回率、低延迟。
- 推荐:HNSW 索引,其分层图结构可快速定位近邻向量,性能优于 IVF 系列。
- 优化:适当调高 ef 参数(如 100→200),提升召回率。
8.2.2 大 Top-K 搜索(topK > 2000)
- 需求:高吞吐量、稳定性能。
- 推荐:IVF 变体(IVF_FLAT、IVF_SQ8),聚类分桶可减少需遍历的向量数量,避免 HNSW 大 topK 场景下的性能下降。
- 优化:调高 nprobe 参数(如 10→50),确保召回率。
8.2.3 中等 Top-K + 高过滤率
- 需求:平衡召回率、延迟、吞吐量。
- 推荐:IVF 变体,高过滤率下有效数据量减少,IVF 的聚类分桶优势依然存在,且构建成本低于 HNSW。
九、决策矩阵:索引类型选择指南
场景描述 | 推荐索引类型 | 核心优化点 |
原始数据适合内存,低延迟 / 高召回率 | HNSW + 可选精炼器 | 分层图结构实现低延迟,精炼器提升精度 |
数据存储在磁盘 / SSD,延迟敏感 | DiskANN | 磁盘优化索引,延迟稳定 |
磁盘数据,有限 RAM | IVF_PQ/SQ8 + 高过滤率(>95%) | 量化压缩节省内存,高过滤率提升效率 |
极高召回率(>99%) | FLAT + 可选 GPU | 无近似保证精度,GPU 加速提升速度 |
大 topK(≥数据集的 1%) | IVF 系列(IVF_FLAT) | 簇剪枝减少计算量,提升吞吐量 |
十、内存使用估算
10.1 IVF 索引内存使用计算
10.1.1 基础计算
- 中心点内存:nlist × dim × 4 bytes(4 bytes 为 float 类型占用空间)。示例:2000 个簇 × 128 维 × 4 bytes = 1.0 MB。
- 簇分配内存:n_data × 2 bytes(每个向量用 2 bytes 存储簇 ID)。示例:100 万向量 × 2 bytes = 2.0 MB。
- 量化压缩内存:
- PQ(8 个子量化器):n_data × m bytes(m 为子向量数量,每个子向量编码占 1 byte)。示例:100 万向量 × 8 bytes = 8.0 MB。
- SQ8:n_data × dim × 1 byte(每个维度压缩为 1 byte)。示例:100 万向量 × 128 维 × 1 byte = 128 MB。
- IVF_FLAT(无量化):n_data × dim × 4 bytes(原始向量存储)。示例:100 万向量 × 128 维 × 4 bytes = 512 MB。
10.1.2 不同配置内存估算
配置 | 各部分内存占用 | 总内存 |
IVF-PQ(无精炼) | 1.0 MB + 2.0 MB + 8.0 MB | 11.0 MB |
IVF-PQ + 10% 精炼 | 1.0 MB + 2.0 MB + 8.0 MB + 51.2 MB | 62.2 MB |
IVF-SQ8(无精炼) | 1.0 MB + 2.0 MB + 128 MB | 131.0 MB |
IVF-FLAT(全原始) | 1.0 MB + 2.0 MB + 512 MB | 515.0 MB |
10.1.3 精炼开销计算
10.2 基于图的索引内存使用
10.2.1 基础计算
- 图结构内存:n_data × M × 4 bytes(M 为每个向量的邻居数量,4 bytes 存储邻居 ID)。示例:100 万向量 × 32 个邻居 × 4 bytes = 128 MB。
- 原始向量内存:n_data × dim × 4 bytes。示例:100 万向量 × 128 维 × 4 bytes = 512 MB。
- 总内存:128 MB + 512 MB = 640 MB。
10.2.2 量化压缩效果(HNSW-PQ)
- PQ 压缩内存:n_data × m bytes(m=8 个子量化器)。示例:100 万向量 × 8 bytes = 8 MB。
- HNSW-PQ 总内存:128 MB + 8 MB = 136 MB(压缩率约 64 倍)。
10.2.3 精炼开销
十一、总结与最佳实践
11.1 索引选择核心原则
- 明确需求:优先确定核心指标(如召回率≥95%、延迟≤100ms),再选择索引类型。
- 数据规模:小规模(万级)选 FLAT,中大规模(百万级)选 IVF 系列,超大规模(千万级)选 IVF_PQ/DiskANN。
- 查询模式:小 topK 低延迟选 HNSW,大 topK 高吞吐量选 IVF,高过滤率选 IVF 或 FLAT。
- 实验验证:通过基准测试(如测试不同索引的构建时间、QPS、召回率),确定最优配置。
11.2 性能优化建议
- 内存优化:合理使用量化(SQ8/PQ)和 mmap 技术,避免内存溢出。
- 磁盘利用:超大规模数据优先考虑 DiskANN,避免 mmap 导致的延迟波动。
- 精度平衡:量化索引搭配精炼器,在内存开销和召回率间找到平衡点。
- 硬件利用:GPU 资源充足时,使用 GPU 加速索引(GPU_IVF_FLAT),大幅提升吞吐量。