rag-mcp
AI-RAG实例实现
RAG 检索增强生效
概念
首先应该是到底什么是rag,在我看来,实际上就是我们在向ai提问的时候受到字数的限制,无法将所有的内容全部提交给ai,所以我们需要把我们需要的内容提取出来,将这部分内容提交给ai,获得更准确的回答,换个切实的场景,如果我们有一个项目,现在你有很多的建表语句进行了储存,但是你现在需要其中一张比表的实体类,rag的思想可以帮助你不需要自己求查询数据创建实体类,他会自己对项目进行扫描,找到我们需要的内容
实现流程
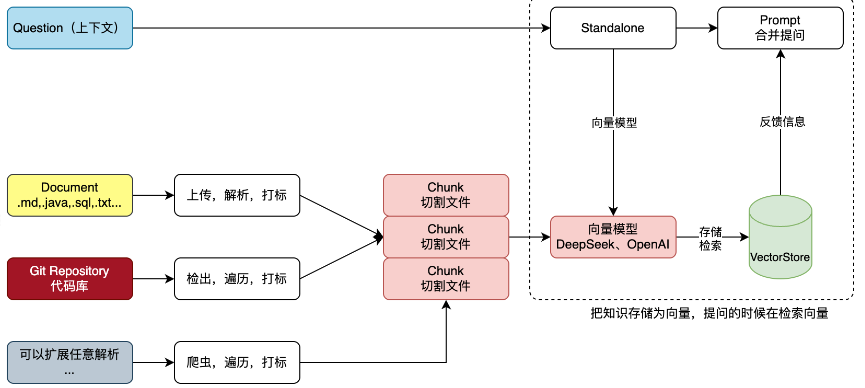
代码实现
我们来直接基于代码实现两个简单的知识库的上传
本地文件
package com.asom.dev.tech.app.test;import com.alibaba.fastjson.JSON;
import jakarta.annotation.Resource;
import lombok.extern.slf4j.Slf4j;
import org.junit.Test;
import org.junit.runner.RunWith;
import org.springframework.ai.chat.ChatResponse;
import org.springframework.ai.chat.messages.Message;
import org.springframework.ai.chat.messages.UserMessage;
import org.springframework.ai.chat.prompt.Prompt;
import org.springframework.ai.chat.prompt.SystemPromptTemplate;
import org.springframework.ai.document.Document;
import org.springframework.ai.ollama.OllamaChatClient;
import org.springframework.ai.ollama.api.OllamaOptions;
import org.springframework.ai.reader.tika.TikaDocumentReader;
import org.springframework.ai.transformer.splitter.TokenTextSplitter;
import org.springframework.ai.vectorstore.PgVectorStore;
import org.springframework.ai.vectorstore.SearchRequest;
import org.springframework.ai.vectorstore.SimpleVectorStore;
import org.springframework.boot.test.context.SpringBootTest;
import org.springframework.test.context.junit4.SpringRunner;import java.util.ArrayList;
import java.util.List;
import java.util.Map;
import java.util.stream.Collectors;@Slf4j
@RunWith(SpringRunner.class)
@SpringBootTest
public class RAGTest {@Resourceprivate OllamaChatClient chatClient;@Resourceprivate TokenTextSplitter tokenTextSplitter;@Resourceprivate SimpleVectorStore simpleVectorStore;@Resourceprivate PgVectorStore pgVectorStore;@Test
// 上传文件public void upload(){// 创建一个 TikaDocumentReader 对象,用于读取文件TikaDocumentReader reader = new TikaDocumentReader("data/test02.txt");// 获取文件List<Document> documents = reader.get();// 分词,可以认为就是切割词汇,防止过大List<Document> documentList = tokenTextSplitter.apply(documents);//打上标签documentList.forEach(document -> document.getMetadata().put("knowledge", "知识库名称"));documents.forEach(document -> document.getMetadata().put("knowledge", "知识库名称"));// 保存pgVectorStore.accept(documentList);log.info("上传成功");}@Testpublic void query(){String message ="书籍haha的作者是";String SYSTEM_PROMPT = """Use the information from the DOCUMENTS section to provide accurate answers but act as if you knew this information innately.If unsure, simply state that you don't know.Another thing you need to note is that your reply must be in Chinese!DOCUMENTS:{documents}""";//指定文档SearchRequest request =SearchRequest.query(message).withTopK(10). // 指定返回的文档数量withFilterExpression("knowledge == '知识库名称'"); // 指定过滤条件List<Document> documents = pgVectorStore.similaritySearch(request);// 将文档内容拼接成字符串String documentCollectors = documents.stream().map(Document::getContent).collect(Collectors.joining());Message ragMessage = new SystemPromptTemplate(SYSTEM_PROMPT).createMessage(Map.of("documents", documentCollectors));List<Message> messages = new ArrayList<>();messages.add(new UserMessage(message));messages.add(ragMessage);ChatResponse chatResponse = chatClient.call(new Prompt(messages,OllamaOptions.create().withModel("deepseek-r1:1.5b")));log.info("测试结果:{}", JSON.toJSONString(chatResponse));}}先来说一下具体的流程
写入
1.读入文件
2.将文件进行切割,因为如果文件过大的话,那就相当于你提问的数据比较大了
3.将数据打赏标签,基于postgresql数据库,我们在进行数据存储的时候,通过 pgVectorStore 存储的是经过向量化处理的数据,而非原始文本内容。Spring AI 框架自动完成了文本分块、向量化及存储的全流程
4.将数据存入,当然在这个时候,我们也可以将标签存入到redis中做一个记录
查询
1.选择你存入的知识库的名称,实际上就是postgressql里面的标签
2.进行向量相似度查询,在这里,数据被存储成向量,然后进行相似度查询
3.进行数据的转化处理,然后对ai进行问答即可
git文件
git文件与本地文件类似,代码如下
package com.asom.dev.tech.app.test;
import com.alibaba.fastjson.JSON;
import jakarta.annotation.Resource;
import lombok.extern.slf4j.Slf4j;
import org.apache.commons.io.FileUtils;
import org.eclipse.jgit.api.Git;
import org.eclipse.jgit.transport.UsernamePasswordCredentialsProvider;
import org.junit.Test;
import org.junit.runner.RunWith;
import org.springframework.ai.chat.ChatResponse;
import org.springframework.ai.chat.messages.Message;
import org.springframework.ai.chat.messages.UserMessage;
import org.springframework.ai.chat.prompt.Prompt;
import org.springframework.ai.chat.prompt.SystemPromptTemplate;
import org.springframework.ai.document.Document;
import org.springframework.ai.ollama.OllamaChatClient;
import org.springframework.ai.ollama.api.OllamaOptions;
import org.springframework.ai.reader.tika.TikaDocumentReader;
import org.springframework.ai.transformer.splitter.TokenTextSplitter;
import org.springframework.ai.vectorstore.PgVectorStore;
import org.springframework.ai.vectorstore.SearchRequest;
import org.springframework.ai.vectorstore.SimpleVectorStore;
import org.springframework.boot.test.context.SpringBootTest;
import org.springframework.core.io.PathResource;
import org.springframework.test.context.junit4.SpringRunner;import java.io.File;
import java.io.IOException;
import java.nio.file.*;
import java.nio.file.attribute.BasicFileAttributes;
import java.util.ArrayList;
import java.util.List;
import java.util.Map;
import java.util.stream.Collectors;@Slf4j
@RunWith(SpringRunner.class)
@SpringBootTest
public class IGitTest {@Resourceprivate OllamaChatClient chatClient;@Resourceprivate TokenTextSplitter tokenTextSplitter;@Resourceprivate SimpleVectorStore simpleVectorStore;@Resourceprivate PgVectorStore pgVectorStore;//把git仓库下载到本地的文件夹@Testpublic void uploadGit() throws Exception{String localPath ="./git-clone-repo";FileUtils.deleteDirectory(new File(localPath));Git git = Git.cloneRepository().setURI("https://gitee.com///").setDirectory(new File(localPath)).setCredentialsProvider(new UsernamePasswordCredentialsProvider("", "")).call();git.close();}@Testpublic void query() throws IOException {//上传到知识库当中,打上标记Files.walkFileTree(Paths.get("./git-clone-repo"),new SimpleFileVisitor<>(){@Overridepublic FileVisitResult visitFile(Path file, BasicFileAttributes attrs) throws IOException {log.info("{} 遍历解析路径,上传知识库:{}", "xxxx", file.getFileName());try {TikaDocumentReader reader = new TikaDocumentReader(new PathResource(file));List<Document> documents = reader.get();List<Document> documentSplitterList = tokenTextSplitter.apply(documents);documents.forEach(doc -> doc.getMetadata().put("knowledge", "xxxx"));documentSplitterList.forEach(doc -> doc.getMetadata().put("knowledge", "xxxx"));pgVectorStore.accept(documentSplitterList);} catch (Exception e) {log.error("遍历解析路径,上传知识库失败:{}", file.getFileName());}return FileVisitResult.CONTINUE;}@Overridepublic FileVisitResult visitFileFailed(Path file, IOException exc) throws IOException {log.info("Failed to access file: {} - {}", file.toString(), exc.getMessage());return FileVisitResult.CONTINUE;}});}
}向量模型,向量
在自然语言处理(NLP)和人工智能领域,文本嵌入模型(Embedding Model) 是将文本转换为高维向量的核心技术。以text-embedding-ada-002 为例,其核心作用是为文本生成语义密集的数值表示,使计算机能够理解文本的深层含义
实际上以白话而言,就是将我们认为的数据转化为计算机可以理解的内容,将数据转化为向量的形式,
在自然语言处理(NLP)和人工智能领域,文本嵌入模型(Embedding Model) 是将文本转换为高维向量的核心技术。以text-embedding-ada-002 为例,其核心作用是为文本生成语义密集的数值表示,使计算机能够理解文本的深层含义
实际上以白话而言,就是将我们认为的数据转化为计算机可以理解的内容,将数据转化为向量的形式,
例如,我们假设猫在(1,1.1) 猫咪在(1,1.2) 狗在(1,1.9),这里实际上就是把数据转换成了向量,在进行相似度查询的时候就能够根据猫咪查询到猫,而不是狗