基于大语言模型(LLM)的多智能体应用的新型服务框架——Tokencake
面向基于大语言模型(LLM)的多智能体应用的新型服务框架——Tokencake。其核心目标是优化多智能体场景下 KV Cache 的管理效率,从而显著提升系统性能与资源利用率。
一、问题背景
在多智能体应用(如协作编程、深度研究等)中,多个智能体并发执行,并频繁调用外部工具(如代码执行、搜索等)。这带来两大 KV Cache 管理挑战:
- 空间竞争:关键智能体的缓存可能被低优先级任务挤出 GPU 内存。
- 时间浪费:智能体在等待外部函数返回时,其 KV Cache 长时间闲置,却仍占用宝贵 GPU 显存。
二、Tokencake 核心设计
Tokencake 从时间和空间两个维度协同优化 KV Cache 生命周期,包含三大组件:
1. 前端 API
- 将用户定义的多智能体工作流(如 RAG)转化为可调度的计算图,供调度器使用。
2. 空间调度器(Spatial Scheduler)
- 采用动态内存分区策略,将 GPU KV Cache 划分为:
- 全局共享池:供所有智能体使用;
- 预留池:仅分配给当前“关键智能体”。
- 关键智能体由混合优先级得分(结合历史内存使用量与任务重要性)动态决定。
- 预留池容量随系统内存压力自适应调整,兼顾保护性与资源利用率。
3. 时间调度器(Temporal Scheduler)
- 在智能体因外部调用阻塞时,主动将其 KV Cache 卸载到 CPU 内存;
- 基于函数调用时长预测,在预计恢复前提前预加载回 GPU;
- 仅当卸载收益 > 数据传输开销时才执行,避免无效操作。
优化细节:
- CPU 块缓冲区:避免频繁系统调用,将内存分配延迟从秒级降至亚毫秒级;
- 渐进式 GPU 内存预留:提前分批预留上传所需显存,防止加载时阻塞。
三、实验评估
- 测试应用:Code-Writer(代码生成)、Deep Research(深度调研);
- 数据集:ShareGPT + AgentCode,请求按泊松分布模拟真实负载;
- 对比基线:vLLM、LightLLM 等主流推理框架。
关键结果:
- 端到端延迟降低 ≥47.06%(在 1.0 QPS 高负载下);
- GPU KV Cache 利用率最高提升 16.9%;
- 在高并发下仍保持稳定性能,而其他系统(如 LightLLM)表现不佳。
注:文中图表将 Tokencake 标记为 “SunCake”,系同一系统。
四、总结
Tokencake 是首个以 KV Cache 为中心、专为 LLM 多智能体应用 设计的服务框架。通过智能体感知的空间分区与预测驱动的时间卸载/加载机制,有效解决了多智能体场景下的资源争用与缓存闲置问题,在真实负载下显著优于现有系统。
原文:
大型语言模型(LLM)正越来越多地应用于需要外部函数调用的复杂多智能体场景中。这类工作负载给KV Cache带来了严峻的性能挑战:空间竞争会导致关键智能体的缓存被驱逐,而时间利用率低下使得运行工具调用等待期间,停滞的智能体缓存长时间闲置于GPU内存中。
针对上述挑战,北京航空航天大学联合北京大学、阿里的研究者提出了一种以KV Cache为中心的多智能体应用服务框架Tokencake,通过智能体感知设计协同优化调度与内存管理。其中,空间调度器采用动态内存分区机制保护关键智能体免受资源争用影响,时间调度器则通过主动卸载与预测性加载策略,在函数调用阻塞期间重新配置GPU内存。在典型多智能体基准测试中,Tokencake相较于vLLM可将端到端延迟降低47.06%以上,并使GPU内存有效利用率提升16.9%。

论文标题:
Tokencake: A KV-Cache-centric Serving Frameworkfor LLM-based Multi-Agent Applications
论文链接:
https://arxiv.org/pdf/2510.18586
01
方法
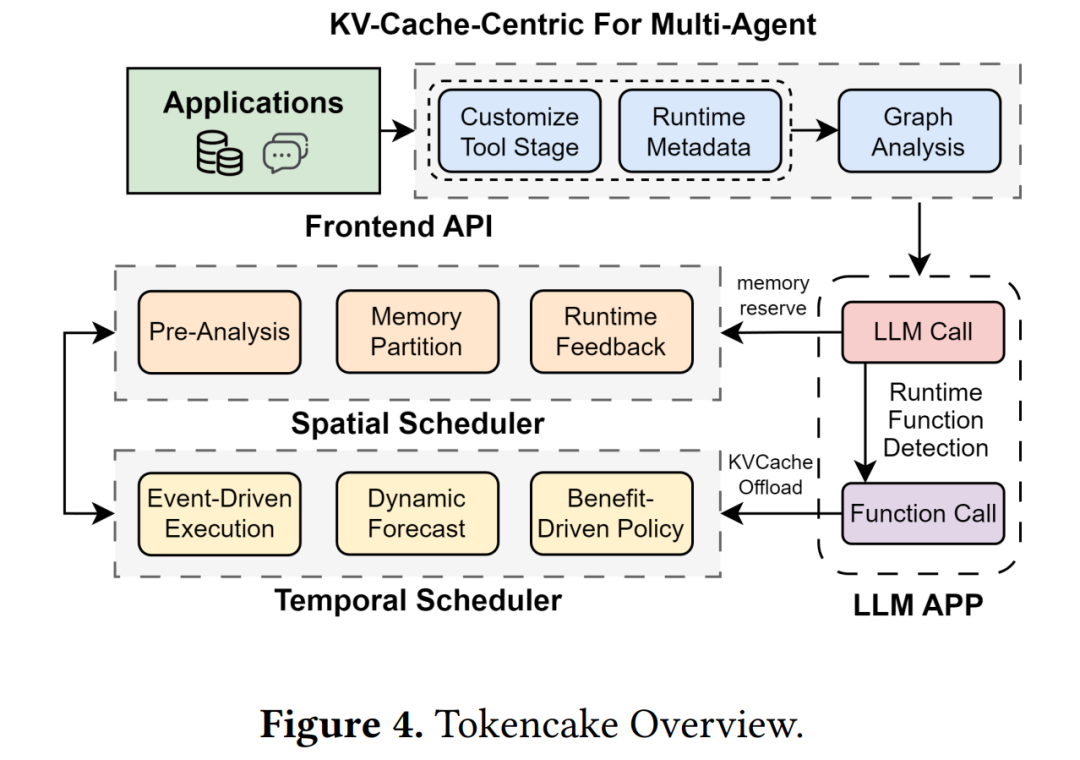
Tokencake 旨在通过从时间和空间两个维度管理KV Cache资源,以优化多智能体应用的性能。图4展示了Tokencake的架构,包含三个核心组件:前端API、空间调度器和时间调度器。这些组件协同工作,共同管理GPU内存中KV Cache块的整个生命周期。
前端 API 将用户定义的应用逻辑转换为一个可优化的图结构。图5展示了如何使用该API构建一个简单的RAG应用。该图结构随后被两个专用调度器所使用。

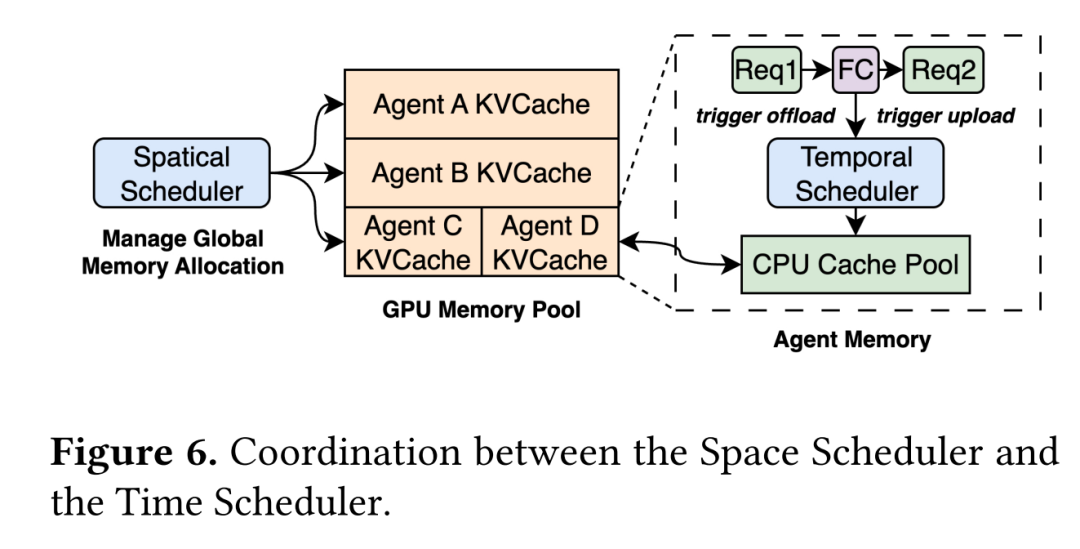
图6展示了空间调度器与时间调度器之间的紧密协作。空间调度器负责管理不同智能体之间全局内存的分配,时间调度器则处理单个智能体请求随时间变化的内存生命周期。它们协调工作最为关键的地方在于两者策略的交汇点。
时间调度器致力于最大化 KV Cache 利用率,在智能体执行长时间的外部操作(例如函数调用)期间,将其 KV Cache 卸载到 CPU 内存中,并根据对外部调用执行时间的预估,在下次使用前将其预测性传回GPU。
只有当释放GPU资源带来的预期收益超过数据传输成本时才会启动卸载操作,需要实时分析预测函数调用时长、KV Cache大小、等待请求队列状态等多个动态因素。时间调度器的决策逻辑如算法1所示。

尽管 Tokencake 的主动卸载与上传机制是其性能的核心,但CPU同时分配或释放大量内存块操作可能引入显著的延迟,从而影响主调度循环。为减轻这种延迟,研究团队引入了两项针对性的优化:
研究团队实现了一个专用的CPU块缓冲区。Tokencake 不再将内存块释放回操作系统,而是将其返回到一个轻量级的内部空闲列表。后续的卸载操作会优先从此缓冲区中满足其分配请求,从而规避关键路径上的高成本系统调用。这一设计使得大型卸载操作的内存管理延迟从最坏情况下的近秒级降至稳定的亚毫秒级。
Tokencake 利用预测模型执行渐进式内存块预留,基于函数调用预计完成时间,调度器会在上传操作启动前的多个调度周期内开始逐步预留所需的 GPU 内存块。这种方法通过将一次大的分配请求分解为一系列小请求,确保预测上传触发时目标内存块已就绪,从而避免分配阻塞并大幅提升操作可靠性。
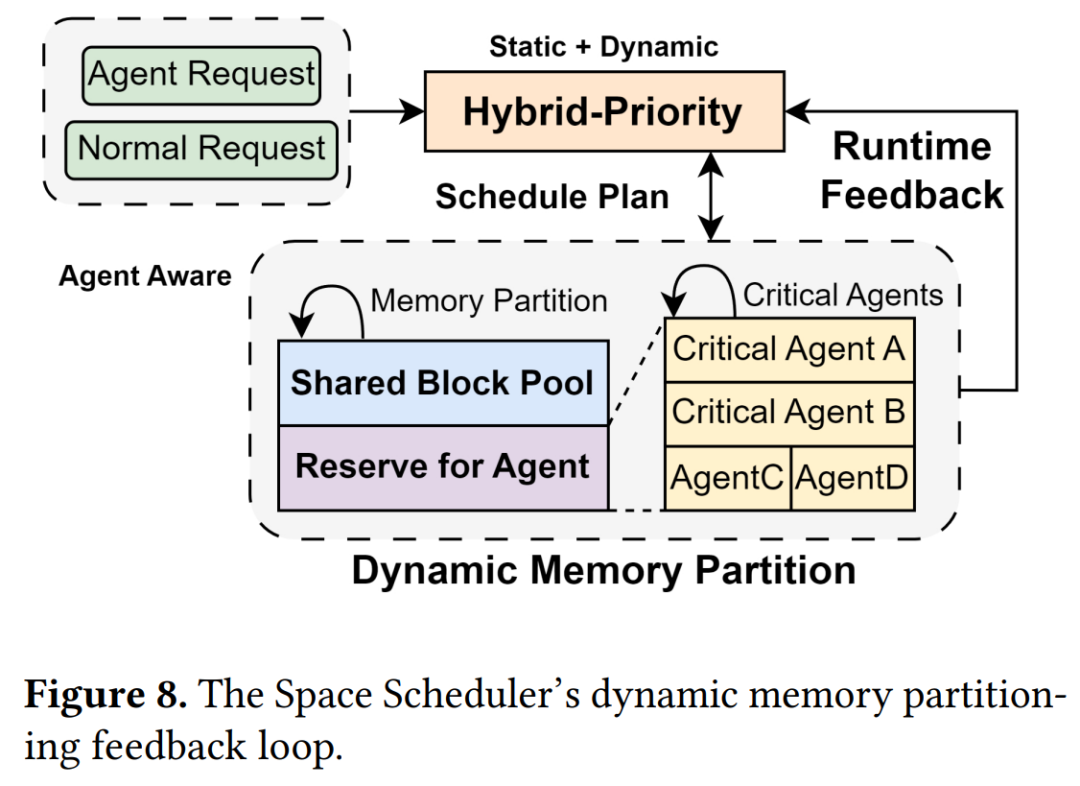
空间调度器旨在通过感知各智能体重要性来解决内存管理问题。如图8所示,该调度器采用基于混合优先级指标的动态内存分区策略,将GPU的KV Cache划分为两个区域:面向所有智能体的全局共享池,以及仅限最关键智能体访问的预留池。该策略确保即使共享池使用率较高时,关键智能体仍能获得有保障的内存资源,避免被低优先级任务阻塞。

空间调度器会周期性计算各智能体类型的混合优先级综合得分,得分排名靠前的指定为关键智能体。这种动态选择机制确保受保护的智能体集合能随应用需求变化而自适应调整。
一旦确定了关键智能体,空间调度器就会根据算法2中的两阶段过程更新内存预留:
阶段1(第5-11行):基于当前GPU块使用率计算系统内存压力,动态调整预留内存池总容量。当内存使用率较高时,系统会提升total_reserve_ratio 以增强对关键任务的保护;当使用率较低时则降低该比率,避免共享池可用内存的浪费。
阶段2(第13-19行):给每个关键智能体分配预留池(R_total)容量。每个智能体的配额由两大因素的加权平均值决定:该智能体的历史内存使用量(第15行)及其相对优先级得分(第16行)。这种均衡分配方式确保那些兼具高优先级与高内存需求特征的智能体获得更大的预留空间。
02
评估
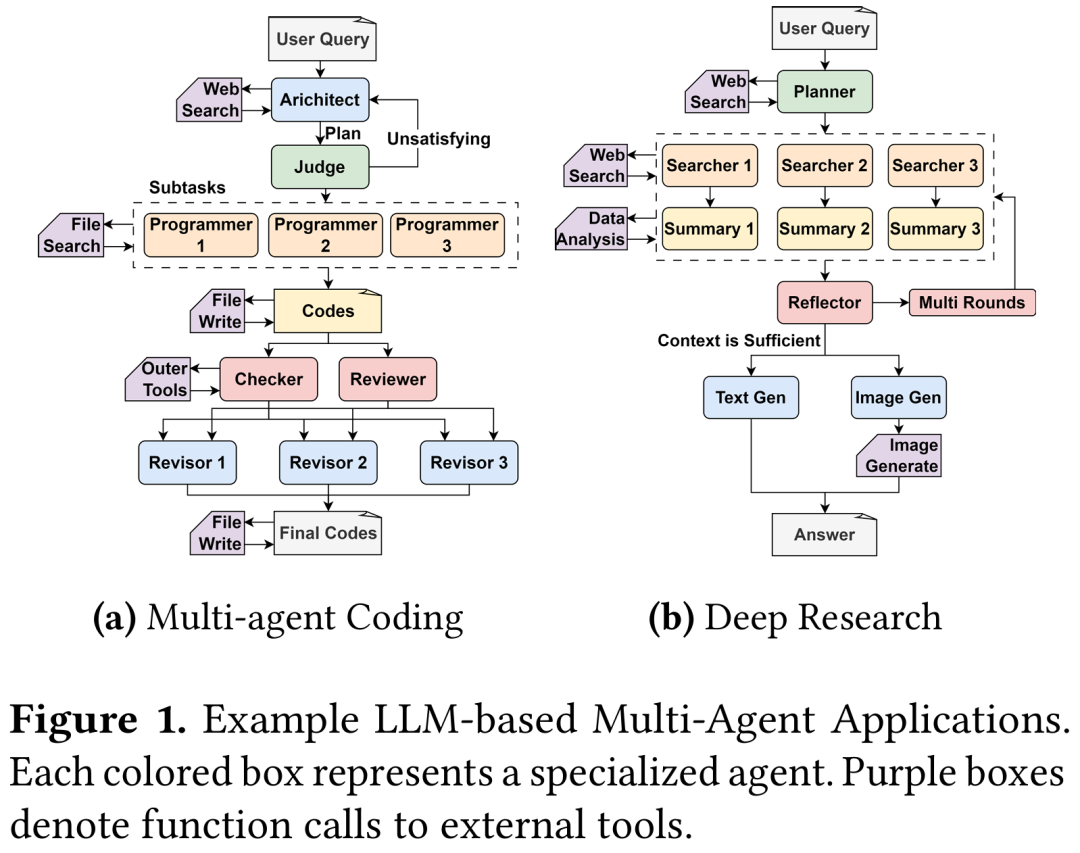
为了确保能够反映真实的场景的评估,研究团队实现了两个具有代表性的多智能体应用:代码编写者(Code-Writer)和深度研究(Deep Research),如图1所示。
基准测试的用户请求基于ShareGPT和AgentCode数据集生成,这些数据集包含真实世界中的对话数据。为了模拟动态的用户环境,使用泊松分布生成请求到达时间,通过调整每秒应用请求数量来评估系统在不同负载条件下的性能表现。
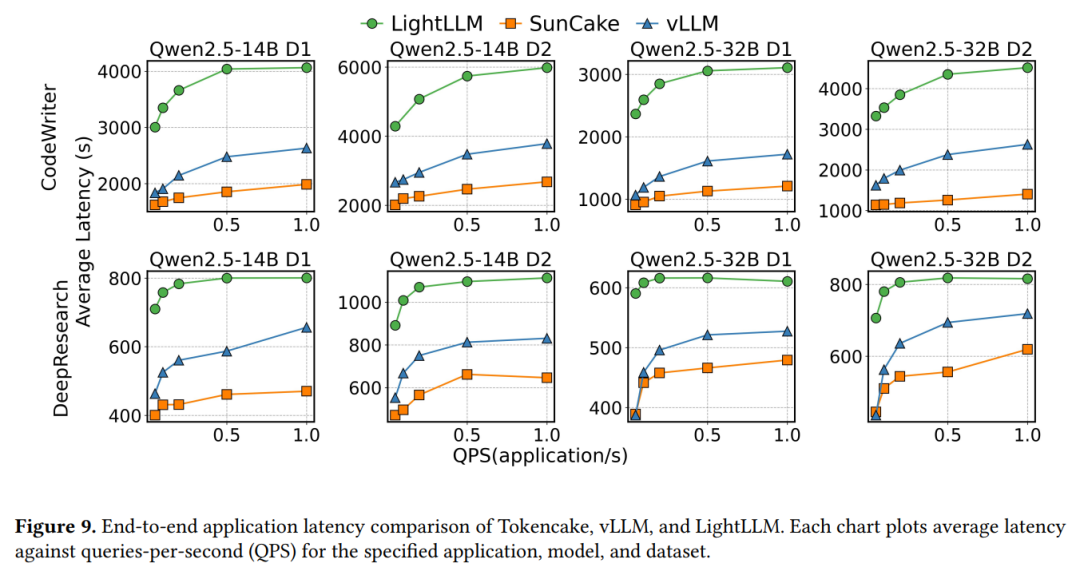
注:Tokencake在图例中是SunCake
如图9所示,Tokencake 的延迟随负载增加呈现出更平缓的上升趋势。通过智能地卸载停滞智能体的 KV Cache,Tokencake释放了宝贵的GPU内存,使其能为活跃请求维持更大、更高效的批处理大小。
在 1.0 QPS 的高负载下,Tokencake相较vLLM基线可降低47.06%以上的平均端到端延迟。这一结果充分证明,Tokencake在多智能体工作负载的严苛条件下能持续保持高性能与稳定性,而LightLLM等专用系统在此场景中表现不佳。
图10显示Tokencake在所有负载下,始终维持更高的平均 GPU KV Cache 使用率,相比vLLM最高提升16.9%。
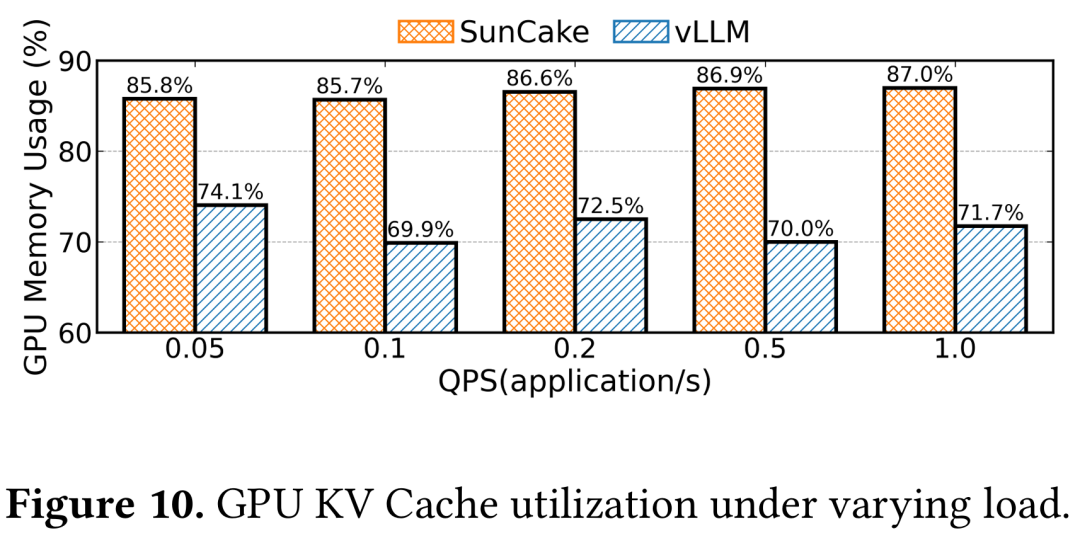
注:Tokencake在图例中是SunCake