[fmt] 格式化器 (formatter<T, Char>) | 简单情况的`format_as`
第4章:格式化器(formatter<T, Char>)
在前一章:格式字符串解析器(parse_context,format_handler)中,我们学习了fmt如何仔细阅读和理解你的"食谱说明"——格式字符串。
它知道每个"原料"(参数)应该放在哪里以及需要什么样的样式。但在弄清楚这一切之后,还有最后一个关键步骤:实际准备每个原料,将其转换为最终的文本形式。
想象一下,你为一道菜准备了所有原料。食谱告诉你"取面粉"(参数类型),“放在这里”(在格式字符串中的位置),以及"过筛"(格式化规范)。formatter就是实际的厨房工具,它知道如何过筛面粉、如何切蔬菜或如何融化黄油。它是将特定类型的数据(int、std::string或你的自定义MyClass)转换为文本的专用指令集。
fmt库为所有标准C++类型(如数字、字符串、指针)提供了内置的formatter食谱。但它的真正强大之处在于,你可以教会它如何将**你自己的自定义数据类型转换为格式化文本。
核心概念:formatter<T, Char>
将formatter<T, Char>视为特定原料类型T的专用食谱卡片,使用特定的字符类型Char(通常是char用于常规字符串,或wchar_t用于宽字符串)。
对于fmt可以打印的每个类型T,都有一个对应的formatter<T, Char>特化。这个formatter定义了两个基本方法:
-
parse方法:这个方法就像阅读食谱卡片上关于如何准备这个原料的具体子指令。它查看格式规范(格式字符串中冒号:后面的部分,例如{:^10}),并决定如何为类型T解释它们。它告诉fmt:“好的,对于一个Point对象,如果你看到^10,意味着将输出居中在10个字符内。” -
format方法:这是实际烹饪发生的地方!它接受一个类型为T的对象(你的实际原料),并将其转换为文本,应用在parse阶段学到的所有规则。它将结果字符写入fmt的输出缓冲区。
通过特化fmt::formatter<YourCustomType>,你实际上是在向fmt的食谱书中添加一张新的食谱卡片,使其能够像处理内置类型一样处理和打印你的数据。
用例:格式化你自己的类型
假设你有一个简单的Point结构,你想漂亮地打印它,比如(10, 20)。
#include <fmt/format.h> // 我们需要这个来使用 fmt::print 和 formatter
#include <string> // 用于内部字符串处理(memory_buffer)// 我们的自定义数据类型:一个带有X和Y坐标的Point
struct Point {int x, y;
};int main() {Point p = {1, 2};// 这一行会导致编译时错误,因为 fmt 还不知道如何将 'Point' 直接转换为文本!// fmt::println("我的点是: {}", p); // <-- 会失败!fmt::println("如果没有自定义格式化器,这将无法编译。");return 0;
}
输出:
如果没有自定义格式化器,这将无法编译。
为了使这工作,我们需要=为Point提供一个formatter特化。对于简单类型,一个常见且简单的方法是重用现有的格式化器(如formatter<std::string_view>)来处理常见的格式化选项(宽度、对齐、填充字符),而你自己只需处理特定类型的转换。
以下是实现方式:
#include <fmt/format.h>
#include <string> // 用于内部 fmt::memory_buffer 处理// 我们的自定义数据类型
struct Point {int x, y;
};// 步骤1:为我们的 Point 类型特化 fmt::formatter
// 我们从 fmt::formatter<std::string_view> 继承以重用其解析逻辑
// 用于常见的格式规范,如宽度、对齐和填充字符。
template <>
struct fmt::formatter<Point> : fmt::formatter<std::string_view> {// parse 方法自动从 fmt::formatter<std::string_view> 继承。// 这意味着我们的 Point 对象现在可以使用类似字符串的格式规范,// 例如 "{:^20}"(居中,20个字符宽)。// 步骤2:实现 format 方法以将 Point 转换为文本。auto format(const Point& p, fmt::format_context& ctx) const-> fmt::format_context::iterator {// 首先,将 Point 的内部数据格式化为临时缓冲区。// 我们使用 fmt::memory_buffer 和 fmt::format_to 作为构建字符串的高效方式。fmt::memory_buffer buffer;fmt::format_to(fmt::appender(buffer), "({}, {})", p.x, p.y);// 然后,使用继承的格式化器(fmt::formatter<std::string_view>)// 将任何通用格式规范(宽度、对齐、填充)应用到我们刚刚创建的字符串。return fmt::formatter<std::string_view>::format(fmt::string_view(buffer.data(), buffer.size()), ctx);}
};int main() {Point origin = {0, 0};Point target = {10, 20};fmt::println("原点: {}", origin);// 输出: 原点: (0, 0)fmt::println("目标(居中并用破折号填充): {:-^20}", target);// 输出: 目标(居中并用破折号填充): ----(10, 20)----fmt::println("仅X: {}", Point{5, 0}); // y 将为 0// 输出: 仅X: (5, 0)return 0;
}
🎢解释:
- 我们定义了
struct Point。 - 我们为
fmt::formatter<Point>提供了一个模板特化。通过从fmt::formatter<std::string_view>继承,我们自动获得了字符串格式化器的parse方法。这意味着我们不需要为Point的通用格式化(如width或alignment)编写自定义逻辑。 - 在
format(const Point& p, fmt::format_context& ctx)中,我们做了两件事:- 我们使用
fmt::memory_buffer(一个高效、动态增长的字符数组)和fmt::format_to将p.x和p.y转换为类似"(10, 20)"的字符串。 - 然后,我们调用基类
fmt::formatter<std::string_view>(我们继承的)的format方法,将"(10, 20)"字符串应用任何格式规范(如:-^20),并将最终结果写入ctx.out()。
- 我们使用
现在fmt知道如何打印你的Point对象了
内部机制:formatter如何工作
当调用fmt::print(或fmt::format)时,以下是formatter在整个过程中的作用:
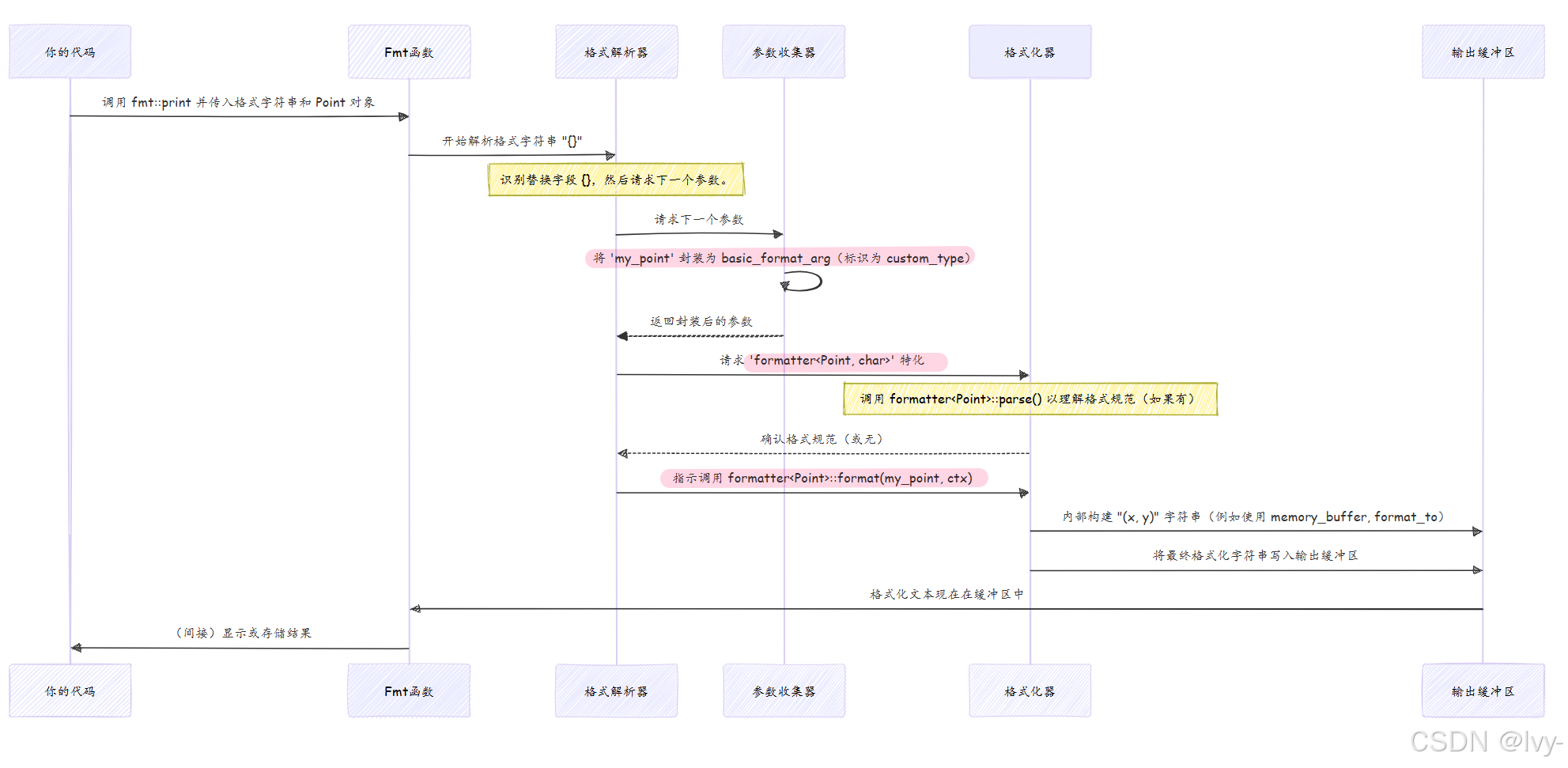
这个序列突出了formatter的深度集成
格式字符串解析器(parse_context和format_handler,来自第3章:格式字符串解析器(parse_context,format_handler))与每个参数的特定formatter<T, Char>紧密协作。
探讨:formatter结构
formatter结构模板(在include/fmt/base.h和include/fmt/format.h中声明)在概念上如下:
// 来自 include/fmt/base.h 和 include/fmt/format.h(简化)// 通用格式化器模板
template <typename T, typename Char = char, typename Enable = void>
struct formatter {// 默认情况下,它是删除的。你必须为你的类型特化它。formatter() = delete;
};// 内置整数类型格式化器的示例(简化)
template <typename T, typename Char>
struct formatter<T, Char,enable_if_t<detail::type_constant<T, Char>::value !=detail::type::custom_type>>: detail::native_formatter<T, Char, detail::type_constant<T, Char>::value> {// 这是 fmt 处理其自身类型的方式。它们继承自一个// `native_formatter`,其中包含实际的 parse 和 format 逻辑。
};// 你的自定义特化看起来像:
// template <>
// struct fmt::formatter<Point, char> {
// // ... parse 方法 ...
// // ... format 方法 ...
// };
当你定义template <> struct fmt::formatter<Point> : fmt::formatter<std::string_view>时,你实际上是在为Point提供特定的食谱卡片。
- 具有可扩展性的模板设计~
表:formatter方法
| 方法 | 角色 | 输入 | 输出 |
|---|---|---|---|
parse | 从格式字符串中读取类型T的特定格式化指令。 | fmt::format_parse_context& ctx:包含剩余的格式字符串(例如^20})。它帮助推进解析器。 | 一个迭代器,指向解析的格式规范的末尾。 |
format | 根据解析的指令将类型T的对象转换为文本。 | const T& value:要格式化的实际对象。 fmt::format_context& ctx:提供对输出缓冲区(ctx.out())和可能的区域设置信息的访问。 | 一个迭代器,指向缓冲区中写入输出的末尾。 |
parse方法在格式化过程开始时(或在使用编译时格式化时在编译时)调用一次。它读取你的类型的任何自定义格式说明符,并将其存储为formatter对象中的成员变量。例如,如果你设计Point接受像"{:P}"这样的说明符表示"极坐标",parse方法会检测P并设置一个内部标志。
然后,format方法为在格式字符串中找到的每个类型为T的参数调用。它使用在parse阶段收集的标志或数据,将给定的value正确转换为文本,并将其写入ctx.out()。
简单情况的format_as
对于只需要格式化为另一种类型的自定义类型(例如,一个enum应该打印为其底层整数值),fmt提供了一个更简单的辅助函数format_as。你不需要为这些情况编写完整的formatter特化。
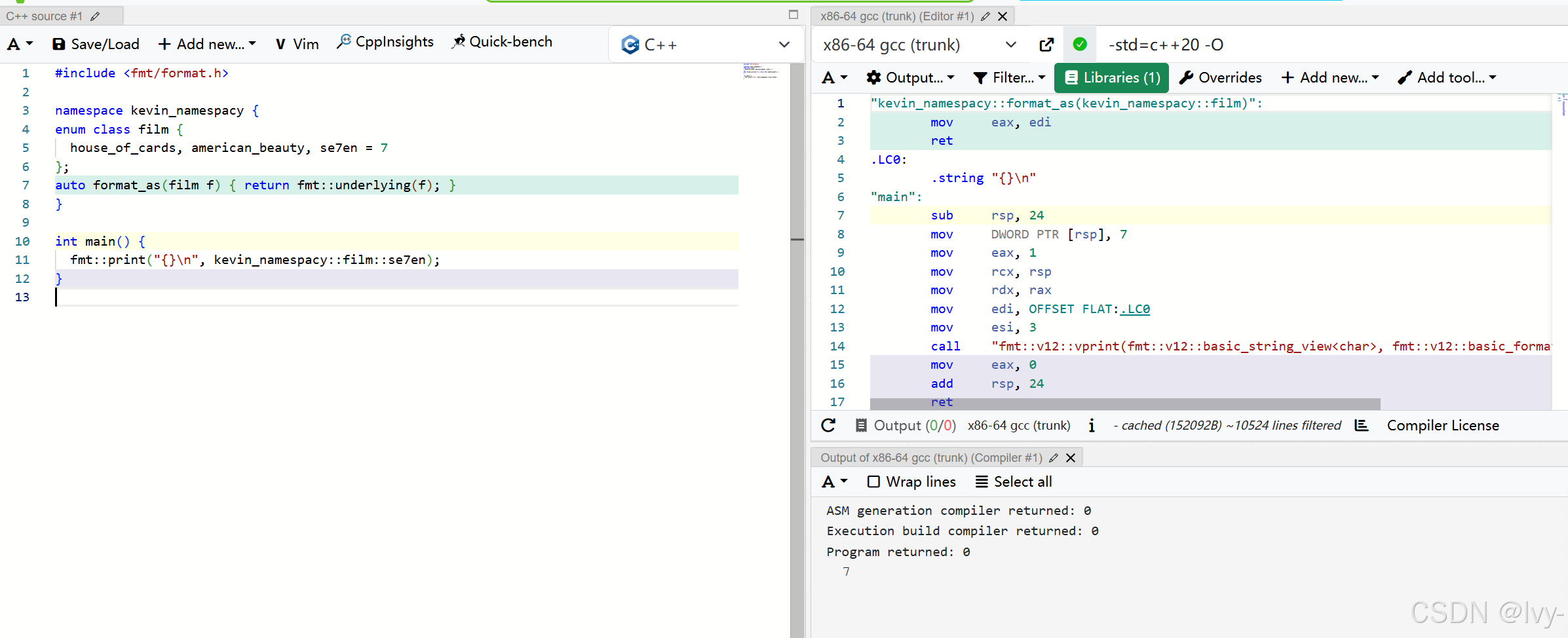
#include <fmt/format.h>namespace Chess {enum class Piece {Pawn = 1, Knight, Bishop, Rook, Queen, King};// 通过在同一命名空间中定义 format_as,fmt 知道如何将 Piece// 打印为其底层整数类型,而无需完整的格式化器特化。auto format_as(Piece p) { return fmt::underlying(p); }
} // namespace Chessint main() {Chess::Piece my_piece = Chess::Piece::Knight;fmt::println("我的棋子值是: {}", my_piece);// 输出: 我的棋子值是: 2return 0;
}
在这里,fmt::underlying(p)将enum class转换为其整数值,而fmt已经知道如何格式化整数。这比完整的formatter特化简单得多。
结论
在本章中,我们解锁了fmt::formatter<T, Char>的强大功能:
- 它是食谱书,告诉
fmt如何将任何特定数据类型T转换为格式化文本。 - 你学会了通过为自定义类型提供自己的
formatter特化来扩展fmt的功能,使它们能够像内置类型一样被格式化。 parse方法解释格式规范,format方法执行实际的文本转换。- 对于简单情况,
format_as函数提供了一个方便的快捷方式,将自定义类型格式化为现有的可格式化类型。
现在你了解了如何将单个数据类型转换为文本,下一步是理解这些文本在最终发送到目的地之前如何高效地存储和管理。在下一章中,我们将探讨输出缓冲(basic_memory_buffer,basic_appender)。