PDF 全文翻译开发实现思路:挑战、细节与工程化解决方案
在 AI 应用加速落地的今天,PDF 全文翻译已成为学术工具、跨语文档阅读与知识服务的重要能力。然而,一个看似简单的需求:“把 PDF 翻译成另一种语言”,技术实现却涉及文档解析、版面分析、OCR、语言理解、对齐复原、格式渲染等复杂环节。
本文将从流程设计 → 难点分析 → 工程化策略全链路解析 PDF 全文翻译的实现。
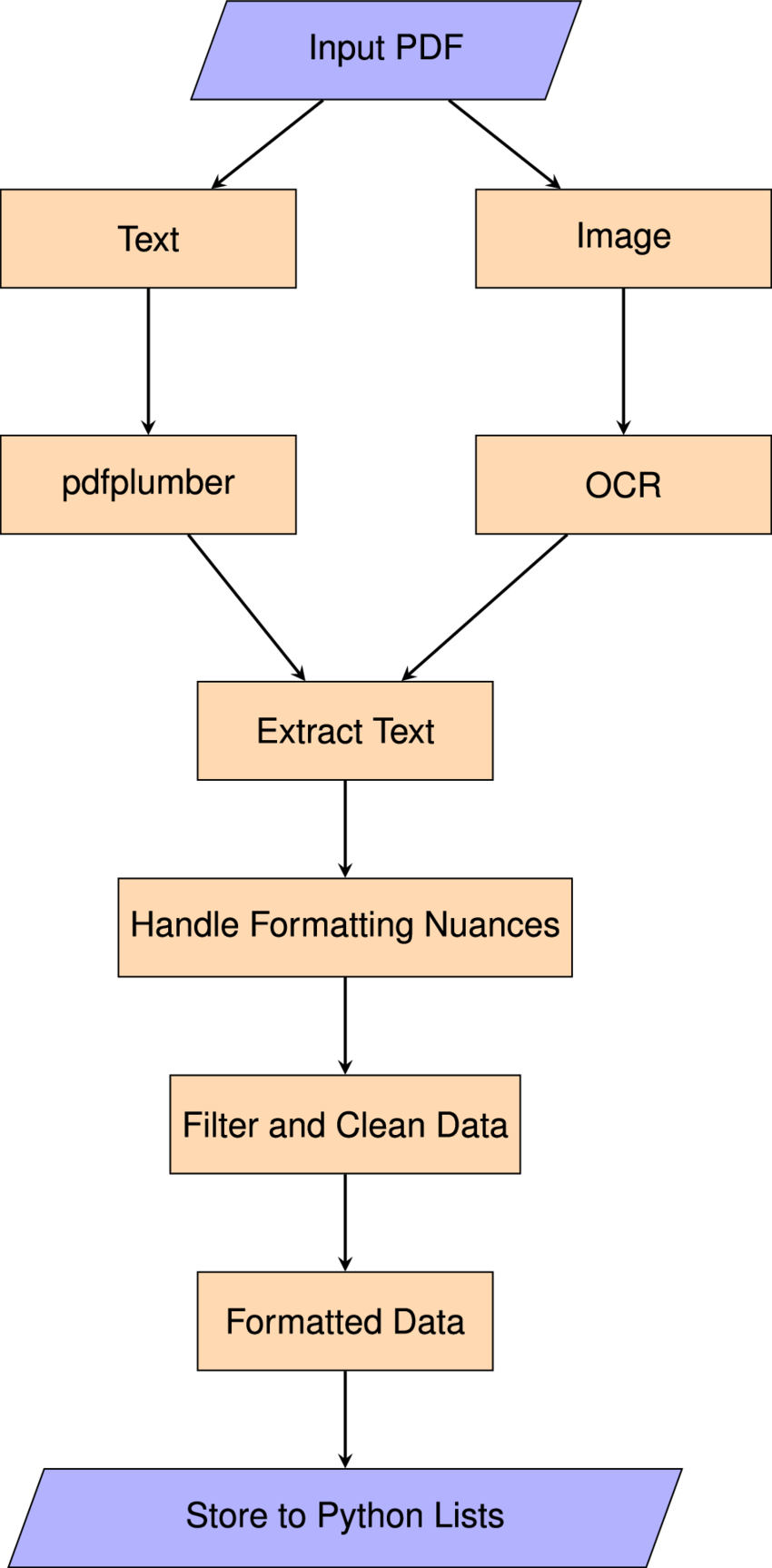
最推荐的标准管线是:
| 阶段 | 核心逻辑 | 技术点 |
|---|---|---|
| 1. PDF解析 | 解包结构、获取对象树和资源 | PDFium / MuPDF / PyMuPDF |
| 2. 文本提取 | 读取文本块、版面坐标 | layout-aware extraction、坐标层级布局 |
| 3. OCR增强 | 针对扫描件或缺失文本层 | Tesseract / PaddleOCR / Vision API |
| 4. 内容分类 | 正文 vs 表格 vs 脚注 vs 公式 | 版面分析、ML 分类 |
| 5. 章节切分 | 块化翻译,保证语义完整 | NER + 句段切分算法 |
| 6. 翻译处理 | Context-aware、高可用性 | LLM、翻译引擎混合策略 |
| 7. 对齐回写 | 坐标复原、格式重建 | XML/HTML/Canvas 渲染 |
| 8. 导出 | 可编辑或展示形式 | DOCX / PDF / HTML |
用一句话总结:抽取比翻译更难,回填比抽取更难。
❌ 二、PDF 全文翻译十大真实难点与解决策略
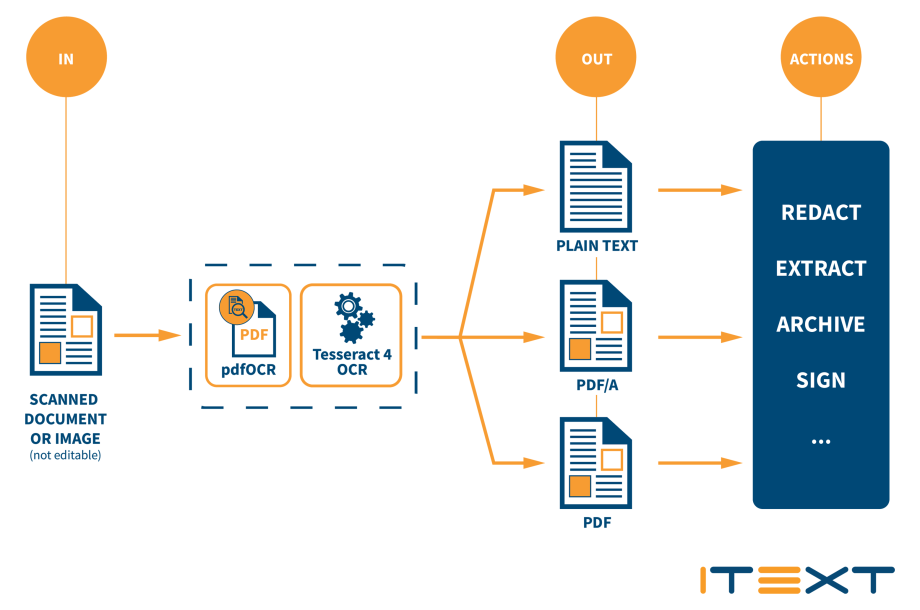
1️⃣ 扫描版 PDF —— 无文本层,OCR是第一关
| 症状 | 效果惨烈:图片转换、文本缺失、行无法分辨 |
| 推荐解决 |
PaddleOCR 多语言模型
表格区 OCR 特判
数学/公式区域使用 Mathpix API
2️⃣ 版面混乱与阅读顺序错误
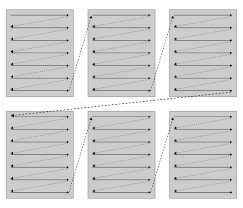

多栏排版、图注插入、脚注穿插,会导致翻译顺序错乱,内容就像洗牌一样。
✅ 解决建议
基于坐标聚类(XY-cut / Doc2Vec for Layout)
采用 LayoutLM 进行版面语义识别
对每个 text block 建立顺序链并验证“视觉阅读路径”
3️⃣ 表格结构丢失、单元格顺序乱
关键挑战:提取结构不仅要识字,还要识网格关系。
✅ 工程策略
单独解析
<w:tbl>层(如果是 DOCX)PDF → 表格结构识别(Camelot / Tabula / DeepTable)
表格文案优先逐单元格翻译
4️⃣ 图片中包含文本
如图注、流程图、截图内容会遗漏 → 必须执行:
✅ OCR 二次扫描
检测可疑区域(低文本密度/边缘区域)
分类:文字图片 → OCR;内容图 → 保留原图
5️⃣ 文本提取后的乱码、丢字问题
| 原因 | 字体映射缺失、编码表无法解析、ToUnicode损坏 |
|——|——|
| 方案 | 字形匹配、字体子集还原、AI字符预测 |
推荐:
PyMuPDF + 字体提取
如果字体损坏→结合图层OCR回填
6️⃣ 段落碎片化导致语义误翻
常见:列间换行误判 / 标题被拆散
✅ 对策
NLP 分句模型 + 坐标连通性
合并高度相似字体属性且同列的文本
➡️ 翻译引擎应以“句”为最小单位
不能按行翻译
7️⃣ 专业名词 & 引用格式混乱
医学、法律、科研领域专有词要求高精度
文献引用、公式编号不能动
✅ 对策
名词术语库+用户自定义术语替换
公式编号与位置原样保留(禁止翻译)
8️⃣ 格式回填不对齐 & 段落散架
翻译后长度变了,导致排版错位:
✅ 用 HTML 回填比生成新 PDF 更可控
推荐输出:
双栏同步对照 HTML
可下载 DOCX
最终可渲染为 PDF
9️⃣ 翻译成本极高
如 50 页扫描论文 → 图片 200 张
LLM 翻译几万 Token 费用毫不留情…
✅ 成本优化方案
| 内容类型 | 处理策略 |
|---|---|
| 重复结构(表格列头) | 缓存翻译结果 |
| 相同内容 | 去重 |
| 图片无文字 | 跳过 OCR |
| 长文 | 分段异步翻译、失败重试 |
🔟 隐私与版权风险
一定要提供:
全本本地处理选项
隐私加密和数据不落盘策略
用户授权确认 UI
✅ 三、工程落地架构建议
适合云端部署的高可用架构:
┌────────────┐
PDF → 解析引擎 → 结构抽取 → 内容分类 │└────────────┘│┌──────────────────────┴──────────────────────┐文本翻译引擎 OCR 通道(Chunk Batch + Context) (图像/表格/损坏字体)│ │└──────────────────────┬──────────────────────┘模块合并 → 格式恢复 → 导出 PDF/HTML/DOCX
可引入多级故障恢复:
PDF 文本层失败 → OCR Fallback
翻译失败 → 自动重试 + 回滚机制
✅ 四、开发者实战建议
| 项目阶段 | 推荐检查项 |
|---|---|
| MVP | 单栏PDF、文本层完整、无表格 |
| V1.5 | 双栏、多图注、基础表格 |
| Pro | OCR + 学术排版对齐 + 公式/章节号保留 |
另外务必加入:
🚧 并发/速率限流(避免翻译 API 爆炸)
✅ 翻译缓存(减少成本)
🔄 下载断点续传 & 容错
📌 五、给产品的文案建议
”支持学术级 PDF 全文智能翻译,原格式复现、资料完整可溯源。“
用户更关心的不是翻译本身,而是:
✅ 正确
✅ 排版好
✅ 一键导出
✅ 不丢信息
🏁 总结
| 核心价值 | 实现重点 |
|---|---|
| 保留结构、不丢语义 | 版面分析、分块翻译 |
| 原样格式还原 | 坐标映射 & 格式回填 |
| 可用性强、稳定 | 容错 + 本地化 + 成本优化 |
一句话概括成功法则:
永远把 PDF 当“视觉文档”处理,而不是纯文本。
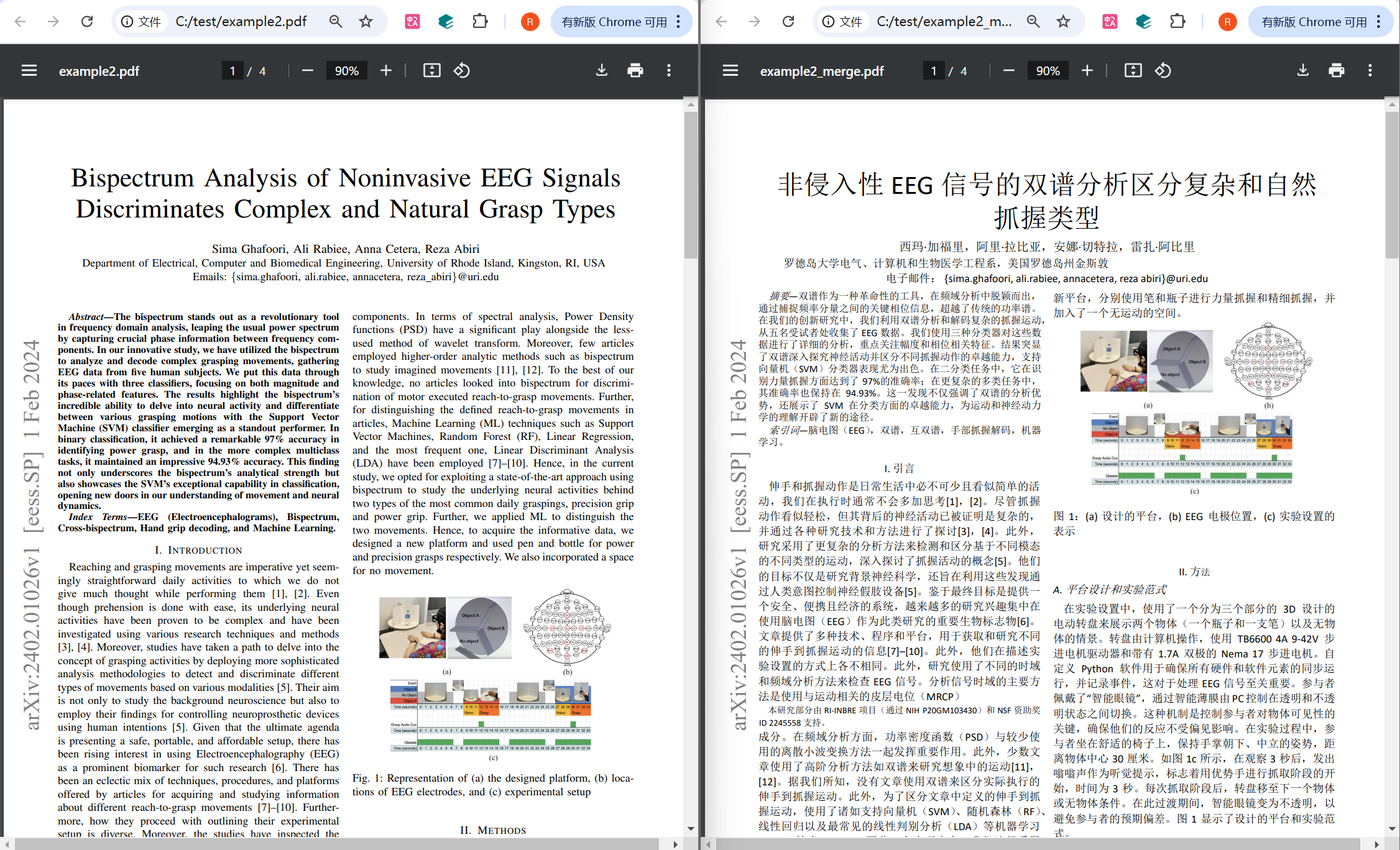
📌 六、成果展示
1. 图文混排
2.公式+文字混排
3.图表+文字混排
4.段落翻译