【论文精读】CMD:迈向高效视频生成的新范式
标题:EFFICIENT VIDEO DIFFUSION MODELS VIA CONTENT-FRAME MOTION-LATENT DECOMPOSITION
作者:Sihyun Yu, Weili Nie, De-An Huang, Boyi Li, Jinwoo Shin, Anima Anandkumar
单位:KAIS, NVIDIA Corporation, UC Berkeley, Caltech
发表:ICLR 2024
论文链接:https://arxiv.org/pdf/2403.14148
项目链接:https://sihyun.me/CMD/
代码链接:暂无
关键词:视频扩散模型;内容 - 运动分解;Latent 空间;高效生成;预训练模型复用
在生成式AI领域,视频扩散模型凭借其出色的生成质量备受关注,但高内存占用和庞大的计算开销始终是制约其落地的关键瓶颈。Nvidia等团队提出了一种名为CMD(Content-Motion Latent Diffusion Model)的高效视频扩散模型,通过创新的内容-运动 latent 分解策略,成功在生成质量与效率之间实现了突破性平衡。
一、研究背景:视频扩散模型的困境与机遇
扩散模型在图像生成领域已取得巨大成功,从高质量图像合成到文本-图像生成,均展现出强大能力。受此启发,研究者们将目光投向更具挑战性的视频生成任务,一系列视频扩散模型应运而生。然而,与图像生成相比,视频生成面临两大核心难题:
-
数据与维度难题:高质量视频数据集的收集难度远高于图像,且视频作为立方数组(通道×高度×宽度×时间)具有极高的维度,导致模型内存占用和计算成本激增,尤其在高分辨率、长时长视频生成场景下更为突出。
-
现有方案的局限性:当前主流方案分为两类,一类直接基于预训练图像扩散模型扩展,通过添加时间层适配视频任务,但仍需处理高维视频数据,效率低下;另一类采用 latent 空间压缩策略,将视频投影到低维空间再训练扩散模型,虽提升了效率,但因未融合预训练图像模型的视觉知识,生成质量受限。
基于此,论文提出CMD模型,核心目标是融合预训练图像模型的质量优势与 latent 分解的效率优势,解决视频生成“高质量”与“高效率”不可兼得的痛点。
二、核心创新:内容-运动 latent 分解框架
CMD模型的核心创新在于设计了一种“内容帧+运动 latent”的双分支 latent 分解结构,让预训练图像扩散模型能直接高效地应用于视频生成任务。其核心思路可概括为:将视频编码为一个类似图像的“内容帧”(承载静态视觉内容)和一个低维“运动 latent 表示”(刻画时序动态信息),分别通过优化后的扩散模型生成,最终解码为完整视频。这种分解策略既保留了预训练图像模型的视觉建模能力,又通过运动 latent 压缩降低了时序维度的计算开销。
下图清晰对比了CMD与传统方案的差异:

如图2(a)所示,传统方案直接在预训练图像扩散模型中添加时间层,需处理完整的高维视频数据;而图2(b)的CMD方案通过三步实现视频生成:1. 视频编码为内容帧和运动 latent;2. 微调预训练图像扩散模型生成内容帧;3. 训练轻量扩散模型生成运动 latent。蓝色标记部分为新增参数,可见CMD的新增开销极小。
三、模型架构深度解析
CMD模型由三大核心模块构成:视频自编码器(负责内容-运动分解与重构)、内容帧扩散模型(生成高质量内容帧)、运动扩散模型(生成时序一致的运动信息)。三者协同工作,实现高效高质量的视频生成。
3.1 视频自编码器:分解与重构的核心
自编码器是CMD实现内容-运动分解的关键,其核心任务是将输入视频(长度为L的视频序列)编码为内容帧
和运动 latent
,并能从这两个分量中重构原始视频。其结构设计如下:
CMD自编码器结构示意图
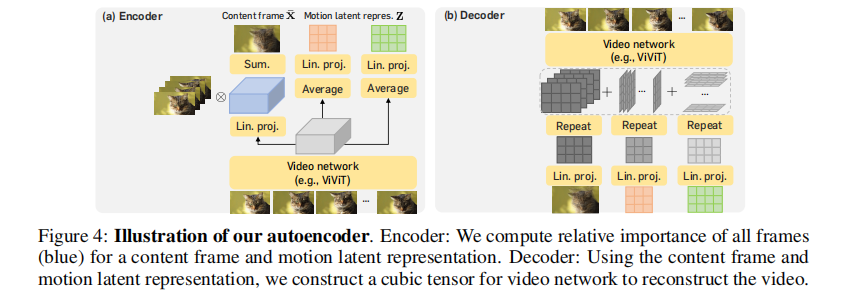
3.1.1 编码器:从视频到双分支 latent
编码器由基础网络和两个头部网络组成:
-
基础网络
:采用视频Transformer(如ViViT)作为骨干网络,将输入视频
映射为隐藏特征
,完成初步的时空特征提取。
-
内容帧头部
:计算各视频帧的权重(通过softmax实现时间轴上的权重分配),将视频帧加权求和得到内容帧
,公式为:
。其中
为元素积,
为softmax函数。这种加权方式能自动聚焦视频中的核心静态内容,使
-
运动 latent 头部
:将隐藏特征
通过轴平均投影为两个张量
(
轴平均)和
(
轴平均),再通过1×1卷积映射为低维运动 latent
,其中
、
。这种2D投影设计灵感源于三平面视频编码,能以极低维度刻画运动信息。
3.1.2 解码器:从双分支 latent 到视频
解码器负责将内容帧
和运动 latent
重构为原始视频,核心是通过嵌入层和视频网络实现特征融合:
-
嵌入层
与
:分别将内容帧
、
映射为相同通道数$C'$的特征
、
、
。
-
特征融合:将三个特征按空间位置求和,得到融合特征
,实现内容与运动信息的紧密结合。
-
视频网络
:采用与编码器基础网络相同的视频Transformer架构,将融合特征解码为原始分辨率的视频
自编码器通过重构损失进行训练,确保分解后的两个分量能完整保留原始视频的信息。
3.2 内容帧扩散模型:复用图像模型的质量优势
由于内容帧是视频帧的加权和,其分布与自然图像高度相似,因此CMD直接复用预训练图像扩散模型(如Stable Diffusion 1.5/2.1),通过微调适配内容帧生成任务,无需新增网络参数,极大降低了训练成本。
训练采用标准的-预测目标函数:
![]()
其中,为条件(如文本描述或类别标签)。微调过程仅更新预训练模型的参数,因输入仍为图像维度(无时间轴),内存效率极高。
3.3 运动扩散模型:轻量高效的时序建模
为建模运动 latent 的分布,CMD设计了一个轻量扩散模型
,以内容帧
和条件
为引导,生成与内容匹配的运动信息。
-
网络架构:采用DiT(Diffusion Transformer)作为骨干网络,因其在扩散模型中兼具性能与效率优势。输入
(带噪声的运动 latent)和
-
条件注入:文本条件
通过AdaIN层注入,内容帧
-
训练目标:采用与内容帧扩散模型相同的
-预测目标:
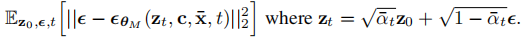
由于运动 latent 维度低(仅为原始视频的1/16.7),模型训练速度极快。
3.4 生成流程:双分支协同生成
CMD的视频生成流程分为三步,整体采用DDIM采样器(50步采样,)以提升效率:
-
从高斯分布采样初始噪声
和
;
-
通过内容帧扩散模型对
;
-
以
;
-
将
四、实验验证:质量与效率双突破
论文在UCF101(类别条件生成)、WebVid-10M(文本-视频生成)和MSR-VTT(零样本文本-视频生成)三大基准数据集上进行了全面实验,从定量指标、定性效果、效率三个维度验证了CMD的优越性。
4.1 实验设置
-
数据集:UCF101(101类人体动作视频,分辨率64×64/512×512,长度16帧);WebVid-10M(1070万文本-视频对,分辨率512×1024,长度16帧);MSR-VTT(1万视频,用于零样本评估)。
-
基线模型:涵盖主流视频生成模型,如LVDM、ModelScope、VideoLDM、MAGVIT、Make-A-Video等。
-
评估指标:生成质量采用FVD(Fréchet Video Distance,越低越好);文本-视频对齐采用CLIPSIM(越高越好);效率指标包括计算量(TFLOPs)、采样时间(秒)和内存占用(GB)。
4.2 定量结果:质量领先,效率碾压
4.2.1 类别条件生成(UCF101)
表1展示了UCF101数据集上的类别条件生成结果,CMD在两种评估场景下均取得最优性能:
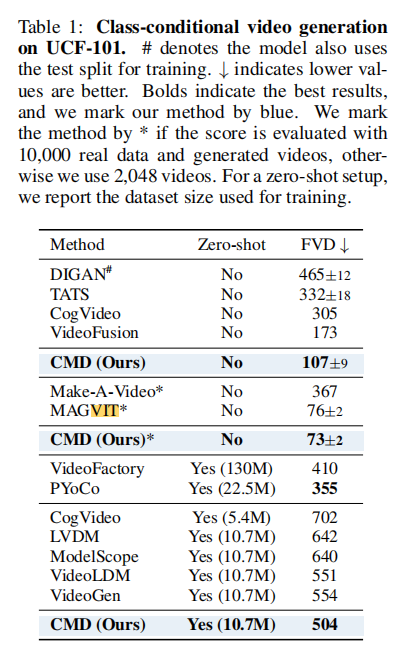
注:#表示使用测试集训练,*表示使用10000个样本评估。在非零样本场景下,CMD的FVD低至73±2,超过MAGVIT等强基线;零样本场景下,仅用10.7M数据就实现504的FVD,远超同数据量的基线模型。
4.2.2 文本-视频生成(WebVid-10M & MSR-VTT)
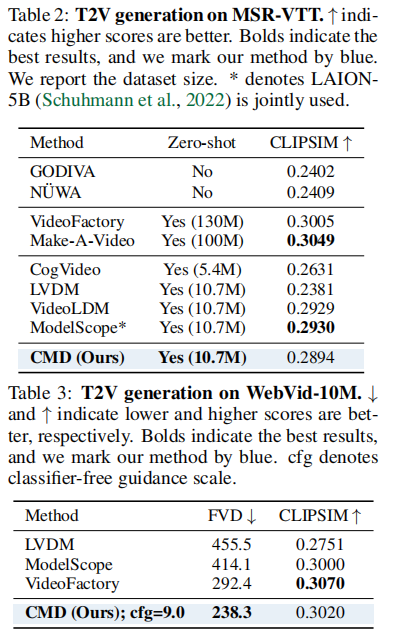
WebVid-10M是文本-视频生成的核心基准,CMD在此取得了突破性结果:CMD的FVD达到238.3,比此前SOTA模型VideoFactory(292.4)提升18.5%,同时CLIPSIM达到0.3020,与SOTA持平,证明其在生成质量和文本对齐性上均表现出色。
在MSR-VTT零样本评估中,CMD的CLIPSIM为0.2894,虽略低于ModelScope(0.2930),但需注意CMD的模型参数仅1.6B,远小于VideoLDM(3.1B),且未使用额外的50亿图像-文本数据,效率优势显著。
4.3 定性效果:高分辨率与时序一致性
CMD能生成512×1024高分辨率、16帧的视频,且无需时空上采样模块。下图展示了部分文本-视频生成结果:

从结果可见,CMD生成的视频不仅细节丰富(如“时代广场滑冰的泰迪熊”中背景建筑清晰),且时序过渡流畅,运动一致性强(如“旋转的地球”“游动的小丑鱼”)。内容帧的可视化结果显示,其能准确捕捉视频的核心静态内容,运动 latent 则精准刻画了动态变化。
4.4 效率分析:计算与内存的双重优化
效率是CMD的核心优势,论文从训练和采样两个阶段进行了全面评估,所有指标均在NVIDIA A100 GPU上测试:
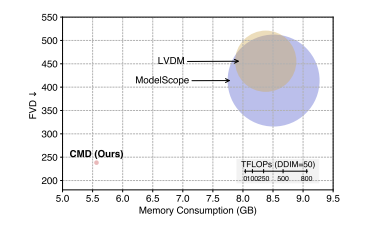
如图1所示,在生成512×1024、16帧视频时,CMD的计算量仅为传统模型的1/16.7,内存占用仅为66%,同时FVD显著更低,实现了“效率-质量”双优。
4.4.1 训练效率
图5展示了各模型训练阶段的计算量、时间和内存开销:
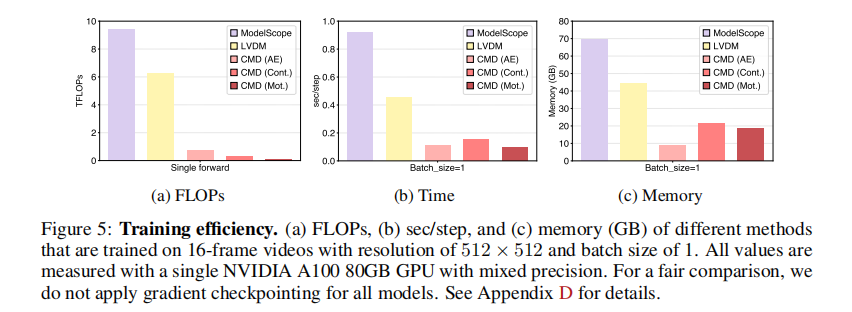
CMD的自编码器、内容帧扩散模型、运动扩散模型的计算量分别仅为0.77、0.34、0.14 TFLOPs,远低于ModelScope的9.41 TFLOPs。且内容帧与运动扩散模型可并行训练,进一步缩短训练时间。
4.4.2 采样效率
图6展示了采样阶段的效率指标:

关键结论:
-
计算量:CMD采样50步仅需46.8 TFLOPs,是ModelScope(939 TFLOPs)的1/20,LVDM(625.6 TFLOPs)的1/13.4;
-
采样时间:CMD仅需3.13秒生成一段视频,比ModelScope(35.1秒)快11倍,比LVDM(24.2秒)快7.7倍;
-
内存占用:批量生成4段视频时,CMD仅需8.57 GB内存,是ModelScope(21.3 GB)的1/2.5。
4.4.3 消融实验:关键组件的必要性
论文通过消融实验验证了各核心设计的有效性:
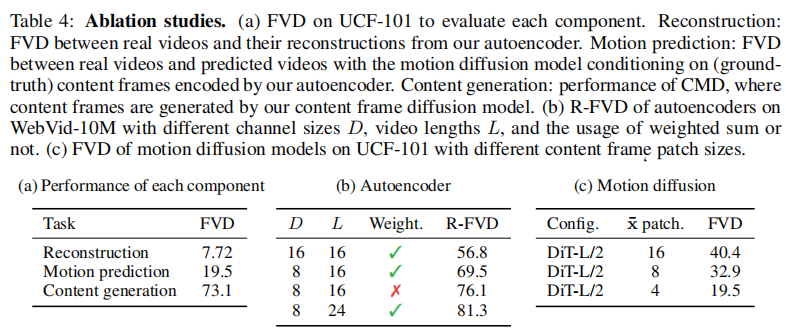
可见自编码器的重构质量极高(FVD=7.72),运动预测和内容生成模块单独使用时也表现出色,证明各组件设计合理。此外,加权和的内容帧设计、运动 latent 的低维投影等均通过消融实验验证了其必要性。
五、讨论与展望
5.1 优势与贡献
CMD的核心贡献可总结为三点:
-
创新的分解策略:提出“内容帧+运动 latent”的双分支结构,首次实现了预训练图像扩散模型在视频 latent 空间的直接复用,兼顾质量与效率;
-
极致的效率优化:通过低维运动建模、无新增参数的内容帧生成,使训练和采样的计算量、内存占用大幅降低,为高分辨率视频生成的落地提供可能;
-
全面的性能验证:在三大基准数据集上实现FVD和CLIPSIM的SOTA或近SOTA,证明了方法的通用性和有效性。
5.2 局限性与未来方向
论文也指出了CMD的不足及未来改进方向:
-
固定视频长度:当前仅支持生成16帧固定长度的视频,未来可借鉴PVDM的clip-by-clip生成思路,扩展至长视频生成;
-
动态运动建模不足:在极端动态场景下,生成质量略有下降,可通过优化 latent 空间设计(融合时空信息)或采用级联扩散模型改进;
-
模型规模潜力:当前CMD模型参数仅1.6B,未来扩大模型规模并结合负提示等技术,有望进一步提升生成质量。
5.3 伦理考量
论文提及,CMD在内容创作等领域具有积极价值,可辅助设计师快速生成创意视频,但也需警惕DeepFake等恶意应用风险。未来需在模型训练中加入内容审核机制,推动技术的负责任落地。
六、总结
CMD模型通过“内容-运动 latent 分解”这一核心创新,成功打破了视频扩散模型“高质量”与“高效率”的矛盾,为视频生成技术的工业化应用迈出了关键一步。其设计思路不仅为视频扩散模型提供了新范式,也为跨模态模型的复用与优化提供了借鉴。随着长视频生成、动态建模优化等方向的深入,相信CMD的理念将进一步推动生成式视频技术的发展。
点个关注吧...