运输层协议概述及UDP
目录
运输层协议概述
运输层的作用与地位
运输层的核心概念
复用与分用
运输层的两种通信方式
TCP/IP 运输层的协议结构
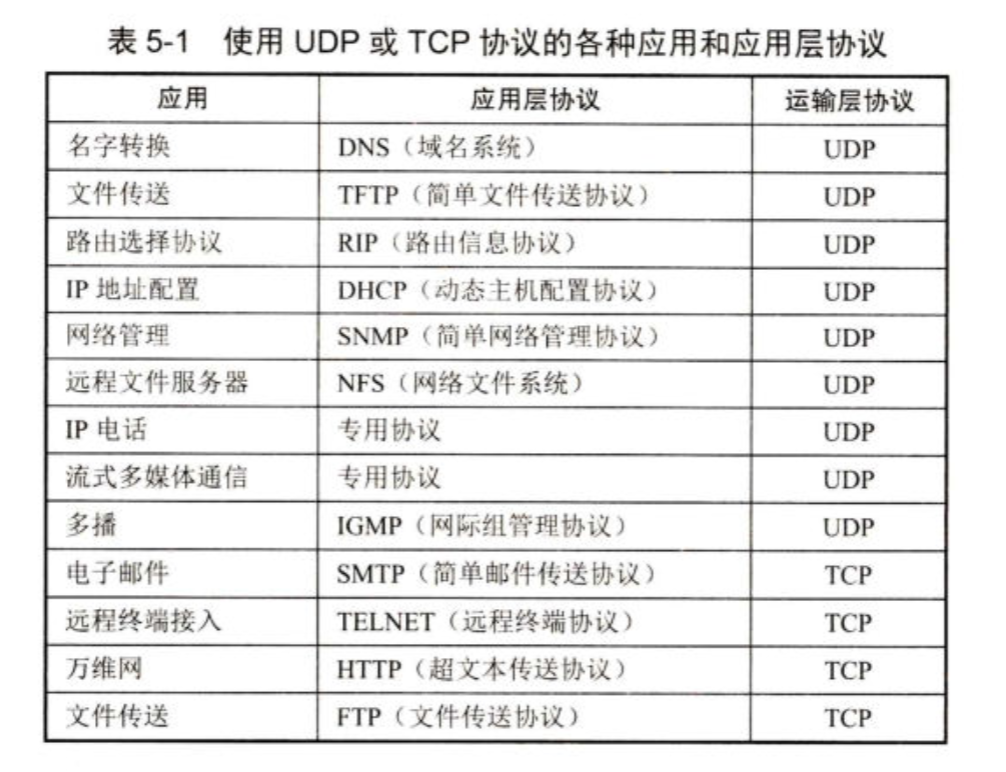
常见应用与所用运输层协议
运输层的端口(Port)
用户数据报协议UDP
UDP 的主要特点
UDP 的首部格式
UDP 校验和计算
运输层协议概述
运输层是计算机网络体系结构中网络层之上的关键层之一,它的核心作用是为相互通信的应用进程之间提供逻辑通信服务
运输层的作用与地位
1. 网络层 vs. 运输层
网络层(Network Layer):为主机到主机之间的通信提供服务
运输层(Transport Layer):为进程到进程(process-to-process)之间的通信提供服务
也就是说,网络层只保证数据包能到达目标主机,而运输层则要保证主机内具体哪个应用进程能正确接收到数据。
运输层的核心概念
1. 应用进程与通信
在两台主机进行通信时,真正发生通信的并不是主机本身,而是主机内的应用进程。
运输层的职责就是为主机中的应用进程之间提供端到端的通信服务。
2. 逻辑通信
逻辑通信指的是从应用层的角度看,似乎两个进程之间存在一条直接的通信通道。
实际上,这种通信是经过多个中间层(传输层、网络层、数据链路层、物理层)逐层实现的。
复用与分用
1. 定义
复用(Multiplexing):发送端多个应用进程可通过同一个运输层协议共享网络层提供的服务
分用(Demultiplexing):接收端运输层根据报文中的信息将数据交付给对应的应用进程
2. 实例说明
如图 5-1 所示,主机 A 的多个应用进程 AP₁、AP₂可分别与主机 B 的多个应用进程通信。
运输层在发送时执行复用,在接收时执行分用。
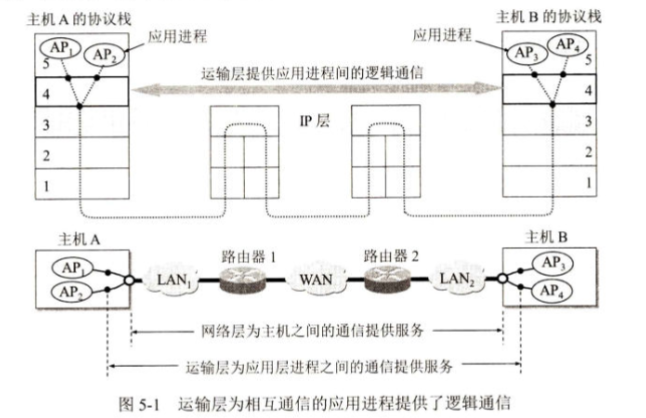
逻辑通信的意思是:从应用层来看,只要把应用层报文交给下面的运输层,运输层
就可以把这报文传送到对方的运输层(哪怕双方相距很远,例如几千公里),好像这种通信
就是沿水平方向直接传送数据。但事实上这两个运输层之间并没有一条水平方向的物理连接。数据的传送是沿着图中的虚线方向(经过多个层次)传送的。逻辑通信的意思是“好像是这样通信,但事实上并非真的这样通信”。
运输层的两种通信方式
运输层提供两种不同类型的通信服务:
| 类型 | 代表协议 | 特点 |
|---|---|---|
| 无连接服务 | UDP(User Datagram Protocol) | 简单、高效、无连接、不可靠 |
| 面向连接服务 | TCP(Transmission Control Protocol) | 可靠、面向连接、支持流量控制与差错恢复 |
1. UDP(用户数据报协议)
不建立连接;
不确认、不重传;
不保证顺序;
适合实时性要求高的应用(如视频、语音、DNS 查询)
2. TCP(传输控制协议)
通信前需建立连接;
提供可靠传输;
实现流量控制、拥塞控制;
适合要求数据可靠性的应用(如HTTP、FTP、SMTP)
TCP/IP 运输层的协议结构
在 TCP/IP 模型中,运输层协议包括:
UDP(User Datagram Protocol) — RFC 768
TCP(Transmission Control Protocol) — RFC 793
这两者在网络体系中的位置如下:

按照OSI的术语,两个对等运输实体在通信时传送的数据单位叫作运输协议数据单元
TPDU(Transport Protocol Data Unit)。但在TCP/IP体系中,则根据所使用的协议是TCP或
UDP,分别称之为TCP报文段(segment)或UDP用户数据报
常见应用与所用运输层协议
运输层的端口(Port)
1. 定义
端口是运输层提供的抽象通信端点(abstract endpoint)
每个端口用一个 16 位整数标识,范围是 0 ~ 65535
在通信时:
发送端在报文首部中写入源端口号;
接收端根据目标端口号将数据交付给正确的进程。
2. 分类
IANA(Internet Assigned Numbers Authority)规定了三类端口:
| 类型 | 范围 | 说明 |
|---|---|---|
| 熟知端口号(Well-known Ports) | 0–1023 | 常用于标准服务(HTTP:80, FTP:21, SMTP:25, DNS:53, HTTPS:443) |
| 注册端口号(Registered Ports) | 1024–49151 | 用户注册的应用程序使用 |
| 动态或私有端口号(Dynamic/Private Ports) | 49152–65535 | 客户端在通信时临时分配使用 |
3. 端口的重要性
端口标识应用进程,使得不同主机中的进程能唯一对应并建立通信。
即IP 地址定位主机,端口号定位主机内的应用。
用户数据报协议UDP
UDP(User Datagram Protocol,用户数据报协议)
是一种无连接的、尽最大努力交付(Best-Effort Delivery)的运输层协议。
它仅在 IP 层的基础上增加了极少的功能,包括:
复用与分用(通过端口号识别应用进程)
差错检测(通过校验和发现传输错误)
UDP 的主要特点
(1) 无连接
UDP 在发送数据之前不建立连接,也不释放连接。
每个报文都是独立发送的,减少了建立和释放连接的开销与时延。
适合实时性要求高的场景(如视频、语音、DNS查询)
(2) 尽最大努力交付
UDP 不保证可靠传输,即不确认、不重传、不排序、不拥塞控制。
但这种简化使得 UDP 开销小、速度快。
(3) 面向报文
UDP 对应用层交下来的报文,保留报文的边界,一次发送一个完整报文,不合并、不拆分。
接收方收到后,也按报文边界交付给上层。
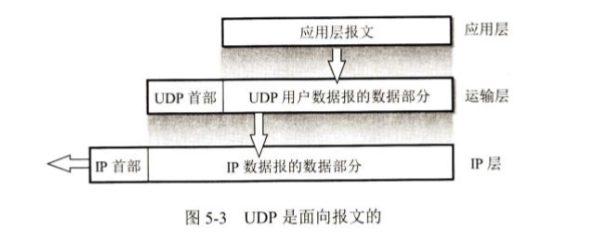
TCP:会把应用层的多个应用报文拆成多个 TCP 段发送,也可能把多个小应用报文合并成一个 TCP 段发送。接收方 TCP 收到段后,会先缓存、重组,再按需交给应用层,应用层拿不到原始的报文边界。
UDP:严格遵循 1 个应用报文→1 个 UDP 数据报→1 个应用报文的逻辑,应用层发什么,最后就能收到什么,边界完全保留。
说明:
如果应用层交下的报文太大,IP 层可能会分片传输;
如果太小,会导致首部相对开销增大;
所以应用层要自己控制报文长度,以平衡效率和开销。
(4) 无拥塞控制
UDP 发送速率完全由应用决定,网络出现丢包也不降低速率。
适用于实时应用(如语音、视频会议),因为它们容忍部分丢包但不容忍延迟。
(5) 支持一对一、一对多、多对一、多对多通信
UDP 的通信灵活性高,适用于广播和多播场景。
例如:
DNS 查询:一对一
视频直播:一对多
日志汇聚:多对一
P2P:多对多
(6) 首部开销小
UDP 报文首部仅 8 字节(相比 TCP 的 20 字节),结构简单、处理快速。
下面举例说明UDP的通信和端口号的关系(如图5-4所示)
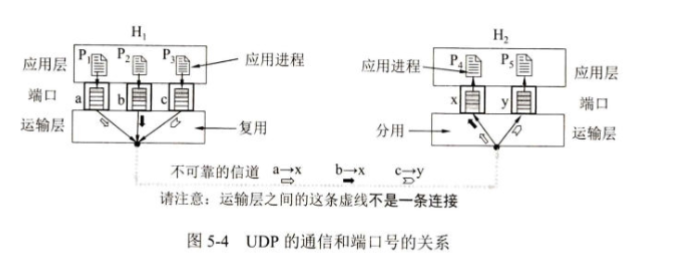
1. 通信的端点不是主机,而是进程:网络通信的最终目的不是一台计算机与另一台计算机对话,而是这台计算机上的一个应用进程与另一台计算机上的一个应用进程对话。IP地址只能把数据报送到目标主机,但无法区分主机上的哪个程序应该接收这个数据。
2. 端口号是进程的“地址”或“门牌号”:为了在同一台主机内区分不同的应用进程,运输层引入了端口号的概念。每个需要通信的进程都会被分配一个端口号。这样,“IP地址” + “端口号” 就唯一地确定了互联网上的一个通信端点。
3. 多路复用与多路分解:
复用:发送方(如主机H₁)的多个应用进程(P₁, P₂, P₃)可以通过不同的端口(a, b, c)将数据交给同一个运输层协议(UDP)。UDP将这些数据打包后,统一使用下层的网络层(IP)服务发送出去。这就是多对一的复用。
分用:接收方(如主机H₂)的运输层(UDP)从IP层收到数据报后,根据数据报首部中的目的端口号(x 或 y),将数据正确地交付给相应的应用进程(P₄ 或 P₅)。这就是一对多的分用。
4. UDP通信的特点:无连接和不可靠:
图中两个运输层之间的虚线强调了UDP是无连接的。通信前不需要像TCP那样先建立连接。
正因为无连接,它也是不可靠的。不保证数据不丢失、不保证数据顺序到达。它的优点是简单、开销小。
UDP 的首部格式
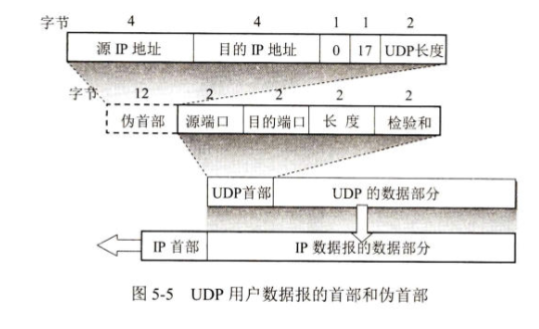
字段解释:
源端口号(Source Port):
标识发送进程,若不需要可填 0。
目的端口号(Destination Port):
标识接收进程,必须填写。
长度(Length):
UDP 首部 + 数据的总长度,最小值为 8(仅首部)
校验和(Checksum):
用于检测首部和数据是否出错。
若检测出错或目的端口不存在,接收方丢弃该报文并返回 ICMP 错误报文(端口不可达)。
UDP 校验和计算
UDP 校验和计算使用伪首部参与计算。伪首部不实际传输,仅用于检验。
所谓伪首部是因为这种伪首部并不是UDP用户数据报真正的首部。只是在计算检验和时,临时添加在UDP用户数据报前面,得到一个临时的UDP用户数据报。检验和就是按照这个临时的UDP用户数据报来计算的。伪首部既不向下传送也不向上递交,而仅仅是为了计算检验和
伪首部字段包括:
| 字段 | 说明 |
|---|---|
| 源 IP 地址 | 来自 IP 层首部 |
| 目的 IP 地址 | 来自 IP 层首部 |
| 保留字段 | 全 0(8 位) |
| 协议号 | 表示 UDP(17) |
| UDP 长度 | 与 UDP 首部中的长度相同 |
将伪首部 + UDP 首部 + 数据部分拼接成一个整体,按 16 位为单位求和取反,即为校验和。
接收端按同样方法计算并比较,若不一致则说明出错。
UDP 校验和示例(图 5-6)
假设:
源 IP:153.19.8.104
目的 IP:171.3.14.11
UDP 长度:15 字节
源端口:1087
目的端口:13
数据:若干字节
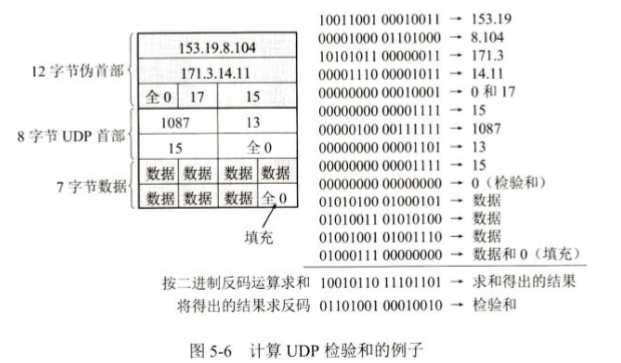
发送方将数据划分为16位(2字节)的字,将所有字进行二进制反码加法求和,最后对求和结果取反码,得到校验和。接收方进行同样的计算,如果结果不为全1(即十进制65535),则说明数据在传输中出错。
在计算开始前,数据中预留的校验和字段必须全部置为0
如图5-6所示,伪首部的第3字段是全零;第4字段是IP首部中的协议字段的值。以前曾讲过,对于UDP,此协议字段值为17;第5字段是UDP用户数据报的长度。因此,这样的检验和,既检查了UDP用户数据报的源端口号和目的端口号以及UDP用户数据报的数据部分,又检查了IP数据报的源IP地址和目的地址。
所以校验范围不仅包含 UDP 的首部和数据,还包含 IP 层的源地址和目的地址。
二进制反码求和的核心是符号位参与运算,进位循环加到结果最低位
反码表示:
正数:符号位为 0,数值位与原码一致(如 +3 反码:0011)
负数:符号位为 1,数值位是原码数值位的取反(如 -3 原码:1011 → 反码:1100)