JavaSe—Set集合
目录
1、认识Set集合的特点和常用操作
2、HashSet集合的底层原理
2.1 哈希值
2.2 哈希表
2.3 红黑树
3、HashSet集合元素的去重操作.
4、LinkedHashSet集合的底层原理
5、TreeSet集合
6、总结
1、认识Set集合的特点和常用操作
Set系列集合特点:无序:添加数据的顺序和获取出的数据顺序不一致;不重复、无索引;
- HashSet:无序、不重复、无索引。
- LinkedHashSet:无序、不重复、无索引。
- TreeSet:排序、不重复、无索引。
- 注意:Set要用的常用方法,基本上都是Collection提供的!!自己几乎没有额外新增一些常用功能!
import java.util.HashSet;
import java.util.Iterator;
import java.util.LinkedHashSet;
import java.util.TreeSet;public class SetDemo1 {public static void main(String[] args) {//// HashSet 无序,不可重复,无索引HashSet<String> set = new HashSet(); //一行经典代码set.add("hello");set.add("world");set.add("java");set.add("hello"); //添加重复元素set.add("55");System.out.println("无序,不可重复->: " + set);set.remove("55");System.out.println("删除55->: " + set);//LinkedHashSet//有序,不可重复,无索引LinkedHashSet<String> linkedHashSet = new LinkedHashSet();linkedHashSet.add("hello");linkedHashSet.add("world");linkedHashSet.add("java");linkedHashSet.add("hello");linkedHashSet.add("55");System.out.println("有序,不可重复->: " + linkedHashSet);//TreeSet////有序,不可重复,无索引TreeSet<String> treeSet = new TreeSet();treeSet.add("hello");treeSet.add("world");treeSet.add("java");treeSet.add("hello");treeSet.add("55");System.out.println("排序,不可重复->: " + treeSet);System.out.println("最小值->: " + treeSet.first());System.out.println("最大值->: " + treeSet.last());System.out.println("删除55->: " + treeSet.remove("55"));TreeSet< Integer> treeSet1 = new TreeSet();treeSet1.add(1);treeSet1.add(5);treeSet1.add(2);treeSet1.add(4);System.out.println("排序,不可重复->: " + treeSet1);//Str怎么遍历for (String s : treeSet) {System.out.println(s);}//迭代器for (Iterator<String> it = treeSet.iterator(); it.hasNext();) {String s = it.next();System.out.println(s);}//函数式treeSet1.forEach(s -> System.out.print(s + " "));}
}
/*
无序,不可重复->: [55, world, java, hello]
删除55->: [world, java, hello]
有序,不可重复->: [hello, world, java, 55]
排序,不可重复->: [55, hello, java, world]
最小值->: 55
最大值->: world
删除55->: true
排序,不可重复->: [1, 2, 4, 5]
hello
java
world
hello
java
world
1 2 4 5
./
2、HashSet集合的底层原理
思考:为什么HashSet集合中存储的数据是无序、不重复、无索引的?带着此问题去学习底层原理。
2.1 哈希值
- 就是一和int 类型的随机值,Java中每个对象都一个哈希值。
- Java中对象,都可以调用Obejct类提供的hashCode方法,返回该对象自己的哈希值。
public hashCode(); //返回对象的哈希码值
对象哈希值的特点
- 同一个对象多次地调用HashCode() 方法返回的哈希值是相同的。
- 不同的对象,它们的哈希值大概率不相等,但是也有可能会想等(哈希碰撞)。
public class SetDemo2 {public static void main(String[] args) {String a = "hello";String b = "hello world";System.out.println(a.hashCode());System.out.println(b.hashCode());}
}
/*
99162322
1794106052*/2.2 哈希表
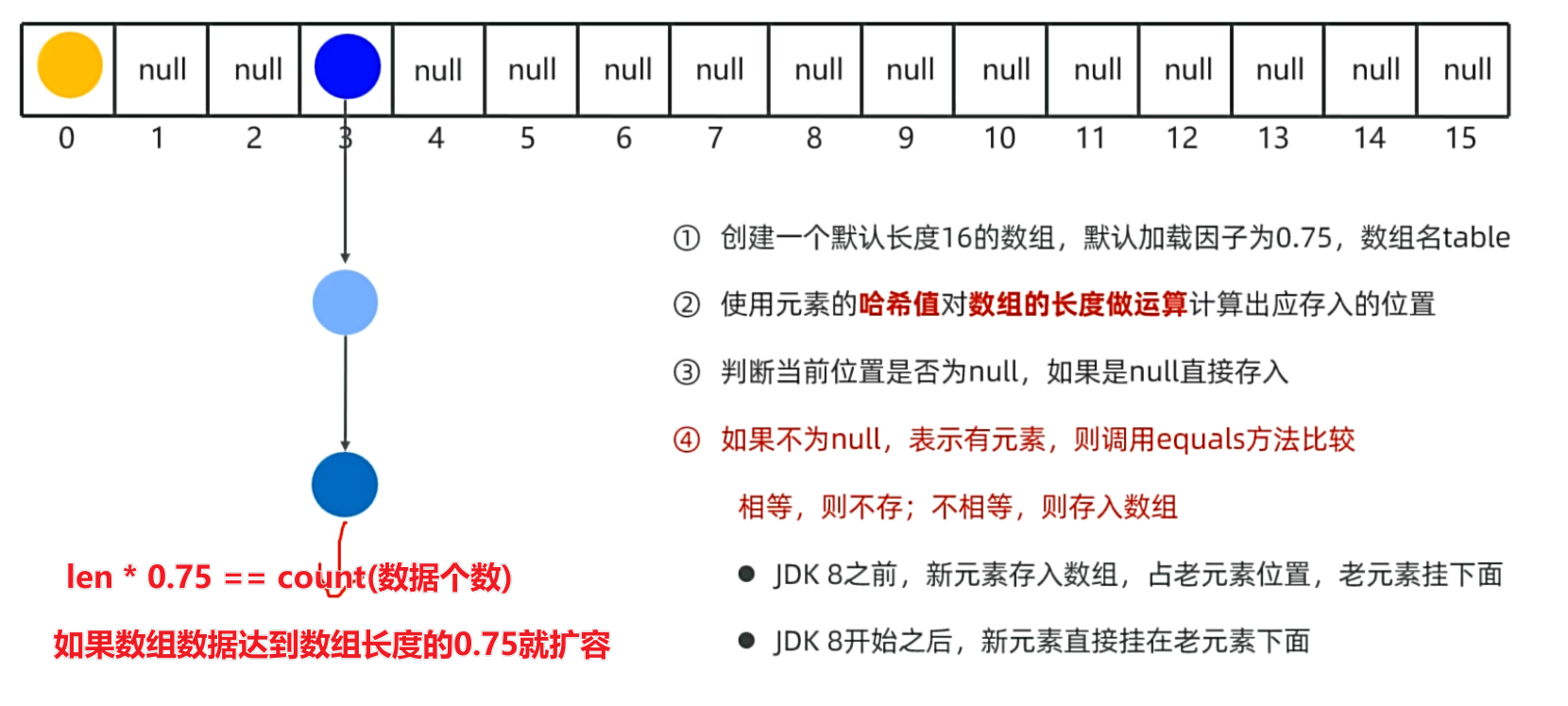
- HashSet是基于哈希表存储数据的。
哈希表
- JDK8之前,哈希表 = 数组 + 链表
- JDK8开始,哈希表 = 数组 + 链表 + 红黑树
- 哈希表是一种增删改查数据,性能都较好的数据结构。
JDK之前的哈希表:数组 + 链表
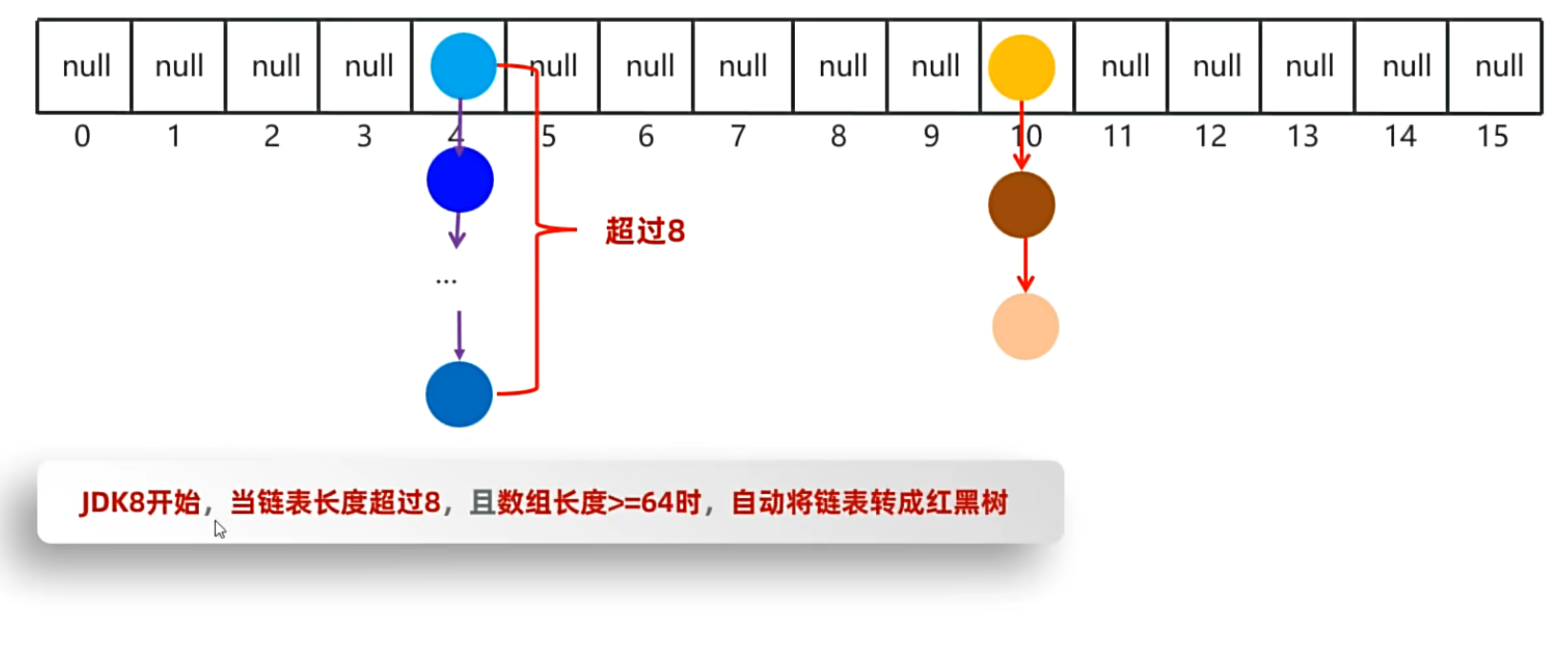
JDK8开始哈希表:数组 + 链表 + 红黑树
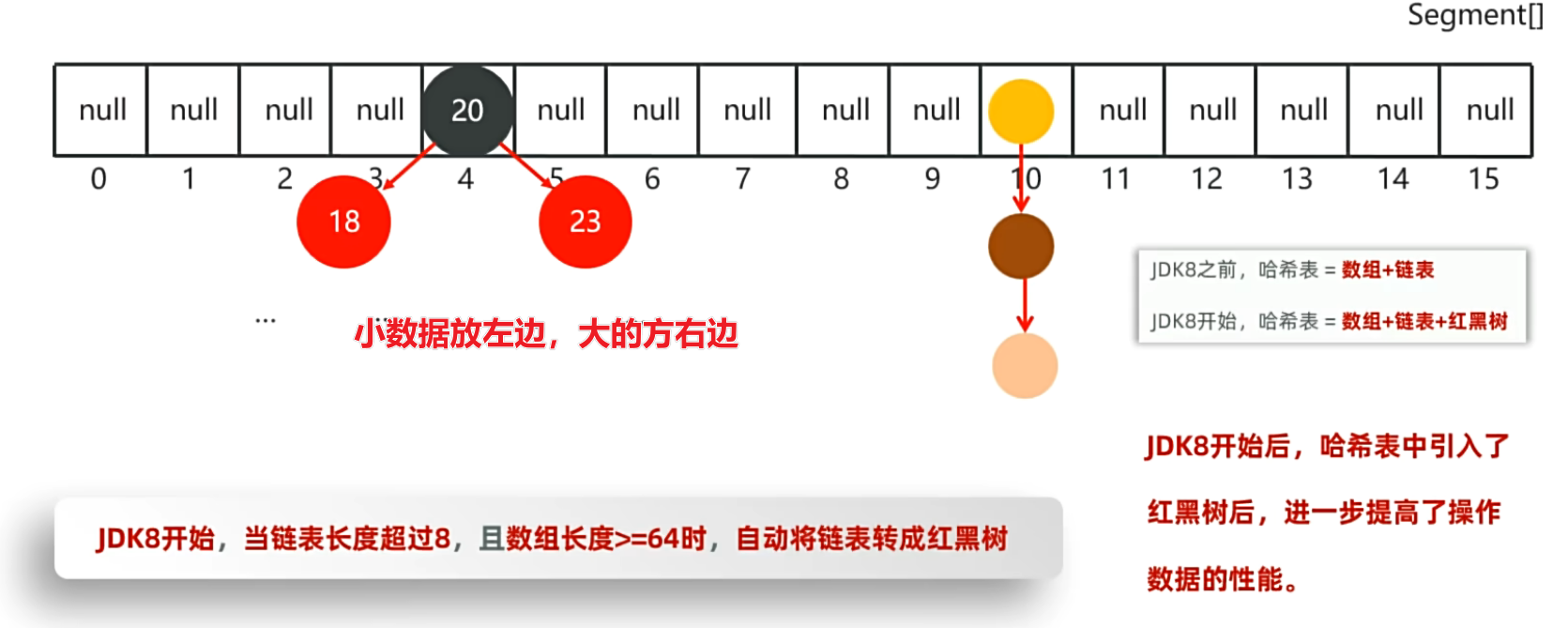
2.3 红黑树
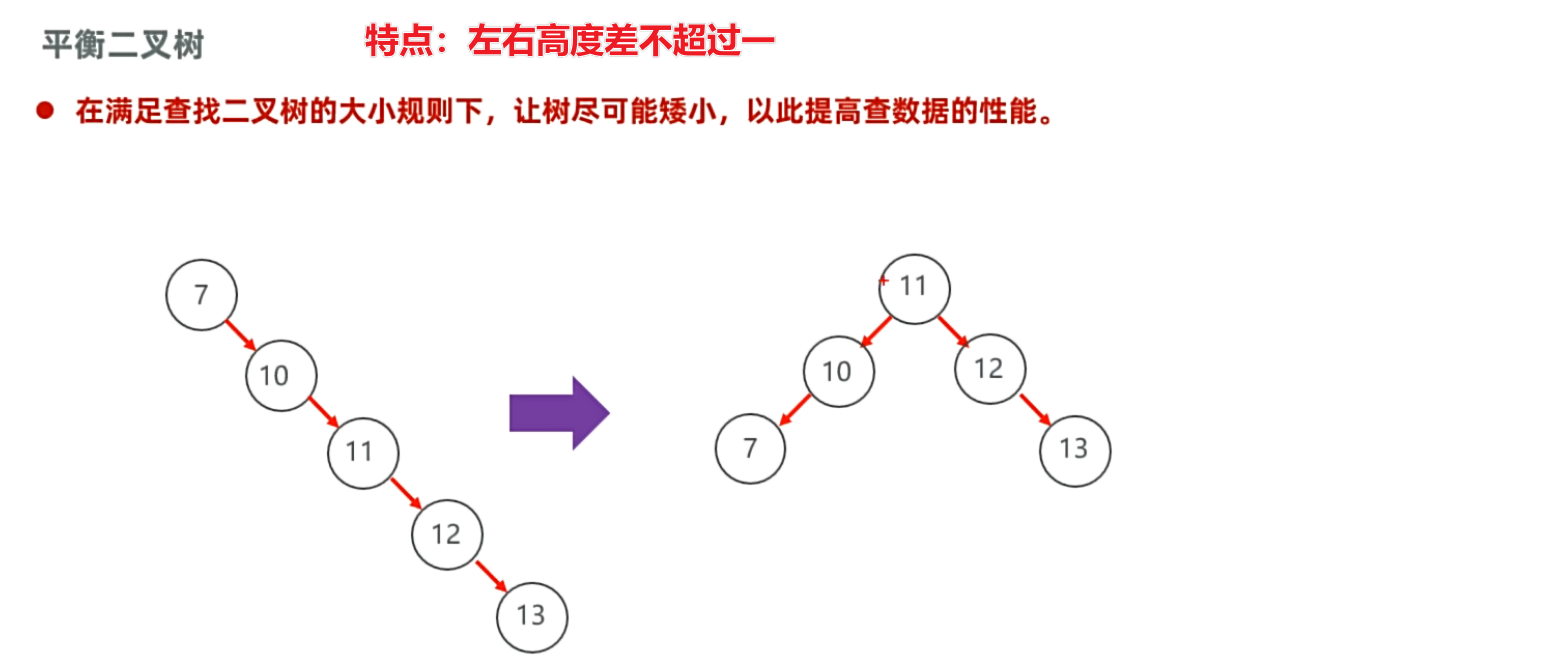
从二叉树开始理解
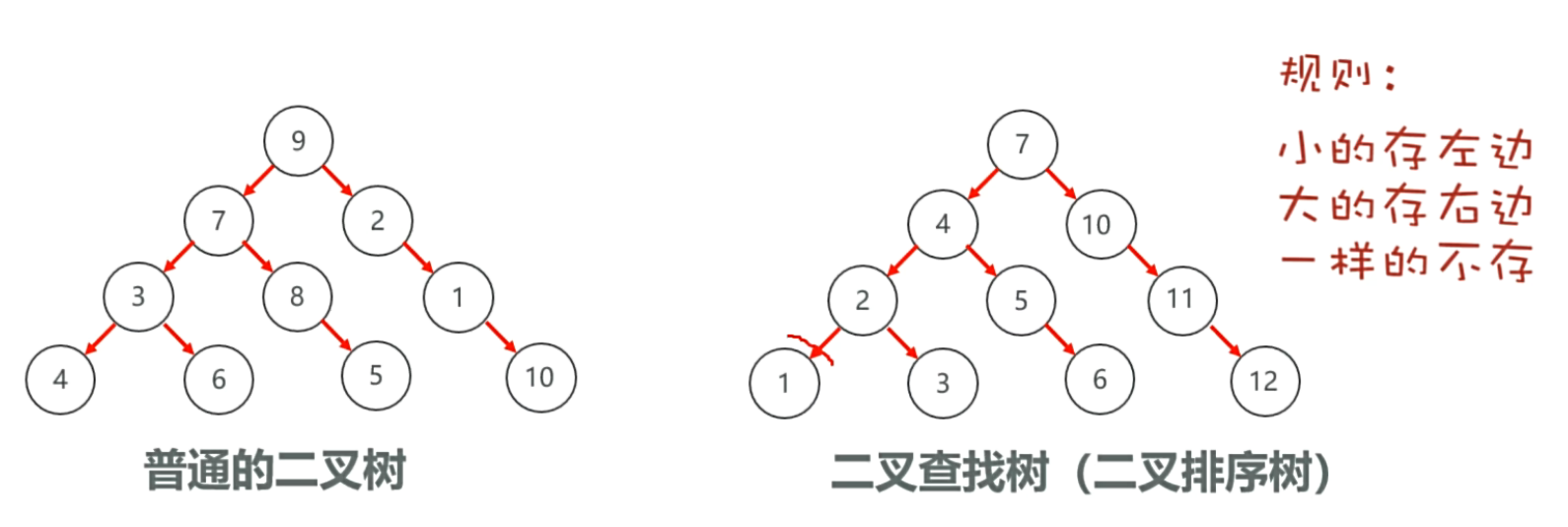
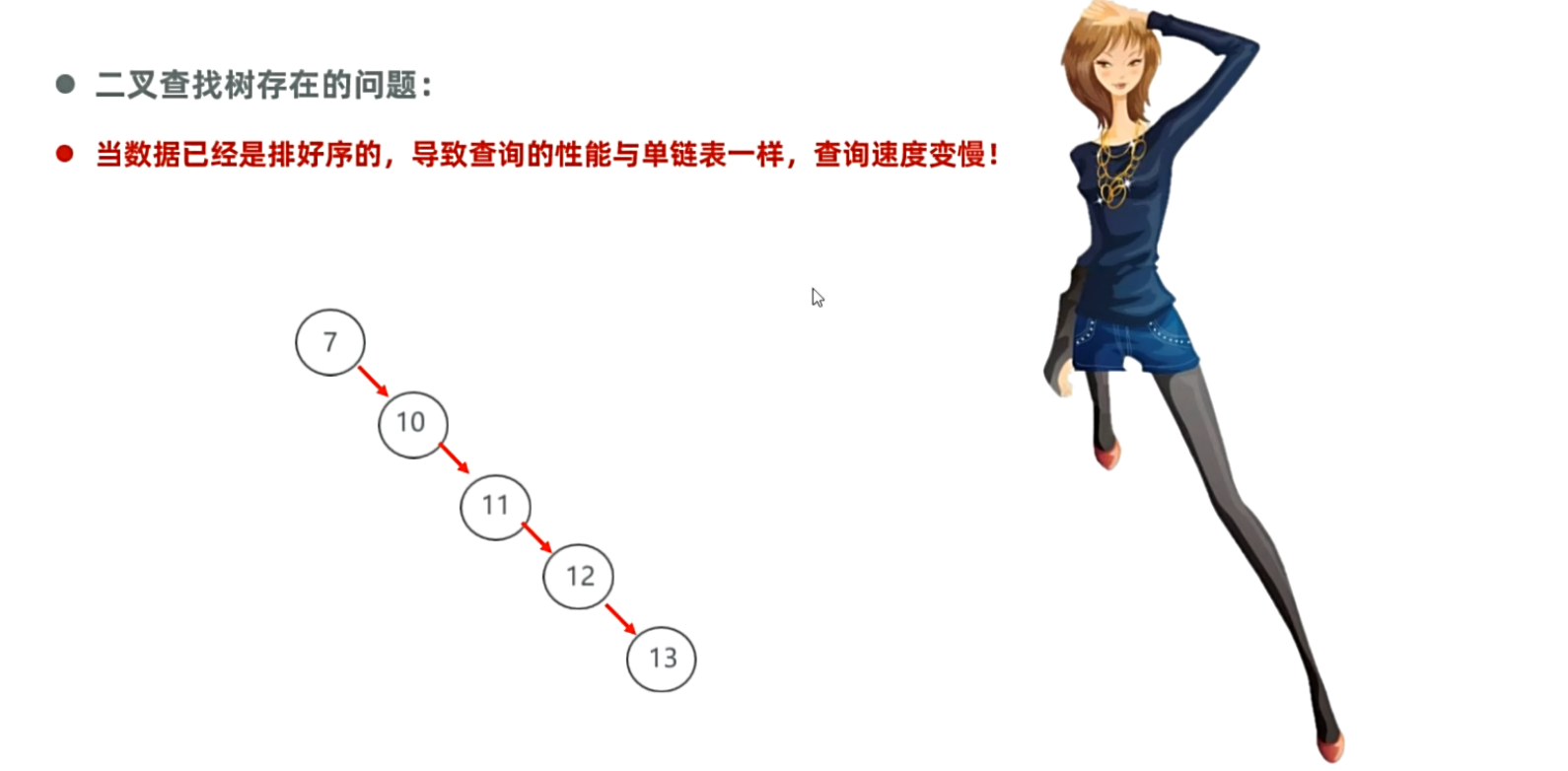
解决方法
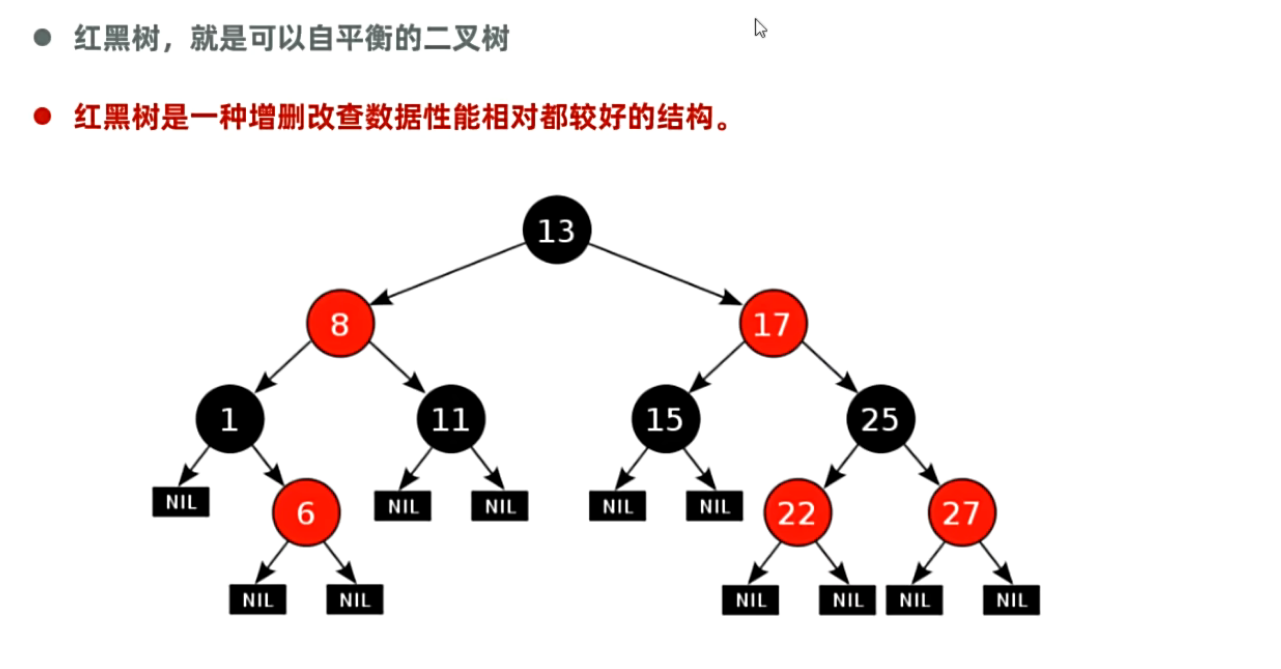
3、HashSet集合元素的去重操作.


public class Student {//属性private String name;private int age;private char sex;public Student(String name, int age, char sex) {this.name = name;this.age = age;this.sex = sex;}public Student() {}public String getName() {return name;}public void setName(String name) {this.name = name;}public int getAge() {return age;}public void setAge(int age) {this.age = age;}public char getSex() {return sex;}public void setSex(char sex) {this.sex = sex;}@Overridepublic String toString() {return "Student{" +"name='" + name + '\'' +", age=" + age +", sex=" + sex +'}' + "\n";}
}import java.util.HashSet;
public interface SetDemo3 {public static void main(String[] args) {Student s1 = new Student("小王", 18, '男');Student s2 = new Student("小王", 18, '男');Student s3 = new Student("小颜", 18, '女');//创建HashSet集合HashSet<Student> set = new HashSet<>();set.add(s1);set.add(s2);set.add(s3);System.out.println(set); //发现并没有去重}
}
/*
[Student{name='小颜', age=18, sex=女}
, Student{name='小王', age=18, sex=男}
, Student{name='小王', age=18, sex=男}
]*/发现上面完全相同并没有去重
解决方案:
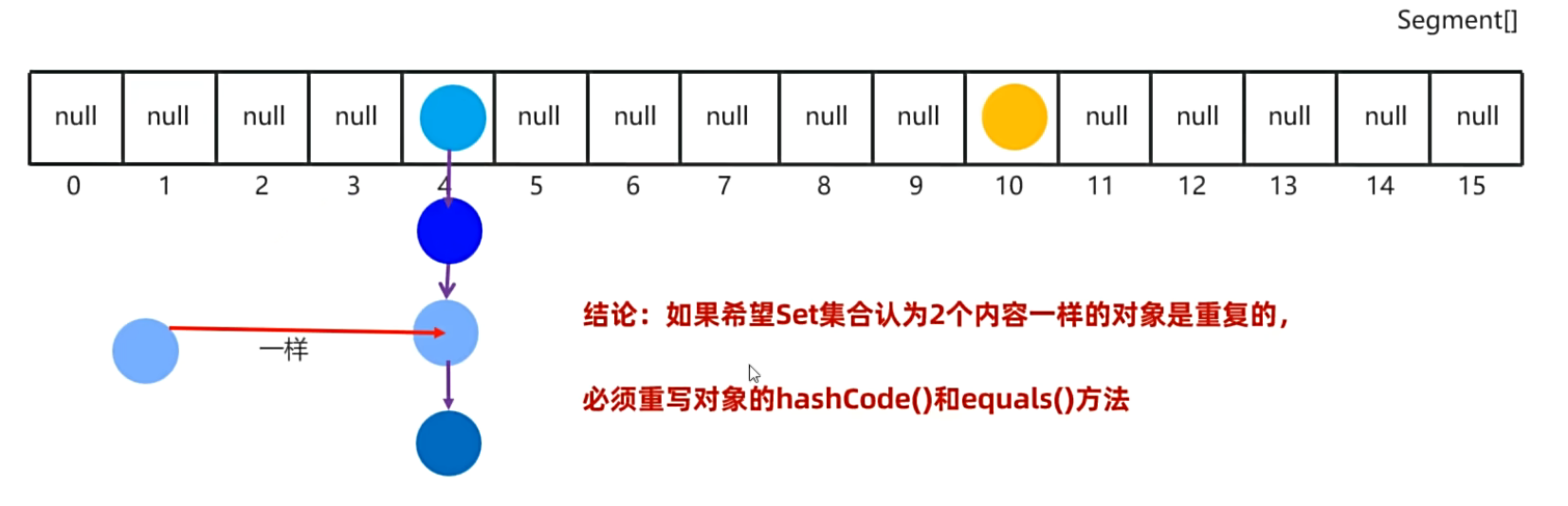
import java.util.Objects;public class Student {//属性private String name;private int age;private char sex;public Student(String name, int age, char sex) {this.name = name;this.age = age;this.sex = sex;}public Student() {}public String getName() {return name;}public void setName(String name) {this.name = name;}public int getAge() {return age;}public void setAge(int age) {this.age = age;}public char getSex() {return sex;}public void setSex(char sex) {this.sex = sex;}@Overridepublic String toString() {return "Student{" +"name='" + name + '\'' +", age=" + age +", sex=" + sex +'}' + "\n";}//重写hashCode() 方法 和 equals() 方法@Overridepublic boolean equals(Object o) {//1、判断对象是否是同一个对象 如果自己和自己相等,则返回trueif (this == o) return true;//2、判断对象是否是null 如果对象是null,则返回false//如果不是此类型的对象,则返回falseif (o == null || getClass() != o.getClass()) return false;//3、将参数转为Student类型 因为传入的参数是Object类型Student student = (Student) o;//4、比较属性是否相同return age == student.age && sex == student.sex && Objects.equals(name, student.name);}@Overridepublic int hashCode() {return Objects.hash(name, age, sex);}
}
import java.util.HashSet;
public interface SetDemo3 {public static void main(String[] args) {Student s1 = new Student("小王", 18, '男');Student s2 = new Student("小王", 18, '男');Student s3 = new Student("小颜", 18, '女');//创建HashSet集合HashSet<Student> set = new HashSet<>();set.add(s1);set.add(s2);set.add(s3);System.out.println(set); //发现并没有去重}
}
/*
[Student{name='小王', age=18, sex=男}
, Student{name='小颜', age=18, sex=女}
]*/4、LinkedHashSet集合的底层原理
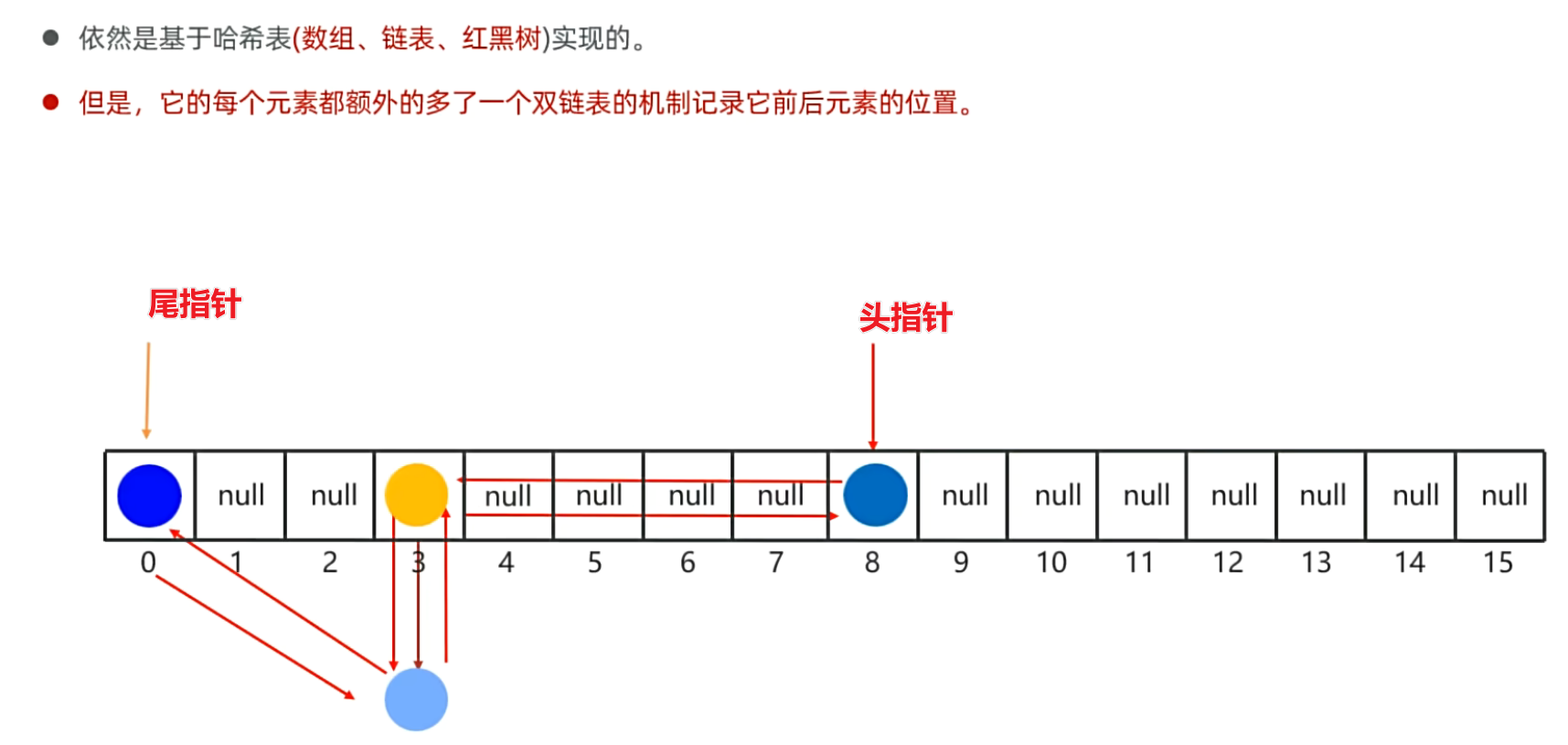
缺点:牺牲了内存换来了有序的特点。
5、TreeSet集合

import lombok.Data;
import lombok.NoArgsConstructor;
import lombok.AllArgsConstructor;@NoArgsConstructor
@AllArgsConstructor
@Data
public class Teacher implements Comparable<Teacher> {private String name;private int age;//薪水private double salary;@Overridepublic String toString() {return "Teacher{" +"name='" + name + '\'' +", age=" + age +", salary=" + salary +'}' + "\n";}//t2.compareTo(t1)//t2 == this//t1 = o;//规则如果是升序,则返回值应该为正数//规则如果是降序,则返回值应该为负数//如果返回值0,认为左右边相等@Overridepublic int compareTo(Teacher o) {return this.getAge() - o.getAge();//上面的去重了如果不想去重
// if(this.getAge() == o.getAge()){
// return 1;
// }else if(this.getAge() > o.getAge()){
// return 1;
// }else{
// return -1;
// }}
}
import java.util.Comparator;
import java.util.TreeSet;public class SetDemo4 {public static void main(String[] args) {//目标:搞清楚TreeSet集合对自定义对象的排序Teacher t1 = new Teacher("小王", 18, 6000);Teacher t2 = new Teacher("光头强", 20, 5000);Teacher t3 = new Teacher("熊大", 19, 4000);Teacher t4 = new Teacher("小张", 18, 3000);//创建TreeSet集合//结论:TreeSet集合存储自定义对象时,要求对象必须实现Comparable接口,并重写compareTo方法//方法2、public TreeSet(Comparator<? super E> comparator) 自带比较器Comparator对象,指定排序规则TreeSet<Teacher> set = new TreeSet();set.add(t1);set.add(t2);set.add(t3);set.add(t4);System.out.println(set);System.out.println("利用方法2 降序");TreeSet<Teacher> set2 = new TreeSet(new Comparator<Teacher>() {@Overridepublic int compare(Teacher o1, Teacher o2) {return o2.getAge() - o1.getAge();//按照薪水
// return o2.getSalary() - o1.getSalary(); //报错//改进1
// if(o1.getSalary() > o2.getSalary()){
// return 1;
// }else if(o1.getSalary() < o2.getSalary()){
// return -1;
// }else{
// return 0;
// }//改进2
// return Double.compare(o1.getSalary(), o2.getSalary());}});// 上面代码简化形式set2.add(t1);set2.add(t2);set2.add(t3);set2.add(t4);System.out.println(set2);TreeSet<Teacher> set3 = new TreeSet<>(( o1, o2) ->o1.getAge() - o2.getAge());}
}
/*
//利用方法1 升序
[Teacher{name='小王', age=18, salary=6000.0}
, Teacher{name='熊大', age=19, salary=4000.0}
, Teacher{name='光头强', age=20, salary=5000.0}
]
//利用方法2 降序
利用方法2 降序
[Teacher{name='光头强', age=20, salary=5000.0}
, Teacher{name='熊大', age=19, salary=4000.0}
, Teacher{name='小王', age=18, salary=6000.0}
]*/6、总结
