【具身智能】Spatial Forcing 论文笔记 如何隐式地为 VLA 注入 3D 空间感知能力
Spatial Forcing
Implicit Spatial Representation Alignment For Vision-Language-Action Model
🧠 摘要(Abstract)
✅ 研究背景
视觉-语言-动作模型(VLA)能让机器人根据语言指令执行动作,展现出巨大潜力。
⚠️ 核心问题
大多数 VLA 模型基于仅在 2D 图像 上预训练的视觉-语言模型(VLM),缺乏对 3D 空间结构 的理解,难以在物理世界中精确操作。
🔍 现有方法及其局限
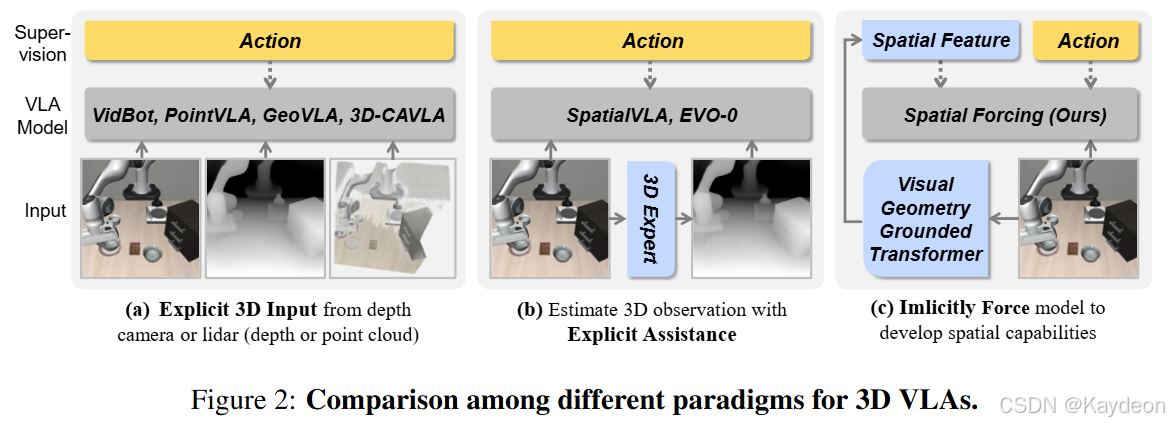
- 显式引入 3D 输入(如深度图、点云):
- 问题:传感器噪声大、硬件差异大、数据不完整。
- 从 2D 图像估计 3D 信息:
- 问题:深度估计器性能有限,导致策略次优。
🌟 本文方法:Spatial Forcing(SF)
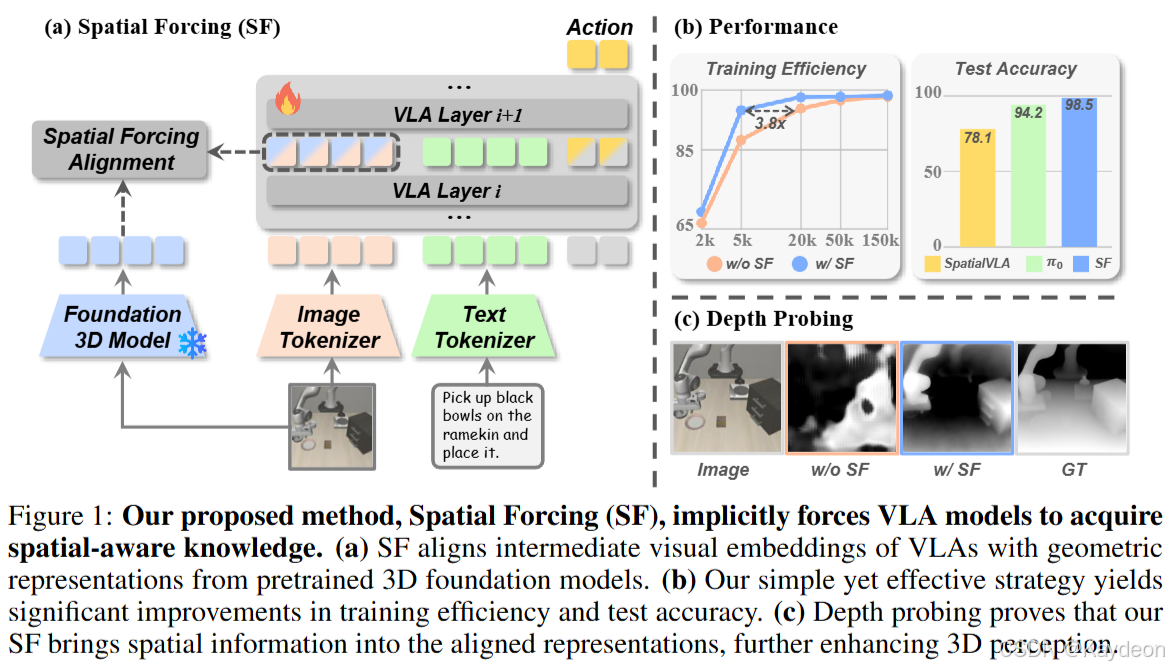
- 核心思想:隐式地 迫使 VLA 模型发展空间理解能力,不依赖 显式 3D 输入或深度估计器。
- 实现方式:将 VLA 的 中间视觉嵌入 与 预训练 3D 基础模型(如 VGGT)生成的几何表征进行对齐。
- 效果:
- 提升动作精度;
- 训练速度提升 3.8 倍;
- 数据效率更高;
- 在模拟与真实环境中均达到 SOTA 性能。
📖 第一章:引言(Introduction)
🔁 问题重述
- VLA 模型通常基于 VLM 构建,继承其语义理解能力;
- 但 VLM 仅在 2D 数据上训练,缺乏 3D 空间感知能力;
- 导致机器人在 3D 环境中难以完成精确操作。
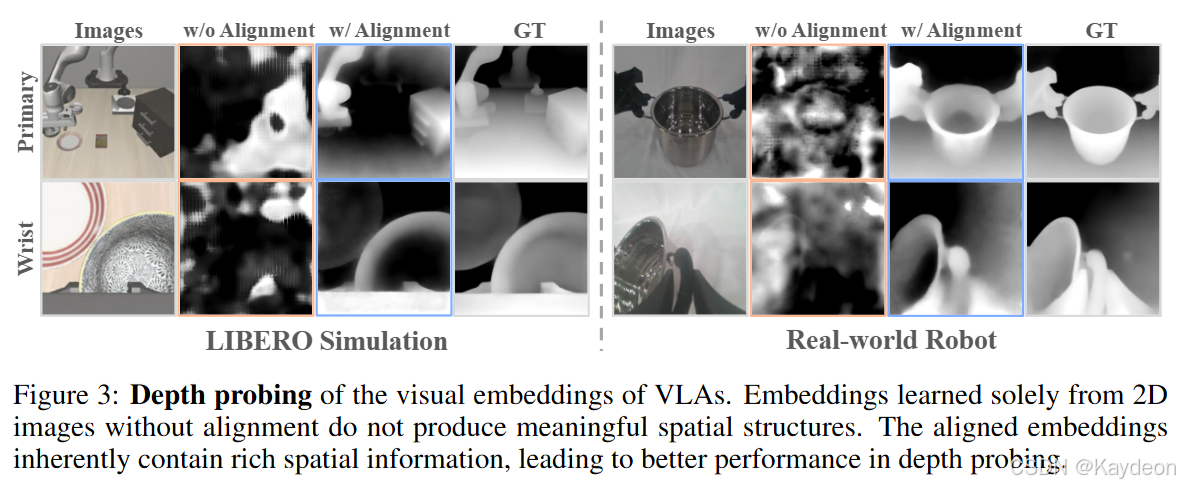
🧪 动机实验:深度探测(Depth Probing)
- 做法:冻结 VLA 模型的视觉编码器,仅训练一个 DPT 头部来预测深度图;
- 结果:预测出的深度图无意义,说明 VLA 的视觉嵌入中缺乏空间信息;
- 结论:VLA 模型在没有外部空间监督的情况下,无法有效编码 3D 结构。
🌟 提出方法:Spatial Forcing(SF)
- 目标:让 VLA 模型隐式地获得 3D 感知能力;
- 方法:将 VLA 的中间视觉嵌入与 VGGT(3D 基础模型)输出的空间表征对齐;
- 优势:
- 不增加推理开销;
- 不依赖 3D 传感器;
- 可提升动作精度与训练效率。
🧪 第二章:方法(Method)
2.1 预备知识(Preliminaries)
🧠 VLA 模型结构
VLA 模型基于 VLM,处理三种模态:
- 视觉模态:多视角图像 → 编码为视觉 token:
{xiV}i=1N\{x_i^V\}_{i=1}^N{xiV}i=1N - 语言模态:任务指令 → 编码为语言 token:
{xjL}j=1M\{x_j^L\}_{j=1}^M{xjL}j=1M - 动作模态:基于视觉和语言 token,自回归地生成动作 token:
{xkA}k=1K\{x_k^A\}_{k=1}^K{xkA}k=1K
🔢 动作生成公式(公式 1):
xtA∼pθ(xtA∣{xiV}i=1N,{xjL}j=1M,x<tA) x_t^A \sim p_\theta\left(x_t^A \mid \{x_i^V\}_{i=1}^N, \{x_j^L\}_{j=1}^M, x_{<t}^A\right) xtA∼pθ(xtA∣{xiV}i=1N,{xjL}j=1M,x<tA)
- xtAx_t^AxtA:第 ttt 个动作 token;
- pθp_\thetapθ:参数为 θ\thetaθ 的条件概率模型;
- x<tAx_{<t}^Ax<tA:之前生成的动作 token。
📉 动作损失函数(公式 2):
Laction=L[G({xkA}),Agt] \mathcal{L}_{\text{action}} = \mathcal{L}\left[\mathcal{G}(\{x_k^A\}), A_{\text{gt}}\right] Laction=L[G({xkA}),Agt]
- G\mathcal{G}G:动作专家(如 MLP),将动作 token 解码为实际动作;
- AgtA_{\text{gt}}Agt:真实动作标签;
- L\mathcal{L}L:损失函数(如 L1、L2)。
🧠 VGGT 模型
- 输入:2D 图像;
- 输出:3D 属性(深度图、点云、相机参数等);
- 本文中用于提供 空间监督信号。
2.2 动机(Motivation)
- 2D VLA 模型缺乏 3D 理解;
- 显式引入 3D 数据存在噪声、异构、缺失等问题;
- 从 2D 估计 3D 又不准确;
- 结论:需要一种 不依赖显式 3D 输入 的方法来增强 VLA 的空间理解能力。
2.3 Spatial Forcing(SF)
🎯 目标
通过外部 3D 模型(VGGT)提供的空间表征,监督 VLA 的视觉嵌入,使其 隐式地 具备 3D 感知能力。
🧮 对齐损失函数(公式 3):
Lalign=−1N∑i=1NS[MLP⋅Γ(xiV),fi3D(I)+E] \mathcal{L}_{\text{align}} = -\frac{1}{N} \sum_{i=1}^N \mathcal{S}\left[\text{MLP} \cdot \Gamma(x_i^V), f_i^{3D}(I) + E\right] Lalign=−N1i=1∑NS[MLP⋅Γ(xiV),fi3D(I)+E]
- xiVx_i^VxiV:VLA 的视觉 token;
- Γ\GammaΓ:BatchNorm;
- MLP:两层感知机,用于维度对齐;
- fi3D(I)f_i^{3D}(I)fi3D(I):VGGT 输出的空间表征;
- EEE:位置编码,保留 token 的位置信息;
- S\mathcal{S}S:余弦相似度;
- 目标:最大化 VLA 视觉 token 与 3D 表征之间的相似性。
🧠 监督哪一层?
- 实验发现:第 24 层(共 32 层)效果最好;
- 太浅:表征未充分提取;
- 太深:视觉特征已融合语言信息,不适合空间监督。
📦 总损失函数(公式 4):
LSF=Laction+α⋅Lalign \mathcal{L}_{\text{SF}} = \mathcal{L}_{\text{action}} + \alpha \cdot \mathcal{L}_{\text{align}} LSF=Laction+α⋅Lalign
- α\alphaα:权重因子,实验中设为 0.5;
- 平衡动作预测与空间对齐两个目标。
✅ 推理阶段
- VGGT 和对齐损失被完全移除;
- VLA 模型结构与标准模型完全一致;
- 不增加任何推理开销。
📊 第三章:仿真实验(Simulation Experiments)
3.1 实验设置
- 平台:LIBERO(4 个任务套件)、RoboTwin(双臂任务);
- 基础模型:
- LIBERO:OpenVLA-OFT;
- RoboTwin:π0\pi_0π0;
- 指标:任务成功率(SR)。
3.2 与 SOTA 方法对比
- LIBERO:SF 平均成功率 98.5%,超过所有 2D 和 3D 方法;
- RoboTwin:SF 在所有任务中均表现最佳,尤其在困难设置中提升显著。
3.3 消融实验(Ablation Study)
| 实验项 | 结论 |
|---|---|
| 目标表征 | 使用 VGGT + 位置编码最佳(96.9%) |
| 对齐层数 | 第 24 层最佳 |
| 训练效率 | SF 实现 3.8 倍 加速 |
| 数据效率 | 仅用 5% 数据达到 75.8% 成功率,5.9 倍 数据效率提升 |
| t-SNE 可视化 | VLA 特征与目标结构一致,但未发生表征崩溃 |
🤖 第四章:真实世界实验(Real-World Experiments)
设置
- 平台:AgileX 双臂机器人;
- 数据量:单臂 40 条演示,双臂 20 条;
- 任务:
- 单臂:堆叠玻璃杯(光照变化)、抓蔬菜(物体变化)、放积木(高度变化);
- 双臂:举罐子(平衡测试);
结果
| 任务 | 基线 | SF | 提升 |
|---|---|---|---|
| 堆叠玻璃杯 | 15.0% | 62.5% | +47.5% |
| 抓蔬菜 | 10.0% | 47.5% | +37.5% |
| 放积木 | 67.5% | 85.0% | +17.5% |
| 举罐子 | 30.0% | 42.5% | +12.5% |
- 结论:SF 显著提升了机器人在真实环境中的 空间理解能力 和 数据效率。
📚 第五章:相关工作(Related Work)
- VLA 模型发展:
- 从 2D 到 3D(引入深度、点云);
- 本文创新:不修改输入,而是监督中间表征;
- 表征监督:
- 重建式:可能保留冗余信息;
- 对齐式(如 SF):更有效,避免表征崩溃。
✅ 第六章:结论(Conclusion)
- 提出 Spatial Forcing,一种隐式增强 VLA 空间感知能力的方法;
- 通过 对齐中间视觉表征 与 3D 基础模型,显著提升性能;
- 在模拟与真实任务中均验证了其 高效性、通用性与实用性。