美团开源啦,源码地址+部署脚本,全模态实时交互
大家好,我是小悟。
美团LongCat-Flash系列又添新成员,LongCat-Flash-Omni正式开源了。

从「能聊天」到「能看会听」
早在今年9月,美团就悄咪咪放出了LongCat-Flash系列的前两个版本(Chat和Thinking)。
当时就因为5600亿参数的大体量还能跑得飞快被圈内人讨论了一波。但那时候的模型还停留在「文字交流」层面,说白了就是个特别能聊天的AI。
而这次新发布的Omni版本,直接把能力从「文字」扩展到了「图、文、音、视」全模态,甚至还能实时语音交互。
举个例子:你拍张菜市场的鱼摊照片,问它「这鱼新鲜不?」它能分析图片里的鱼眼、鱼鳃状态,再结合你对「新鲜」的定义,给出比菜贩子还靠谱的答案。
或者你发段方言语音吐槽加班,它不仅能转文字,可能还能用带情绪的语音回你一句:「摸鱼不如摸键盘,但打工人的命也是命啊!」
5600亿参数还能「秒回」
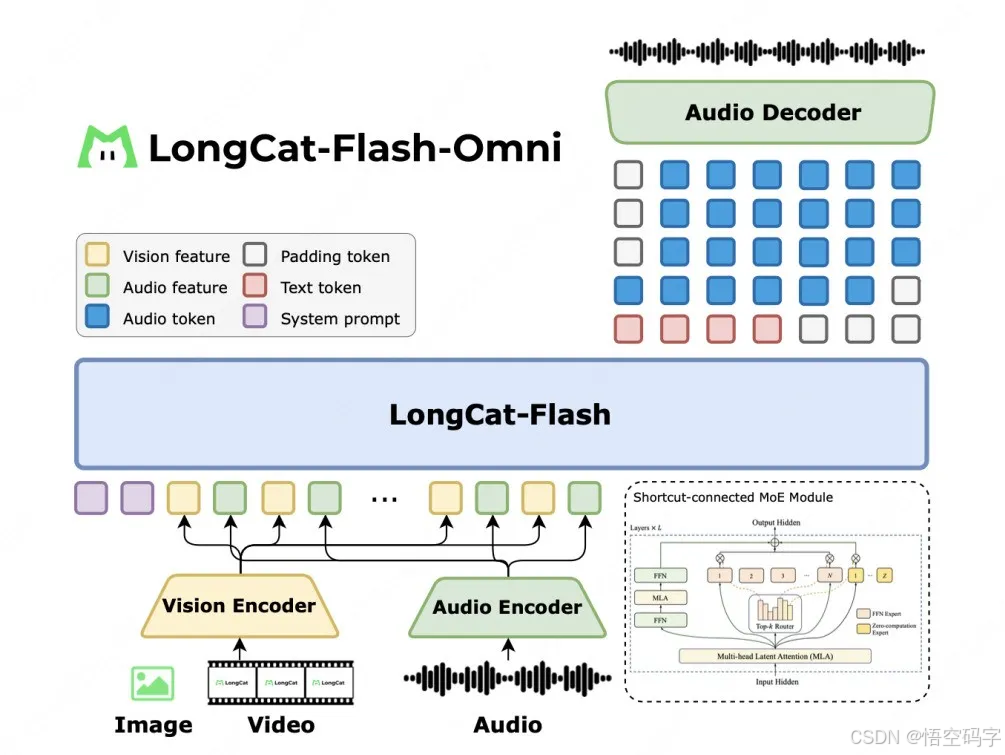
按常理说,模型参数越大,思考越慢。但LongCat-Flash-Omni偏不,5600亿总参数(实际激活270亿)的情况下,居然实现了低延迟的实时音视频交互。
Shortcut-Connected MoE架构(含零计算专家),简单说就是让模型遇到简单问题时直接抄答案,只对复杂问题开足马力算。就像班里学霸,基础题扫一眼就过,难题才认真动笔。
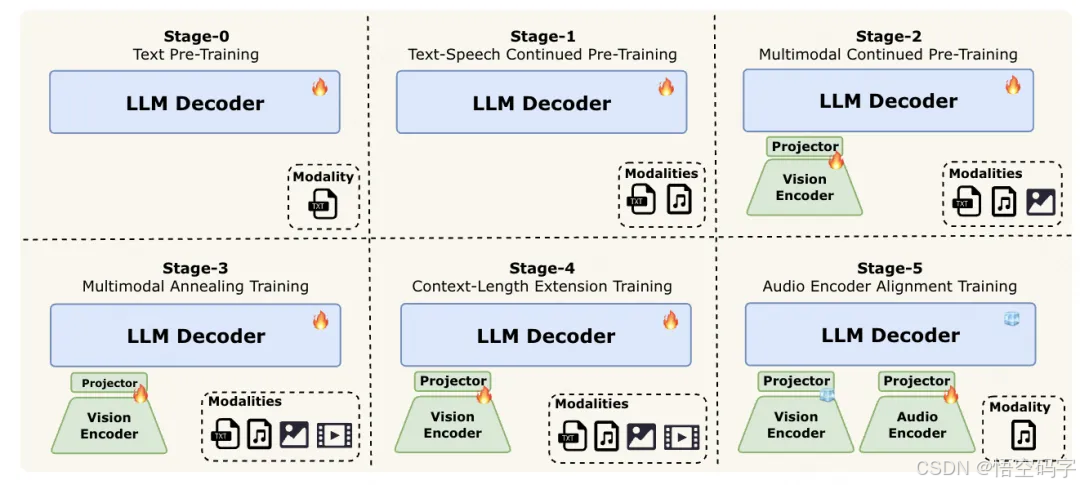
多模态感知+语音重建:给模型装了「眼睛」和「耳朵」,视觉与音频编码器负责理解图片、视频和声音,再通过大语言模型(LLM)处理信息,最后用轻量级解码器把回答变成语音波形。整个过程像流水线作业,效率拉满。
分块式特征交织:支持128K超长上下文和8分钟以上的音视频连续交互,聊久了也不会「断片」。
这点对需要分析长视频或深度对话的场景特别重要,比如看一部电影后让AI总结剧情,或者和长辈视频聊天时它能记住半小时前的话题。
开源才是真·杀手锏
比起某些闭源模型藏着掖着,美团这次直接把LongCat-Flash-Omni的代码和模型权重扔到了Hugging Face和GitHub上,还贴心地配了教程。
入口:https://longcat.aiHugging Face:https://huggingface.co/meituan-longcat/LongCat-Flash-OmniGithub:https://github.com/meituan-longcat/LongCat-Flash-Omni
安装
python >= 3.10.0 (推荐使用 Anaconda)
PyTorch >= 2.8
CUDA >= 12.9conda create -n longcat python=3.10
conda activate longcat# install SGLang
git clone -b longcat_omni_v0.5.3.post3 https://github.com/XiaoBin1992/sglang.git
pushd sglang
pip install -e "python"
popd# install longcat-flash-omni demo
git clone https://github.com/meituan-longcat/LongCat-Flash-Omni
pushd LongCat-Flash-Omni
git submodule update --init --recursive
pip install -r requirements.txt
popd单节点推理
python3 longcat_omni_demo.py \--tp-size 8 \--ep-size 8 \--model-path where_you_download_model_dir \--output-dir output多节点推理
python3 longcat_omni_demo.py \--tp-size 16 \--ep-size 16 \--nodes 2 \--node-rank $NODE_RANK \--dist-init-addr $MASTER_IP:5000 \--model-path where_you_download_model_dir \--output-dir output注意:请将$NODE_RANK 和$MASTER_IP 替换为您的 GPU 机器的相应值
开发者可以快速上手:比如你想做个能听歌识曲+推荐歌单的App,或者开发一个给视障人士读图的工具,直接调用它的多模态能力就行,不用从零训练模型。
中小公司低成本上车AI:以前搞全模态交互得砸钱买昂贵的API服务,现在有了开源版本,相当于免费领了个「技术外挂」。
这是AI落地的重要一步
AI圈总在说「多模态」的概念,但很多停留在实验室阶段。而LongCat-Flash-Omni做到了三点:
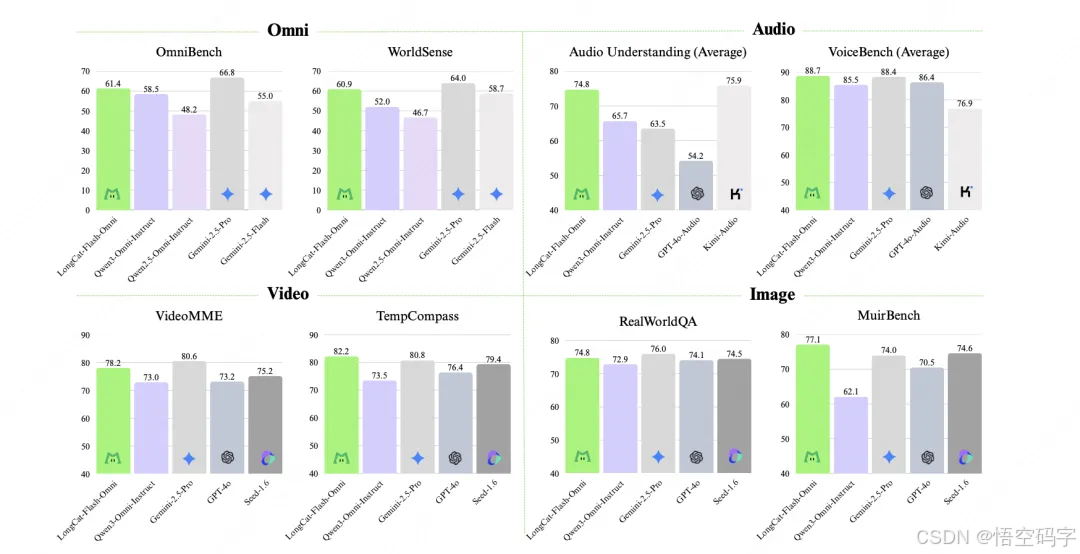
真正的一体化:不是简单拼凑文字、图像、语音模块,而是从底层架构设计时就考虑了多模态融合,就像人的大脑处理信息一样自然。
实用大于炫技:它的能力是解决实际问题。比如视频理解能力对教育、安防行业有用,语音交互对智能硬件是刚需,文本优化则能赋能内容创作。
推动行业竞争:开源后,其他团队可以基于这个模型改进,加速技术迭代。最终受益的还是普通用户,以后遇到的AI产品,大概率会更聪明、更人性化。
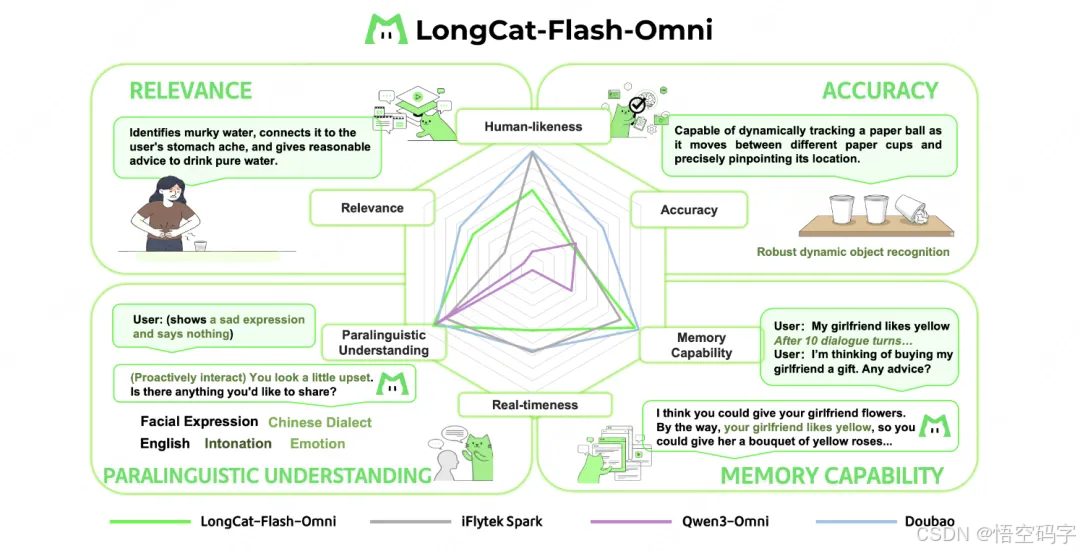
最后
技术不再是巨头的专利:通过开源,美团把原本可能高高在上的大模型能力「平民化」,让更多人能参与到AI应用的开发中。
本地生活的AI渗透:别忘了美团的主业是外卖、到店这些业务。LongCat系列模型未来很可能深度整合进这些场景,比如帮你分析餐厅菜品图判断口味,或者根据语音指令快速下单。
当然,目前的版本可能还有优化空间,但作为一个开源项目,LongCat-Flash-Omni已经给出了一个很好的起点。

谢谢你看我的文章,既然看到这里了,如果觉得不错,随手点个赞、转发、在看三连吧,感谢感谢。那我们,下次再见。
您的一键三连,是我更新的最大动力,谢谢
山水有相逢,来日皆可期,谢谢阅读,我们再会
我手中的金箍棒,上能通天,下能探海