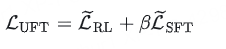SFT 和 RL 融合:CHROD, LUFFY,UFT
1 CHROD
其中, SFT 损失,用于引导模型学习高质量专家数据;
RL 损失(如 GRPO),用于优化任务相关的可验证奖励;
μ为全局控制系数,用于动态平衡 SFT 与 RL 的相对权重。
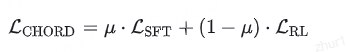
在训练初期设置 μ=0.9,以促使模型优先学习专家行为模式,快速建立基础能力;随后在前 200 个训练步中将 μ 逐步衰减至 0.05;此后保持
μ 不变,使模型主要通过 RL 探索高奖励路径,避免过度依赖静态专家数据。
此外,CHORD 对传统的 SFT 损失进行了改进,引入 token-level 动态加权机制。该机制通过一个权重函数
对每个 token 的学习信号进行调制,使得:
- 当模型对某个 token 的预测概率接近 0 或 1 时(即高度不确定或高度自信),其学习权重自动降低;
- 当预测概率接近 0.5 时(即处于最不确定状态),该 token 权重最大成为学习重点。
这一设计缓解了可能出现的策略崩溃和熵坍缩等问题,显著提升了训练的稳定性与效率。
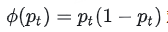
2 LUFFY(“海贼王”)
不同于CHORD,LUFFY 通过设计一个混合优势函数,将 SFT 与 RL 深度融合。该方法的核心在于对在线策略生成的轨迹(RL)和专家策略生成的离线轨迹(SFT)进行统一的优势计算。
具体来说,LUFFY 在计算优势值时,对两类轨迹的奖励进行了联合标准化处理:
其中 τi 是来自混合数据集中的任意轨迹, Gon 和 Goff 分别代表当前策略和专家策略生成的轨迹集合。这种处理方式使得模型能够同时参考自身的探索行为和专家的示范行为。
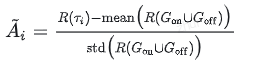
LUFFY 的优化目标是 SFT 和 RL 的损失和:
LUFFY 基于 RL 思想对 SFT 目标进行了重构,使其具备探索能力。改进后的 SFT 损失为:
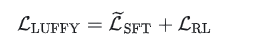
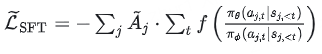
其中包含两项核心设计:
- 优势感知加权(Advantage-Aware Weighting):通过联合标准化的优势值 Aj 对每条专家轨迹进行加权,使模型在训练过程中更关注高奖励的推理路径。
- 策略塑形函数(Policy Shaping Function):采用 f(x) = x/(x+γ) 对重要性比进行非线性压缩。LUFFY 设定专家策略的概率输出为 存在函数1(即 πΦ=1),此时重要性比退化为模型自身的动作概率πθ。在这种设定下, f(πθ) 能为低概率 token 保留非零梯度,防止模型在优化过程中忽略概率低但可能正确的 token。
此外,LUFFY 在 off-policy 分支(SFT)中省略了 CLIP 操作。通过该目标函数设计,LUFFY 将 SFT 从“死记硬背”答案转变为具备引导性与探索性的 RL 过程,从而提升模型的泛化能力。
3 UFT
监督微调SFT->强化微调RFT->动态微调DFT->统一微调UFT
UFT 从“信息引导”的视角提出了一种更为优雅的融合范式。
其核心思想在于:在训练初期提供完整的答案作为暗示(hint),并通过逐步缩短该暗示的长度,在统一的优化框架下实现从 SFT 到 RL 的平滑过渡,最终达到无需任何暗示的自主推理。
从”提供完整答案“逐步过渡到“无提示自主推理”。
具体而言,UFT 利用人类标注的完整答案,将其开头部分作为暗示(hint),拼接到问题后面一起输入模型。模型从这个暗示出发,继续生成后续的答案,并根据最终答案是否正确获得奖励。
这种方式自然地结合了两种学习模式:
- 当暗示长度为完整解答时,模型被引导复现专家行为,此时为标准的SFT;
- 当暗示长度为零时,模型完全自主生成推理路径,此时为标准的 RL。
UFT 的优化目标可抽象为 RL 与 SFT 的结合:
其中, Lsft 和 Lrl 基于暗示构造:输入为“问题 + 暗示”,模型从暗示末尾开始续写,对暗示部分施加监督信号(类 SFT 行为),对续写部分使用奖励优化(类 RL 行为)。暗示长度随训练进程逐步衰减(余弦退火算法),实现从SFT “模仿”到 RL “自主推理”的平滑过渡。
超参数 β 可手动设置,用于平衡 SFT与 RL。