【工程开发】GLM-4.1V调试
GLM模型
https://github.com/zai-org/GLM-4.1V-Thinking/blob/main/README_zh.md![]() https://github.com/zai-org/GLM-4.1V-Thinking/blob/main/README_zh.md
https://github.com/zai-org/GLM-4.1V-Thinking/blob/main/README_zh.md
中文readme
问题1:是否支持多模态?
项目更新
-
🔥 News:
2025/07/16: 我们已经开源了训练 GLM-4.1V-Thinking 时使用的 VLM 奖励系统!查看代码仓库并在本地运行:python examples/reward_system_demo.py -
News:
2025/07/02: GLM-4.1V-9B-Thinking 系列现已开源!支持增强的视觉推理和智能体交互。 -
News:
2025/07/01: 我们发布了 GLM-4.1V-Thinking 的技术报告。
模型介绍
视觉语言大模型(VLM)已经成为智能系统的关键基石。随着真实世界的智能任务越来越复杂,VLM模型也亟需在基本的多模态感知之外, 逐渐增强复杂任务中的推理能力,提升自身的准确性、全面性和智能化程度,使得复杂问题解决、长上下文理解、多模态智能体等智能任务成为可能。
基于 GLM-4-9B-0414 基座模型,我们推出新版VLM开源模型 GLM-4.1V-9B-Thinking ,引入思考范式,通过课程采样强化学习 RLCS(Reinforcement Learning with Curriculum Sampling)全面提升模型能力, 达到 10B 参数级别的视觉语言模型的最强性能,在18个榜单任务中持平甚至超过8倍参数量的 Qwen-2.5-VL-72B。 我们同步开源基座模型 GLM-4.1V-9B-Base,希望能够帮助更多研究者探索视觉语言模型的能力边界。
回答1:从这里的内容来看是支持的多模态的
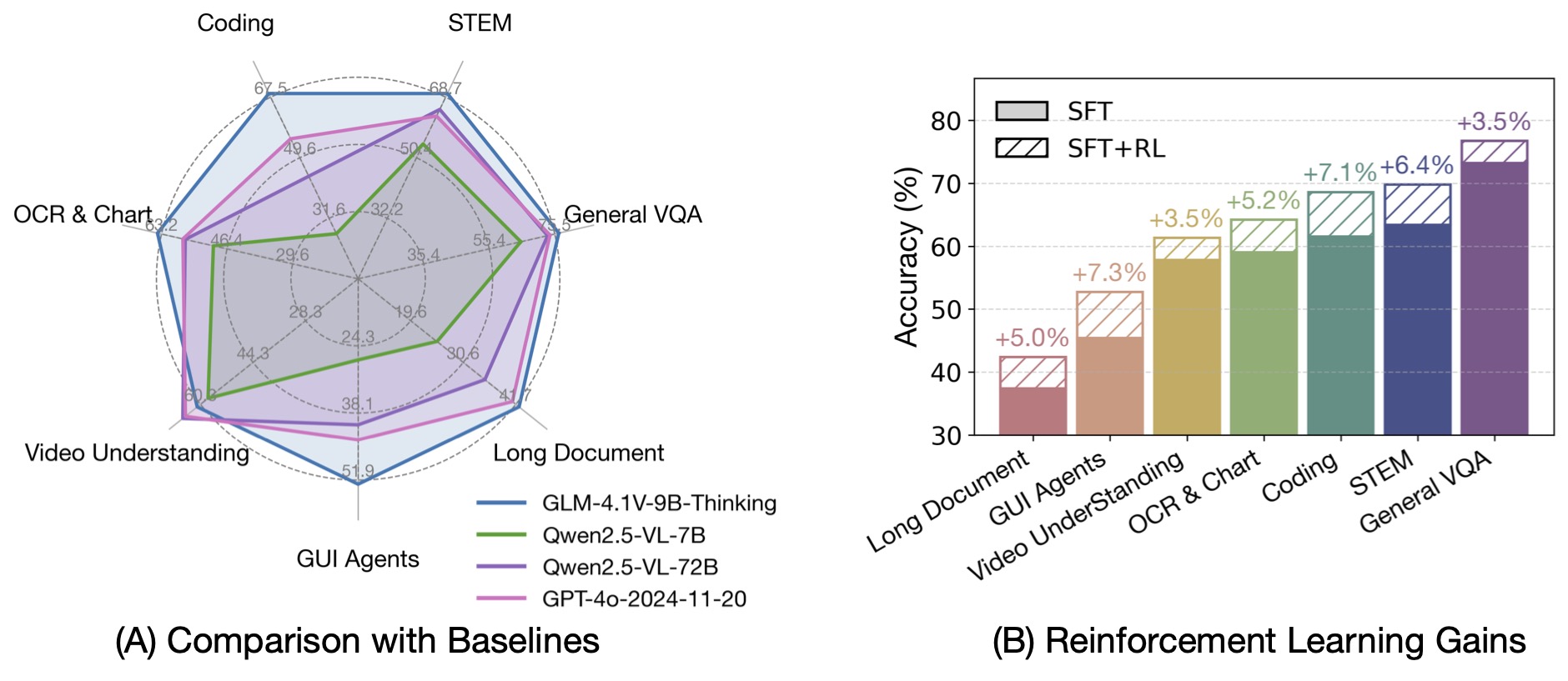
与上一代的 CogVLM2 及 GLM-4V 系列模型相比,GLM-4.1V-Thinking 有如下改进:
- 系列中首个推理模型,不仅仅停留在数学领域,在多个子领域均达到世界前列的水平。
- 支持 64k 上下长度。
- 支持任意长宽比和高达 4k 的图像分辨率。
- 提供支持中英文双语的开源模型版本。
模型信息
模型下载地址
| 模型 | 下载地址 | 模型类型 |
|---|---|---|
| GLM-4.1V-9B-Thinking | 🤗Hugging Face 🤖 ModelScope | 推理模型 |
| GLM-4.1V-9B-Base | 🤗Hugging Face 🤖 ModelScope | 基座模型 |
模型算法代码可以查看 transformers 的完整实现。
运行要求
推理
| 设备(单卡) | 框架 | 最低显存占用 | 速度 | 精度 |
|---|---|---|---|---|
| NVIDIA A100 | transformers | 22GB | 14 - 22 Tokens / s | BF16 |
| NVIDIA A100 | vLLM | 22GB | 60 - 70 Tokens / s | BF16 |
问题2:两种架构区别?
回答2:两种推理框架,它们的核心区别主要体现在运行效率和适用场景上,
-
transformers
支持完整的模型训练、微调、推理流程,提供丰富的 API 供开发者修改模型结构(如添加新的注意力变体、修改激活函数等),适合研究场景和小规模应用验证。 -
vLLM
专注于推理阶段,不支持训练 / 微调,但其提供的 OpenAI 兼容 API(如/completions、/chat/completions)可无缝对接现有基于 OpenAI SDK 的应用,适合快速部署高并发的生产级服务。
| 对比维度 | transformers | vLLM |
|---|---|---|
| 速度 | 较慢(14-22 Tokens/s) | 更快(60-70 Tokens/s) |
| 显存占用 | 最低 22GB(单卡 NVIDIA A100) | 最低 22GB(单卡 NVIDIA A100) |
| 精度 | 支持 BF16 | 支持 BF16 |
| 功能特性 | 提供命令行交互(trans_infer_cli.py)和 Web 界面(trans_infer_gradio.py),支持多模态输入(图片、视频、PDF 等) | 可直接拉起 OpenAI 格式的 API 服务,适合构建高效的后端服务,支持最多 32 张图片或 1 个视频输入 |
| 适用场景 | 适合快速演示、交互测试或需要灵活定制前端界面的场景 | 适合高并发、低延迟的生产环境,需要高效 API 服务的场景 |
| 维度 | transformers | vLLM |
|---|---|---|
| 核心目标 | 灵活性与兼容性 | 推理效率与高并发支持 |
| 注意力机制 | 标准实现,连续 KV Cache | PagedAttention,分页式 KV Cache |
| 批处理方式 | 静态批处理(固定批次 + 填充) | 连续批处理(动态插入新请求) |
| 内存利用率 | 较低(易碎片化) | 较高(分页管理 + 动态释放) |
| 硬件优化 | 依赖框架默认算子 | 自定义 CUDA 核 + 预取机制 |
| 适用场景 | 研究、原型开发、小规模推理 | 生产环境、高并发 API 服务、大规模部署 |
简单来说,transformers是 “通用工具包”,适合灵活调试和修改;vLLM是 “推理加速器”,通过算法创新和硬件级优化实现高效部署。transformers 框架更侧重灵活性和多模态交互的便捷性,而 vLLM 框架则专注于提升推理速度,更适合对性能要求较高的场景。
微调
该部分数据使用 LLaMA-Factory 提供的图片微调方案进行测试。
| 设备(集群) | 策略 | 最低显存占用 / 需要卡数 | 批大小 (per GPUs) | 冻结情况 |
|---|---|---|---|---|
| NVIDIA A100 | LORA | 21GB / 1卡 | 1 | 冻结 VIT |
| NVIDIA A100 | FULL ZERO2 | 280GB / 4卡 | 1 | 冻结 VIT |
| NVIDIA A100 | FULL ZERO3 | 192GB / 4卡 | 1 | 冻结 VIT |
| NVIDIA A100 | FULL ZERO2 | 304GB / 4卡 | 1 | 不冻结 |
| NVIDIA A100 | FULL ZERO3 | 210GB / 4卡 | 1 | 不冻结 |
使用 Zero2 微调可能出现 Loss 为 0 的情况,建议使用 Zero3 进行微调。
问题3:Zero2 微调和Zero3 区别?
回答3:ZeRO(Zero Redundancy Optimizer)Zero2 和 Zero3 是 DeepSpeed 框架中两种主流的分布式优化策略(属于 ZeRO 优化器系列),主要用于解决决大模型训练时的内存瓶颈问题,通过精细化的内存分片和优化策略提升训练效率。结合你提供的 GLM-4.1V-Thinking 微调信息,两者的核心区别如下:
1. 核心原理与内存优化粒度
-
Zero2(ZeRO-2)
对模型的优化器状态(Optimizer States) 和梯度(Gradients) 进行分片存储,而模型参数(Parameters)由所有进程共同保存。- 优化器状态(如动量、二阶矩)和梯度会被平均分配到不同 GPU 上,每个 GPU 仅存储部分数据,减少单卡内存占用。
- 但模型参数仍在各卡保留完整副本,因此内存节省幅度有限。
-
Zero3(ZeRO-3)
在 Zero2 的基础上进一步对模型参数(Parameters) 进行分片,实现 “优化器状态、梯度、参数” 三者的全部分片。- 每个 GPU 仅存储模型参数的一部分(而非完整副本),训练时通过通信按需获取所需参数,大幅降低单卡内存压力。
- 内存节省效果比 Zero2 更显著,尤其适合超大规模模型(如数十亿参数)的训练。
2. 显存占用与硬件需求
从 GLM-4.1V-Thinking 的微调数据来看(基于 NVIDIA A100 显卡):
-
Zero2:
- 冻结 VIT 时,4 卡总显存需求为 280GB;不冻结时需 304GB。
- 由于参数未分片,对单卡显存压力较大,适合中等规模模型或卡数较少的场景。
-
Zero3:
- 冻结 VIT 时,4 卡总显存需求为 192GB;不冻结时需 210GB。
- 显存需求明显低于 Zero2(节省约 30%),更适合大模型全参数微调或显存资源有限的情况。
3. 通信开销与训练稳定性
-
Zero2:
- 通信量较小(仅需同步梯度和优化器状态),训练速度较快,但可能因参数未分片导致内存分配不均,容易出现 loss 异常(如文档中提到的 “Loss 为 0” 问题)。
-
Zero3:
- 由于参数分片,训练过程中需要更多跨卡通信来交换参数片段,可能略微降低训练速度,但内存分配更均衡,训练稳定性更高(文档推荐优先使用 Zero3 避免 loss 异常)。
4. 适用场景
- Zero2:适合中小规模模型微调、对训练速度要求较高,或硬件资源(如 GPU 数量)有限的场景。
- Zero3:适合超大规模模型(如 GLM-4.1V 这类 9B 参数模型)的全参数微调,或显存紧张、追求稳定性的场景(如文档中明确建议用 Zero3 替代 Zero2 避免训练问题)。
总结:核心差异对照表
| 维度 | Zero2(ZeRO-2) | Zero3(ZeRO-3) |
|---|---|---|
| 分片对象 | 优化器状态、梯度 | 优化器状态、梯度、模型参数 |
| 显存占用 | 较高 | 较低(节省 30% 左右) |
| 通信开销 | 较小 | 较大 |
| 训练稳定性 | 较低(可能出现 loss 异常) | 较高(推荐用于稳定训练) |
| 适用场景 | 中小模型、对速度敏感 | 大模型全量微调、显存有限场景 |
在 GLM-4.1V-Thinking 微调中,Zero3 是更优选择,既能减少显存压力,又能避免 Zero2 可能出现的训练异常问题。
榜单信息
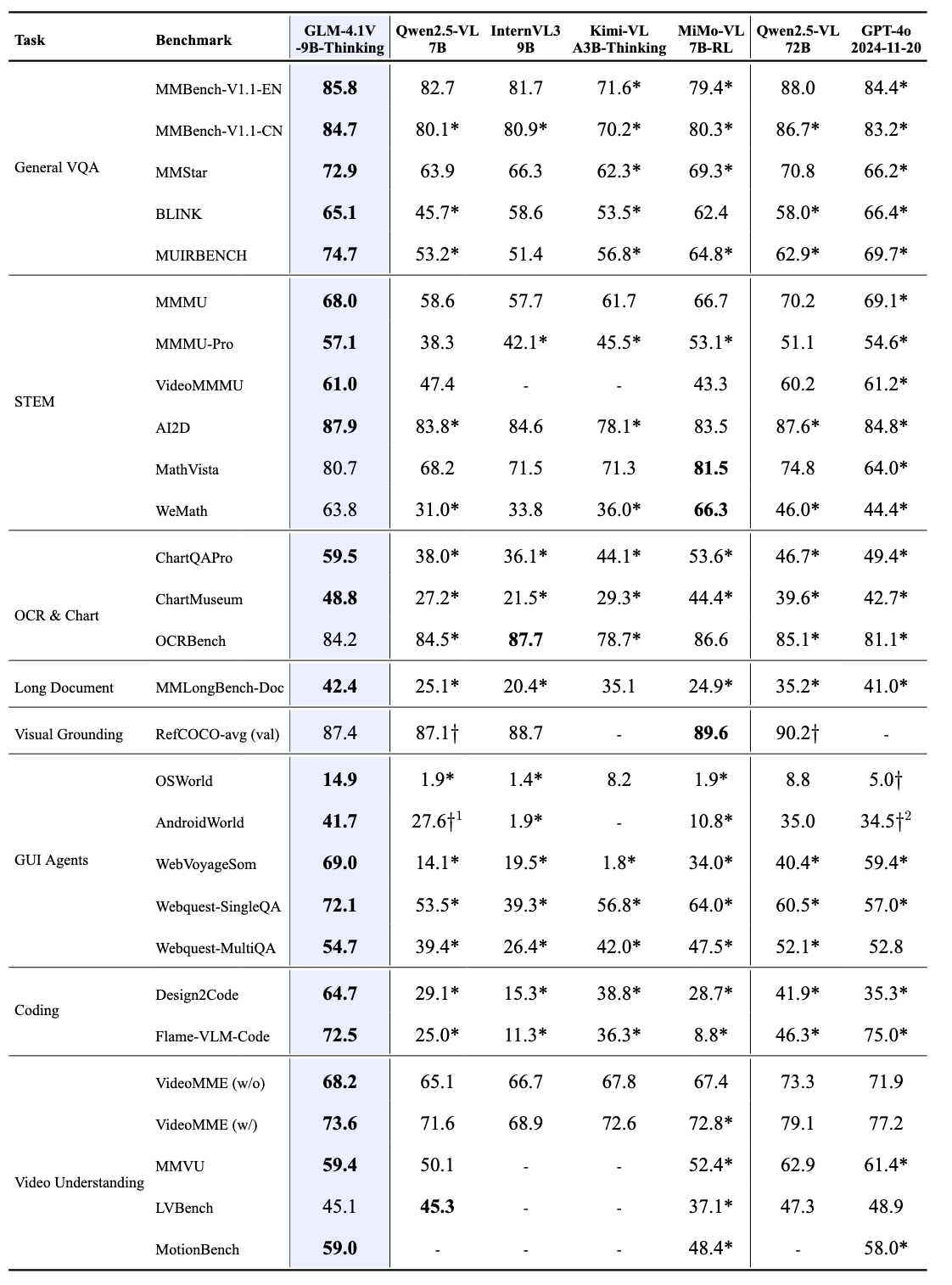
GLM-4.1V-9B-Thinking 通过引入「思维链」(Chain-of-Thought)推理机制,在回答准确性、内容丰富度与可解释性方面, 全面超越传统的非推理式视觉模型。在28项评测任务中有23项达到10B级别模型最佳,甚至有18项任务超过8倍参数量的Qwen-2.5-VL-72B。
 模型推理
模型推理
模型推理代码均在 inference 文件夹中,包含了:
-
trans_infer_cli.py: 使用transformers库作为推理后端的命令行交互脚本。你可以使用它进行连续对话。 -
trans_infer_gradio.py: 使用transformers库作为推理后段的 Gradio 界面脚本,搭建一个可以直接使用的 Web 界面,支持图片,视频,PDF,PPT等多模态输入。 -
使用
vllm直接拉起OpenAI格式的API服务。并在vllm_api_request.py中提供了一个简单的请求示例。vllm serve THUDM/GLM-4.1V-9B-Thinking --limit-mm-per-prompt '{"image":32}' --allowed-local-media-path /
-
limit-mm-per-prompt若不指定,只支持1张图片。模型支持最多1个视频或300张图片输入,不支持图片和视频同时输入。allowed-local-media-path需要指定允许访问多模态图片的路径。
-
trans_infer_bench:用于学术复现的推理脚本,支持GLM-4.1V-9B-Thinking模型。其核心在于- 指定了中断思考的长度,当思考长度超过
8192时,强制中断思考并补上</think><answer>再次发起请求,让模型直接输出答案。该例子中使用的一个视频作为输入的测试的例子。其他情况需自行修改。 - 该方案仅提供
transformers版本,vLLM版本需要自行根据该逻辑修改方案。
- 指定了中断思考的长度,当思考长度超过
-
vllm_request_gui_agent.py: 该脚本展现了用于 GUI Agent时对于模型返回的处理和构建提示词方案, 包含手机,电脑和网页端的策略,可集成到您的应用框架。GUI Agent详细文档请查看这里 -
使用 Ascend NPU 设备推理,可查看 这里
模型微调
LLaMA-Factory 已经支持本模型的微调。以下是构建数据集的说明,这是一个使用了两张图片的数据集。你需要将数据集整理为 finetune.json
[{"messages": [{"content": "<image>Who are they?","role": "user"},{"content": "<think>\nUser ask me to observe the image and get the answer. I Know they are Kane and Gretzka from Bayern Munich.</think>\n<answer>They're Kane and Gretzka from Bayern Munich.</answer>","role": "assistant"},{"content": "<image>What are they doing?","role": "user"},{"content": "<think>\nI need to observe what this people are doing. Oh, They are celebrating on the soccer field.</think>\n<answer>They are celebrating on the soccer field.</answer>","role": "assistant"}],"images": ["mllm_demo_data/1.jpg","mllm_demo_data/2.jpg"]}
]
<think> XXX </think>中的部分不会被存放为历史记录和微调。<image>标签会被替换成图片信息。
接着,即可按照 LLaMA-Factory 的微调方式进行微调。