对话智源研究院:多模态世界模型如何实现“大一统”?

文|魏琳华
编|王一粟
从去年10月发布全球首个原生多模态世界模型悟界·Emu3,到如今推出全面升级的悟界·Emu3.5,智源研究院用一年时间,找到了更多具备开创性的新解法。
10月30日,在悟界·Emu系列技术交流会上,智源发布Emu3.5被定义为“多模态世界模型”,与专注于内容(如视频)“生成”的模型不同,其核心在于“理解、预测与规划”,它不仅能生成对未来的预测,更致力于构建一个关于世界如何运作的内在模型。
Emu3.5的架构设计证明了一条更简洁、更具扩展性的技术路径是可行的。
此前,和路径相对确定的大语言模型相比,围绕多模态大模型领域还存在种种问题。比如采用自回归架构还是基于扩散模型的架构,业内仍然没有给出一个确切的答案。
虽然自回归架构虽然在统一性上有优势,但在生成效率上常受逐步解码限制;相比之下,扩散模型目前应用范围广,但受限于推理步数与长时一致性,随着模型规模提升,在推理成本与时长可扩展性上会遇到瓶颈。
智源发布的Emu3.5模型采用了单一的自回归Transformer架构。为了解决生成效率的问题,Emu3.5通过创新的”离散扩散自适应”(DiDA)技术,将自回归模型的生成效率提升近20倍,使其在速度上能够媲美顶尖的扩散模型。
“通过Emu3,我们验证了自回归架构实现多模态理解与生成大一统的可行性,Emu3.5则开启了多模态Scaling的新时代。”智源研究院院长王仲远说。
相比Emu3,Emu3.5的训练规模有了质的飞跃:模型参数从80亿扩展到340亿,累计视频训练时长从15年增加到790年。更重要的是,Emu3.5首次实现了多模态领域的大规模强化学习,这为多模态模型的Scalingup指明了方向。

实际测试中,Emu3.5的表现超越了众多知名闭源模型,达到SOTA效果。官方表示,Emu3.5在图像生成和编辑任务上取得了与Gemini 2.5 Flash Image(Nano Banana)相媲美的性能,并在系列图文交错生成任务中展现出更优异的结果。
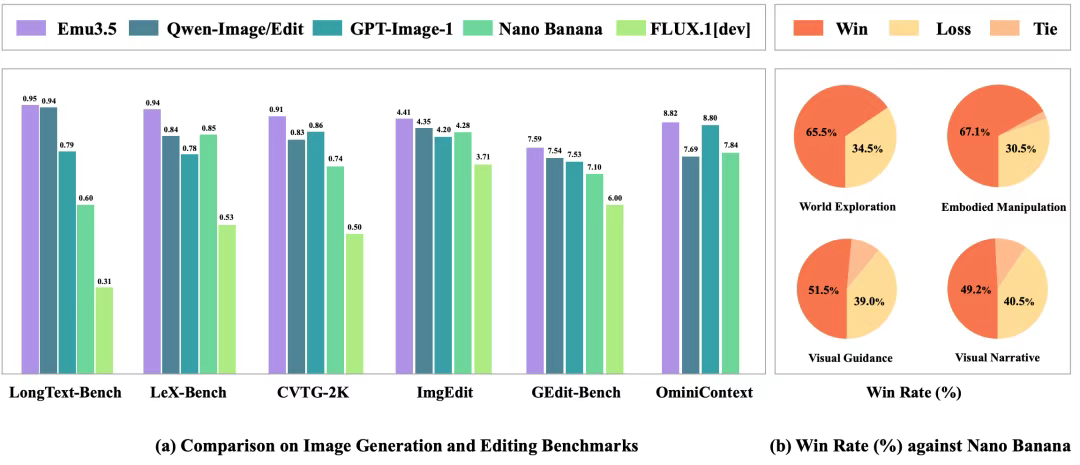
在交流会现场,研究团队展示了Emu3.5在具身操作、世界探索、视觉指导等多个场景的应用能力。从众多测试结果来看,它能够做到类似Genie 3的场景交互、支持图片编辑修改等操作。

Emu3.5的意义不仅在于技术突破,更在于为具身智能的发展提供了全新的可能性。
交流会上,智源研究院表示,Emu3.5为具身智能提供了坚实的世界模型支撑,推动具身智能从数据稀缺和规划瓶颈向更可靠、泛化的方向演进。传统机器人往往局限于预设指令或特定场景数据,Emu3.5的价值在于数据生成、高级任务规划和泛化推理能力,推动具身智能向更“智能”的方向发展。
长坡厚雪,智源研究院在原生多模态领域迈出了重要的一步,但如何解决模型遗忘等等问题,还需要更多探索。
谈及发展的下一步,王仲远和模型团队负责人王鑫龙回应光锥智能,希望接下来进一步扩大模型参数。
“当前Emu3.5的参数是34B,语言模型现在都已经到万亿级别。”王仲远说,“如果有更大的参数,投入更多的算力,我们相信基于Emu3.5架构的这样一个多模态世界模型能力还会有跃升。”
以下为沟通会问答环节实录(经光锥智能编辑整理)。
受访者嘉宾为:
智源研究院院长王仲远
智源研究院多模态大模型团队技术负责人王鑫龙
Q: 刚才我们提到了Emu3.5可以应用在具身智能领域,请问我们的模型有没有已经和机器人领域的一些机构或企业有过合作?
A:智源研究院自己就在研发RoboBrain系列的具身大模型,这些模型已经在跟国内非常广泛的具身机器人公司合作,包括不限于星海图、星动际元、乐聚、宇树科技等。
Emu3.5具备进一步提升具身智能基座模型的能力,包括探索新的具身智能技术路线的可能性。我们已经开始做了一些初步尝试,例如刚才展示的,能够预测机械臂操作所需的数据,这些数据原来可能需要真机采集,现在我们可以非常精准地生成大量数据。
过往真机采集数据可能在固定场景,但现在通过世界模型能力,它能够泛化到没见过的场景。在没见过场景下,别的模型可能是0,但用上Emu3.5它可以直接达到70%。这是我们的一个方向,现在也在进一步扩大规模,把真机各种场景都去尝试一下。
Q: 关于模型效率的问题,前段时间李飞飞的项目说一块GPU可以搞定推理,想问问我们效率怎么样?
A:首先,行业内各种模型都在进行推理优化,随着模型的发展,甚至会出现推理效率的“新摩尔定律”,即成本不断降低,性能无损。这是各家厂商和科研机构都在努力的方向。
对于Emu3.5,我们最大的贡献是在自回归架构上实现了近乎并行的多Token生成,且实现性能无损。由此,我们首次用包含离散Token的自回归架构,在图像生成上与主流扩散式方法相媲美,我们的开源模型比肩闭源的图像生成能力。
对于效率方面,我们还是比较有信心。原来原生多模态的成本极高,我们现在的这套技术一次20倍的加速,可以说是把原生多模态的成本砍下来了。
Q: 对于世界模型和机器人的商业化路径,目前咱们探索出哪些可行的方向?比如说Emu3.5与药房机器人的结合,这些案例能否复制到更多行业?
A:未来这些都是可以的。我们的悟界EMU系列(多模态世界大模型)和悟界RoboBrain系列(具身大小脑模型),都会快速推动具身智能向更多的场景,实现能力上的泛化。
就像刚才所介绍的,现在做具身智能,很多时候真机只能采集到具体场景有限的数据。通过Emu3.5,它可以产生泛化的数据,这能够极大地提高具身模型,包括具身机器人、机械臂在实际场景中处理泛化性的能力,自然而然就会推动整个具身更快进入一些真实的场景中。
Q: 数据采集和数据缺失是一个痛点,另外一个痛点在没见过场景执行的准度和任务度,我们整个模型在数据的执行精度和任务度上能完成什么样复杂的动作呢?
A:Emu3.5具备在具身智能上做Next-State Prediction(下一个状态预测)的能力,在时序推理与行动预测上更接近人类大脑的处理方式。
我们认知到其实整个具身智能行业现在面临着非常多的挑战,包括:硬件本体不成熟、数据缺乏、模型能力不强、应用场景比较弱。因此,尽管具身智能有多种范式,在实际发展中仍会遇到大量问题。Emu3.5有望成为具身智能的基座模型,但这中间还有大量的工作需要去做。
具身智能更大的关键不在“具身”,而在“智能”。 智能并不会因仅有硬件而自然产生,我们希望第一步先把智能基础打牢,让模型能够泛化到未见过的场景,现在已经有一些喜人的进展。比如在一些想象的场景中,“把火星上的宇航员救起来”,或者生成“叠衣服”这类可能包含数十步的复杂操作,且是在任意场景中完成——这些数据往往难以真实采集(实验场景中大部分叠衣服都在干净的台面上完成)。但是现在有了基础模型能力之后,可以支持各种场景、各种任务,显著释放智能的想象空间与可用性。
Q:咱们说预训练模型的时候,采用大规模长视频数据, 这个数据做了什么特别的处理吗?直觉来讲大家可能会想到长视频的数据,为什么当时大家没有这么做?现在你们做具备了什么样的条件?
A:用长视频数据来学习,一直都是多模态大模型,尤其是原生多模态大模型努力的一个方向。全球范围内确实有一些科研团队,包括一些企业机构在尝试做这件事情,但是它的挑战非常大。
刚刚王鑫龙在展示我们Loss曲线的时候强调“Loss下降非常稳定”,要实现这一点,背后涉及一系列挑战,包括数据应该怎么设计,初期数据的配比,包括到底选用什么样的视频等等,这些都是过去几年时间我们集中攻关的。
Emu3.5是去年3月份正式立项,整个科研团队在反复试错中持续突破,遇到了一个又一个新的挑战,攻克了一个又一个难关。到今天我们能够非常自豪地说:在自回归这条路线上,我们生成的效果和速度可以媲美Diffusion方法,并且有更好的上限空间。智源研究院真的走出了一条新的大模型的路。我们也期待这条路后续成为主流的路。
登珠穆朗玛峰,南坡和北坡也许都可以登峰,我们希望我们走的是大家认可的一条路,我们也会把我们的基座模型开源,期待生态共同拓展。
关于长视频,我们一直在推进。核心的问题在于:到底用什么架构才能够支撑有效的Scaling up。受益于此前EMU系列的一些研究,现在在我们的自回归架构下可以非常方便地把长视频学进去,能实现大规模的预训练和大规模的多模态RL。从训练视角看,判断一个架构是否可扩展,关键在于能否同时满足“可进行大规模预训练”和“可进行大规模RL”,现在很多架构要么只能满足一个,要么两个都不满足,现在Emu3.5现在两者均已打通,这是训练的角度。从推理的角度,长视频推理需要有更高效的加速方案,只有技术创新到位,才能把数据真正“学进去”,把能力体现出来。
Q:前不久我们跟大模型研发人士交流,讨论到最近几个月模型差距在拉大,您怎么看?从您研发的世界模型视角,咱们智源处于什么情况?
A:谨代表个人观点。我们要正视国内大模型和全世界最先进的大模型,一直都处在你追我赶的阶段。比如说今年年初DeepSeek的发布,让我们能够至少在语言模型上,开始有了一个追赶甚至接近的情况。
关于“差距拉大”的讨论,一方面从已公开的模型与开源结果对比来看,当前阶段确有差距有拉大的现象。在9月底的时候,我们公布了一个对60多款推理大模型的评测报告,结果显示国际最先进的模型较目前多数国产的模型仍保持明显的领先。另一方面,我相信国内各家科研机构和公司,也一定会在包括像语言模型,后训练及推理模型上有很多新的模型还在训练当中,后续进展值得期待。
就智源自身而言,我们悟界·Emu3.5开启了多模态世界大模型的新时代,某种程度上可以证明中国科研机构,在坚持默默无闻地做一些原始的科研创新。在当前阶段,EMU系列在其所定位的方向与能力上已取得具有国际竞争力的进展,并在若干维度达到国际领先水平。
Q: 现在文字类和视频类的模型发展速度很快,多模态其实比较慢,您感觉在技术侧,包括各个方面它限制性的因素还有哪一些?
A:因为技术路线没有收敛,与我们对于整个行业技术路线的判断一致,市面上很多方案仍是将多模态理解和多模态生成割裂开来,采用组合式管线处理。比如以大语言模型为核心学语言,再以DiT等模块处理多模态。这样会带来一系列问题,包括跨模块协同成本、端到端优化困难,以及“遗忘/记忆”的问题长期未被很好地解决,上述因素共同限制了多模态系统的效率与可扩展性。
我们认为悟界·Emu3.5代表了一条可扩展的多模态智能路径。我们有理由相信,通过这项探索,我们正在逐步厘清通向真正意义上通用智能的技术路线。
Q:在大规模预训练的时候, 我们在训练模型的什么能力?我们建立了怎样的奖励机制?或者说怎么样进阶它的下一个能力?
A:我之前举过一个例子,今年春节期间,我观察到一个两岁的小女孩学会串糖葫芦,没有大人教她,她是怎么学会的呢?她刷短视频,特别喜欢看一位吃糖果的小姐姐,每天反复看,她从视频中学习,视频里面涵盖了大量的真实世界物理动态信息,包括各种声音、语言、图像等,视频是目前最容易获取、可用来做“世界模型”预训练的关键数据。
这个小女孩在现实世界中尝试:她自己撕糖果纸,第一次失败了,但她没放弃,又从不同的角度去尝试,最终她吃到了糖果,得到了奖励,类似强化学习过程。人类也是在大量的感知,比如通过视频,通过真实世界交互在不断地学习。学习的过程中又通过交互,通过强化学习反馈习得到了能力。对于小女孩来讲她吃到了糖果,对于足球运动员来讲是这样射门更容易成功,这就是学习。
对应到模型,第一性原理同样是在真实世界数据上做大规模的Pretrain,以及在具体任务重通过强化学习优化策略,将其内化为自己的能力。这也是我们将Emu3.5的路线称为“第一性原理”的原因之一:在多模态世界模型上,以“大规模预训练+大规模多模态强化学习”为核心的技术范式与路线。
从学习阶段来说,预训练主要在学世界知识与泛化能力,我觉得泛化性也是评价智能的一个重要标准,不泛化就谈不上智能。当前主流的人机交互方式是Chat,但是Chat并不是原生多模态的,多模态原生到底应该用什么样的交互形式,过去并不清晰。假如说以后有了智能眼镜,做菜的时候你不会跟它聊天,而是边做边得到下一步指导(下一步应该拿土豆,应该怎么切),这更多是一种指导式交互。这类原生多模态交互与大规模世界知识的泛化能力相结合,构成了我们追求的目标:既具备广泛的世界知识与泛化性,又具备高效、自然的多模态协同与交互。
Q:我们选择了统一的自回归架构,但在多模态世界中,仍有很多问题需要处理。在您看来,接下来最重要、最需要解决的方向是什么?
A:扩大规模,我们现在没有足够的资源。扩大规模可能是最明显的一条路。我们已将范式指明,后续提升关键在两方面:数据、Infra。之前范式是不确定的,大家不知道往哪个方向去做。我们现在有了一个明确的Scaling方向,接下来是如何把数据,比如把所有的视频数据全部用起来,二是Infra,支持更大规模的预训练与强化学习,需要更高效的训练系统与推理加速,且在多模态上算力需求更高,还有存储。这些都需要去提升。
我们认为Emu3.5一个很重要的贡献是提出并验证了多模态Scaling的可行范式,它是第三种Scaling up的方式。在语言模型上现在确实遇到了各种各样发展的瓶颈。我们很幸运在多模态上找到了有可能Scaling的方式。。大量长短视频平台与网站拥有的私有视频数据,若在合规前提下用于训练,有望进一步提升模型能力。
另外一块是参数和算力。如果把模型规模拓展到比如说70B,300B,乃至于语言模型的万亿规模,在既有范式有效的前提下,参数与算力的提升有望带来能力跃升。我们希望,也呼吁行业里拥有大规模算力的企业机构,能够跟智源合作,我们一起尝试探索更大规模的多模态世界模型,也欢迎投资方在合规与可持续的框架下共同投入资源。谢谢!