RT-DETR解码模块(Decoder)
RT-DETR上篇可以参考:RT-DETR网络结构(Encoder)-CSDN博客
前面也提到了RT-DETR由两部分构成,分别是Encoder和Decoder模块,经过这两个模块后直接输出结果,也就是没有所谓的NMS等后处理操作,下面主要来介绍一下Decoder模块,由于使用了denoising training的训练方法,训练阶段和推理阶段略有不同,但是都是差不多的,最后会有对比总结。
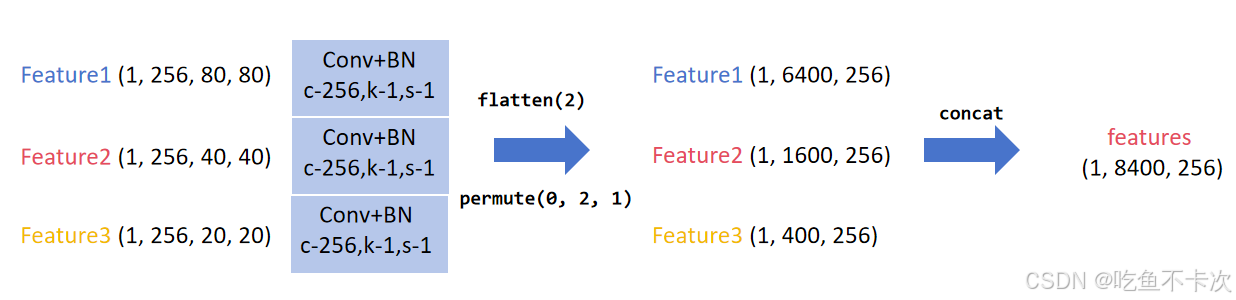
首先需要将Encoder中得到的三个尺度的特征图展开然后拼接成一个特征图,即将(B,256,80,80),(B,256,40,40)和(B,256,20,20)特征图最后两维展开后在拼接成shape为(B,256,8400)的特征图,将这个作为Docoder模块的输入,过程如下所示。
这一步是基础,后面会有很更多复杂的操作,将按照顺序介绍。
2.1对比去噪训练(Contrastive Denoising Training)
这种训练方法是在《DINO: DETR with Improved DeNoising Anchor Boxes for End-to-End Object Detection》这篇论文提出的,论文地址:https://arxiv.org/pdf/2203.03605
而对比去噪训练的核心内容都包含在这张图里。
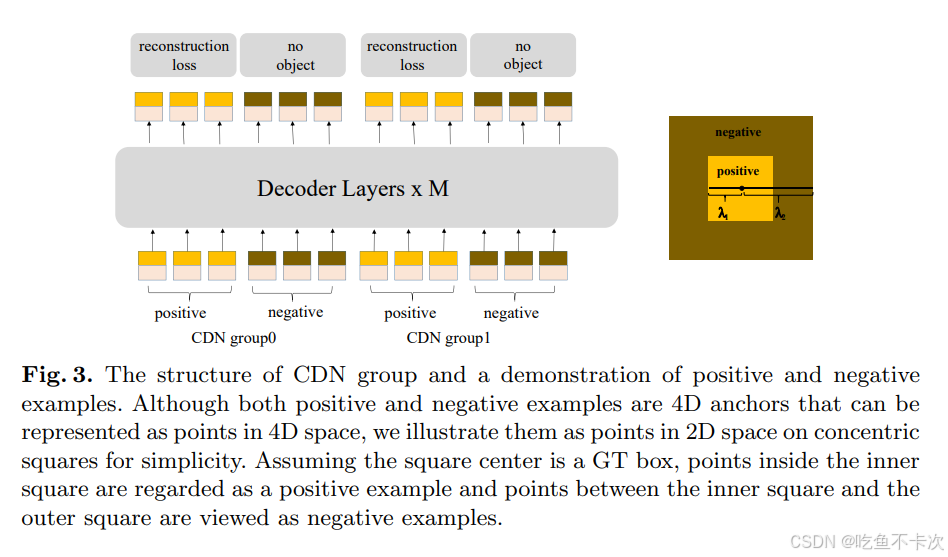
2.1.1标签框
首先来看一下轻微噪声和严重噪声,下图展示了标注框的真实标签,以及通过真实标签生成的轻微噪声和严重噪声,其中将轻微噪声称为positive,严重噪声称为negative,
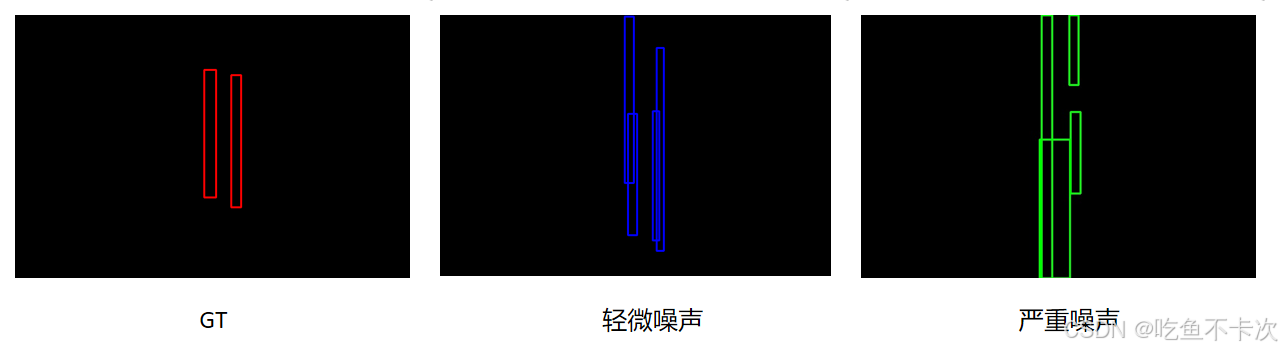
代码实现如下,感兴趣可以看看是怎么去生成轻微噪声和严重噪声的:
注意:这里会对生成的标签进行logit变换,torch.logit().
if box_noise_scale > 0:known_bbox = xywh2xyxy(dn_bbox)diff = (dn_bbox[..., 2:] * 0.5).repeat(1, 2) * box_noise_scale # 2*num_group*bs*num, 4 (w/2, h/2, w/2, h/2) rand_sign = torch.randint_like(dn_bbox, 0, 2) * 2.0 - 1.0 #范围是[-1,1] 让噪声有正负方向(向左/右、上/下随机偏移)rand_part = torch.rand_like(dn_bbox)#[0, 1)rand_part[neg_idx] += 1.0#偏移量 微弱噪声[0,1) 强噪声[1,2)rand_part *= rand_sign#方向 只有1和-1 known_bbox += rand_part * diff#基准量known_bbox.clip_(min=0.0, max=1.0)dn_bbox = xyxy2xywh(known_bbox)dn_bbox = torch.logit(dn_bbox, eps=1e-6) # inverse sigmoid
下面举一个batch size=2的例子,说明一下如何通过真实标签生成噪声标签框。
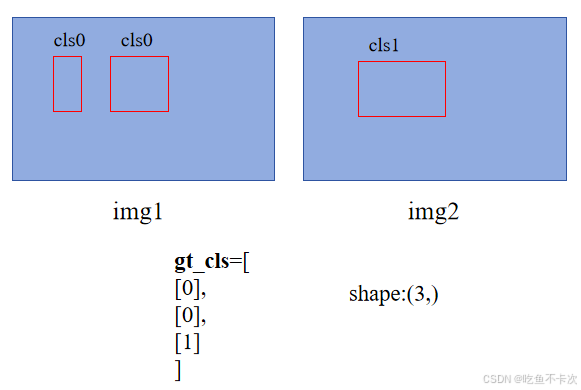
如下图所示,img1中有两个标签,分别为(x0,y0,w0,h0)和(x1,y1,w1,h1),img2有一个标签,为(x2,y2,w2,h2).

即img1和img2分别有[2,1]个标签,每张图片最多有max_nums=2个标签,则num_group = num_dn // max_nums=100/2=50,其中num_dn初始化值为100,这里的num_group =50是指positive标签有50组,同样的与此相对应negative标签也需要有50组,则一共包含有100组,并且每组里面有包含3个标签。
如下图所示,gt_bbox表示该batch下所有的标签,shape为(3,4);
dn_bbox为positive和negative的标签,我故意写成下面这种方式,即每组有3个标签,一共有100组,前50组是positive标签(即前150行),后50组(即后150行)是negative标签,即shape为(300,4).
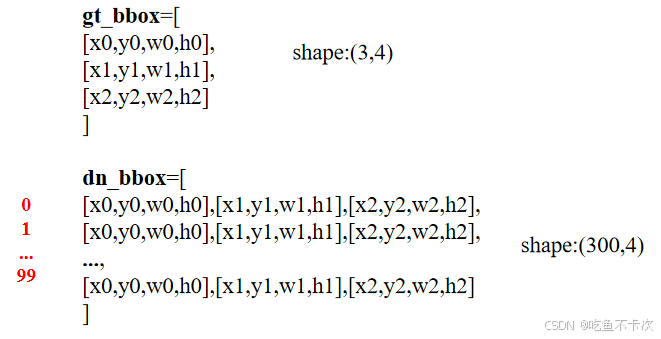
当然如果写成下面这种方式看起来就更明显了,前面只是为了理解num_group =50这个概念。

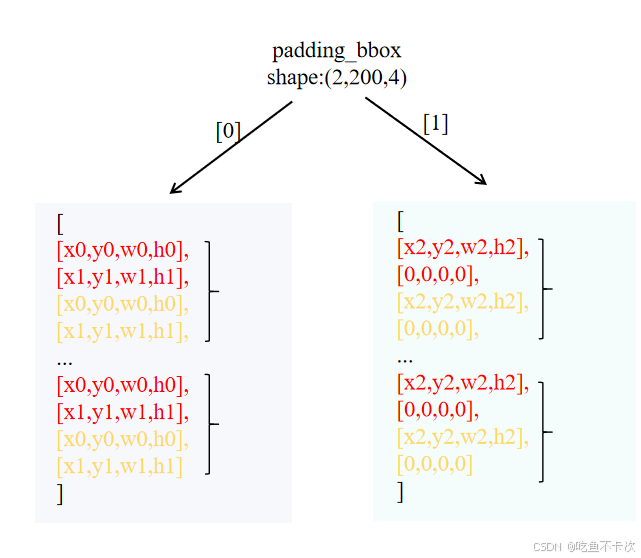
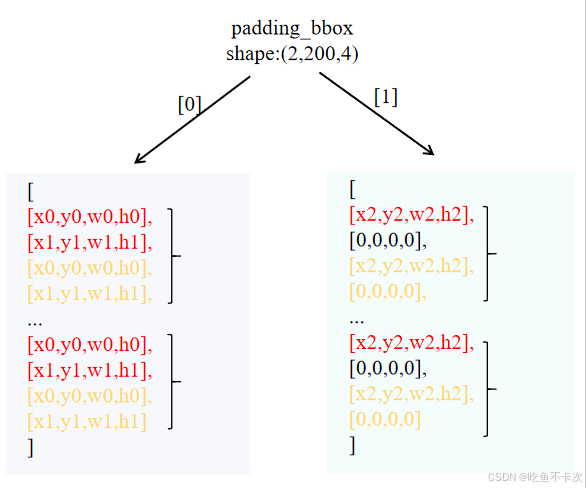
最后来划分[positive,negative]标签对,如下所示,左边表示img1的标签一共有200个标签,其中包含100个positive标签,100个negative标签,然后将其进行组合成[positive,negative]标签对,其中红色代表轻微噪声标签,黄色表示严重噪声标签。
在img1中可以观察到[positive,negative]标签对是由max_nums=2个positive标签和max_nums=2个negative标签组成的;在img2中因为只有一个真实标签,所以需要使用[0,0,0,0]来填充,如下图右所示。为什么要这样做呢?这是为了保证batch内的图片包含相同的结构,方便批次处理,这种方式也是很常见的。
padding_bbox即为对比去噪训练生成的噪声标签,每张图片都包含有200个这样的轻微、严重噪声标签。
还有一个比较重要的返回参数是dn_pos_idx,即positive的下标值,在本例中img0的值为[0,1,4,5,..196,197],img1的值为[0,4,8,12,...,196].
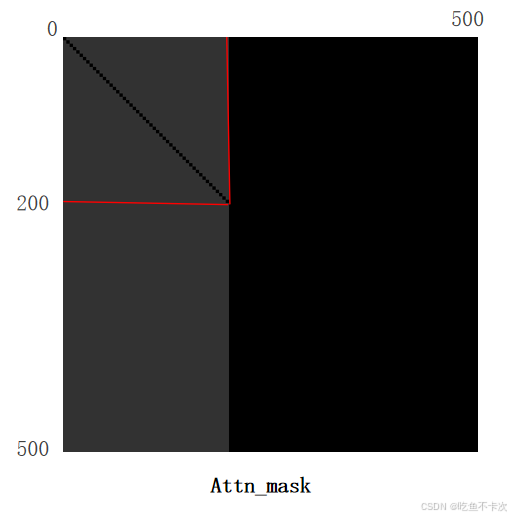
最后还会返回一个attan_mask,可视化出来如下所示:
(1)其中黑色区域是false, 表示允许注意力计算,灰色是true,表示屏蔽注意力计算。
(2)attan_mask的shape是(500,500),其中前200表示我们前面处理得到的噪声标签,后300表示模型预测出来的结果:
①后300行,前200列:推理时没有噪声分支,不能让模型预测的结果依赖于噪声标签;
②前200行,后300列:让烂初始化的噪声 快速抄到正确特征,可以加速收敛;
③后300行,后300列,标准 DETR 解码,负责最终检测输出;
④前200行,前200列中,只在同组中计算相似度权重,防止跨组信息泄露;
(3)这里补充一点就是,不管前面怎么计算,最后噪声组的标签个数都是接近200的,然后模型预测的结果是固定的300个标签。

2.1.2标签类别
还是同样的例子,如下所示,则gt_cls记为下面所示:
标注框的类别,就是随机进行替换的,这里就不区分轻微和严重了,代码如下:
if cls_noise_ratio > 0:#如果只有一个类别 没有类别的真实扰动# Half of bbox probmask = torch.rand(dn_cls.shape) < (cls_noise_ratio * 0.5)#小于0.25为trueidx = torch.nonzero(mask).squeeze(-1)#返回满足条件(mask=True)的索引 # Randomly put a new one herenew_label = torch.randint_like(idx, 0, num_classes, dtype=dn_cls.dtype, device=dn_cls.device)#53个dn_cls[idx] = new_label
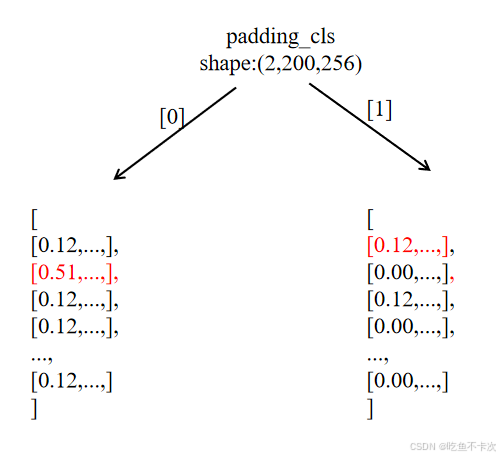
除此之外,还需要将类别通过dn_cls_embed = class_embed[dn_cls]映射到256维,如下所示:

最后按照噪声标签框划分的方式来划分类别噪声,对于img1只有一个类别,类别编码使用全0来填充,其实类别噪声这块没啥意义,主要是框的噪声,以及positive下标。
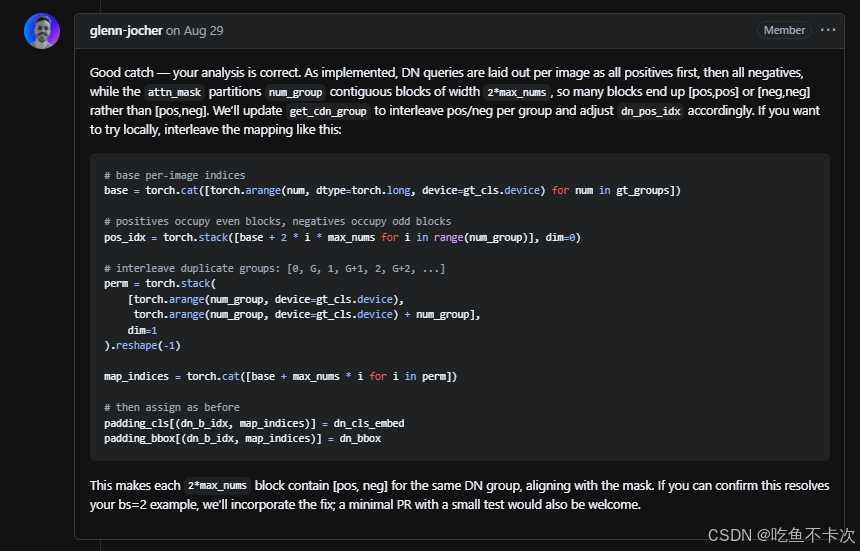
最后,关于对比去噪训练的核心函数get_cdn_group在ultralytics\models\utils\ops.py中,完整代码就不贴了,之前看这部分代码时候,因为代码生成的attn_mask总是和论文中所说的对应不上,emo了好久,然后向ultralytics作者提出了这个问题,最后根据他们的回复修改这部分代码就可以生成正确的attn_mask了,如下所示:
get_cdn_group · Issue #21767 · ultralytics/ultralytics
2.2Generate Anchors
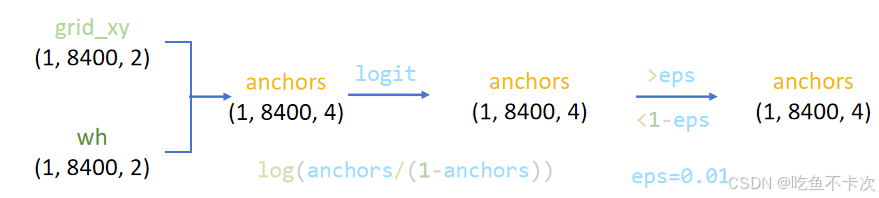
这一步是生成anchor box,如下图所示:(80,80)、(40,40)和(20,20)三种尺度都会生成在当前尺度下宽高为4的anchor box,映射到输入尺寸(640,640)就分别是32,64和128.
以(80,80)为例,将该特征图划分成80x80个网格,然后每个网格的中心就是Anchor box的中心点,然后每个Anchor box的宽高都为4,实际计算中需要将中心点的XY坐标和宽高都得归一化到[0,1]区间。
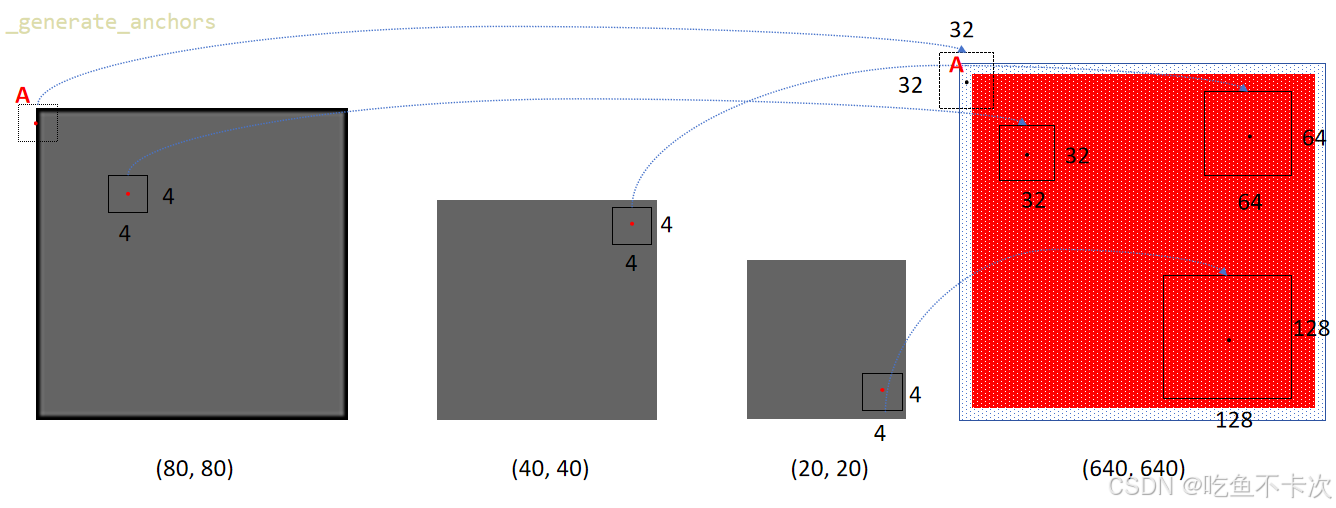
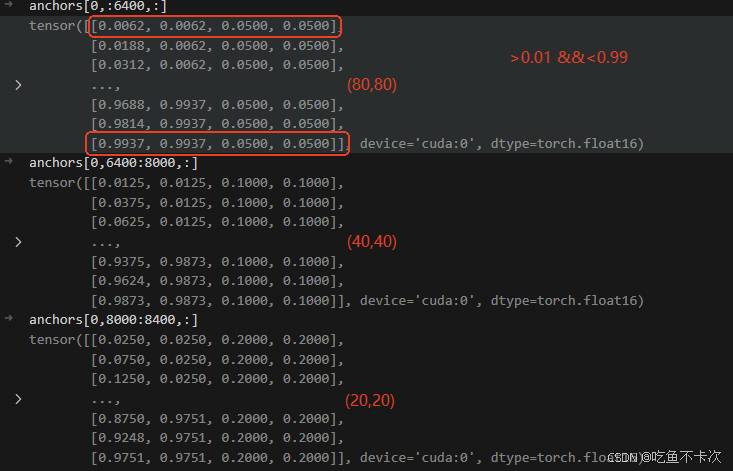
除此之外,需要对靠近边缘的anchor box中心点进行过滤,如上图中心点A所代表的Anchor box就会被过滤,通过观察可以发现被过滤的锚框都是(80,80)尺度下的,过滤的规则就是保留中心点在0.01-0.99范围内的锚框。
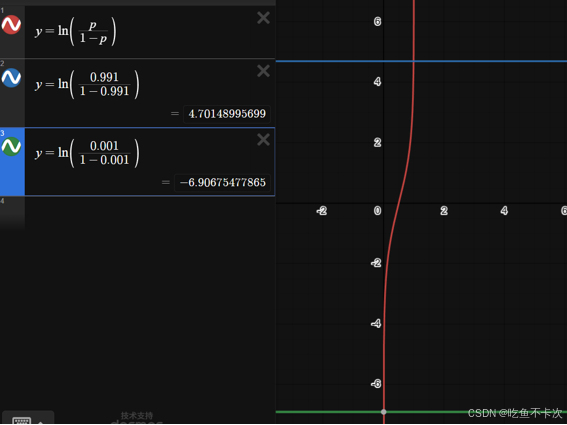
还有logit变换,在第2.1中我们也提到过生成噪声标签框最后也需要进行logit变换,就是将(0,1)区间内的值扩展到(-∞,+∞),公式如下:
函数图像如下所示,实际上我们来看,当x=0.001时,y=-6.9,当x=0.991,y=4.7,而且我们关心的anchor都是在[0.01,0.99]区间的,换句话说,经过logit变换也并没有把值变得很大或者很小,只是扩大了输出范围。
下图显示经过logit变换后的anchor box。
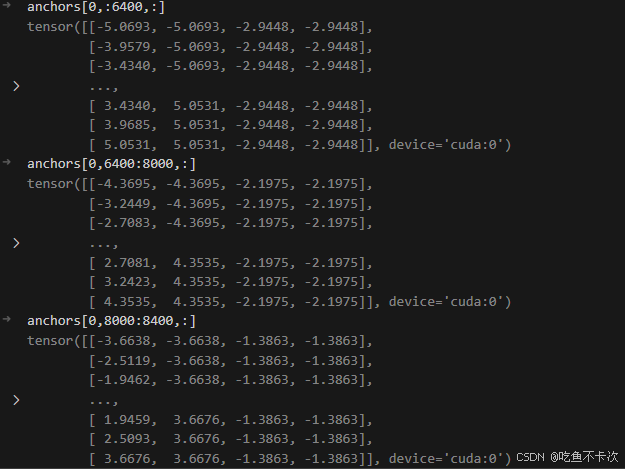
最后总结一下,主要就是对每个尺度生成anchor box,并将anchor box进行logit变换,最后过滤掉边缘的anchor box。
2.3Decoder模块
Decoder模块很大很复杂,在将数据输入到Decoder模块之前,还需要对数据进行处理,也就是2.3.1章节的Decoder Input
2.3.1Decoder Input
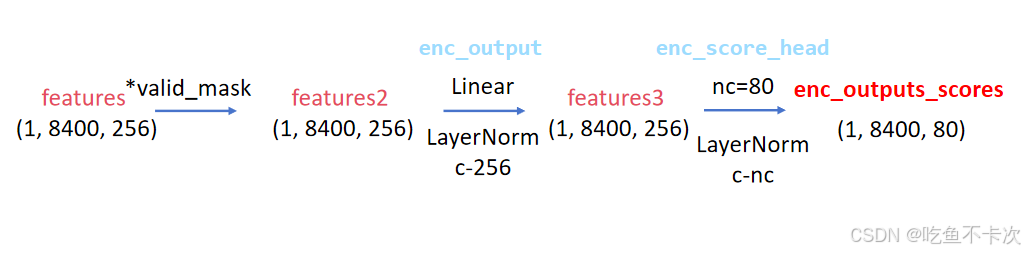
第一步,将Encoder得到的features通过valid_mask过滤掉边缘的一圈grid cell中心点,然后通过enc_score_head分类头得到和类别数相同通道数的enc_outputs_scores特征图,假设使用coco数据集,则nc=80,得到shape为(1,8400,80)的特征图。
- [ ] 需要注意一点:features和*valid_mask相乘过滤掉边缘的值,即将边缘的值赋0,但是后面又会经过enc_output和enc_score_head两个线性层,被赋0的值可能经过线性层后更新成非0值。
第二步,通过enc_outputs_scores来挑选出num_queries=300个具有最大的“置信度”的预测结果,记录下这300个结果的下标topk_ind;
需要注意一点:
- [ ] (1)enc_outputs_scores并没有经过sigmoid,从而归一化每个类别的预测结果得到置信度;
- [ ] (2)挑选方法是通过比较8400个预测的类别最大值,挑出最大的300个。
第三步,首先借助topk_ind下标从anchors和features3中挑选出对应的anchor坐标,以及包含Encoder提取的特征图,得到top_k_anchors和top_k_features;然后需要通过三次线性层变换将top_k_fratures的通道数变成4为,用来表示预测框中心点以及宽高的偏移量,而top_k_anchors表示的是预测框的基准值(这个和YOLOv5的anchor base方法类似);最后将这两个值相加就得到refer_bbox。
第四步,得到预测框的位置信息refer_bbox,主要就是和前面生成的噪声标签进行拼接,变成了500个预测结果,其中前面200个是标签噪声的xywh,后300个是网络预测的xywh。enc_bboxes在这里先晾着,后面再说。
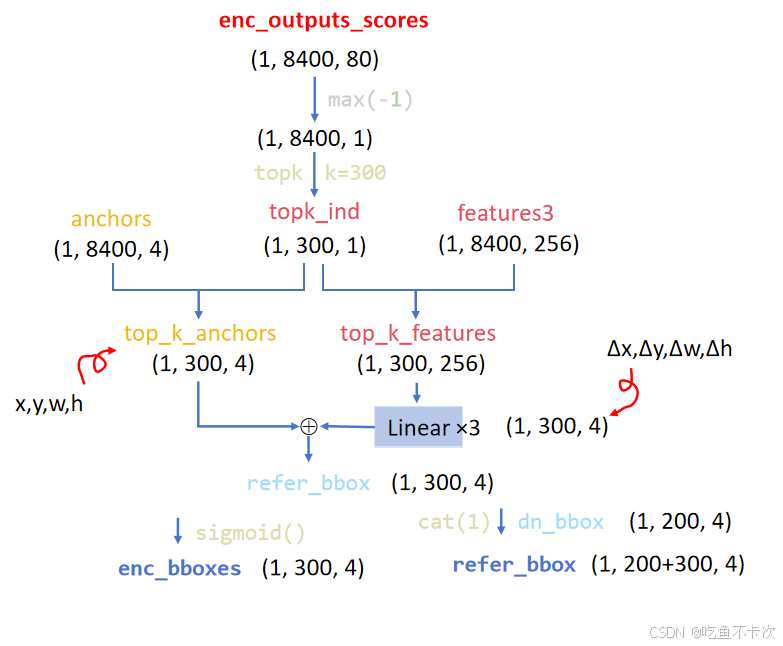
第五步,除了预测框的位置信息,还要有预测框的类别信息,如下所示,通过和前面生成的噪声类别dn_embed拼接得到embed,即为500个预测结果的类别信息;enc_scores这里也先晾着。

2.3.2Decoder
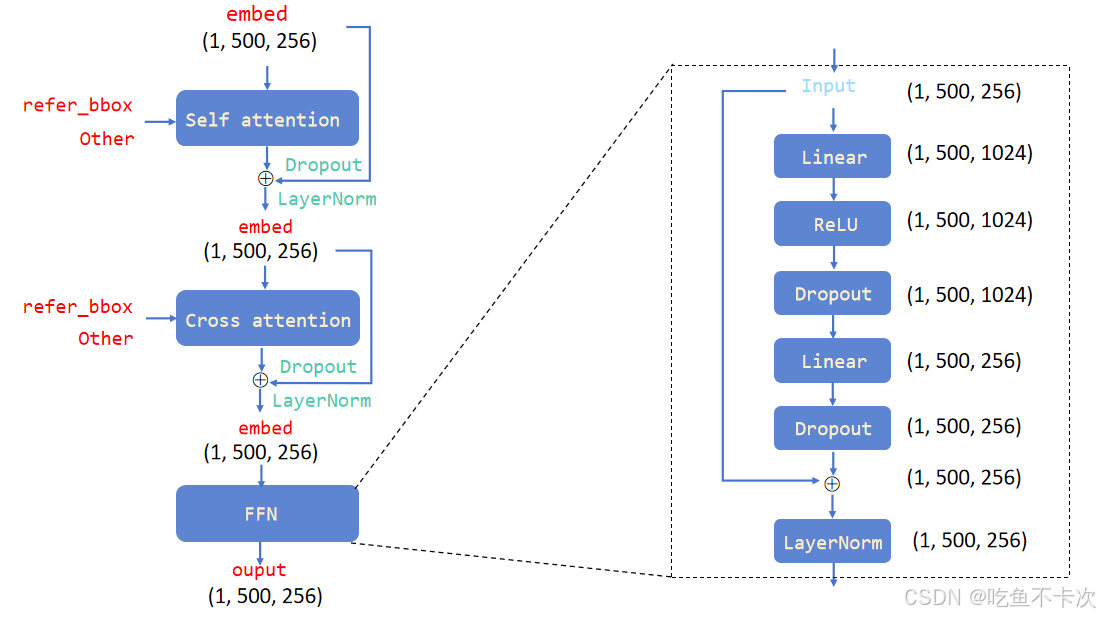
Decoder模块核心部分包括Self Attention和Cross Attention,下面来看看这两部分的具体内容。
2.3.2.1Self Attention
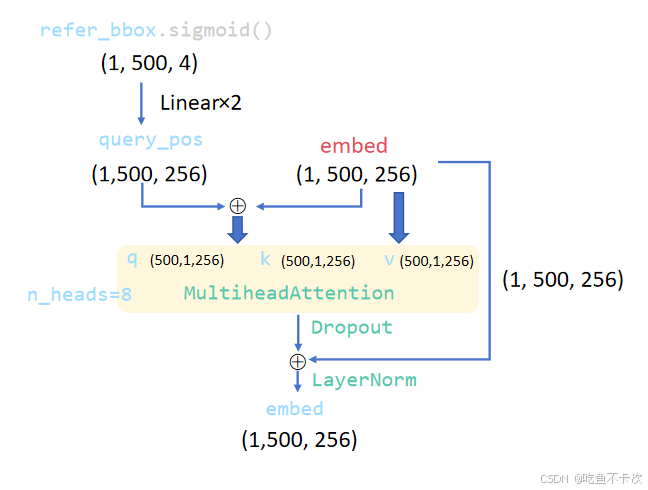
self-Attention的具体计算这里就不讲了,主要介绍下self-Attention的输入q,k,v,如下图所示:
(1)q和k:先将refer_bbox使用sigmoid归一化到(0,1)范围内,然后通过两个Linear线性层将维度从4维扩大到256维,再和embed相加得到的输出结果作为q和k;
(2)v:直接将embed作为v;
注意:
(1)这里的MultiheadAttention使用的是nn.MultiheadAttention,q,k,v输入会通过Linear计算得到Q,K,V,其中Q和K负责计算权重,V作为权重的基准值。
(2)前面提到了refer_bbox包含了噪声标签框和网络预测标签框的xywh信息,升维到256维度的query_pos当然也会包含更高维度的位置信息,query_pos和embed对应位置相加可以理解为给只包含语义信息的embed加入位置信息。
(3)作为q和k的输入向量shape为(1,500,256),其中256表示每个向量都包含着位置信息和从Encoder提取的语义信息;并且这样的向量有500个,其中前200个为根据标签生成的噪声标签向量(也可以记为DN query),后面300个为模型预测的向量(记为正常query)。
这500个向量进行self-Attention相似度计算的时候,需要设置attn_mask,如下所示,前面2.1章的时候也提到过,黑色区域需要计算相似度,灰色区域需要进行屏蔽无需计算相似度(实际上操作是给灰色区域填 -inf,后面再做softmax的时候灰色区域的值就为0了).
(4)那么这个self-Attention到底学会了什么呢?
①前200行-前200列:组间进行屏蔽,组内进行注意力权重计算,主要是正样本之间会相互强化,而负样本会从正样本中学习如何纠正,或者因为与正样本差异过大而被抑制。
②前200行-后300列:前200个的噪声标签向量有明确的监督信号和优化方向,当噪声标签从网络预测的标签中提取信息时,计算损失,梯度会反向传播,后300个网络预测的标签也会得到梯度,从而被优化,通过引入噪声标签可以加速优化过程。
③后300行-前200列:只有训练阶段存在DN query,所以为了不影响预测阶段正常query不依赖DNquery,屏蔽正常query对DNquery的关注。
④后300行-后300列:正常query之间可以交换信息,可以实现去重,增强上下文理解等,这就是RT-DETR不需要NMS后处理的原因,在推理过程中自动协调,根本不让重复框产生。
2.3.2.2Cross Attention
实际上就是Deformable Attention可变形注意力,来自论文《
DEFORMABLE DETR: DEFORMABLE TRANSFORMERS FOR END-TO-END OBJECT DETECTION》
链接为https://openreview.net/pdf?id=gZ9hCDWe6ke
首先来看看这部分内容:
(1)query_pos和前一节中self-Attention输出的embed相加得到query,这里的query_pos和self-Attention中的query_pos实际上是同一个,而embed则是经过注意力后的新的embed,得到的query包含了500个预测结果的语义信息和的位置信息。
(2)左边输出的是sampling_location,shape为(1,500,8,3,4,2),可以先这么去理解:一共500个预测结果,每个结果分成8个头,每个头有3个尺度,每个尺度取4个点进行预测XY,其中8个头一般要去学习的方向。
(3)右边输出的是attention_weights,shape为(1,500,8,3,4),可以理解为sampling_location准备的权重,也可以理解为Deformable Attention的权重,不过并没有通过Q和K去计算,而是直接通过Linear+softmax计算得到,从某种意义来说,Deformable Attention只是普通的Attention,并不是self-Attention。
注意:注意力权重 12个数的和为1,也就是3个层的12个点的权重之和为1.
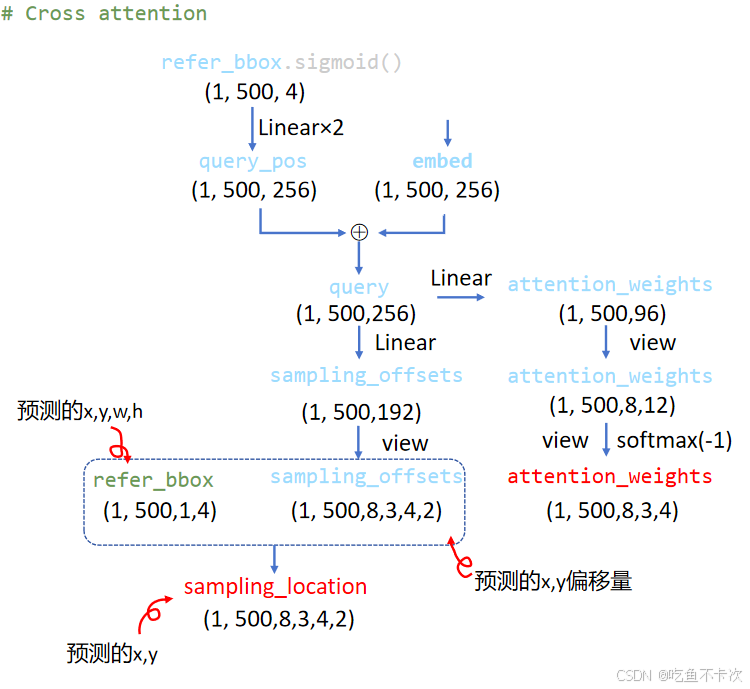
现在来细讲下左边的输出sampling_location,首先sampling_offsets是query通过Linear层得到的,表示预测的x,y偏移量,其次refer_bbox则是经过sigmoid处理后结果,取值范围为(0,1),(实际上和(1)中的refer_bbox.sigmoid是同一个值),表示预测的x,y,w,h,最后通过下面这条式子得到sampling_location,表示预测的x,y坐标。
注意:refer_bbox 的 cx, cy, w, h 是对整个输入图像的归一化比例(左上 0,0,右下 1,1)
先来看这个计算公式,首先中心点肯定就是直接取refer_bbox中预测的xy中心点,然后需要加上相对偏移量得到预测的x,y坐标,相对偏移量的计算是通过(sampling_offsets/n_points)乘以半边长来计算得到的,这里的n_points=4,这里我觉得除以其他数也行,目的就是为了让模型更好收敛。
得到的sampling_loaction都是归一化之后的坐标,不过由于sampling_offsets是纯神经网络的输出结果,所以也有可能存在>1或者<0的情况
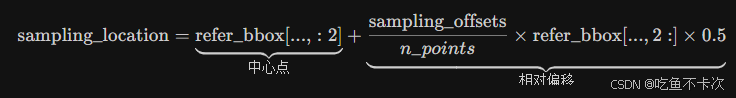
说到这里就补充一下Deformable Attention的基本原理,详细可以去看看大佬的文章:https://zhuanlan.zhihu.com/p/700776674,这里我就用自己的话来谈谈理解:
首先,只选取一部分的点而不使用全部的点做attention,可以更节省计算资源;
其次,如何选取这部分的点呢?在这里分成了8个方向,每个方向有3个尺度,每个尺度有4个点,简单可以理解成下图所示,一共有500个预测结果,红色点表示其中一个预测结果,以红色点为中心,不断优化sampling_offsets采样点的位置(即绿色点);
最后,再对采样的点(绿色点)和预测的点(红色点)做attention生成权重来更新预测的点(红色点),为了更简洁,attention这一步也省了,直接使用Linear+softmax来计算权重

接下来看看如何利用sampling_location的坐标,
因为拆分成了8个头,所以也需要将Encoder输出的features拆分成8个头得到value,那么每个头的维度为32,如下所示。
注意,这里的feature是指Encoder层输出的3个尺度特征图拼接的features,注意和前面在计算Decoder Input使用所用到的features2,features3相区别开来。

可以看到下图流程,我们先来看第1部分:
-
[ ] 输入:
value(1,8400,8,32),代表着从Encoder中提取的特征,然后分成8个头,每个头包含32个维度的特征。
sampling_location(1,500,8,3,4,2),代表着500个预测结果,每个结果分成8个头,每个头有3个尺度,每个尺度取4个点进行预测XY,其中8个头一般要去学习的方向。
-
[ ] 输出:
3个(8,32,500,4)的列表,代表从3个尺度中得到的结果,然后经过stack和flatten后得到sampling_value_list(8,32,500,12)
-
[ ] 过程:
(1)首先value将(1,8400,8,32)划分成三个尺度,分别为80x80尺度的(1,6400,8,32)、40x40尺度的(1,1600,8,32)和20x20尺度的(1,400,8,32);
(2)然后sampling_location取出各自尺度下预测的点,Shape为(1,500,8,4,2),代表着以500个预测点作为中心点,在8个方向上各采样的4个点;
(3)最后,在每个尺度下对这些点的位置进行插值,得到3个shape为(8,32,500,4)的结果,比如在20x20尺度下,value值reshape成(1,8,32,20,20),然后将sampling_location中采样的点映射到20x20尺度下,通过双线性插值方法获取该点对应的32维度的特征向量,shape为(8,32,500,4);
(4)最最后,再将这3个shape为(8,32,500,4)的结果通过stack和flatten得到sampling_value_list(8,32,500,12),其实就是表示的是500个预测结果中,每个预测结果在8个方向上,三个尺度共12个点,每个点对应的value值的特征向量。
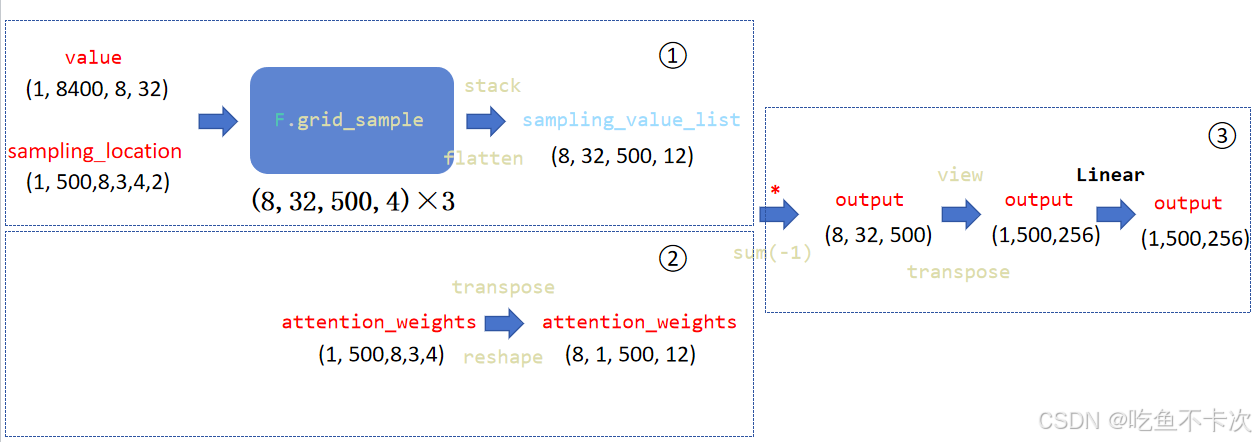
再来看第2部分:
这部分主要是将attention_weights的维度进行交换和调整,只需要注意最后一维的12个数的和为1,
即每个方向上有3个尺度共12个点的权重和为1。
最后来看第3部分:
sampling_value_list和attention_weights对应相乘再相加,这就是Attention计算的流程,然后再8个头的结果拼接在一起,这是multi-head Attention的计算过程。
现在来看下F.grid_sample插值,代码只有一行
sampling_value_l_ = F.grid_sample(value_l_, sampling_grid_l_, mode="bilinear", padding_mode="zeros", align_corners=False)
首先需要将sampling_locations的xy坐标全部映射到下面这种坐标系中,这种坐标系也是grid_sample 所需的 [-1, 1] 坐标系,前面也已经提到sampling_locations的范围大部分也是在(0,1)之间的,所以转换成[-1,1]坐标系后大部分点的范围也是在(-1,1)中的。
转换代码也简单,如下所示:
sampling_grids = 2 * sampling_locations - 1
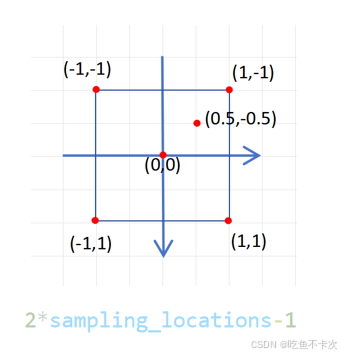
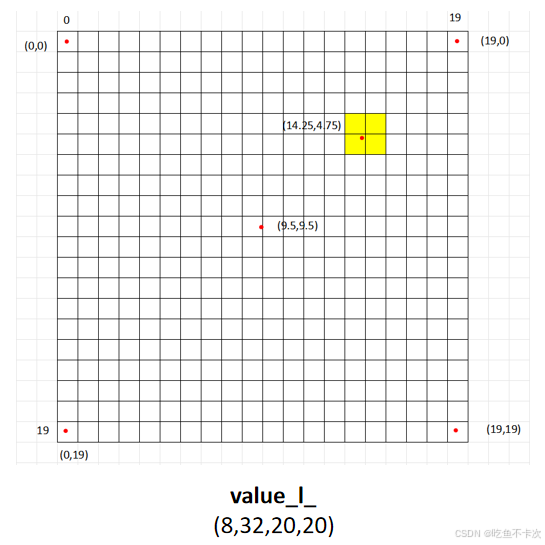
以(20,20)尺度为例,sampling_grid_l_的shape为(8,500,4,2),value_l_的shape为(8,32,20,20),经过插值将得到shape为(8,32,500,4)的值,简单来看一下计算过程:
(1)首先W和H均为20,根据下面公式将点(0,0),(-1,-1),(1,-1),(-1,1),(1,1)和(-0.5,-0.5)映射到(20,20)尺度下。

得到(9.5,9.5),(0,0),(19,0),(0,19),(19,19)和(14.25,4.75)映射点,如下图所示。
注意,如果存在越界的点,会将越界侧邻居被当成 0 参与插值。
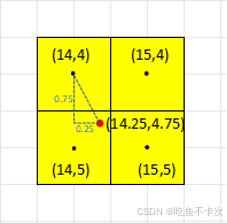
(2)进行双线性插值计算:取周围 4 个像素值,按双线性权重加权求和,得到 32维的向量,下面以(14.25,4.75)为例,分别计算周围4个点(14,4),(14,5),(15,4)和(15,5)的权重w11,w12,w21,w22,然后再取这4个点的32维度和权重加权求和,得到(14,25,4.75)的插值结果。
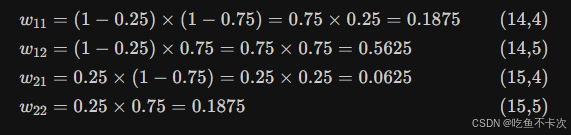
(3)在RT-DETR中,前面已经说过了,每个尺度下都会有4个点,那么F.grid_sample就是计算每个尺度下这4个点对应的32维度的特征值。
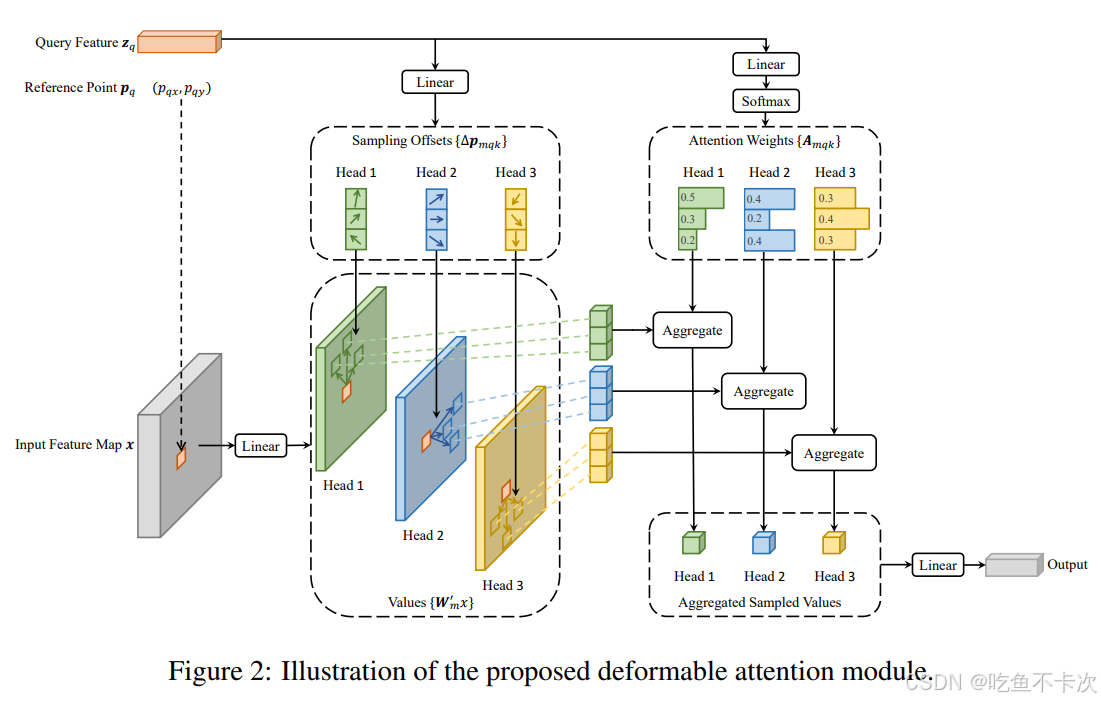
为了更好地自恰,我们现在来看下DEFORMABLE DETR论文的这张图:
(1)Reference Point即为refer_bbox中预测的500个结果中的任意一个;
(2)Query Feature即为query,包含了500个预测结果的语义信息和的位置信息;
(3)Query Feature有两个分支,一个分支得到Sampling Offsets,表示相对于Reference Point的XY偏移量,和Reference Point相加后得到Sampling_location,代表采样的点坐标,并且经过插值得到带有Value向量维度的特征图;另一个分支得到Attention weights,代表采样点的权重;在这张图中,我们可以看到他共设置了三个头(head1,head2,head3),并且只画出来了一个尺度,且每个尺度下有3个点,因此权重是针对一个尺度共3个点的权重;
(4)每个头的权重和采样点的特征相乘,然后再将3个头拼接在一起,经过一个Linear层得到输出结果。
2.3.3Decoder Output
2.3.3.1Decoder总结
现在先来梳理一下Decoder的流程,(1)两个模块,分别是self Attention和Cross Attention;(2)两个输入,embed提供的是语义信息,refer_bbox提供的是位置信息和框大小信息;(3)一个FFN模块,也是经典的先升维再降维,并通过残差连接得到输出结果。
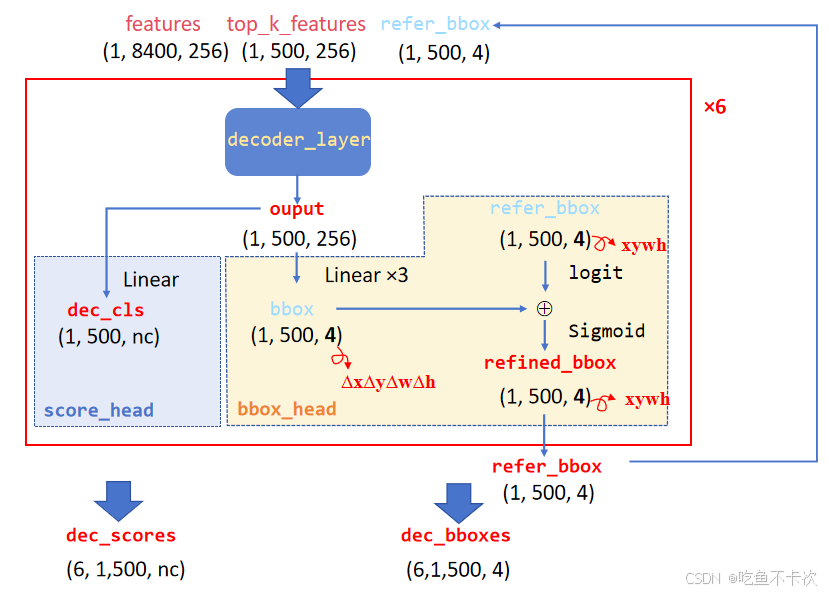
这样的结构Decoder实际上有6层,记为下图中的decoder_layer,并且每层都会保存一些中间参数dec_bboxes和dec_cls,分别通过score_head和bbox_head得到。
score_head直接将每层中decoder_layer的输出结果经过一个Linear层,得到500个预测结果在nc个类别的预测值dec_cls.
bbox_head将每层中decoder_layer的输出结果经过三个Linear层,得到500个预测结果的xywh的偏移量,然后再和logit处理后的refer_bbox相加,最后将结果通过sigmoid压缩在(0,1)范围得到refined_bbox,也就是更新后的refer_bbox。
经过6层后得到dec_cls和dec_bboxes,shape分别为(6,1,500,nc)和(6,1,500,4)。
这里注意一点:
_get_decoder_input 给的 refer_bbox 只是 “起跑线”, 6 层 decoder 就是 6 次 refine,每层都用 最新框 去指导可变形 attention 采样,再输出更小残差,最终才得到 真正精确的预测框。
2.3.3.2Decoder Output
Decoder Output包含两部分:
一部分是从Encoder中提取出的enc_bboxes和enc_scores;
另一部分是从Decoder中提取到的dec_bboxes和dec_scores;
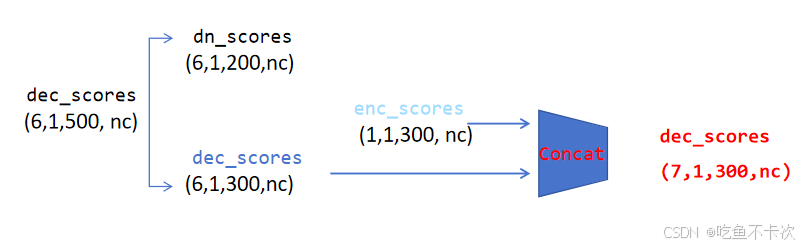
经过拆分及拼接处理,Decoder Output最后的输出由下面四部分组成:
(1)dec_bbox和dec_scores前200个是混合了噪声的向量,进一步将dec_bbox拆分成dn_bboxes和dec_bboxes,将dec_scores拆分成dn_scores和dec_scores.这里噪声标签预测会输出dn_bboxes和dn_scores;
(2)将Encoder的输出enc_bboxes和Decoder的输出dec_bboxes进行拼接,得到dec_bboxes;
(3)将Encoder的输出enc_scores和Decoder的输出dec_scores进行拼接,得到dec_scores;
注意:这里的第二维参数是指的batch size,这里以bs=1为例说明

2.4Loss损失计算
class RTDETRDetectionLoss(DETRLoss):"""Real-Time DeepTracker (RT-DETR) Detection Loss class that extends the DETRLoss.This class computes the detection loss for the RT-DETR model, which includes the standard detection loss as well asan additional denoising training loss when provided with denoising metadata."""def forward(self, preds, batch, dn_bboxes=None, dn_scores=None, dn_meta=None):""" # (dec_bboxes, dec_scores), targets, dn_bboxes=dn_bboxes, dn_scores=dn_scores, dn_meta=dn_metaForward pass to compute the detection loss.Args:preds (tuple): Predicted bounding boxes and scores.batch (dict): Batch data containing ground truth information.dn_bboxes (torch.Tensor, optional): Denoising bounding boxes. Default is None. torch.Size([6, 3, 200, 4])dn_scores (torch.Tensor, optional): Denoising scores. Default is None. torch.Size([6, 3, 200, 1])dn_meta (dict, optional): Metadata for denoising. Default is None.Returns:(dict): Dictionary containing the total loss and, if applicable, the denoising loss."""pred_bboxes, pred_scores = predstotal_loss = super().forward(pred_bboxes, pred_scores, batch)# Check for denoising metadata to compute denoising training lossif dn_meta is not None:dn_pos_idx, dn_num_group = dn_meta["dn_pos_idx"], dn_meta["dn_num_group"]assert len(batch["gt_groups"]) == len(dn_pos_idx)# Get the match indices for denoising 1.正样本的下标(0,1,2,3...99) 2.对应的标签下标 (0,1,0,1,0,1...)match_indices = self.get_dn_match_indices(dn_pos_idx, dn_num_group, batch["gt_groups"])# Compute the denoising training lossdn_loss = super().forward(dn_bboxes, dn_scores, batch, postfix="_dn", match_indices=match_indices)total_loss.update(dn_loss)else:# If no denoising metadata is provided, set denoising loss to zerototal_loss.update({f"{k}_dn": torch.tensor(0.0, device=self.device) for k in total_loss.keys()})return total_loss
2.4.1匈牙利算法
一句话来说就是:从一堆预测框中选出几个预测框,然后和真实标签一一对应,这个过程需要利用已有的信息制定规则构造一个cost矩阵,通过cost矩阵来选出那几个预测框。在RT-DETR中,需要借助预测的类别信息和位置信息来构建cost矩阵。
为了更具普适性,在解释这块内容的时候使用的是bs=2,一共有两个类别cls0和cls1,还是使用2.1的这个例子来举例说明。
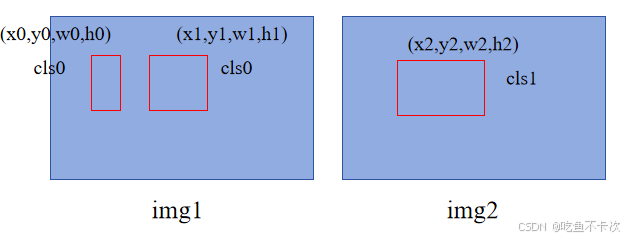
1.对于预测类别信息:
首先将dec_scores最后一层的结果提取出来并展开,然后做sigmoid归一化,shape为(600,2),表示有600个预测结果,每个预测结果都有cls0和cls1这两个类别的预测概率,记为Step1.
然后根据gt_cls提供的索引,取出每个预测结果对应的真实标签的预测概率,shape为(600,3),记为Step2.
这里用一个简单的例子看看这个过程,假设现在只有6个预测结果,其他一样,如下所示。
#Step1. shape(6,2)
pred_scores=[[0.9, 0.1],[0.8, 0.2],[0.3, 0.7],[0.4, 0.6],[0.2, 0.8],[0.5, 0.5]]#Step2 gt_cls = [0, 0, 1] shape(6,3)
pred_scores= [[0.9000, 0.9000, 0.1000],[0.8000, 0.8000, 0.2000],[0.3000, 0.3000, 0.7000],[0.4000, 0.4000, 0.6000],[0.2000, 0.2000, 0.8000],[0.5000, 0.5000, 0.5000]]
最后利用前面计算得到的pred_scores来计算类别的Cost矩阵,这里使用了计算Focal Loss的方法来得到positive loss和negative loss,代码如下所示:
neg_cost_class = (1 - self.alpha) * (pred_scores**self.gamma) * (-(1 - pred_scores + 1e-8).log()) #torch.Size([900, 6])
pos_cost_class = self.alpha * ((1 - pred_scores) ** self.gamma) * (-(pred_scores + 1e-8).log())
cost_class = pos_cost_class - neg_cost_class #构建成本矩阵
这里以pred_scores第一个预测结果,也即是第一行[0.9000, 0.9000, 0.1000]为例,说明cost_class 的计算过程。
post_cost_class: [0.0050, 0.0050, 0.5699]
**negative_cost_class: ** [1.3988e+00, 1.3988e+00, 7.9020e-04]
cost_class: [-1.3938, -1.3938, 0.5691]
我们可以看到,当预测概率越大,则pos_cost_class(positive loss)的值肯定越小,而neg_cost_class(negative loss)的值相对越大,计算得到cost为负值;
当预测概率越小,则pos_cost_class(positive loss)的值肯定越大,而neg_cost_class(negative loss)的值相对越小,计算得到cost为正值。
cost矩阵就是代价矩阵,当代价为负值时候说明代价最小,会优先匹配代价低的,完整的cost矩阵应该是shape(600,3).
2.对于预测位置信息:
首先同样是取dec_scores最后一层的结果并展开得到pred_bboxes,表示600个预测结果的XYWH值,这个值都是归一化后的结果。

然后计算代价矩阵,首先是cost_bbox,计算的是600个预测框的XYWH到3个标签框的XYWH的L1距离,再将这XYWH的距离求和,得到shape从(600,3,4)变为(600,3);cost_bbox用来表示框的位置/大小与 GT 的距离,距离越近,cost 越小,越容易被匹配。
其次是cost_giou,和前面是一样的流程,只不过从L1距离变成了GIoU损失,cost_giou用来表示预测框和GT框的重叠面积,重叠多,则cost小。
# Compute the L1 cost between boxes
cost_bbox = (pred_bboxes.unsqueeze(1) - gt_bboxes.unsqueeze(0)).abs().sum(-1) # (bs*num_queries, num_gt) L1距离 # Compute the GIoU cost between boxes, (bs*num_queries, num_gt)
cost_giou = 1.0 - bbox_iou(pred_bboxes.unsqueeze(1), gt_bboxes.unsqueeze(0), xywh=True, GIoU=True).squeeze(-1)#giou
3.结果输出
最后将前面的三个cost按照对应权重想加得到最终的代价矩阵,
C = (self.cost_gain["class"] * cost_class #2+ self.cost_gain["bbox"] * cost_bbox #5+ self.cost_gain["giou"] * cost_giou #2
)然后使用 linear_sum_assignment来计算匈牙利匹配,得到以下结果,注意这里是把两张图的预测结果拆分开,分别进行匹配,该结果表明第0张图的第8、12号预测分别对应它的1、0号 GT,第1张图的第12号预测对应它的2号 GT。
[(array([ 8, 12], dtype=int64), array([1, 0], dtype=int64)),
(array([12], dtype=int64), array([2], dtype=int64))]
2.4.2 total_loss
在通过匈牙利匹配获取到每个预测结果对应的真实标签后,现在就可以进行损失的计算了,分别有loss_class、loss_bbox、loss_giou和aux_loss.
2.4.2.1 loss_class
我把整个过程缩略的介绍一下,我们已经从前面得到了预测框和标签的匹配关系,
第0张图中,第8、12号预测分别对应它的1、0号 GT,类别均为cls0,下标记为0.
第1张图中,第12号预测对应它的2号 GT,类别为cls1,下标记为1.
下面展示的是三个重要的计算参数:
(1)onehot:表示300个预测结果的类别独热编码,比如第0张图的第8、12号预测分别对应它的1、0号 GT,这两个GT的类别都是0,所以对应的onehot均为[1,0].
(2)gt_scores:其实就是带权重的onehot编码,这个权重就是预测框和GT框的IoU值.
(3)pred_scores:是直接通过dec_scores取最后一层输出+sigmoid得到的,表示模型的300个预测结果对类别预测概率.

下面是loss_class的计算公式,使用的是VFL,p代表pred_scores,q表示gt_scores。我们可以看到正例和负例有不同的权重:
(1)正例:gt_score*label,其实就是gt_score.
(2)负例:alpha * pred_score.sigmoid().pow(gamma) ,其实就是focal loss那一套.

举个简单的计算例子吧:
第一张图片中第8号预测结果为[0.7,0.3],这里面就包含了一个正例和一个负例,正例为0.7,负例为0.3,
所以正例的loss为:
-0.8*(0.8*log(0.7)+(1-0.8)*log(1-0.7))=0.42
负例的loss为:
-0.75*(0.3**2)*log(1-0.3)=0.024
所以对于第一张图片中第8号预测的loss_class为[0.42,0.024],对于其他预测一样进行计算,然后再根据类别来求平均损失(.mean(1)),最后再求总损失(.sum())
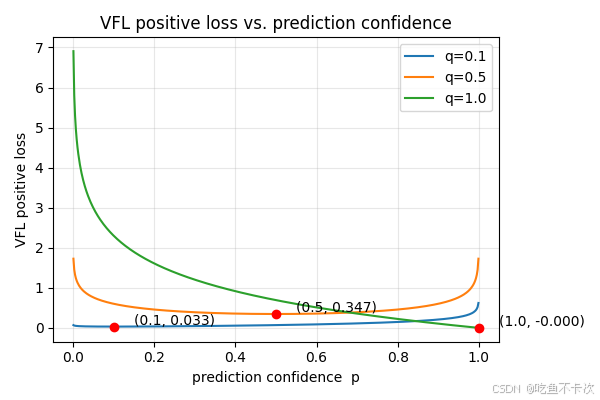
下面来看看正例计算公式的函数图像,横轴表示预测的置信度,纵轴表示loss值,这里列出了Iou=0.1、0.5和1.0三种情况的函数图像,观察该图像我们可以看到,当IoU=1时,说明预测框和GT框完全重合,这时候置信度越接近1,loss越小;当IoU=0.1时,说明预测框和GT框相差甚远,这时候哪怕置信度很高,这种置信度也不可信,所以此时的loss是很大的一个值;
所以将Iou值作为标签值,而不是直接使用1作为标签值,可以防止模型过度自信,选出那些置信度很高但是IoU却很低的框。
对于正例,模型优化方向是置信度去接近于IoU值,这时候loss是最小的。
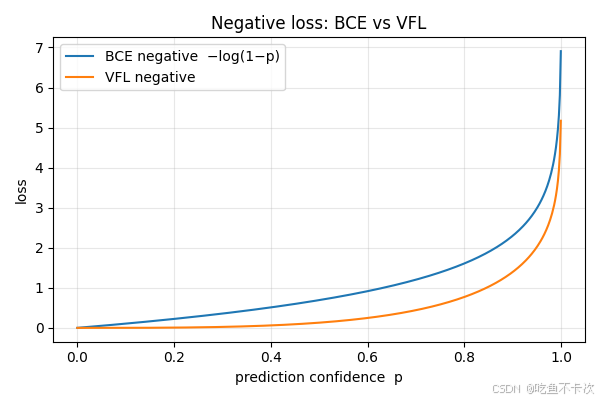
**对于负例的loss函数图像,横轴表示预测的置信度,纵轴表示loss值,**相比于BCE Loss,VFL会对那些易于区分的loss设置的更小,什么属于易于区分呢,就是置信度接近于1或者接近于0的那些预测,这也是Focal Loss的核心了。
对于负例,模型优化方向是给予很低的预测置信度,这时候loss是最小的。
下面是VarifocalLoss的源码。
class VarifocalLoss(nn.Module):"""Varifocal loss by Zhang et al.https://arxiv.org/abs/2008.13367."""def __init__(self):"""Initialize the VarifocalLoss class."""super().__init__()@staticmethoddef forward(pred_score, gt_score, label, alpha=0.75, gamma=2.0):"""Computes varfocal loss.""" #pred_scores, gt_scores, one_hotweight = alpha * pred_score.sigmoid().pow(gamma) * (1 - label) + gt_score * label #shape: torch.Size([2, 300, 2])with torch.cuda.amp.autocast(enabled=False):loss = ((F.binary_cross_entropy_with_logits(pred_score.float(), gt_score.float(), reduction="none") * weight).mean(1).sum())return loss
2.4.2.2 loss_bbox和loss_giou
还是前面得到了预测框和标签的匹配关系,
第0张图中,第8、12号预测分别对应它的1、0号 GT.
第1张图中,第12号预测对应它的2号 GT.
如下图所示,注意pred_bbox是由前面dec_bbox最后一层+匈牙利匹配下标得到的,代表归一化之后的XYWH,gt_bboxes也是归一化之后的XYWH标签值。
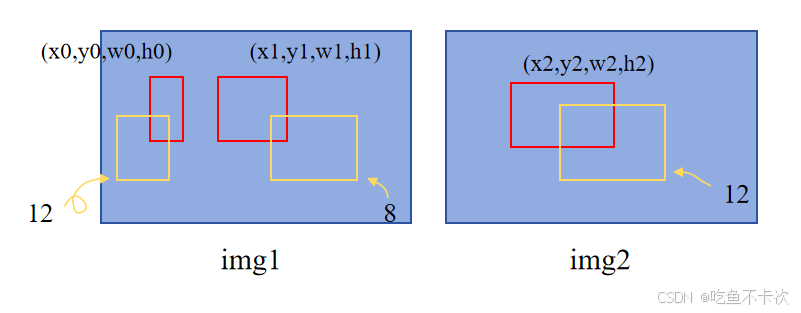
首先loss_bbox计算的是L1距离,也就是曼哈顿距离,计算公式如下
loss_giou计算的是GIoU损失,这里就不再详细去说明了。
关于框的损失,具体代码如下,相对类别损失,框的损失还是比较清楚的,毕竟一对一的正样本。
def _get_loss_bbox(self, pred_bboxes, gt_bboxes, postfix=""):"""Calculates and returns the bounding box loss and GIoU loss for the predicted and ground truth boundingboxes."""#pred_bboxes, gt_bboxes, postfix# Boxes: [b, query, 4], gt_bbox: list[[n, 4]] name_bbox = f"loss_bbox{postfix}"name_giou = f"loss_giou{postfix}"loss = {}if len(gt_bboxes) == 0:loss[name_bbox] = torch.tensor(0.0, device=self.device)loss[name_giou] = torch.tensor(0.0, device=self.device)return lossloss[name_bbox] = self.loss_gain["bbox"] * F.l1_loss(pred_bboxes, gt_bboxes, reduction="sum") / len(gt_bboxes)#L1距离 曼哈顿距离loss[name_giou] = 1.0 - bbox_iou(pred_bboxes, gt_bboxes, xywh=True, GIoU=True)loss[name_giou] = loss[name_giou].sum() / len(gt_bboxes)loss[name_giou] = self.loss_gain["giou"] * loss[name_giou]return {k: v.squeeze() for k, v in loss.items()}
2.4.3 aux_loss
前面一章计算的是主损失,而aux_loss计算的是辅助损失,也就是将主损失中没有用到的前6层,**每层都算一遍主损失,**然后再相加。
注意这里的前6层中的第一层是enc_bboxes和enc_scores,并且通过enc_bboxes和enc_scores来做一次匈牙利匹配,后面所有层复用同一组匹配索引,避免每层都跑匈牙利,训练提速。
下面是保存的loss示例,可以看到aux loss明显大于主损失,因为aux loss是将6层的损失直接相加得到的。
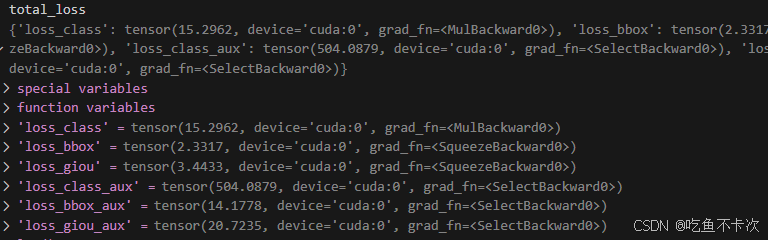
源码如下所示:
def _get_loss_aux(self,pred_bboxes,pred_scores,gt_bboxes,gt_cls,gt_groups,match_indices=None,postfix="",masks=None,gt_mask=None,):"""Get auxiliary losses."""# NOTE: loss class, bbox, giou, mask, diceloss = torch.zeros(5 if masks is not None else 3, device=pred_bboxes.device)if match_indices is None and self.use_uni_match:match_indices = self.matcher(pred_bboxes[self.uni_match_ind],pred_scores[self.uni_match_ind],gt_bboxes,gt_cls,gt_groups,masks=masks[self.uni_match_ind] if masks is not None else None,gt_mask=gt_mask,)for i, (aux_bboxes, aux_scores) in enumerate(zip(pred_bboxes, pred_scores)):aux_masks = masks[i] if masks is not None else Noneloss_ = self._get_loss(aux_bboxes,aux_scores,gt_bboxes,gt_cls,gt_groups,masks=aux_masks,gt_mask=gt_mask,postfix=postfix,match_indices=match_indices,)loss[0] += loss_[f"loss_class{postfix}"]loss[1] += loss_[f"loss_bbox{postfix}"]loss[2] += loss_[f"loss_giou{postfix}"]# if masks is not None and gt_mask is not None:# loss_ = self._get_loss_mask(aux_masks, gt_mask, match_indices, postfix)# loss[3] += loss_[f'loss_mask{postfix}']# loss[4] += loss_[f'loss_dice{postfix}']loss = {f"loss_class_aux{postfix}": loss[0],f"loss_bbox_aux{postfix}": loss[1],f"loss_giou_aux{postfix}": loss[2],}# if masks is not None and gt_mask is not None:# loss[f'loss_mask_aux{postfix}'] = loss[3]# loss[f'loss_dice_aux{postfix}'] = loss[4]return loss
2.4.4 dn_loss
还记得我们之前为了加快收敛,运用了对比去噪训练方法,当然也需要计算这部分的损失,即dn_loss.
还是掏出来这张图,img1中有两个标签,分别为(x0,y0,w0,h0)和(x1,y1,w1,h1),img2有一个标签,为(x2,y2,w2,h2).

然后每张图都会生成200个噪声(轻微噪声和严重噪声),需要记住的是positive(轻微噪声)的下标值,在本例中img1的值为[0,1,4,5,..196,197],img2的值为[0,4,8,12,...,196],也就是下图中红色的噪声坐标的下标值。
因为噪声标签是由GT标签生成的,所以我们是知道噪声标签对应的GT标签的,以第一张图为例,噪声标签下标为0,1,4,5,...对应上图中红色字体的标签,GT标签下标为0,1,0,1....表示噪声标签分别是由(x0,y0,w0,h0)和(x1,y1,w1,h1)生成的,具体可以去看对比去噪训练那一节内容。
#噪声标签
0: tensor([ 0, 1, 4, 5, 8, 9, 12, 13, 16, 17, 20, 21, 24, 25, 28, 29, 32, 33, 36, 37, 40, 41, 44, 45, 48, 49, 52, 53, 56, 57, 60, 61, 64, 65, 68, 69, 72, 73, 76, 77, 80, 81, 84, 85, 88, 89, 92, 93, 96, 97, 100, 101, 104, 105, 108, 109, 112, 113, 116, 117, 120, 121,124, 125, 128, 129, 132, 133, 136, 137, 140, 141, 144, 145, 148, 149, 152, 153, 156, 157, 160, 161, 164, 165, 168, 169, 172, 173, 176, 177, 180, 181, 184, 185, 188, 189, 192, 193, 196, 197])
#GT标签
1: tensor([0, 1, 0, 1, 0, 1, 0, 1, 0, 1, 0, 1, 0, 1, 0, 1, 0, 1, 0, 1, 0, 1, 0, 1, 0, 1, 0, 1, 0, 1, 0, 1, 0, 1, 0, 1, 0, 1, 0, 1, 0, 1, 0, 1, 0, 1, 0, 1, 0, 1, 0, 1, 0, 1, 0, 1, 0, 1, 0, 1, 0, 1, 0, 1, 0, 1, 0, 1, 0, 1, 0, 1, 0, 1, 0, 1, 0, 1, 0, 1, 0, 1, 0, 1, 0, 1, 0, 1, 0, 1, 0, 1, 0, 1, 0, 1, 0, 1, 0, 1])
接着就是按照total_loss的流程去计算dn_loss了,也就是说正样本就是轻微噪声,让轻微噪声慢慢恢复成GT标签,并且负样本就是严重噪声,直接去抑制这种标签。
最后一共求得了这么些loss.
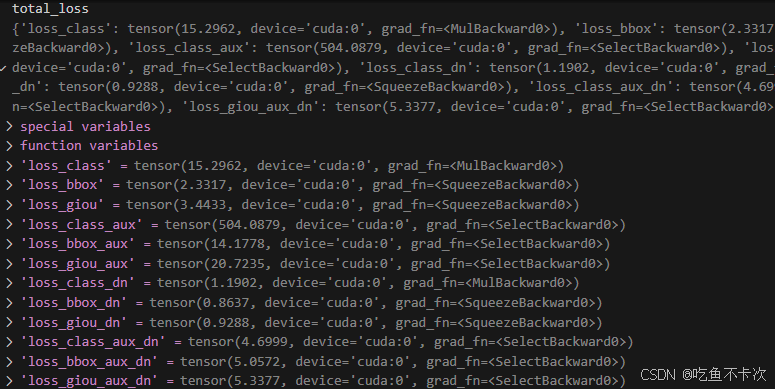
2.5预测流程
有了前面的学习,这块就尽量简洁一点来介绍了,和YOLOv8目标检测一样,一个模型的推理过程依旧包括数据预处理,模型推理以及后处理模块。

2.5.1preprocess
这部分基本没啥操作,letterBox也不是之前那种letterBox,这里的letterBox做的实际上是对图片直接缩放到(640,640)尺寸,相当简洁。
剩下的就是归一化等操作了。
2.5.2Inference
这部分就是把对比去噪训练的200个预测结果给去掉,只取网络预测出来的300个预测结果,然后取Decoder Output的最后一层作为结果dec_bboxes和dec_scores,其中dec_bboxes表示预测的归一化后的XYWH,需要将其转换为XYXY格式,即左上角右下角点坐标格式;dec_scores表示预测的所有类别的概率,需要经过sigmoid归一化到(0,1),然后筛选出每个预测结果中预测概率最大的值,通过conf阈值判定是否作为最后的结果输出,如下所示:

最后通过idx来获取置信度高的预测结果,在这里有7个预测结果的置信度>0.25,并且前四维表示XYXY坐标,且可以直接和原始图像的宽高相乘放大道原始图像尺寸,score是(0,1)范围的预测置信度,cls表示预测的类别下标。
从这里我们就可以看到RT-DETR的预处理和后处理是多么地简洁,和YOLOv8相比省略了letterbox,NMS等后处理过程,如今YOLO26即将横空出世,也是无NMS的算法,或许从Anchor base—>Anchor free — >无NMS就是目标检测发展的历史轨迹吧。

2.5.3PostProcess
无需任何后处理,或者后处理都在Inference中了.