Java-166 Neo4j 安装与最小闭环 | 10 分钟跑通 + 远程访问 Docker neo4j.conf
TL;DR
- 场景:从 0–1 搭 Neo4j 并远程访问,快速验证图模型与查询。
- 结论:按文中脚本 10 分钟起服务,Bolt/HTTP 可访,跑通建模/索引/查询。
- 产出:docker-compose.yml、init.cypher、neo4j.conf 片段,Linux 服务安装全流程

Neo4j
基本概念
Neo4j 是一个开源的原生图形数据库管理系统,采用 Java 语言开发。与传统的关系型数据库不同,它不采用表结构(Schema-less),而是以图的形式存储和管理结构化数据。
核心特性
-
原生图存储:
- 数据以节点(Node)和关系(Relationship)的形式存储
- 节点表示实体(如人、地点、事物)
- 关系表示节点间的连接(如"朋友"、"属于"等)
- 示例:社交网络中,用户是节点,"关注"是关系
-
事务支持:
- 完全支持 ACID(原子性、一致性、隔离性、持久性)事务
- 适用于需要强一致性的应用场景
- 包含完整的回滚机制
-
存储架构:
- 嵌入式数据库设计,可直接集成到Java应用中
- 基于磁盘的持久化存储,保证数据安全
- 支持高可用性和集群部署
-
灵活的数据模型:
- 不需要预先定义严格的表结构
- 支持动态添加新属性和关系类型
- 节点和关系都可以附加属性键值对
应用场景
-
社交网络:
- 高效处理用户间复杂的关系网络
- 快速查询"朋友的朋友"等多度关系
-
推荐系统:
- 基于用户-产品-兴趣的图结构
- 实现精确的个性化推荐
-
知识图谱:
- 构建实体间的语义关系网络
- 支持复杂的图遍历查询
-
欺诈检测:
- 分析交易网络中的异常模式
- 识别潜在的风险关联
技术优势
- 使用专门的图存储引擎,优化图遍历性能
- 支持 Cypher 查询语言,专为图数据设计
- 提供 Java API 和 REST 接口
- 支持索引加速特定查询
- 包含可视化工具,直观展示图结构
通过这种图结构的数据表示方式,Neo4j 能够更自然地建模现实世界中复杂的关联关系,在处理关联数据时比传统关系型数据库效率更高。
模块构建
节点
节点是图标的基本单位,它包含具有键值对的属性
属性
属性是用于描述图节点和关系的键值对
key=值,其中Key是一个字符串,值可以通过使用Neo4j数据类型来表示
关系
关系是图形数据库的另一个主要构建块,它连接两个节点,如下所示:
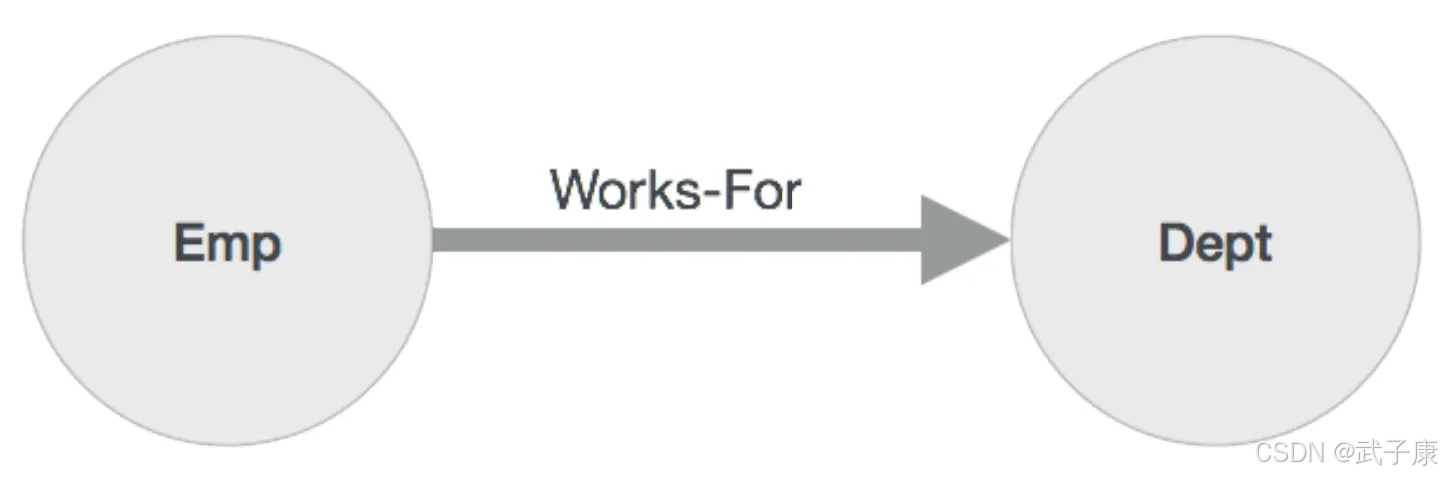
这里 Emp 和 Dept 是两个不同的节点,WORKS_FOR 是 Emp 和 Dept 节点之间的关系。
因为它表示从 Emp 到 Dept 的箭头标记,那么这种关系描述的一样,Emp WORKS_FOR Dept,每个关系包含一个起始节点和一个结束节点。
这里 Emp 是一个起始节点,Dept 是端节点,由于该关系箭头标记表示从 Emp 节点 到 Dept 节点的关系,该关系被称为进入关系到Dept节点,并且外向关系到Emp节点。
像节点一样,关系也可以包含属性作为键值对。
标签
Label 是 Neo4j 图数据库中的重要概念,它为节点或关系提供了一种分类和组织方式。通过 Label:
- 可以将多个节点或关系归类到同一类别下
- 支持高效的索引和查询
- 实现数据模型的语义化表达
Label 的具体应用
节点标签
在前面的示例图中:
- 左侧节点都被标记为
Emp标签,表示这些节点代表员工实体 - 右侧节点都被标记为
Dept标签,表示这些节点代表部门实体
关系标签
图中的关系被标记为 WORKS_FOR 标签,表示员工与部门之间的"工作于"关系。
Label 的操作
我们可以对 Label 执行以下操作:
-
添加标签:
- 可以为新创建的节点/关系添加标签
- 也可以为已存在的节点/关系添加新标签
-
删除标签:
- 可以从节点/关系上移除不再需要的标签
数据存储机制
Neo4j 将数据库中的所有数据(包括属性和标签)都存储在节点和关系中。标签提供了一种高效的分类机制,使得查询特定类型的节点或关系更加快速。
主要场景
社交媒体和社交网络
当使用图形数据库为社交网络应用程序提供动力时,可以轻松利用社交关系或者活动推荐关系。
查询社区聚类分析,朋友的朋友推荐,影响者分析,共享和写作关系分析等。
推荐引擎和产品推荐系统
图形驱动的推荐引擎通过实时利用多种连接,帮助司个性化产品,内容和服务。
身份和访问管理
使用图形数据库进行身份和访问管理时,可以快速有效的跟踪用户、资产、关系、授权。
查询访问管理,资源来源,数据所有权,身份管理,互联组织,主数据,资源授权
金融反欺诈多维关联
通过图分析可以清楚的指导洗钱网络相关嫌疑,例如对用户所使用的账号、发生交易的IP地址、MAC地址、手机IMEI号等进行关联分析。
环境搭建
容器搭建
我们可以快速启动一个 docker 服务来运行 Neo4j
# docker-compose.yml
services:neo4j:image: neo4j:5.26container_name: neo4jports:- "7474:7474" # HTTP- "7687:7687" # Boltenvironment:NEO4J_AUTH: neo4j/neo4j123 # 首登请改密NEO4J_server_default__listen__address: 0.0.0.0NEO4J_server_default__advertised__address: ${HOST_IP:-127.0.0.1}# 按需调整内存(容器默认很小)NEO4J_server_memory_heap_max__size: 2GNEO4J_server_memory_pagecache_size: 1Gvolumes:- ./data:/data- ./logs:/logs- ./conf:/var/lib/neo4j/conf
启动服务后,配置访问,可以运行如下脚本来启动一个demo
// init.cypher
CREATE (e1:Emp {name:"张三"})-[:WORKS_FOR {since:2018}]->(d1:Dept {name:"研发部"});
CREATE (e2:Emp {name:"李四"})-[:WORKS_FOR {since:2020}]->(d1);
CREATE INDEX emp_name IF NOT EXISTS FOR (e:Emp) ON (e.name);
CREATE INDEX dept_name IF NOT EXISTS FOR (d:Dept) ON (d.name);
服务搭建
下载项目
我们首先在服务器上,下载项目,或者SFTP传输也可以:
cd /opt/software
wget https://neo4j.com/artifact.php?name=neo4j-community-3.5.17-unix.tar.gz
解压项目:
tar -zxvf neo4j-community-3.5.17-unix.tar.gz
移动目录:
mv neo4j-community-3.5.17 ../servers/
修改配置
修改配置文件,neo4j.conf,修改之后支持远程访问
cd /opt/servers/neo4j-community-3.5.17
vim conf/neo4j.conf
修改的内容如下:
dbms.connectors.default_listen_address=0.0.0.0
对应的如下所示:
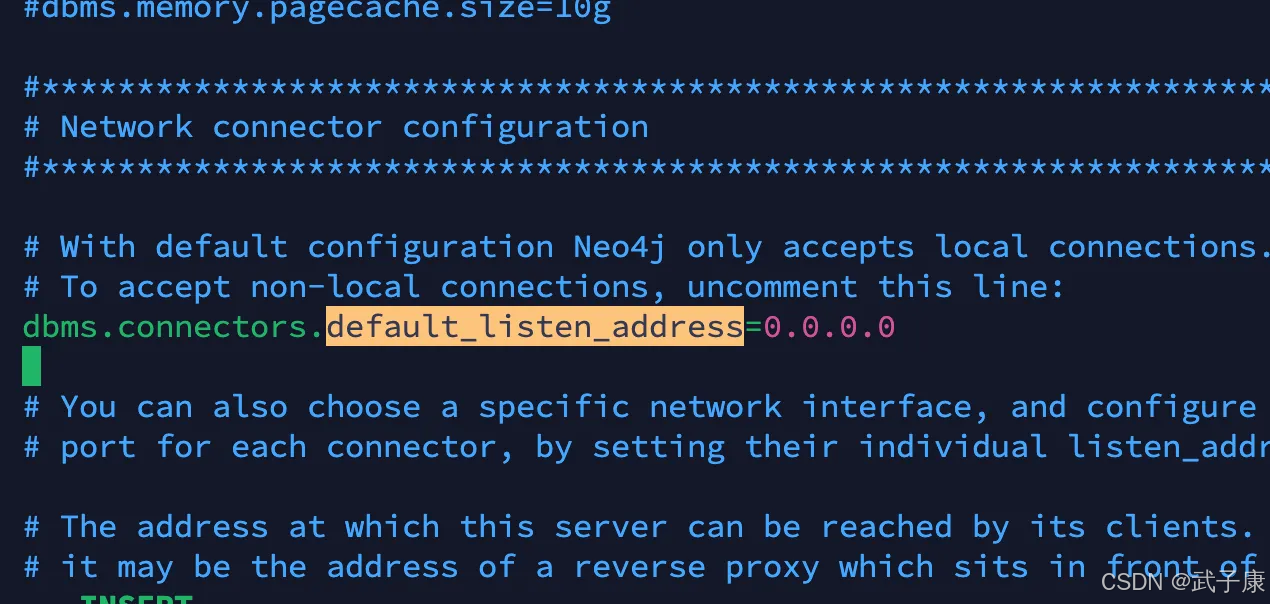
PS:防火墙注意要开放 7474和7687
启动服务
接着启动服务:
./bin/neo4j start
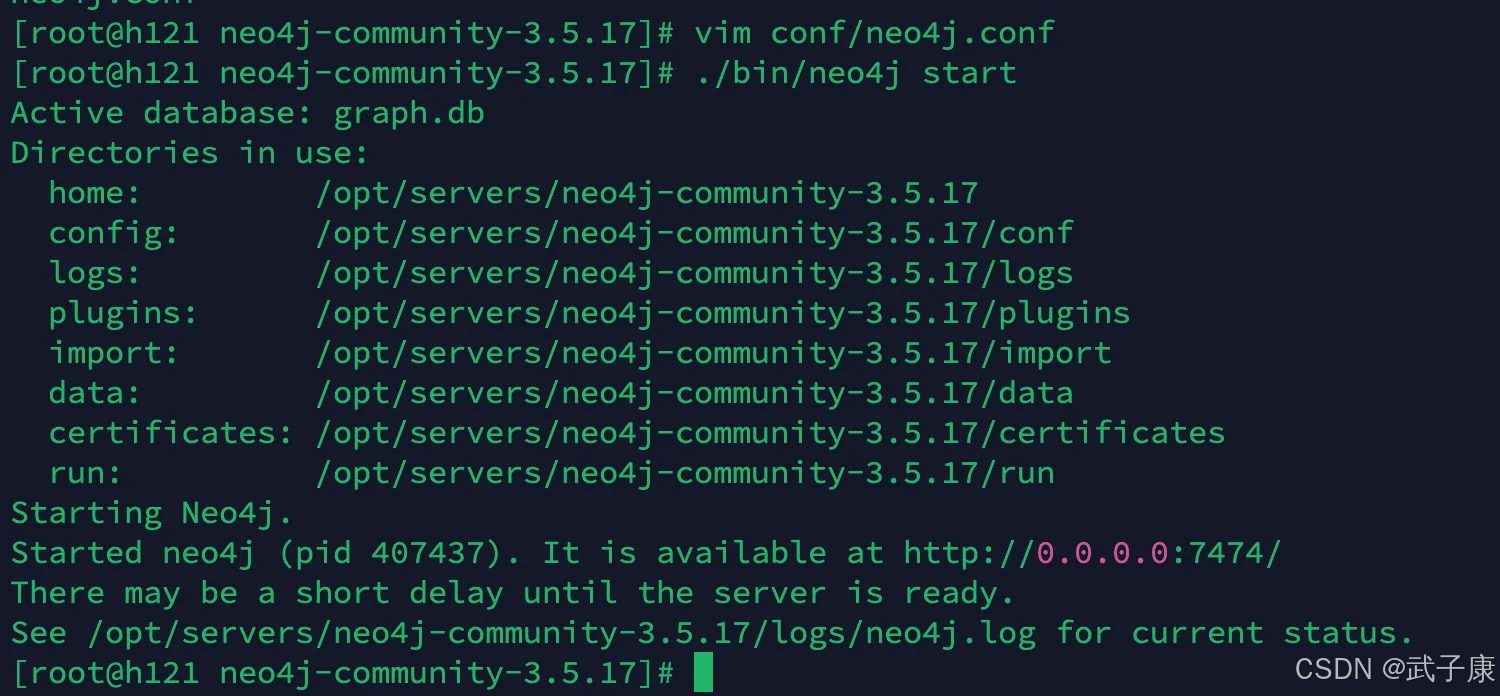
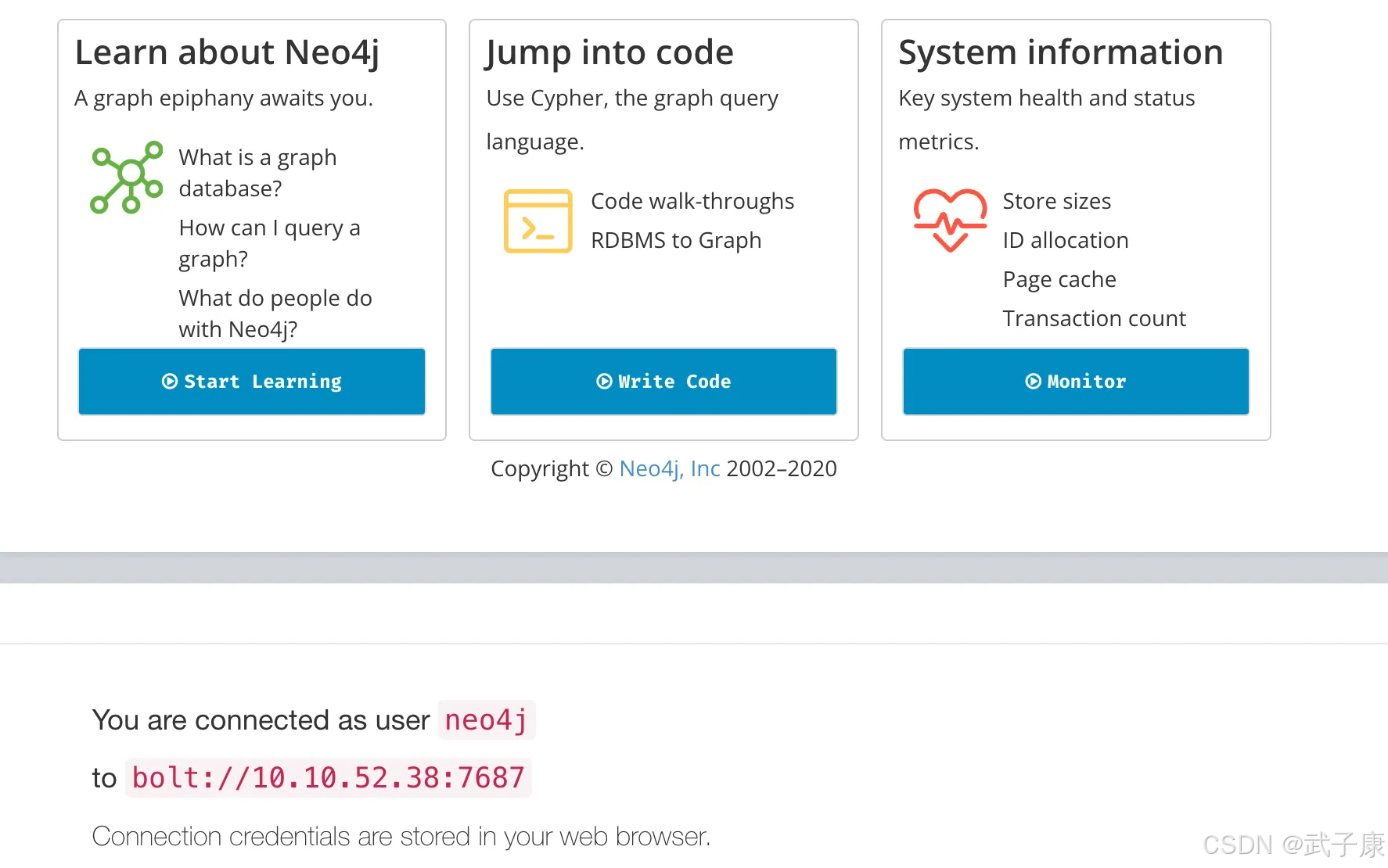
访问服务
访问网页的 7474,默认的账号密码都是 neo4j
http://10.10.52.38:7474/browser/

顺利登录的话,可以看到如下的内容:
关键配置
server.default_listen_address=0.0.0.0
server.http.listen_address=:7474
server.bolt.listen_address=:7687
# 对外宣告(NAT/容器环境常用)
server.default_advertised_address=你的公网或主机IP
错误速查
| 症状 | 可能原因 | 排查/修复方法 |
|---|---|---|
| 7474/7687 端口不通 | 监听仅 localhost | 修改 server.default_listen_address=0.0.0.0,确认防火墙/NAT 端口映射 |
| 登录失败/强制改密 | 首次登录需改默认密码 | 使用 Neo4j Browser 或 cypher-shell 设置新密码 |
| 内存不足 | 容器默认内存配置极小 | 调高 NEO4J_server_memory_* 系列环境变量参数 |
其他系列
🚀 AI篇持续更新中(长期更新)
AI炼丹日志-29 - 字节跳动 DeerFlow 深度研究框斜体样式架 私有部署 测试上手 架构研究,持续打造实用AI工具指南!
AI-调查研究-108-具身智能 机器人模型训练全流程详解:从预训练到强化学习与人类反馈
🔗 AI模块直达链接
💻 Java篇持续更新中(长期更新)
Java-154 深入浅出 MongoDB 用Java访问 MongoDB 数据库 从环境搭建到CRUD完整示例
MyBatis 已完结,Spring 已完结,Nginx已完结,Tomcat已完结,分布式服务正在更新!深入浅出助你打牢基础!
🔗 Java模块直达链接
📊 大数据板块已完成多项干货更新(300篇):
包括 Hadoop、Hive、Kafka、Flink、ClickHouse、Elasticsearch 等二十余项核心组件,覆盖离线+实时数仓全栈!
大数据-278 Spark MLib - 基础介绍 机器学习算法 梯度提升树 GBDT案例 详解
🔗 大数据模块直达链接