HTML应用指南:利用POST请求获取全国爱回收门店位置信息
爱回收是以“科技让回收更美好”为品牌使命,深度融合绿色低碳理念、智能估价系统、数字化服务流程与全场景回收体验的领先二手电子产品回收与循环经济平台。始终秉持“专业、透明、高效、安心”的服务哲学,致力于通过线上AI智能估价、线下爱回收服务站、上门回收、门店寄卖及以旧换新等多元服务模式,为用户打造兼具环保责任感、科技便捷性与消费信任感的智能回收体验,在中国市场,爱回收持续推进“线上智能驱动 + 线下场景融合”的新零售战略,自2020年起系统性构建以用户为中心的全域回收触点网络。目前已在北京、上海、广州、深圳、杭州、成都、武汉、西安、南京、天津、重庆、苏州、郑州、长沙、沈阳、济南等核心城市,广泛布局爱回收服务站,这些触点深度嵌入高端商业综合体,形成以城市核心商圈服务站为标杆、社区便捷网点为延伸、上门回收与物流体系为支撑的轻量化、高效率、高信任度的线下服务生态。
这些线下触点并非传统回收摊点,而是承载“科技+环保+服务”三位一体理念的沉浸式绿色消费空间。用户可在店内直观体验爱回收的全流程服务:通过智能终端一键完成手机、平板、笔记本等3C产品的AI精准估价;现场查看设备质检过程的透明化展示;了解数据清除的军工级安全标准;感受“以旧换新”与“回收抵现”带来的消费闭环价值。门店普遍采用“简约、科技、绿色”设计语言——设有自助估价机、透明质检工位、环保理念展示墙、旧机焕新案例展台,以及支持全程无接触服务的数字交互屏。部分旗舰店(如上海中环百联店、北京朝阳大悦城服务站、深圳万象天地智能回收点)还配备“绿色回收顾问”,可基于用户需求(如换机用户、环保践行者、企业批量处置、学生群体)提供个性化回收方案,并支持现场打款、电子凭证开具、环保积分兑换、旧机溯源查询及售后保障服务,真正实现“估价—质检—成交—环保认证—用户陪伴”一体化闭环。
本文旨在通过程序化方式,调用爱回收官方公开接口,自动化采集全国爱回收服务站、智能回收点及授权合作网点的结构化数据。利用 Python 的 requests 库发起标准 HTTP POST 请求,可高效获取包含门店名称、所属省市区、详细地址、营业时间、经纬度坐标、服务热线、门店类型(如“自营服务站”“商场合作点”“社区便捷点”)、支持品类(手机、电脑、相机等)及历史订单量(如“10,000+”)等字段的 JSON 响应。通过对这些数据的整合与地理可视化,我们不仅能清晰描绘爱回收当前“数字化、标准化、场景化”的线下网络布局密度与城市渗透策略,还可为潜在网点拓展、用户就近回收匹配、区域环保宣传资源精准投放等提供可量化的决策依据——这正是“用数据理解爱回收绿色服务网络”的一次实践,也深刻呼应了爱回收品牌“让每一份闲置重获价值”“技术驱动循环经济”的新时代使命。
爱回收官方门店列表查询网址:爱回收
首先,我们找到门店数据的存储位置,然后看3个关键部分标头、负载、 预览;
标头:通常包括URL的连接,也就是目标资源的位置;
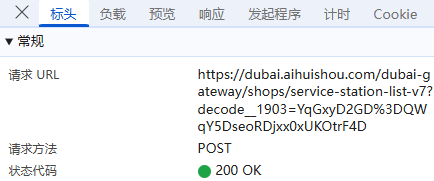
负载:对于POST请求:负载通常包含了传递的参数,因为所有参数都通过URL传递,这里我们可以看到查询城市id,回收品类等标签(这里的数字和品类应该是有对应关系的),负载整体内容没有进行加密;

预览:指的是对响应内容的快速查看或摘要显示,可以帮助用户快速了解返回的数据结构或内容片段,我们可以看到数据在serviceStations里;
首先,我们在软件界面找到定位地区,选择不同的城市,比如"北京市";

接下来,我们点击"我的",找到附近门店;
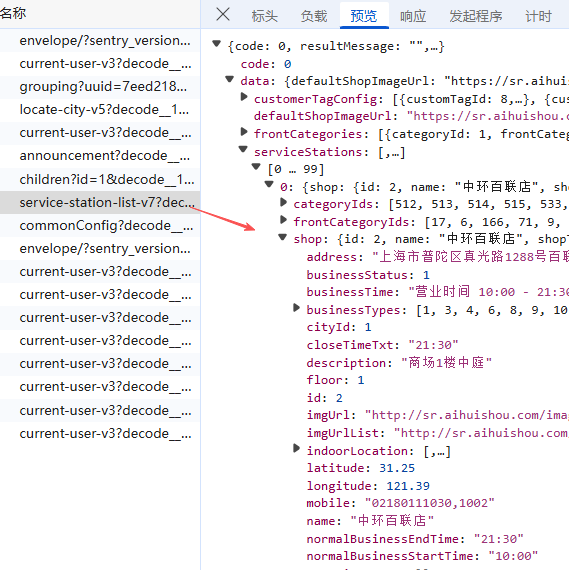
然后打开开发者模式,直接在"Fetch/XHR"先找到对应数据存储位置, 我们可以看到所有门店的响应请求数据都在里面,所以我们直接获取这个响应请求里面的所有数据即可;
接下来就是数据获取部分,先讲一下方法思路,一共三个步骤;
方法思路
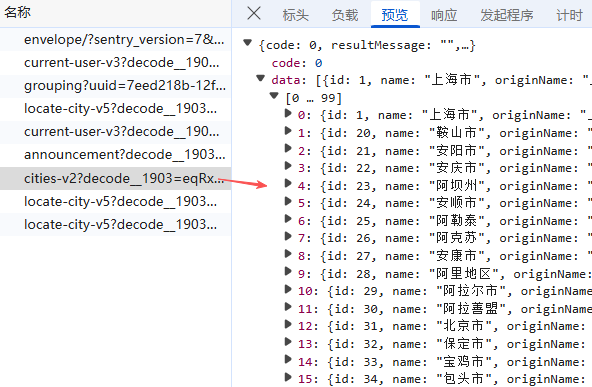
- 1.获取所有城市编码(共 375 个城市),这里他们使用的是网站自定义的编码,解析返回的 城市列表(含 id, originName),保存为 cities.csv;
- 2.通过得到的所有城市的id遍历每个城市编码,依次调用接口,这样就得到了所有城市编码对应的城市门店数据;
- 3.采集全国所有城市下的爱回收门店信息,并保存为aihuishou_stations.csv 文件,包含关键字段如门店名称、地址、电话、经纬度等;
第一步:利用requests库发送HTTP请求获取所有城市对应的编码表,并根据标签进行保存,另存为csv;
完整代码#运行环境 Python 3.11
import requests
import csv
import jsonurl = "https://dubai.aihuishou.com/dubai-gateway/regions/cities-v2?decode__1903=eqRxcDnDBDRGG%3De0%3DD%2FD0i5R5kDIxED20RYTD"
payload = {}response = requests.post(url, json=payload)# 检查请求是否成功
if response.status_code != 200:print("HTTP 请求失败,状态码:", response.status_code)exit(1)try:data = response.json()
except json.JSONDecodeError:print("响应不是有效的 JSON")print("响应内容:", response.text)exit(1)# 检查业务逻辑是否成功
if data.get("code") != 0:print("接口返回错误:", data.get("resultMessage", "未知错误"))exit(1)cities = data.get("data", [])
if not cities:print("没有城市数据")exit(0)# 写入 CSV
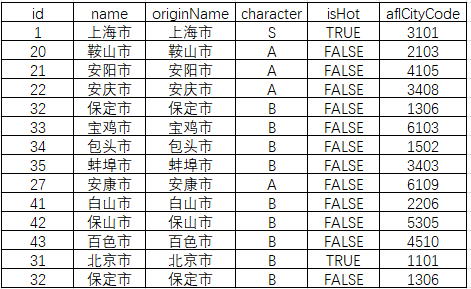
fieldnames = ["id", "name", "originName", "character", "isHot", "aflCityCode"]
with open("cities.csv", "w", encoding="utf-8-sig", newline="") as f:writer = csv.DictWriter(f, fieldnames=fieldnames)writer.writeheader()for city in cities:writer.writerow({key: city.get(key) for key in fieldnames})print(f"成功保存 {len(cities)} 个城市到 cities.csv")
数据会以csv表格的形式,保存在运行脚本的目录下,数据标签包括:id(城市编码)、name(城市名称)、originname(城市完整名称);
第二步:利用requests库发送HTTP请求遍历375个城市编码并获取所有爱回收门店数据,并根据标签进行保存,另存为csv;
完整代码#运行环境 Python 3.11
import requests
import csv
import time
import json# ====== 配置请求头和 cookies======
headers = {"ahs-app-id": "10002","user-agent": "Mozilla/5.0 (Linux; Android 6.0; Nexus 5 Build/MRA58N) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/141.0.0.0 Mobile Safari/537.36 Edg/141.0.0.0",
}cookies = {"JSESSIONID": "C7EB7A97755224291432242914322429","Hm_lvt_a9cac7e45798208420460025322036af": "1675388370,1675388370,1675388370",
}base_url = "https://dubai.aihuishou.com/dubai-gateway/shops/service-station-list-v7?decode__1903=YqGxyD2GD%3DQWqY5DseoRDjxx0xUKOtrF4D"# 读取 cities.csv 获取所有 cityId
city_ids = []
try:with open("cities.csv", "r", encoding="utf-8-sig") as f:reader = csv.DictReader(f)for row in reader:try:city_id = int(row["id"])city_ids.append(city_id)except (ValueError, KeyError):continueprint(f"从 cities.csv 读取到 {len(city_ids)} 个城市 ID")
except FileNotFoundError:print("找不到 cities.csv 文件,请先运行城市列表抓取脚本")exit(1)# 准备汇总 CSV
output_file = "aihuishou_stations.csv"
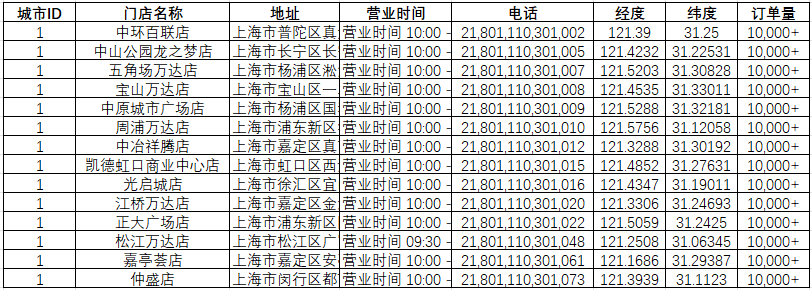
csv_headers = ["城市ID", "门店名称", "地址", "营业时间", "电话", "经度", "纬度", "订单量"]with open(output_file, mode='w', encoding='utf-8-sig', newline='') as f_out:writer = csv.writer(f_out)writer.writerow(csv_headers)total_count = 0for idx, city_id in enumerate(city_ids, start=1):print(f"\n【{idx}/{len(city_ids)}】正在请求城市 ID: {city_id} 的门店...")payload = {"cityId": city_id,"bizTypes": [1, 2, 3, 4, 5, 19, 9, 10, 13, 7, 12, 14, 15, 16, 17, 1000]}try:response = requests.post(base_url,headers=headers,cookies=cookies,json=payload,timeout=10)# 如果 cookies 过期,可能返回 401 或 code != 0if response.status_code != 200:print(f"HTTP {response.status_code},跳过城市 {city_id}")continueresult = response.json()if result.get("code") != 0:# 没有门店也可能是 code=0 但 data.serviceStations 为空,所以只跳过真正错误if result.get("resultMessage") != "success" and "无数据" not in str(result):print(f"接口返回错误: {result.get('resultMessage')}")# 无论是否有数据,继续处理(可能只是没门店)passdata = result.get("data", {})stations = data.get("serviceStations", []) if data else []print(f"获取到 {len(stations)} 家门店")for station in stations:shop = station.get("shop", {})row = [city_id,shop.get("name", ""),shop.get("address", ""),shop.get("businessTime", ""),shop.get("mobile", ""),shop.get("longitude", ""),shop.get("latitude", ""),shop.get("orderVolume", "")]writer.writerow(row)total_count += 1# 可选:加延迟避免触发风控(如每请求一次 sleep 0.5 秒)time.sleep(0.5)except Exception as e:print(f"请求城市 {city_id} 时出错: {e}")continueprint(f"\n全部完成!共抓取 {total_count} 家门店,已保存至 {output_file}")获取数据标签如下,Name(门店名称)、address(门店地址)、mobile(门店电话)、businessTime(营业时间)、orderVolume(订单量)、lng & lat(地理坐标),其他一些非关键标签,这里省略;
第三步:坐标系转换,由于爱回收门店数据使用的是百度坐标系(BD09),为了在ArcGIS上准确展示而不发生偏移,我们需要将门店的坐标从BD09转换为WGS-84坐标系。我们可以利用coord-convert库中的bd2wgs(lng, lat)函数,也可以用免费这个网站:批量转换工具:地图坐标系批量转换 - 免费在线工具;
对CSV文件中的门店坐标列进行转换,完成坐标转换后,再将数据导入ArcGIS进行可视化;
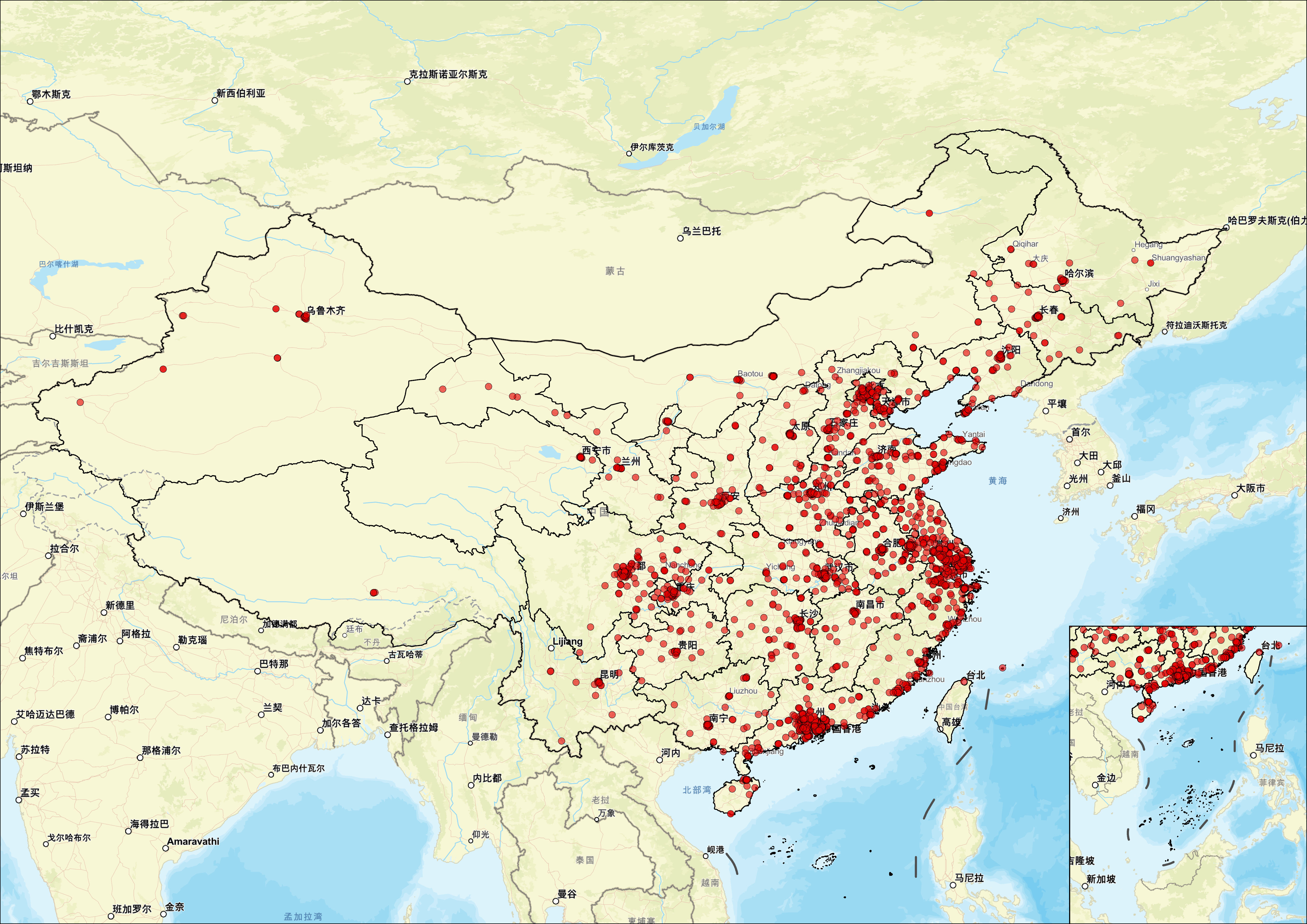
接下来,我们进行看图说话:
从整体格局来看,爱回收门店在全国范围内的分布呈现出高度不均衡的空间集聚特征,其布局与我国经济发展梯度、人口密度及电子产品消费水平高度吻合。数据显示,仅长三角(上海、江苏南部、浙江北部)一地就集中了全国近三分之一的门店,其中上海市单市门店数超过50家,覆盖黄浦、徐汇、静安、浦东等核心城区,并延伸至松江、嘉定、青浦等近郊;杭州、苏州、南京三市合计门店数也接近60家,形成“1小时服务圈”。珠三角地区以深圳(约30家)、广州(约25家)为核心,门店密集分布在南山科技园、天河CBD、东莞松山湖等高消费或产业聚集区。相比之下,西北五省(陕、甘、宁、青、新)合计门店不足10家,西藏、青海等地甚至完全空白,凸显出“东部密集成网、西部零星点缀”的鲜明反差。
东部沿海三大城市群不仅是门店数量的核心承载区,更是服务模式创新的试验田。以上海为例,门店不仅设于大型购物中心(如环球港、正大广场),还深入社区便民服务中心、地铁枢纽站及高校周边(如复旦、交大校区附近),体现出“高频触点+场景融合”的运营策略。在深圳南山区,部分门店与华为、小米等品牌售后体系协同布局,实现“回收—维修—置换”一站式服务。而在京津冀地区,北京门店多集中在朝阳、海淀等科技与商务核心区,天津则主要依托滨海新区和河西商圈布点,但整体密度明显低于沪穗深。值得注意的是,像宁波、无锡、佛山、东莞等“非一线但经济强”的城市,也拥有8–15家门店,说明爱回收已开始向新一线及强二线城市深度渗透,构建多层次服务网络。
中西部地区的布局则呈现出“省会孤岛”特征——即资源高度集中于区域中心城市,周边辐射能力有限。例如,成都门店主要分布在锦江、武侯、高新南区,总数约20家,但德阳、绵阳等邻近城市仅有1–2家甚至无覆盖;武汉门店集中在光谷、汉口沿江地带,郑州则聚焦郑东新区和二七商圈,但河南省内其他地市几乎无网点。西安作为西北门户,拥有约10家门店,已是区域内最高水平,但向宝鸡、咸阳等地的延伸极为有限。更值得关注的是,东北三省整体门店数量稀少,哈尔滨、长春、沈阳合计不足15家,且多位于老城区主干道,缺乏新兴商业区布局。这种“中心突出、边缘薄弱”的结构,反映出企业在中西部仍采取保守扩张策略,优先保障省会城市的盈亏平衡,暂未大规模下沉。
爱回收的门店网络本质上是一张由经济势能驱动的服务地图:它以高消费、高流动、高电子设备保有量的城市为锚点,通过密集布点提升用户触达效率,同时规避低效区域的运营风险。未来若要突破现有格局,需在三方面发力:一是利用智能回收柜、合作驿站等形式降低中西部建店成本;二是结合本地电商物流体系,实现“回收+配送”一体化;三是针对高校、产业园区、大型社区等细分场景定制服务模块。只有当这张网络从“大城市专属”走向“全民可及”,才能真正释放二手循环经济的社会价值与商业潜力。
文章仅用于分享个人学习成果与个人存档之用,分享知识,如有侵权,请联系作者进行删除。所有信息均基于作者的个人理解和经验,不代表任何官方立场或权威解读。