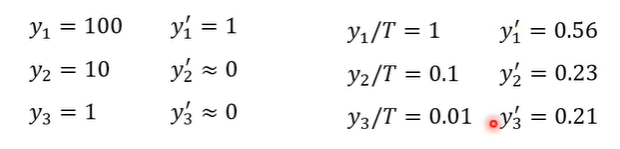李宏毅机器学习笔记39
目录
摘要
1.network pruning
2.knowledge distillation
摘要
本篇文章继续学习李宏毅老师2025春季机器学习课程,学习内容是network compression的两个方法,分别是network pruning和knowledge distillation
很多时候,模型的使用是受到环境的资源限制的,例如在智能手表上等,如果模型过大,可能无法在手表上运行。network compression就是将模型简化,减少参数但是效果与原来差不多。

1.network pruning
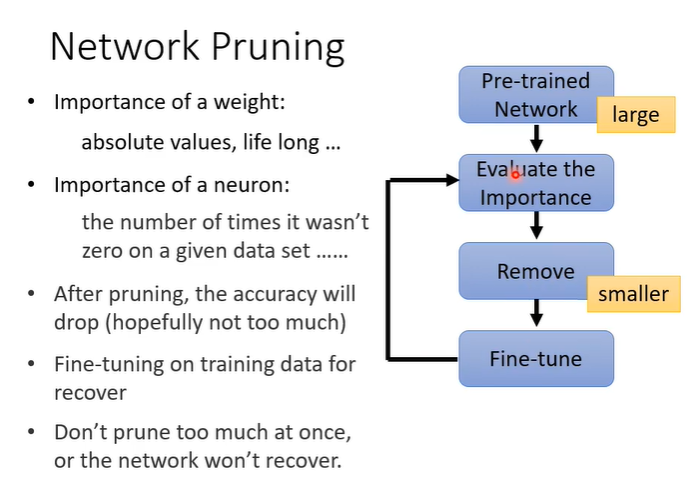
顾名思义就是,把network中一些参数剪掉,network pruning的想法就是把模型中没有用的参数找出来去掉。架构如下,首先训练一个大的network,再去评估network中每个参数或neuron的重要性。评估方法可以看参数绝对值,绝对值越大可能影响越大或者是计算神经元输出不为0的次数等。然后就可以把不重要的参数或neuron去掉得到一个较小的network。通常去掉参数之后模型正确率会低一点,我们需要重新微调参数,重新训练一下较小的network。去掉参数的过程可以反复进行。
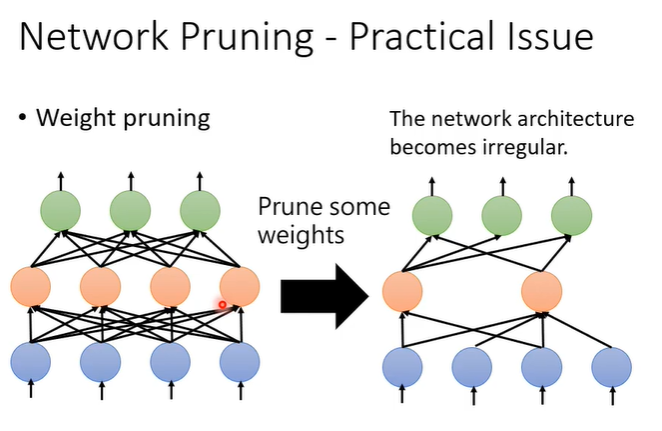
假设去掉参数,我们得到的network的形状可能是不规则的,这样的问题就实现麻烦,因为形状不固定输入输出存在不同,且不好用GPU加速。
下图是实际实验数据纵轴是去除参数占比,大部分参数都被去掉了(紫色线段接近1),但实际上并未加速多少,柱状图仅有少量大于1,大部分情况下都是变慢。

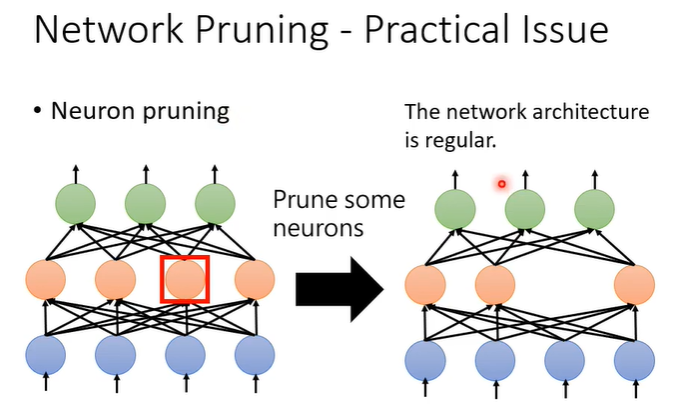
假设以神经元为单位,丢掉一些神经元后,network的架构仍然是规则的,这样便于实作也便于加速。
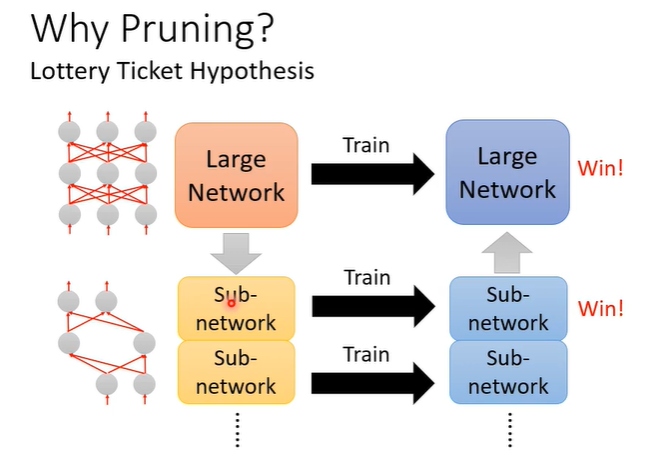
还有一个问题是为什么要这样做?如果先训练一个大的network再把他变小和一个小的network效果差不多,那为什么不直接训练一个小的network呢?普遍的答案是大的network比较好训练,直接训练小的network往往没有这么高的正确率。
有一个大乐透假说用于解释为什么大的network比较好训练。训练是看运气的,每次训练的结果都不一定一样,抽到一组好的参数就得到好结果,抽到坏的参数就得到坏结果,乐透也是一个看运气的游戏,要在乐透里得到较高的中奖率就是买较多彩券。那么对于一个大的network来说也是一样,大的network视为是很多小的sub-network的组合,每一个小的不一定可以成功训练出来,但是众多的sub-network中只要有一个成功训练出来,大的network就成功了。
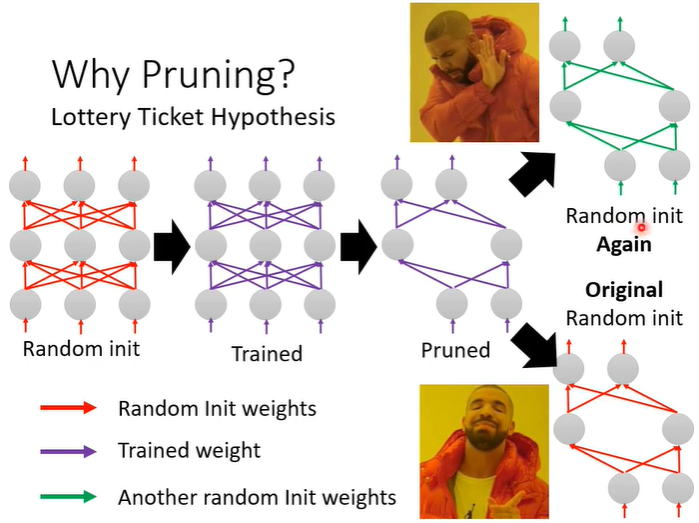
有一个实验证明了大乐透假说,一个红色的随机初始参数的模型,训练之后得到紫色的模型,再用network pruning技术丢掉一些参数得到一个小的network。接下来把小的network仅仅重新随机参数训练(绿色线段),会发现训练不起来,但是如果小的network用原本大的随机初始参数(红色线段)就可以训练起来。红色的参数就相当于抽到的好的参数。
2.knowledge distillation
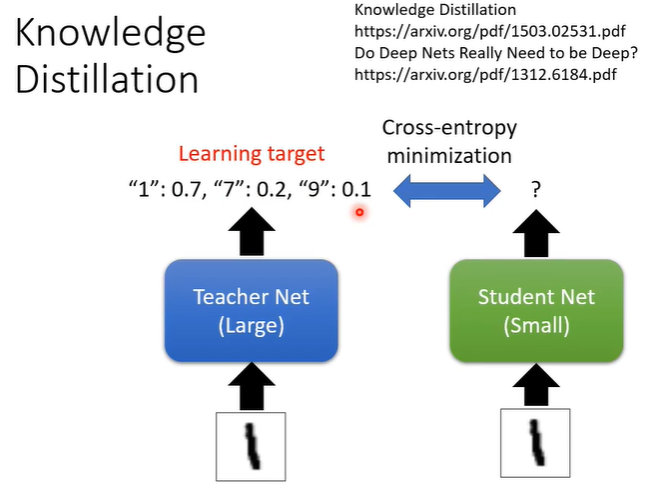
knowledge distillation的概念是先训练一个大的network,当作teacher network,真正想要的小的network叫做student network,student network是根据teacher network来学习的。假设要做数字辨识,学习的方法是把训练资料都给teacher network,输入图片,输出分布,然后给student network一模一样的图片输入,但是学生不上看正确答案来学习,而是把老师的输出当正确答案,即输出要尽可能接近teacher network输出的分布。
knowledge distillation有一个小技巧,就是稍微更改softmax function。简单复习一下softmax,softmax就是把每个neuron的输出取exponential(取指数)然后再进行normalize(标准化)得到最终network的输出,让network的输出变为几率分布。
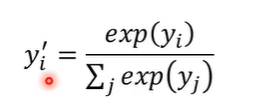
knowledge distillation的改变就是给softmax增加temperature,实际上就是在exponential之前,每个数值都除T,T是一个需要调整的参数。除T(假设T>1)的作用是把比较集中的分布变得平滑一些。
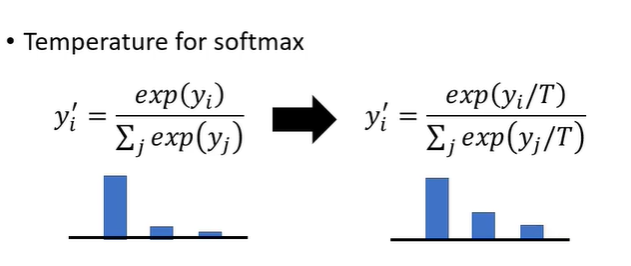
为什么需要更平滑呢?假设y1,y2,y3分别是100,10,1就会发现softmax的结果是接近1,0,0,这样给student network学习就跟与正确答案学习没有差别。跟teacher network学习的好处是,会得到额外的资讯,老师会告诉你哪些类别是比较相似的。假设T是100,softmax处理后输出就会变为0.56,0.23,0.21分类的结果不会变但是分数变平滑了。