不只是计算:昇腾算子开发中的内存管理艺术

在AI性能优化的世界里,我们常常将目光聚焦于FLOPs(每秒浮点运算次数),仿佛更高的算力就等同于更强的性能。这固然没错,计算核心(如昇腾AI处理器的Cube-Unit和Vector-Unit)是引擎,决定了理论性能的上限。然而,在我的昇腾算子开发实践中,我越来越深刻地认识到:决定实际性能下限的,往往不是计算本身,而是内存。
如果说计算单元是一位手速惊人的顶级大厨,那么内存系统就是整个厨房的配菜、传菜体系。大厨炒菜再快,如果食材(数据)迟迟送不到手边,或者炒好的菜(中间结果)没地方放,整个餐厅的效率依然会惨不忍睹。因此,高效的算子开发,本质上是一场关于计算与内存协同的艺术。
一、 内存层级:我们战斗的沙盘
在挥洒这门艺术之前,必须先了解我们的“沙盘”——昇腾AI处理器的内存层级结构。它通常是一个金字塔结构,从上到下,容量变大,速度变慢:
- 片上内存 (On-chip Buffer/Unified Buffer): 这是金字塔的顶端,紧邻计算单元。容量最小(通常为KB到MB级别),但访问速度极快,延迟极低。它是我们进行高性能计算的“主战场”。
- L2 Cache: 作为片上内存和全局内存的缓冲层,它的存在是为了缓解两者之间的速度鸿沟。
- 全局内存 (Global Memory/DDR): 这是金字塔的底座,容量最大(GB级别),但访问速度最慢。我们通常说的数据和模型参数,都存放在这里。
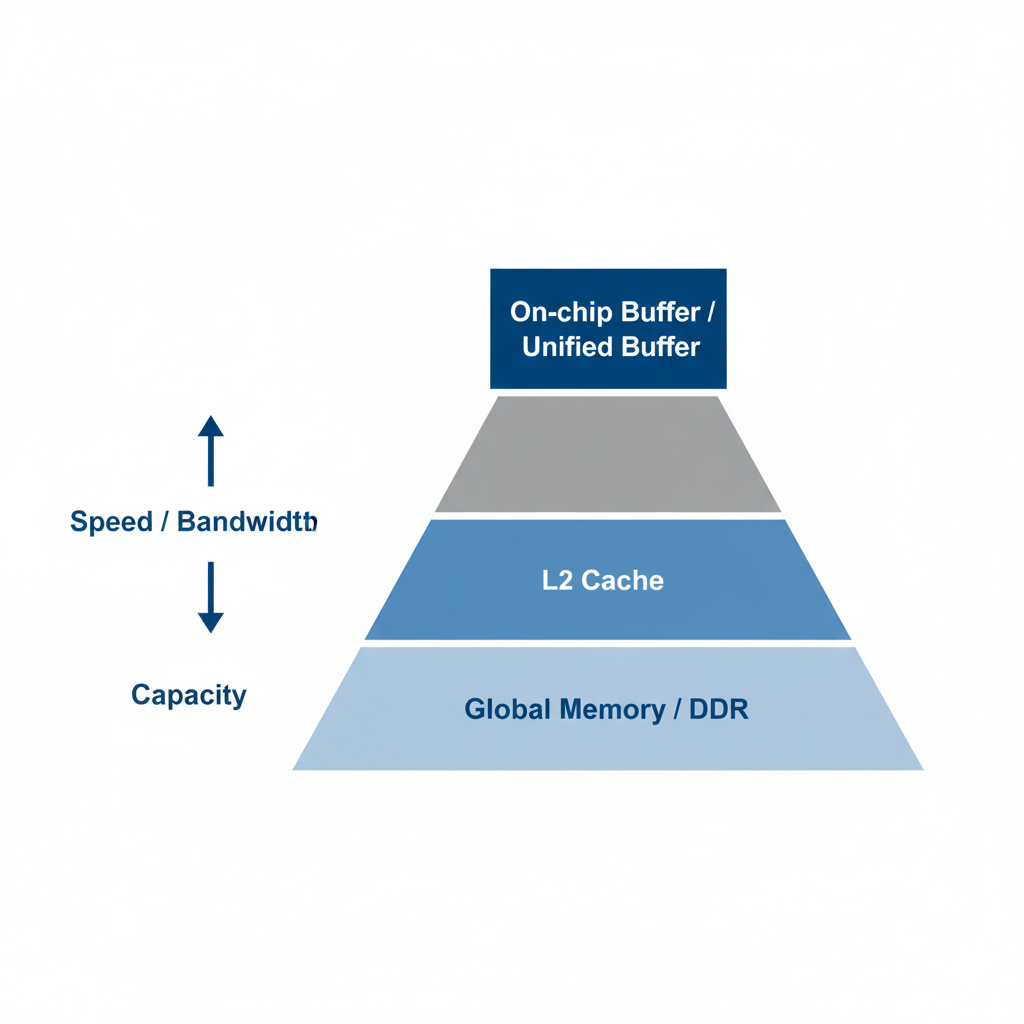
性能优化的核心矛盾,就在于 “计算发生在最快的片上内存,而数据却存储在最慢的全局内存”。我们所有的内存管理艺术,都围绕着如何高效地解决这个矛盾展开。
二、 内存管理的艺术之一:Tiling - 化整为零的智慧
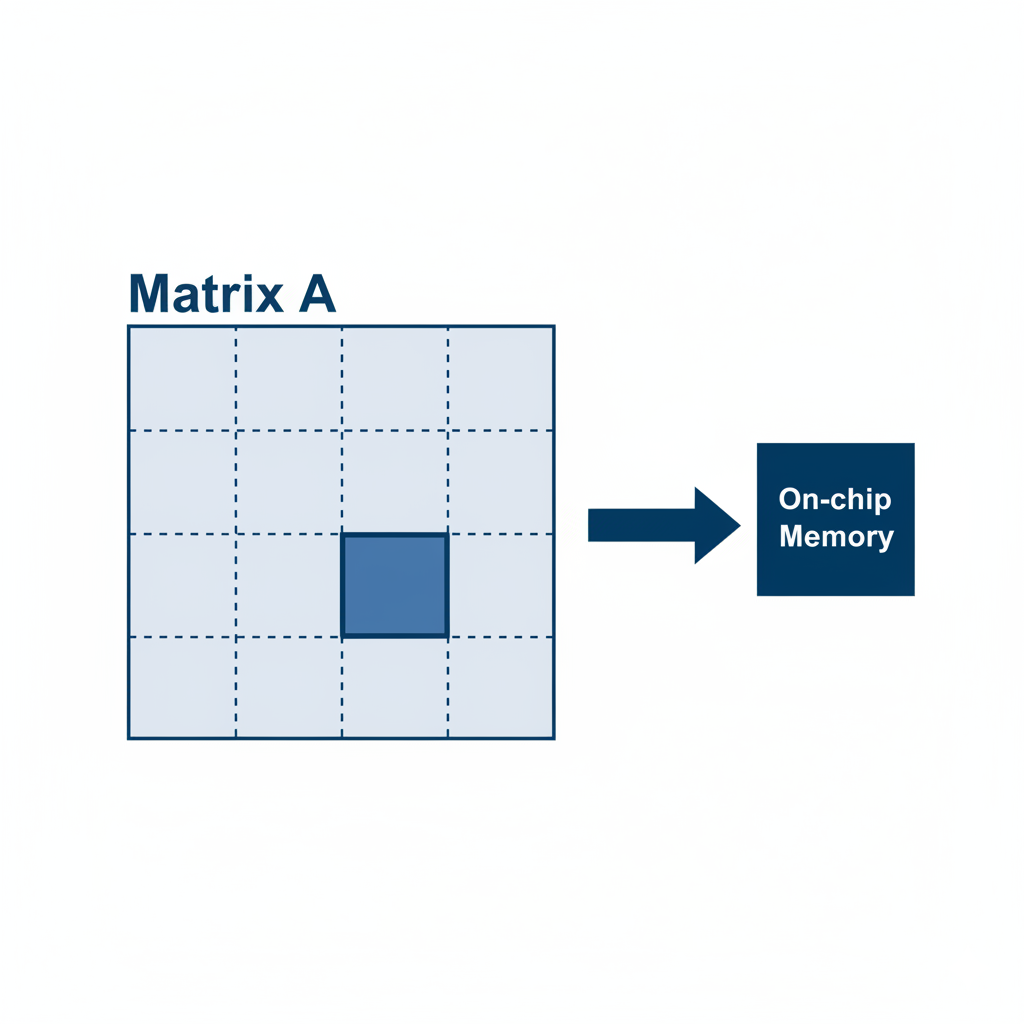
一个巨大的张量(比如一张高清图片或一个大矩阵)不可能一次性全部装入有限的片上内存。最经典的技术就是Tiling(分块/分片)。
我们将大任务分解成若干个可以在片上内存处理的小数据块(Tile),然后分批次地进行“搬运 -> 计算 -> 写回”的循环。
想象一下:
- 搬运: 使用DMA(直接内存访问)控制器,将一个数据块从DDR搬到片上内存。
- 计算: 计算单元对这个数据块进行处理。
- 写回: 将计算结果从片上内存搬回DDR。
Tiling的艺术在于如何切分数据块。块太大,片上内存装不下;块太小,数据搬运的次数过多,DMA启动开销和DDR的带宽可能成为新的瓶颈。找到那个“黄金尺寸”的Tile Size,是每个性能工程师的必修课。
三、 内存管理的艺术之二:Double Buffering - 让等待成为过去
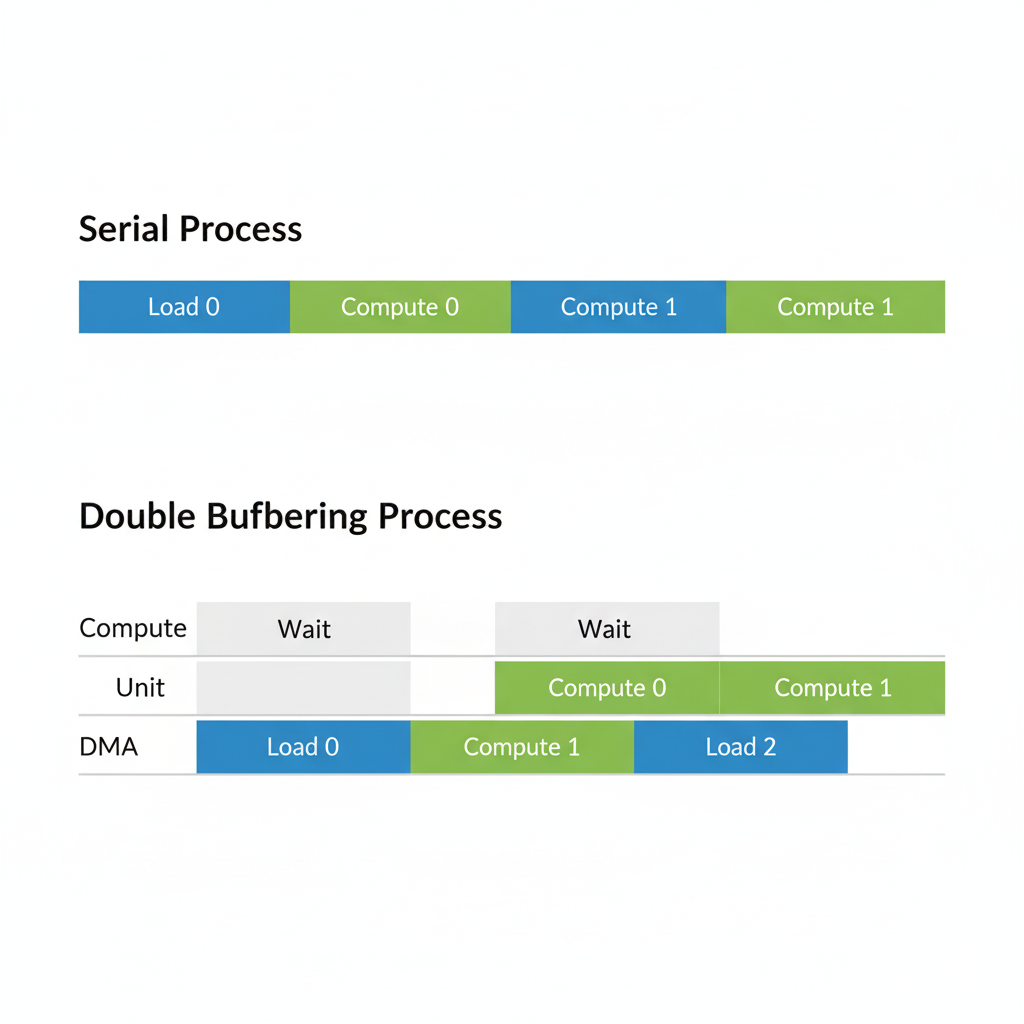
即使有了Tiling,一个朴素的流程依然是串行的:搬运 -> 计算 -> 搬运 -> 计算...。这意味着当DMA在搬运数据时,宝贵的计算单元在“发呆”;而当计算单元在工作时,DMA又在“围观”。
Double Buffering(双缓冲)就是为了打破这种尴尬。我们在片上内存开辟两块缓冲区(Buffer A和Buffer B)。
- DMA将第一个数据块
Tile_0搬入Buffer A。 - DMA开始搬运
Tile_1到Buffer B的同时,计算单元开始处理Buffer A中的Tile_0。 - 当计算单元处理完
Tile_0,DMA也恰好搬完了Tile_1。计算单元立即开始处理Buffer B中的Tile_1,同时,DMA开始向Buffer A(此时已空闲)搬运下一个数据块Tile_2。
如此循环往复,计算和数据搬运实现了流水线式的并行,从而将数据搬运的延迟完美地“隐藏”在了计算时间之中。
四、 内存管理的艺术之三:数据重排与复用 - 榨干每一比特带宽
- 数据重排 (Data Re-layout): 有时候,数据在DDR中的存储格式(如NCHW)并不完全适合计算单元的胃口。在将数据从DDR搬入片上内存的过程中,我们可以“顺便”将其重排成更利于计算的格式(如分形格式 FRACTAL),最大化计算效率。这是一种用搬运的代价换取更高计算性能的权衡。
- 内存复用 (Memory Reuse): 在复杂的算子中,会产生许多中间结果。如果每一步都将中间结果写回DDR再读回来,无疑是巨大的浪费。优秀的算子设计会尽可能让数据“驻留”在片上内存,一个计算步骤的输出,直接作为下一个计算步骤的输入,形成一条高效的“片上流水线”。这正是**算子融合(Operator Fusion)**在内存层面的核心价值。
结语:从工程师到艺术家
在昇腾CANN的算子开发中,我们不仅仅是代码的编写者。我们更像是舞台的调度师,精心安排着数据在不同层级内存间的每一次流动,确保计算单元这位“主角”永远不会空等。
从理解内存层级,到运用Tiling、Double Buffering,再到精妙的数据复用与融合,每一步都体现着对硬件的深刻理解和对性能的极致追求。这不再是简单的工程任务,而是一门权衡与优化的艺术。当我们开发的算子,能够在硬件上以接近理论峰值的性能飞驰时,那种成就感,正是这门艺术带给我们的最大回馈。