大模型应用02 || 检索增强生成Retrieval-Augmented Generation || RAG概念、应用以及现有挑战
1. RAG的概念
RAG,全称检索增强生成(Retrieval-Augmented Generation),是一种将信息检索(Retrieval)系统与生成式(Generation)模型相结合的技术框架。其核心思路是:在大型语言模型(LLM)生成回答之前,先从一个指定的外部知识库(如内部文档、实时新闻数据库)中检索出与用户问题相关的上下文信息,然后将这些信息与原始问题一同提供给LLM,引导其生成更可靠、更具事实性的回答。
RAG的实现流程通常分为两个阶段:
- 数据准备(离线阶段):此阶段旨在建立一个可供检索的知识库。首先,对原始文档进行加载和清洗,然后将其切割成较小的、语义完整的文本块(Chunks)。接着,使用一个嵌入模型(Embedding Model)将每个文本块转换为一个能够代表其语义的数学向量。最后,将这些向量及其对应的原文内容存入一个向量数据库中。
- 检索与生成(在线阶段):当用户输入问题后,系统使用与准备阶段相同的嵌入模型将问题也转换为一个向量。然后,在向量数据库中进行相似度搜索,找出与问题最相关的文本块。这些文本块将作为上下文,与用户的原始问题组合成一个增强的提示词(Augmented Prompt),并最终交由LLM生成答案。
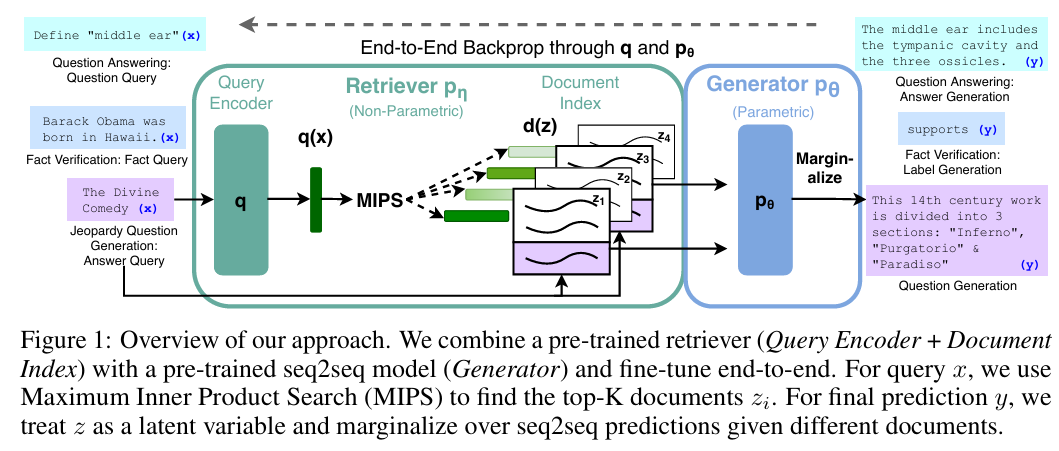
RAG的概念由Meta AI的研究人员在2020年的论文中正式提出:“Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks” (by Patrick Lewis, et al.)。
2. RAG目前的应用
RAG旨在解决大型语言模型固有的三大核心缺陷:
- 知识静态性:LLM的知识被“冻结”在其训练数据截止的日期,无法获知此后的新信息。
- 幻觉:当模型对其知识不确定时,它可能会编造看似合理但实际上是错误的答案。
- 缺乏透明度和可信度:对于LLM给出的答案,我们无从知晓其信息来源,难以进行事实核查。
典型应用场景:
-
企业级知识库问答系统:
- 场景描述:一家公司希望构建一个内部AI助手,能回答员工关于公司规章制度、产品技术文档、法律合规文件等问题。
- 扮演角色:RAG框架将公司的内部文档库作为其外部知识源。当员工提问时,RAG首先从文档中精确检索到相关的条款或段落,然后将其作为上下文交给LLM,生成基于公司内部资料的准确回答。这既保证了信息的私密性(无需用私有数据重新训练模型),又确保了答案的权威性。
-
需要实时信息的问答机器人:
- 场景描述:用户向一个AI助手提问:“昨晚的欧冠比赛结果是什么?”或“最近发布的AI模型有哪些新进展?”
- 扮演角色:由于这些信息发生在LLM训练完成之后,模型本身无法回答。RAG系统可以先通过搜索引擎或接入实时更新的新闻数据库,检索到最新的比赛结果或新闻报道,然后将这些实时信息提供给LLM,让其总结并回答用户。
3. RAG实现过程
RAG的核心流程分为两个阶段:索引(Indexing)和检索与生成(Retrieval & Generation)。
核心实现步骤:
-
数据准备与索引(离线构建):
- 加载与切分 (Load & Split):将原始文档(如PDF、TXT、HTML文件)加载进来,并将其切割成较小的、语义完整的文本块(Chunks)。切分是为了提高检索的精确度,并适配LLM的上下文窗口限制。
- 向量化 (Embedding):使用一个预训练的文本嵌入模型,将每个文本块转换成一个高维的数学向量(Vector)。这些向量能够捕捉文本的语义信息。
- 存入向量数据库 (Store):将所有文本块的向量及其对应的原始文本内容,存储到一个专门用于高效相似度搜索的向量数据库(Vector Database)中,如FAISS、ChromaDB或Pinecone。
-
检索与生成(在线查询):
- 用户提问 (Query):用户输入一个问题。
- 查询向量化:使用与索引阶段相同的嵌入模型,将用户的问题也转换成一个向量。
- 相似度搜索 (Search):在向量数据库中,计算用户问题向量与所有文本块向量之间的相似度(通常使用余弦相似度),并找出最相似的Top-K个文本块。这些文本块就是与问题最相关的“上下文”。
- 增强提示词 (Augmented Prompt):将检索到的Top-K个文本块与用户的原始问题,按照一个预设的模板组合成一个新的提示词(Prompt)。例如:“请根据以下上下文信息回答问题。上下文:[检索到的文本块1] [检索到的文本块2]… 问题:[用户的原始问题]”。
- 生成答案 (Generate):将这个增强后的提示词送入LLM,LLM会基于提供的上下文信息来生成最终的回答。
4. RAG为什么有效
RAG的有效性主要源于两个核心原理:职责分离和上下文学习能力。
- 职责分离:
RAG将LLM的职责进行了划分。它让LLM专注于其最擅长的部分:语言理解、推理和内容组织。而将知识存储和更新这一任务,交给了外部的、可随时更新的向量数据库。这种架构就像是为LLM配备了一个可动态扩展的“长期记忆”,相比于通过昂贵的微调或重新训练来向模型灌输新知识,这种方式要高效和经济得多。 - 利用上下文学习(In-Context Learning)能力:
大型语言模型非常擅长理解和利用在提示词中提供给它的信息。RAG正是利用了这一强大能力。它不改变模型本身的任何参数,而是通过在提示词中动态地“喂”给模型与问题最相关的背景知识,来引导模型在有事实依据的轨道上进行回答,从而显著降低幻觉,提升答案的可靠性。
5. 现有挑战和解决方案
尽管RAG的理论简单,但在实际应用中,从数据处理到系统评估的每个环节都存在挑战。
主要挑战与解决方案:
-
数据处理的复杂性:
- 挑战:原始文档格式多样,如PDF中的表格、图片难以直接提取;简单的固定长度切分会破坏文本的语义完整性。
- 解决方案:
- 智能解析:使用专门的文档解析库或小型视觉模型来识别和提取表格、图片等复杂元素。
- 语义切分:采用基于文档结构(如标题、段落)的切分策略,或利用语言模型分析语义边界,确保切分后的文本块是完整和独立的。
- 元数据标注:在切分的同时,为每个文本块附上来源、时间等元数据标签,便于后续的管理和过滤。
- **利用LLM来切:**参考自用提示词02 || Prompt Engineering || RAG数据切分 || 作用:通过LLM将文档切分成chunks-CSDN博客
-
检索的精准度问题:
- 挑战:用户问题模糊、知识库中无答案、或检索到的文档相关但不够精准。
- 解决方案:
- 查询重写 (Query Rewriting):在检索前,先利用LLM将模糊的用户问题改写得更具体,或分解为多个子问题分别检索。
- 混合搜索 (Hybrid Search):将向量的语义搜索与传统关键词搜索(如BM25)相结合,兼顾语义相关性和关键词的精确匹配。
- 重排 (Re-ranking):采用两阶段检索。先通过快速的检索方法召回一个较大的候选集(如Top-20),再使用一个更精密的重排模型(如Cross-Encoder)对候选集进行二次排序,筛选出最相关的Top-K个文档送入LLM。
-
系统评估的困难:
- 挑战:许多业务问题没有唯一的标准答案,且内部对“好答案”的定义可能存在主观差异,导致难以科学地衡量系统优化的效果。
- 解决方案:
- 建立评估体系:构建一套半自动化的评估流程。首先,由领域专家构建一个包含标准问答对的“黄金测试集”。然后,利用先进的LLM(如GPT-4)作为评估器,从忠实度(Faithfulness,答案是否忠于原文)、相关性(Relevance)等多个维度对系统输出进行打分。开源框架(如RAGAs, ARES)可支持此类评估,从而为系统迭代提供数据支持。
6. 参考资料
- Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks (The original RAG paper)
- LangChain - Question Answering over Documents
- Self-RAG: Learning to Retrieve, Generate, and Critique through Self-Reflection
- HyDE: Precise Zero-Shot Dense Retrieval without Relevance Labels
7. RAG代码实现
0. 代码实现
以下代码使用 langchain 库,结合 OpenAI 的模型和 Chroma 向量数据库,演示了一个完整的、最小化的RAG流程。
前置准备:
你需要先安装必要的库并设置你的OpenAI API密钥。
pip install langchain openai chromadb tiktoken
export OPENAI_API_KEY="your_openai_api_key_here"
# rag_implementation.pyimport os
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain.embeddings import OpenAIEmbeddings
from langchain.vectorstores import Chroma
from langchain.chains import RetrievalQA
from langchain.chat_models import ChatOpenAI# --- 1. 准备数据和知识库 ---# 模拟一些内部文档作为知识库
documents = ["RAG, 全称检索增强生成, 是一种结合了检索和生成模型的技术。","RAG的核心思想是在生成回答前,先从外部知识库中检索相关信息。","实现RAG的第一步是建立索引:将文档切片、向量化并存入向量数据库。","向量数据库Chroma是一个开源的、用于存储和检索向量的工具。","LangChain是一个用于构建基于LLM应用的框架,它极大地简化了RAG的实现。","在RAG流程中,用户问题也会被向量化,用于在向量数据库中进行相似度搜索。","检索到的信息会和原始问题一起,构成一个增强的提示词(Augmented Prompt)。",
]# --- 2. 索引阶段 (Indexing) ---# a. 文档切分 (Split)
# RecursiveCharacterTextSplitter 会尝试按段落、句子、词语等递归地切分文本
text_splitter = RecursiveCharacterTextSplitter(chunk_size=100, # 每个块的最大字符数chunk_overlap=20, # 块之间的重叠字符数
)
doc_chunks = text_splitter.create_documents(documents)print(f"文档被切分成了 {len(doc_chunks)} 个块。")
# print(doc_chunks[0]) # 查看第一个块的内容# b. 向量化与存储 (Embed & Store)
# 使用 OpenAI 的 embedding 模型
embeddings = OpenAIEmbeddings()# 使用 Chroma 向量数据库,将文档块和它们的向量存储在内存中
# from_documents 会自动处理向量化和存储过程
vector_store = Chroma.from_documents(documents=doc_chunks, embedding=embeddings
)print("索引构建完成,文档已存入Chroma向量数据库。")
print("-" * 30)# --- 3. 检索与生成阶段 (Retrieval & Generation) ---# a. 创建一个RAG链 (Chain)
# RetrievalQA 是一个封装了完整RAG流程的链
# llm: 指定用于生成答案的语言模型
# chain_type="stuff": 最简单的模式,将所有检索到的文档块“塞”进一个提示词
# retriever: 指定用于检索的检索器,这里直接从向量数据库创建
llm = ChatOpenAI(model_name="gpt-3.5-turbo", temperature=0)
qa_chain = RetrievalQA.from_chain_type(llm=llm,chain_type="stuff",retriever=vector_store.as_retriever()
)# b. 提问
query1 = "RAG是什么?"
print(f"问题: {query1}")
response1 = qa_chain.run(query1)
print(f"回答: {response1}")
print("-" * 30)query2 = "实现RAG需要哪些步骤?"
print(f"问题: {query2}")
response2 = qa_chain.run(query2)
print(f"回答: {response2}")
print("-" * 30)query3 = "LangChain在这个过程中扮演什么角色?"
print(f"问题: {query3}")
response3 = qa_chain.run(query3)
print(f"回答: {response3}")
print("-" * 30)1. 核心设计
该代码实现了一个端到端的RAG问答系统。其核心设计遵循了RAG的经典两阶段流程:
- 索引 (Indexing):一次性地处理和存储知识库文档,以便后续快速检索。这个过程是离线的。
- 查询 (Querying):当用户提问时,实时地执行检索、构建提示词和生成答案。这个过程是在线的。
langchain 框架将这个复杂的流程抽象成了几个可组合的模块,极大地降低了开发门槛。
2. 关键组件解析
2.1 RecursiveCharacterTextSplitter:文档切分器
- 职责:将长文档切分成适合LLM上下文窗口和精确检索的小块(Chunks)。
- 为什么需要它:
- 上下文窗口限制:LLM无法一次性处理无限长的文本。
- 检索精度:在一个巨大的文档中进行搜索,不如在多个语义集中的小块中搜索来得精确。返回整个大文档会引入大量噪声。
- 工作方式:它会按顺序尝试用不同的分隔符(如
\n\n,\n,
2.2 OpenAIEmbeddings:嵌入模型
- 职责:将文本(无论是文档块还是用户问题)转换为一个固定维度的浮点数向量。
- 工作方式:它背后调用了OpenAI的
text-embedding系列模型。这个模型经过训练,能够将语义上相似的文本映射到向量空间中相近的位置。这是实现“语义搜索”而非“关键词搜索”的关键。
2.3 Chroma:向量数据库
- 职责:高效地存储大量的文本向量,并提供快速的相似度搜索功能。
- 工作方式:当你提供一个查询向量时,它会计算该向量与数据库中所有存储向量的余弦相似度(或其他距离度量),并返回最相似的K个向量及其关联的原始文本块。它扮演了RAG系统中“外部大脑”或“长期记忆”的角色。
2.4 RetrievalQA:RAG执行链
- 职责:作为整个在线查询流程的“总指挥”,它自动完成了以下所有步骤:
- 接收用户问题。
- 调用
retriever(内部使用vector_store和embeddings)将问题向量化并执行检索,获取相关文档块。 - 将检索到的文档块和问题填入一个预设的提示词模板中。
- 调用
llm(语言模型)来执行这个增强后的提示词。 - 返回LLM的最终输出。
3. RAG中的提示词工程解析
RetrievalQA链的背后,是一个精心设计的提示词模板。虽然在代码中被隐藏了,但其stuff模式下的默认模板大致如下:
Use the following pieces of context to answer the question at the end. If you don't know the answer, just say that you don't know, don't try to make up an answer.{context}Question: {question}
Helpful Answer:
{context}:这是一个占位符,langchain会自动将从向量数据库中检索到的所有文档块内容填充到这里。{question}:这是另一个占位符,用于填充用户的原始问题。
这个模板的设计体现了RAG的核心思想:
- 明确指令:
Use the following pieces of context...直接命令模型必须基于提供的上下文来回答。 - 抑制幻觉:
If you don't know the answer, just say that you don't know...提供了“退路”,鼓励模型在上下文不足时承认不知道,而不是胡乱编造。 - 结构化输入:将上下文和问题清晰地分开,帮助模型更好地理解任务。