Dropout提升模型泛化能力【动手学深度学习:PyTorch版 4.6 暂退法】
双隐藏层,每个包含256个隐藏单元
num_inputs, num_outputs, num_hiddens1, num_hiddens2 = 784, 10, 256, 256dropout1, dropout2 = 0.2, 0.5net = nn.Sequential(nn.Flatten(),nn.Linear(784, 256),nn.ReLU(),nn.Dropout(dropout1),nn.Linear(256, 256),nn.ReLU(),nn.Dropout(dropout2),nn.Linear(256, 10))def init_weights(m):if type(m) == nn.Linear:nn.init.normal_(m.weight, std=0.01)net.apply(init_weights);对模型进行训练和测试
trainer = torch.optim.SGD(net.parameters(), lr=lr)
d2l.train_ch3(net, train_iter, test_iter, loss, num_epochs, trainer)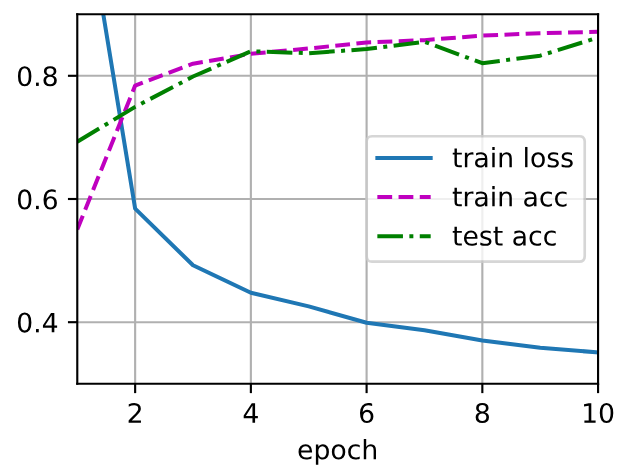
单隐藏层 包含256个隐藏单元,并使用了ReLU激活函数
net = nn.Sequential(nn.Flatten(),nn.Linear(784, 256),nn.ReLU(),nn.Linear(256, 10))def init_weights(m):if type(m) == nn.Linear:nn.init.normal_(m.weight, std=0.01)net.apply(init_weights);训练过程
batch_size, lr, num_epochs = 256, 0.1, 10
loss = nn.CrossEntropyLoss(reduction='none')
trainer = torch.optim.SGD(net.parameters(), lr=lr)train_iter, test_iter = d2l.load_data_fashion_mnist(batch_size)
d2l.train_ch3(net, train_iter, test_iter, loss, num_epochs, trainer)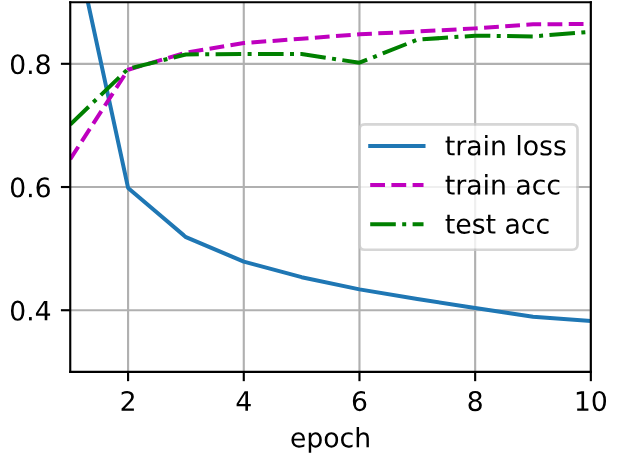
根据结果可以发现:有dorpout的训练精度和测试精度都和没有dorpout的训练精度和测试精度前后基本一样,而且训练精度和测试精度也都基本一致,但dorpout导致训练的损失函数值更小有何好处?
当使用Dropout后,训练精度和测试精度与没有使用Dropout时基本一致,且训练和测试精度本身也相近,但训练损失函数值更小,这实际上是一个很好的迹象。下面详细解释这种情况的好处,并帮助大家理解为什么损失值的变化比精度值更能反映模型的学习质量。
首先,理解精度和损失的区别
精度(Accuracy):这是一个分类指标,只关心模型预测的类别是否正确。例如,在二分类中,如果预测概率大于0.5就判为正类,否则为负类。精度只计算正确预测的比例,但它不关心模型预测的“置信度”。
损失(Loss):通常是一个连续值(如交叉熵损失),它衡量模型预测的概率分布与真实标签之间的差异。损失值反映了模型预测的置信度——如果模型对正确类别的预测概率很高(接近1),损失就会很低;如果预测概率勉强超过0.5,损失就会较高。
在《动手学深度学习》书中这个例子的情况下,精度一致但损失更小,意味着使用Dropout的模型在做出同样正确的预测时,其置信度更高。例如:
没有Dropout的模型可能预测一个正类样本的概率为0.51(正确但置信度低)。
使用Dropout的模型可能预测同一个样本的概率为0.99(正确且置信度高)。
Dropout导致训练损失更小的好处
尽管精度没有变化,但训练损失更小带来了以下几个关键优势:
模型学习更稳健的特征表示
Dropout作为一种正则化技术,通过随机丢弃神经元,强制模型不依赖于任何单个神经元或特征组合。这促使模型学习更通用、更鲁棒的特征,而不是记忆训练数据中的噪声。
损失更小表明模型在训练过程中更有效地捕捉了数据中的本质模式,从而以更高的置信度做出预测。这意味着模型对输入数据的微小变化或噪声更不敏感,在实际应用中更可靠。
模型可能收敛到更优的损失曲面区域
深度学习中的损失曲面通常有多个局部最小值。Dropout通过引入噪声,帮助模型跳出尖锐的局部最小值,找到更平坦的极小值点。
平坦的极小值点通常对应更好的泛化能力,因为模型参数的小幅变动不会导致性能大幅下降。损失更小表明模型可能找到了这样一个平坦区域,同时保持了训练和测试精度的一致,这暗示模型泛化能力更强。
提高模型的校准性和可靠性
损失更小意味着模型的预测概率更接近真实概率(即模型更“校准”)。例如,当模型预测某个事件有90%的概率发生时,实际发生概率也接近90%。
这在决策支持系统中非常重要(如医疗诊断、金融风险评估),因为高置信度的正确预测可以减少不确定性,提高决策的可靠性。
为后续优化提供更好的起点
如果损失值更低,模型可能处于一个更优的优化状态。在需要进一步微调或迁移学习时,这样的模型作为起点通常更容易调整,并可能获得更好的性能。
为什么精度没有变化但损失更小?
精度是一个阈值指标,它只关心预测类别是否正确,而忽略概率值。因此,当所有预测都正确时,精度可能达到上限,无法进一步反映模型内部的改进。
损失函数则更敏感,它能捕捉到模型预测概率的细微变化。即使精度相同,损失降低也意味着模型在“如何正确”方面做得更好。
实际应用中的意义
在部署模型时,损失更小的模型往往更稳定,尤其是在处理真实世界数据时,这些数据可能包含分布外样本或噪声。模型的高置信度可以减少错误预测的风险。
如果你需要模型输出概率(如推荐系统中的排名),损失更小的模型会提供更准确的概率估计,从而提升用户体验。
注意事项
虽然这种情况是积极的,但仍需监控验证集上的损失和精度,确保模型没有过拟合或其他问题。
如果损失过小(接近零),也可能表明过拟合,但根据前提描述(训练和测试精度一致),这似乎不是什么问题。
可以考虑调整Dropout率(如通过网格搜索)来进一步优化,或许能同时提升精度和损失。
总之,Dropout导致训练损失更小,即使精度不变,也表明模型的学习质量更高、更可靠。这通常是正则化技术发挥作用的理想结果,值得鼓励。